概述
《分布式系統概念與設計》一書中對分布式系統概念的定義如下:分布式系統是一個硬體或軟體組件分布在不同的網路計算機上,彼此之間僅僅通過訊息傳遞進行通信和協調的系統
分布式系統的設計目標一般包括如下幾個方面
- 可用性:可用性是分布式系統的核心需求,其用于衡量一個分布式系統持續對外提供服務的能力,
- 可擴展性:增加機器后不會改變或極少改變系統行為,并且能獲得近似線性的性能提升,
- 容錯性:系統發生錯誤時,具有對錯誤進行規避以及從錯誤中恢復的能力,
- 性能:對外服務的回應延時和吞吐率要能滿足用戶的需求,
分布式架構比單體式架構擁有更多的挑戰
- 節點之間的網路通信是不可靠的,存在網路延時和丟包等情況,
- 存在節點處理錯誤的情況,節點自身隨時也有宕機的可能,
- 同步呼叫使系統變得不具備可擴展性,
CAP原理
提到分布式系統,就不得不提CAP原理,
CAP的完整定義為:
- C:Consistency(一致性),這里的一致性特指強一致,通俗地說,就是所有節點上的資料時刻保持同步,一致性嚴謹的表述是原子讀寫,即所有讀寫都應該看起來是“原子”的,或串行的,所有的讀寫請求都好像是經全域排序過的一樣,寫后面的讀一定能讀到前面所寫的內容,
- A:Availability(可用性),任何非故障節點都應該在有限的時間內給出請求的回應,不論請求是否成功,
- P:Tolerance to the partition of network(磁區容忍性),當發生網路磁區時(即節點之間無法通信),在丟失任意多訊息的情況下,系統仍然能夠正常作業,
CAP原理具有重大的指導意義:在任何分布式系統中,可用性、一致性和磁區容忍性這三個方面都是相互矛盾的,三者不可兼得,最多只能取其二,
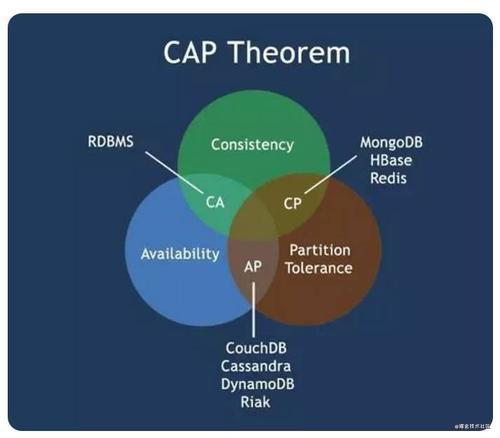
直觀的說明如下:
1)AP滿足但C不滿足:如果既要求系統高可用又要求磁區容錯,那么就要放棄一致性了,因為一旦發生網路磁區(P),節點之間將無法通信,為了滿足高可用(A),每個節點只能用本地資料提供服務,這樣就會導致資料的不一致(!C),一些信奉BASE(Basic Availability, Soft state, Eventually Consistency)原則的NoSQL資料庫(例如,Cassandra、CouchDB等)往往會放寬對一致性的要求(滿足最終一致性即可),以此來換取基本的可用性,
2)CP滿足但A不滿足:如果要求資料在各個服務器上是強一致的(C),然而網路磁區(P)會導致同步時間無限延長,那么如此一來可用性就得不到保障了(!A),堅持事務ACID(原子性、一致性、隔離性和持久性)的傳統資料庫以及對結果一致性非常敏感的應用(例如,金融業務)通常會做出這樣的選擇,
3)CA滿足但P不滿足:指的是如果不存在網路磁區,那么強一致性和可用性是可以同時滿足的,
正如熱力學第二定律揭示了任何嘗試發明永動機的努力都是徒勞的一樣,CAP原理明確指出了完美滿足CAP三種屬性的分布式系統是不存在的,
了解CAP原理的目的在于,其能夠幫助我們更好地理解實際分布式協議實作程序中的取舍,
一致性
分布式存盤系統通常會通過維護多個副本來進行容錯,以提高系統的可用性,這就引出了分布式存盤系統的核心問題——如何保證多個副本的一致性?
