代碼分享
代碼僅供交流使用
講了那么多 , 分享部分我的代碼
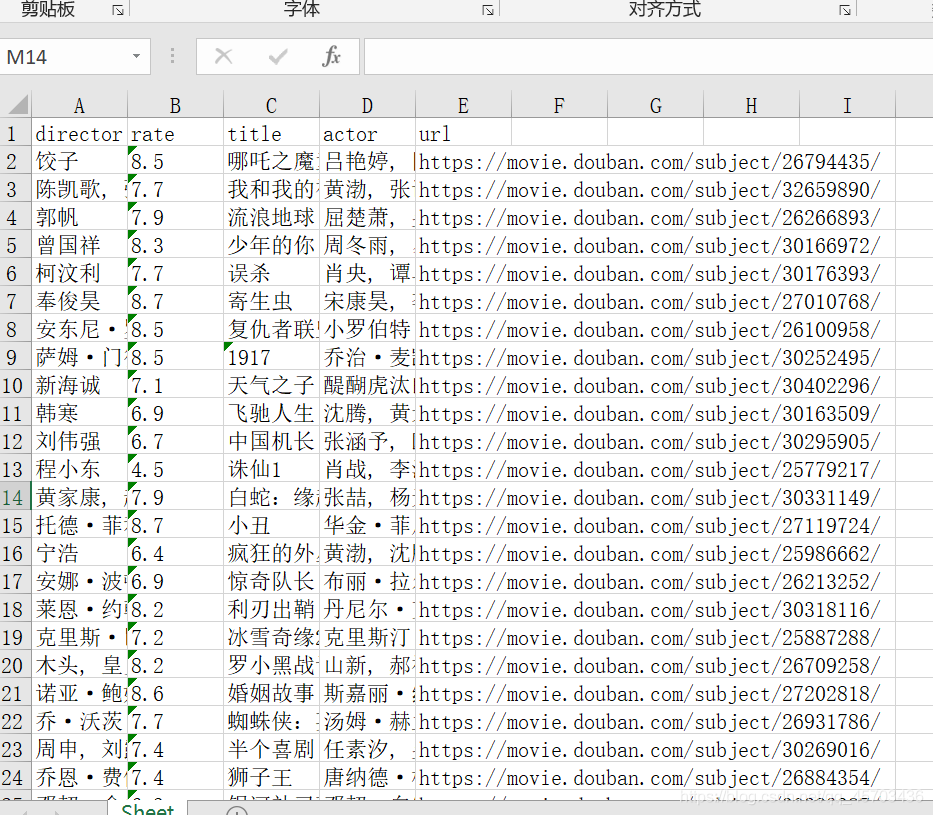
爬電影總的資訊
爬取總的500部電影資訊的代碼,并保存到
500films.xlsx檔案中
( 除了之前講到的,還用到了json的一點點知識,只有一點點)
import requests
import json
from openpyxl import Workbook
#正常的庫參考
wb = Workbook()
ws = wb.active
ws.append(["director","rate","title","actor","url"])
cookie = '' #填你的cookie
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Cookie":cookie
}
#因為這里只請求了一次,所以沒有用cookie也是可以的
url = "https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0&limit=500&year_range=2019,2019"
#'''這里的url是之前提到的修改了limit為500的url'''
print('開始爬了')
retval = requests.get(url,headers=headers)
data = json.loads(retval.text)
for i in data['data']:
directors = str(i['directors']).strip("[]").replace('\'','')
rate = str(i['rate'])
title = str(i['title'])
casts = str(i['casts']).strip("[]").replace('\'','')
url = str(i['url'].replace('"',''))
ws.append([directors,rate,title,casts,url])
#'''非常菜的除括號和引號方法'''
wb.save("500films.xlsx")
爬評論內容
讀取剛剛生成的500films檔案,讀取里面的url,并且進行相應處理
然后進行爬取十部電影的基本資訊和評論內容
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import random
import re
import openpyxl
from openpyxl import Workbook
import time
#'''正常的庫參考'''
cookie = '' #'''這里填你的cookie'''
FilmName = ''
temp_column = 1
temp_row = 2 #這兩個變數用于指向訪問的單元格的行和列
def get_one_url(film_num): #讀取500films中的url
global FilmName
data = openpyxl.load_workbook('./500films.xlsx')
table = data.get_sheet_by_name('Sheet')
url = table.cell(film_num+1,5).value+"comments?start="
FilmName = table.cell(film_num+1,3).value
return url
def dispose_url(url,comment_num): #處理和調整url模擬翻頁
url = url + str(comment_num) + "&limit=20&status=P&sort=new_score"
return url
def get_html(url): #獲取我們要的html檔案
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Cookie":cookie
}
response = requests.get(url,headers = headers)
time.sleep(random.randint(10,20)/10)
#'''這一步讓每次爬取時都能隨機休眠0.5-1s,太規整的休眠容易被識別,沒有休眠也容易導致請求太頻繁被豆瓣封ip'''
#print("here is"+response.text)
return response
def get_soup(response): #beautifulsoup化
demo = BeautifulSoup(response,"html.parser")
return demo
def get_infor(demo): #讀取總的資訊
infor = demo.find_all("span",class_="attrs")
infor = infor[0].find_all("p")
dele = re.compile('\s')
global temp_column,temp_row
temp_column = 2;
for i in infor:
#print(temp_row,temp_column)
temp = dele.sub('',i.text)[3:]
#print(temp)
ws.cell(row = temp_row,column = temp_column).value = temp
temp_column += 1
#'''對html頁面的讀取處理和資訊的存盤'''
def get_comments(demo): #'''獲取評論'''
a = demo.find_all("span",class_="short")
global temp_column,temp_row
for i in a:
#print(i.text)
ws.cell(row = temp_row,column = temp_column).value = i.text
temp_column += 1
temp_row += 1
def get_more_comments(url1): #'''回圈獲取評論'''
global temp_column,temp_row
for i in range(0,26):
temp_column = 8
url = dispose_url(url1,i*20)
print("=========="+url+"==========")
response = get_html(url)
demo = get_soup(response.text)
get_comments(demo)
#f = open("douban.html","r",encoding='UTF-8')
#response = f.read()
wb = Workbook()
ws = wb.active
ws.append(["name","director","actors","type","area","time","release time","comments"])
for film_num in range(1,11):
url1 = get_one_url(film_num)
url = dispose_url(url1,0)
response = get_html(url)
demo = get_soup(response.text)
get_infor(demo)
ws.cell(temp_row,1).value = str(FilmName)
get_more_comments(url1)
wb.save('film_comments.xlsx')
首先寫好模塊,然后呼叫函式進行各種各樣花里胡哨的操作
最終效果是這樣的(之前代碼有點小問題,改了一下啊,爬一小部分是這樣的)
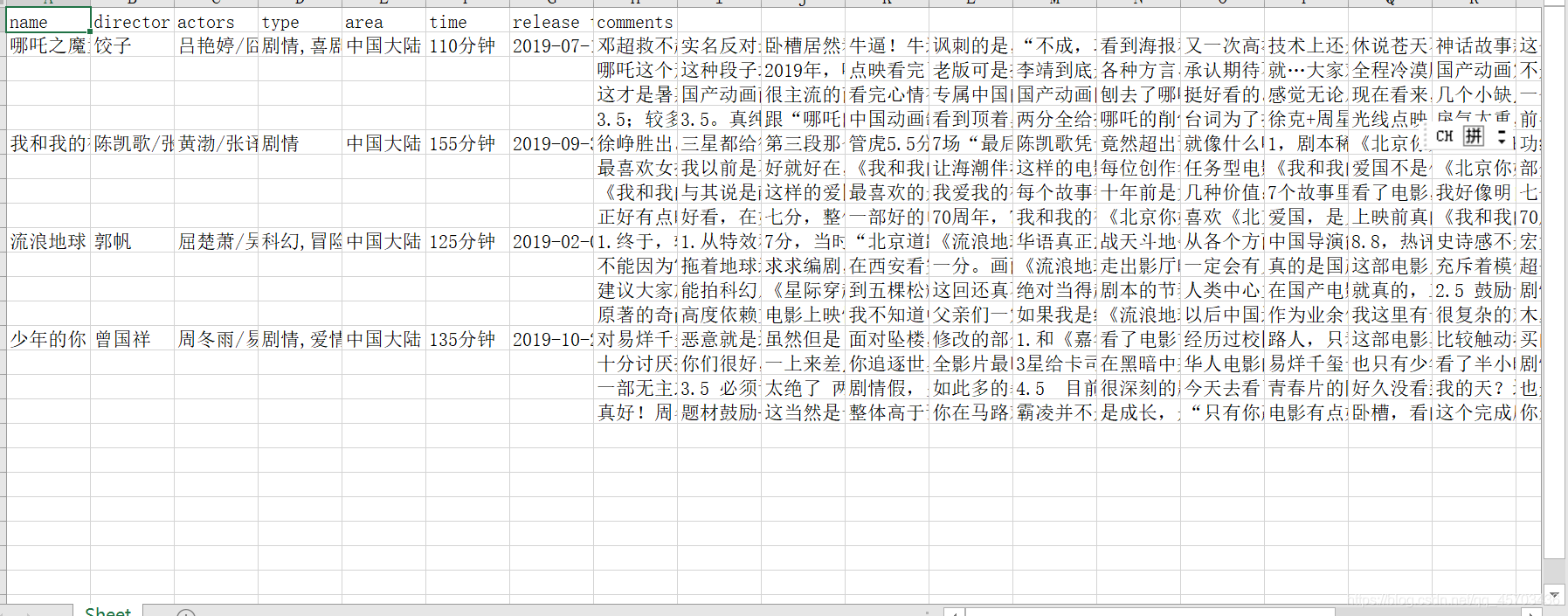
寫在最后,剩余的爬蟲的代碼(其實還有好多,但是改一下就行)其實都大同小異 , 無非是獲取html檔案, 用各種東西提取資料 , 存到excel檔案中 . 再想辦法用python把已經爬下來的存盤在excel中的資料進行處理(這步很繁瑣) , 方便可視化的操作.最后就是寫電影報告啦.
其實這次主要是想試一下markdow的用法, 正好有個作業涉及的內容比較適合做博客 , 就試圖寫一下博客 .
肯定有很多不足之處 , 但也是一種經歷吧.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/210078.html
標籤:python
上一篇:碎片實踐-新聞應用
下一篇:滑動平均濾波器與CIC濾波器