“一致性”有三種含義:
-
Coherence這個單詞只在Cache Coherence場景下出現過,其所關注的是多核共享記憶體的CPU架構下,各個核的Cache上的資料應如何保持一致,
-
Consensus是共識,它強調的是多個提議者就某件事情達成共識,其所關注的是達成共識的程序,例如Paxos協議、Raft選舉等,Consensus屬于replication protocol的范疇,
-
Consistency表達的含義相對復雜一些,廣義上說,它描述了系統本身的不變數的維護程度對上層業務客戶端的影響,以及該系統的并發狀態會向客戶端暴露什么樣的例外行為,CAP、ACID中的C都有這層意思,
這里重點討論的分布式系統中的一致性問題,屬于上文中提到的Consensus和Consistency范疇,
分布式系統的一致性是一個具備容錯能力的分布式系統需要解決的基本問題,通俗地講,一致性就是不同的副本服務器認可同一份資料,一旦這些服務器對某份資料達成了一致,那么該決定便是最終的決定,且未來也無法推翻,
這里有一點需要注意:一致性與結果的正確性沒有關系,而是系統對外呈現的狀態是否一致(統一),例如,所有節點都達成一個錯誤的共識也是一致性的一種表現,
一致性協議就是用來解決一致性問題的,它能使得一組機器像一個整體一樣作業,即使其中的一些機器發生了錯誤也能正常作業,正因為如此,一致性協議在大規模分布式系統中扮演著關鍵角色,
一致性協議從20世紀80年代開始研究,一致性協議衍生出了很多演算法,衡量一致性演算法的標準具體如下:
- 可終止性:非失敗行程在有限的時間內能夠做出決定,等價于liveness,
- 一致性:所有的行程必須對最終的決定達成一致,等價于safety,
- 合法性:演算法做出的決定值必須在其他行程(客戶端)的期望值范圍之內,即客戶端請求回答“是”或“否”時,不能回傳“不確定”,
一致性模型
在給定了與操作和狀態相關的一些規則的情況下,系統中的操作歷史應該總是遵循這些規則,我們稱這些規則為一致性模型
一致性模型分述
對于一致性,可以分別從客戶端和服務端兩個不同的視角來理解,
從客戶端來看,一致性主要是指多并發訪問時如何獲取更新過的資料的問題,
從服務端來看,則是更新如何復制分布到整個系統,以保證資料最終的一致性,
因此,可以從兩個角度來查看一致性模型:以資料為中心的一致性模型和以用戶為中心的一致性模型,
以資料為中心的一致性模型
實作以下這幾種一致性模型的難度會依次遞減,對一致性強度的要求也依次遞減,
-
嚴格一致性(Strong Consistency)
嚴格一致性也稱強一致性,原子一致性或者是可線性化(Linearizability),是要求最高的一致性模型,嚴格一致性的要求具體如下:
- 任何一次讀都能讀到某個資料的最近一次寫的資料,
- 系統中的所有行程,看到的操作順序,都與全域時鐘下的順序一致,
**嚴格一致性維護的是一個絕對全域時間順序,**單機系統遵守嚴格一致性,但對于分布式系統,為每個操作都分配一個準確的全域時間戳是不可能實作的,所以嚴格一致性只是存在于理論中的一致性模型,
-
順序一致性(Sequential Consistency)
順序一致性,也稱為可序列化,比嚴格一致性要求弱一點,但也是能夠實作的最高級別的一致性模型,
因為全域時鐘導致嚴格一致性很難實作,因此順序一致性放棄了全域時鐘的約束,改為分布式邏輯時鐘實作,順序一致性是指所有的行程都以相同的順序看到所有的修改,讀操作未必能夠及時得到此前其他行程對同一資料的寫更新,但是每個行程讀到的該資料不同值的順序卻是一致的,
滿足順序一致性的存盤系統需要一個額外的邏輯時鐘服務,
下圖解釋了嚴格一致性和順序一致性
a) 順序一致性,從這兩個行程的角度來看,順序應該是這樣的:Write(y, 2)→Read(x, 0)→Write(x, 4)→Read(y, 2),完全沒有沖突
b) 嚴格一致性,從兩個行程看到的操作順序與全域時鐘的順序一樣,都是Write(y, 2)→Write(x, 4)→Read(x, 4)→Read(y, 2),
c) 不滿足順序一致性,Write(x, 4)→Read(y, 0)→Write(y, 2)→Read(x, 0),這個有沖突

3. 因果一致性(Causal Consistency)
因果關系可以描述成如下情況:
- 本地順序:本行程中,事件執行的順序即為本地因果順序,
- 異地順序:如果讀操作回傳的是寫操作的值,那么該寫操作在順序上一定在讀操作之前,
- 閉包傳遞:與時鐘向量里面定義的一樣,如果a→b且b→c,那么肯定也有a→c,
不嚴格地說,因果一致性弱于順序一致性,
因果一致性和順序一致性的對比

因果關系可能比較難以理解,下面給大家解釋一下
P2寫x=7,P2同步到P3,P3讀到7
P1寫x=2,P1同步到P3,P3讀到2
P1寫x=4,P1同步到P4,P4讀到4
P2同步到P4,P4讀到7
永遠不會出現先讀到4,再讀到2的情況
因果關系只保證因果的順序是正確的,其他的順序不理會
-
可串行化一致性(Serializable Consis-tency)
如果說操作的歷史等同于以某種單一原子順序發生的歷史,但對呼叫和完成時間沒有說明,那么就可以獲得稱為可序列化的一致性模型,
在一個可序列化的系統中,有如下所示的這樣一個程式:
x = 1
x = x + 1
puts x
在這里,我們假設每行代表一個操作,并且所有的操作都成功,因為這些操作可以以任何順序進行,所以可能列印出nil、1或2,因此,一致性顯得很弱,
但在另一方面,串行化的一致性又很強,因為它需要一個線性順序,例如,下面的這個程式:
print x if x = 3
x = 1 if x = nil
x = 2 if x = 1
x = 3 if x = 2
它可能不會嚴格地以我們撰寫的順序發生,但它能夠可靠地將x從nil→1→2,更改為3,最后列印出3,
以用戶為中心的一致性模型
-
最終一致性(Eventual Consistency)
最終一致性是指如果更新的間隔時間比較長,那么所有的副本都能夠最終達到一致性,
用戶讀到某一操作對系統特定資料的更新需要一段時間,我們將這段時間稱為“不一致性視窗”,
在讀多寫少的場景中,例如CDN,讀寫之比非常懸殊,如果網站的運營人員修改了一張圖片,最終用戶延遲了一段時間才看到這個更新實際上問題并不是很大,
復制狀態機
復制狀態機的基本思想是:一個分布式的復制狀態機系統由多個復制單元組成,每個復制單元均是一個狀態機,它的狀態保存在一組狀態變數中,狀態機的狀態能夠并且只能通過外部命令來改變,
上文提到的“一組狀態變數”通常是基于操作日志來實作的,每一個復制單元存盤一個包含一系列指令的日志,并且嚴格按照順序逐條執行日志上的指令,
所以,在復制狀態機模型下,一致性演算法的主要作業就變成了如何保證操作日志的一致性,
復制狀態機的運行程序如下圖所示:
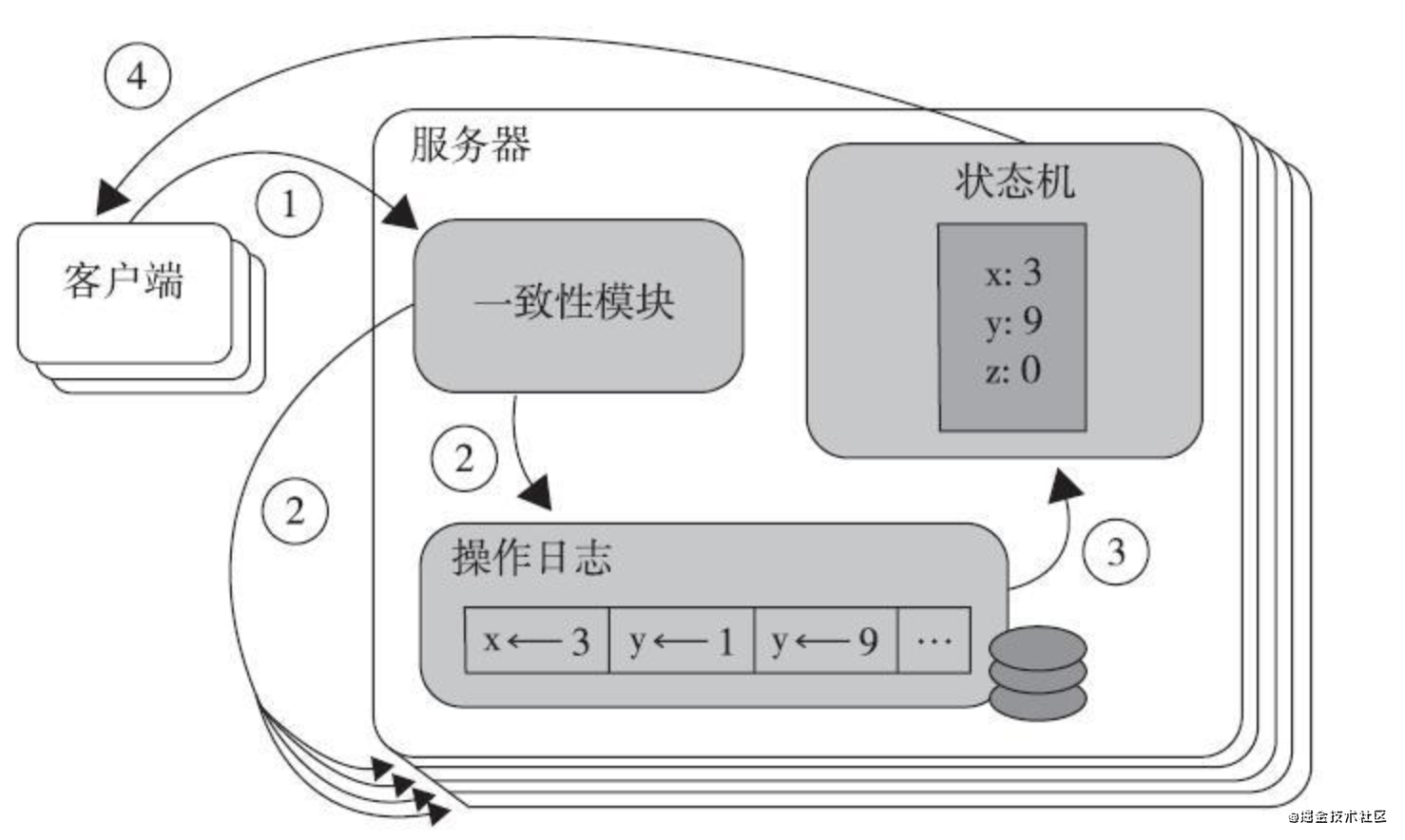
服務器上的一致性模塊負責接收外部命令,然后追加到自己的操作日志中,它與其他服務器上的一致性模塊進行通信以保證每一個服務器上的操作日志最終都以相同的順序包含相同的指令,一旦指令被正確復制,那么每一個服務器的狀態機都將按照操作日志的順序來處理它們,然后將輸出結果回傳給客戶端,
復制狀態機在分布式系統中常被用于解決各種容錯相關的問題,例如,GFS、HDFS、Chubby、ZooKeeper和etcd等分布式系統都是基于復制狀態機模型實作的,
需要注意的是,指令在狀態機上的執行順序并不一定等同于指令的發出順序或接收順序,
復制狀態機只是保證所有的狀態機都以相同的順序執行這些命令,
拜占庭將軍問題
拜占庭位于如今土耳其的伊斯坦布爾,是東羅馬帝國的首都,由于當時拜占庭羅馬帝國幅員遼闊,出于防御的原因,每個軍隊都相隔甚遠,將軍與將軍之間只能靠信差來傳遞訊息,發生戰爭時,拜占庭軍隊內所有將軍必需達成共識,決定是否攻擊敵人,但是軍隊內可能存在叛徒和敵軍的間諜擾亂將軍們的決定,因此在進行共識交流時,結果可能并不能真正代表大多數人的意見,這時,在已知有成員不可靠的情況下,其余忠誠的將軍如何排除叛徒或間諜的影響來達成一致的決定,就是著名的拜占庭將軍問題,
拜占庭將軍問題講述的是一個共識問題,拜占庭將軍問題是對現實世界的模型化,
-
拜占庭錯誤是一個overly pessimistic模型(最悲觀、最強的錯誤模型)
研究這個模型的意義在于:如果某個一致性協議能夠保證系統在出現N個拜占庭錯誤時,依舊可以做出一致性決定,那么這個協議也就能夠處理系統出現N個其他任意型別的錯誤,
-
行程失敗錯誤(fail-stop Failure,如同宕機)則是一個overly optimistic模型(最樂觀、最弱的錯誤模型)
研究這個模型的意義在于:如果某個一致性協議在系統出現N個行程失敗錯誤時都無法保證做出一致性決定,那么這個協議也就無法處理系統出現N個其他任意型別的錯誤,
Fred Schneider在前面提到的論文《Implementing fault-tolerant services using thestate machine approach》中指出了這樣一個基本假設:
一個RSM(分布式狀態機)系統要容忍N個拜占庭錯誤,至少需要2N+1個復制節點,
如果只是把錯誤的型別縮小到行程失敗,則至少需要N+1個復制節點才能容錯,
但是不是只要滿足上文提到的2N+1個要求就能保證萬無一失了呢?很不幸,答案是否定的,
FLP不可能性
FLP不可能性是分布式領域中一個非常著名的定理:
No completely asynchronous consensusprotocol can tolerate even a single unan-nounced process death.
在異步通信場景下,任何一致性協議都不能保證,即使只有一個行程失敗,其他非失敗行程也不能達成一致,
這里的行程失敗(unannounced process death)指的是一個行程發生了故障,但其他節點并不知道,繼續認為這個行程還沒有處理完成或發生訊息延遲了,
舉個例子:
甲、乙、丙三個人各自分開進行投票(投票結果是0或1),他們彼此可以通過電話進行溝通,但有人會睡著,例如:甲投票0,乙投票1,這時候甲和乙打平,丙的選票就很關鍵,然而丙睡著了,在他醒來之前甲和乙都將無法達成最終的結果,即使重新投票,也有可能陷入無盡的回圈之中,
FLP定理實際上說明了在允許節點失效的場景下,基于異步通信方式的分布式協議,無法確保在有限的時間內達成一致性,用CAP理論解釋的話,在P的條件下,無法滿足C和A,
請注意,這個結論的前提是異步通信,在分布式系統中,“異步通信”與“同步通信”的最大區別是沒有時鐘、不能時間同步、不能使用超時、不能探測失敗、訊息可任意延遲、訊息可亂序等,
所以,實際的一致性協議(Paxos、Raft等)在理論上都是有缺陷的,最大的問題是理論上存在不可終止性!但他們都做了一些調整,降低了概率,
Paxos協議
大神Leslie Lamport對類似拜占庭將軍這樣的問題進行了深入研究,并發表了幾篇論文,
總結起來就是回答如下的三個問題:
1)類似拜占庭將軍這樣的分布式一致性問題是否有解?
2)如果有解的話需要滿足什么樣的條件?
3)基于特定的前提條件,提出一種解法,
Leslie Lamport在論文“拜占庭將軍問題”中已經給出了前兩個問題的回答,而第三個問題在他的論文“The Part-Time Parliament”中提出了一種基于訊息傳遞的一致性演算法,
下面講述的就是大神的日常操作:
1990年,Lamport向ACM Transac-tions on Computer Systems提交了他那篇關于Paxos演算法的論文,主編回信建議他用數學而不是神話描述他的演算法,否則他們不會考慮接受這篇論文,Lamport覺得那些人太迂腐,拒絕做任何修改,轉而將論文貼在了自己的個人博客上,
起初Paxos演算法由于難以理解并沒有引起多少人的重視,直到2006年Google的三大論文初現“云”端,其中Chubby Lock服務使用了Paxos作為Chubby Cell的一致性演算法,這件事使得Paxos演算法的人氣從此一路飆升,幾乎壟斷了一致性演算法領域,在Raft演算法誕生之前,Paxos幾乎成了一致性協議的代名詞,
Lamport本人覺得Paxos很簡單,但事實上對于大多數人來說,Paxos還是太難理解了,
參考NSDI社區上的一句話就是:全世界真正理解Paxos演算法的人只有5個!
這可能就是人和神之間的區別吧,
然后,更容易理解的一致性演算法Raft誕生了,
Raft協議:為可理解性而生
終于講到Raft了,我太不容易了,
Raft演算法主要使用兩種方法來提高可理解性,提高理解性主要通過兩個常用手段
-
問題分解
盡可能地將問題分解成為若干個可解決的、更容易理解的小問題——這是眾所周知的簡化問題的方法論,例如,Raft演算法把問題分解成了領袖選舉(leader election)、日志復制(log repli-cation)、安全性(safety)和成員關系變化(membershipchanges)這幾個子問題,
- 領袖選舉:在一個領袖節點發生故障之后必須重新給出一個新的領袖節點,
- 日志復制:領袖節點從客戶端接收操作請求,然后將操作日志復制到集群中的其他服務器上,并且強制要求其他服務器的日志必須和自己的保持一致,
- 安全性:Raft關鍵的安全特性是下文提到的狀態機安全原則(State Machine Safety)——如果一個服務器已經將給定索引位置的日志條目應用到狀態機中,則所有其他服務器不會在該索引位置應用不同的條目,下文將會證明Raft是如何保證這條原則的,
- 成員關系變化:配置發生變化的時候,集群能夠繼續作業,
-
減少狀態空間
Raft演算法通過減少需要考慮的狀態數量來簡化狀態空間,這將使得整個系統更加一致并且能夠盡可能地消除不確定性,
Raft有幾點重要的創新
- 強領匯入,Raft使用一種比其他演算法更強的領導形式,例如,日志條目只從領匯入發向其他服務器,這樣就簡化了對日志復制的管理,提高了Raft的可理解性,
- 領袖選舉,Raft使用隨機定時器來選舉領導者,這種方式僅僅是在所有演算法都需要實作的心跳機制上增加了一點變化,就使得沖突解決更加簡單和快速,
- 成員變化,Raft在調整集群成員關系時使用了新的一致性(joint consensus,聯合一致性)方法,使用這種方法,使得集群配置在發生改變時,集群依舊能夠正常作業,
Raft一致性演算法
基本概念
-
Leader(領袖)
-
Candidate(候選人)
-
Follower(群眾)
-
任期(Term):Raft演算法將時間劃分成為任意個不同長度的任期,任期是單調遞增的,用連續的數字(1, 2, 3……)表示,在Raft的世界里,每一個任期的開始都是一次領匯入的選舉,如果一個候選人贏得了選舉,那么它就會在該任期的剩余時間內擔任領匯入,在某些情況下,選票會被瓜分,導致沒有哪位候選人能夠得到超過半數的選票,這樣本次任期將以沒有選出領匯入而結束,那么,系統就會自動進入下一個任期,開始一次新的選舉,Raft演算法保證在給定的一個任期內最多只有一個領匯入,某些Term會由于選舉失敗,存在沒有領匯入的情況,如t3所示,
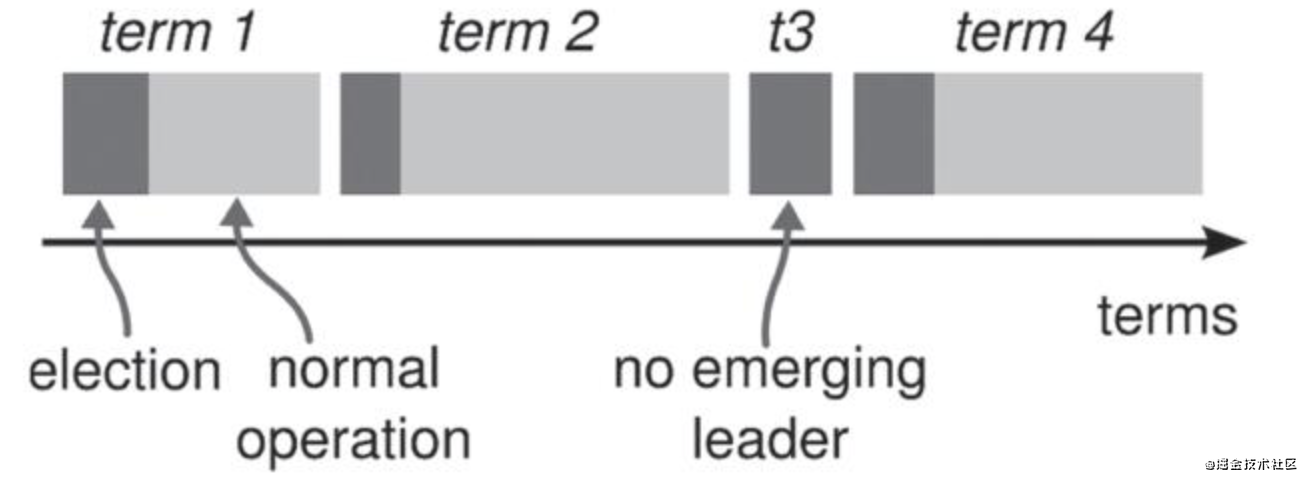
任期在Raft中起著邏輯時鐘的作用,同時也可用于在Raft節點中檢測過期資訊——比如過期的領匯入,每個Raft節點各自都在本地維護一個當前任期值,觸發這個數字變化(增加)主要有兩個場景:開始選舉和與其他節點交換資訊,如果一個節點(包括領匯入)的當前任期號比其他節點的任期號小,則將自己本地的任期號自覺地更新為較大的任期號,如果一個候選人或者領匯入意識到它的任期號過時了(比別人的小),那么它會立刻切換回群眾狀態;如果一個節點收到的請求所攜帶的任期號是過時的,那么該節點就會拒絕回應本次請求,
領匯入選舉
Raft通過選舉一個權力至高無上的領匯入,并采取賦予他管理復制日志重任的方式來維護節點間復制日志的一致性,
領匯入從客戶端接收日志條目,再把日志條目復制到其他服務器上,并且在保證安全性的前提下,告訴其他服務器將日志條目應用到它們的狀態機中,領匯入可以決定新的日志條目需要放在日志檔案的什么位置,而不需要和其他服務器商議,并且資料都是單向地從領匯入流向其他服務器,
領匯入選舉的程序,就是Raft三種角色切換的程序
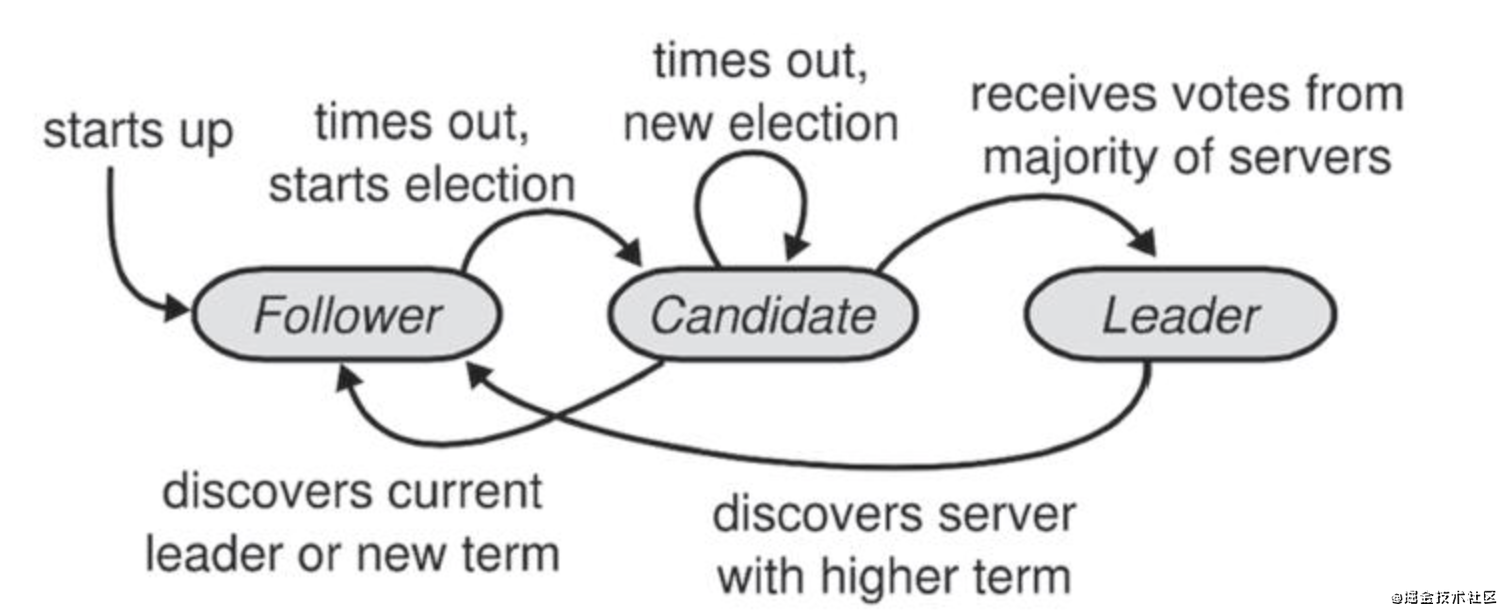
開始的時候,系統有一個Leader和眾多Follower
- 每一個Raft節點(包含Follower)內有一個選舉定時器,如果收到Leader廣播的心跳包,則Follower將選舉定時器重置,
- 如果Follower的選舉定時器時間到了,在這個期間沒有收到任何心跳包,Follower認為Leader,自己可以當Leader了,就開始發起選舉,主要做如下步驟
- 將自己本地維護的當前任期號(current_term_id)加1
- 將自己的狀態切換到候選人(Candidate),并為自己投票
- 向其所在集群中的其他節點發送RequestVote RPC(RPC訊息會攜帶“current_term_id”值),要求它們投票給自己
- 設定選舉超時時間,一般是隨機選取一個區間中的值
- 在Candidate狀態下
- 如果得到大多數選票,則成為Leader
- 如果發現已經產生了新的領匯入或者有更大的任期,則狀態更改為Follower
- 如果選舉超時時間過了,候選人自增任期號(Term++)并且發起新一輪的拉選票活動
- 在Leader狀態下,如果發現了更高的任期,則將自己變更為Follower
日志復制
一旦某個領匯入贏得了選舉,那么它就會開始接收客戶端的請求,領匯入將把這條指令作為一條新的日志條目加入它的日志檔案中,然后并行地向其他Raft節點發起AppendEntriesRPC,要求其他節點復制這個日志條目,當這個日志條目被“安全”地復制之后,Leader會將這條日志應用(apply,即執行該指令)到它的狀態機中,并且向客戶端回傳執行結果,如果Follower發生錯誤,運行緩慢沒有及時回應AppendEntries RPC,或者發生了網路丟包的問題,那么領匯入會無限地重試AppendEntries RPC(甚至在它回應了客戶端之后),直到所有的追隨者最終存盤了和Leader一樣的日志條目,
日志由有序編號的日志條目組成,每一個日志條目一般均包含三個屬性:整數索引(log index)、任期號(term)和指令(command),一般如下所示:
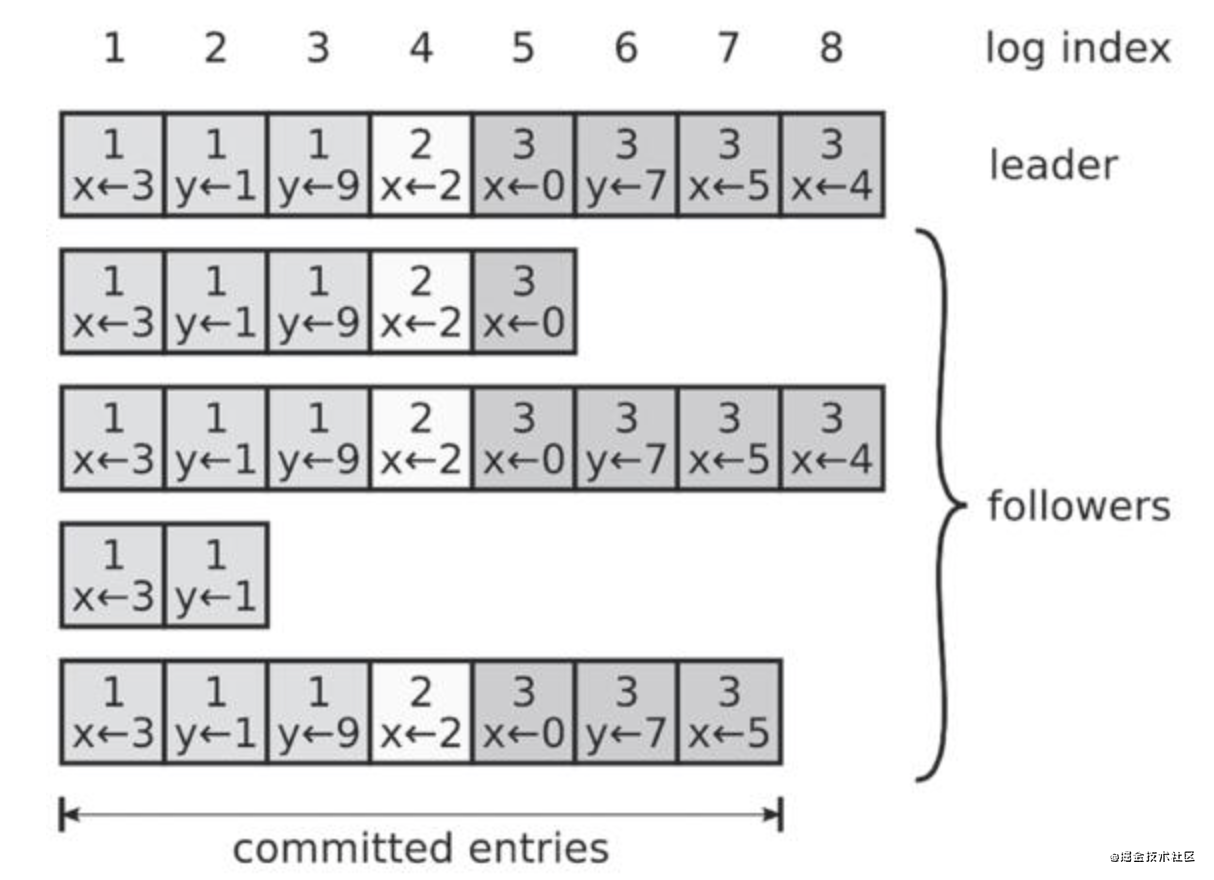
一旦領匯入創建的條目已經被復制到半數以上的節點上了,那么這個條目就稱為可被提交的,
Raft日志復制主要流程如下:
- 客戶端向Leader發送寫請求,
- Leader將寫請求決議成操作指令追加到本地日志檔案中,
- Leader為每個Follower廣播AppendEntries RPC,
- Follower通過一致性檢查,選擇從哪個位置開始追加Leader的日志條目,
- 一旦日志項提交成功,Leader就將該日志條目對應的指令應用(apply)到本地狀態機,并向客戶端回傳操作結果,
- Leader后續通過AppendEntries RPC將已經成功(在大多數節點上)提交的日志項告知Follower,
- Follower收到提交的日志項之后,將其應用至本地狀態機,
從上面的步驟可以看出,針對Raft日志條目有兩個操作,提交(commit)和應用(apply),應用必須發生在提交之后,即某個日志條目只有被提交之后才能被應用到本地狀態機上,
流程圖如下:https://www.processon.com/view/link/5fa6c1045653bb25634dea4a
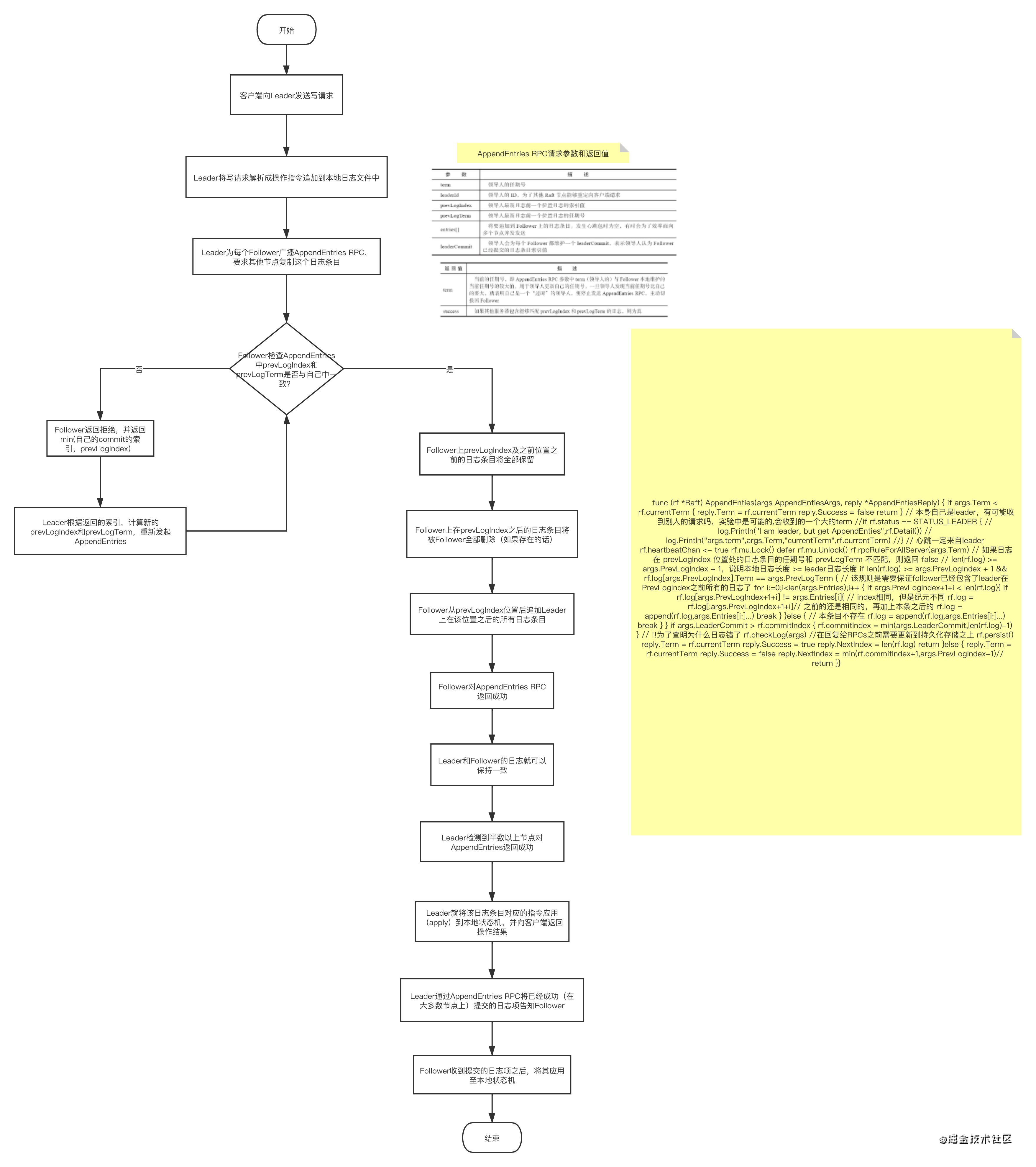
安全性
本文介紹如何在領匯入選舉部分加入一個限制規則來保證——任何的領匯入都擁有之前任期提交的全部日志條目,
-
怎樣才能具有成為領匯入的資格?- 必須包含所有已提交日志條目
RequestVote RPC的接收方有一個檢查:如果Follower自己的日志比RPC呼叫方(候選人)的日志更加新,就會拒絕候選人的投票請求,
這就Raft演算法使用投票的方式來阻止那些沒有包含所有已提交日志條目的節點贏得選舉,
-
如何判斷日志已經提交?
在提交之前term的日志項時,必須保證當前term新建的日志項已經復制到超過半數節點,這樣,之前term的日志項才算真正提交的,
可用性與時序性
broadcastTime << electionTimeout << MTBF
broadcastTime指的是一個節點向集群中其他節點發送RPC,并且收到它們回應的平均時間,
electionTimeout就是選舉超時時間,
MTBF指的是單個節點發生故障的平均時間間隔,
為了使領匯入能夠持續發送心跳包來阻止下面的Follower發起選舉,broadcastTime應該比electionTimeout小一個數量級,
例外情況
####追隨者/候選人例外
Raft演算法通過領匯入無限的重試來應對這些失敗,直到故障的節點重啟并處理了這些RPC為止,
因為Raft演算法中的RPC都是冪等的,因此不會有什么問題,
領匯入例外
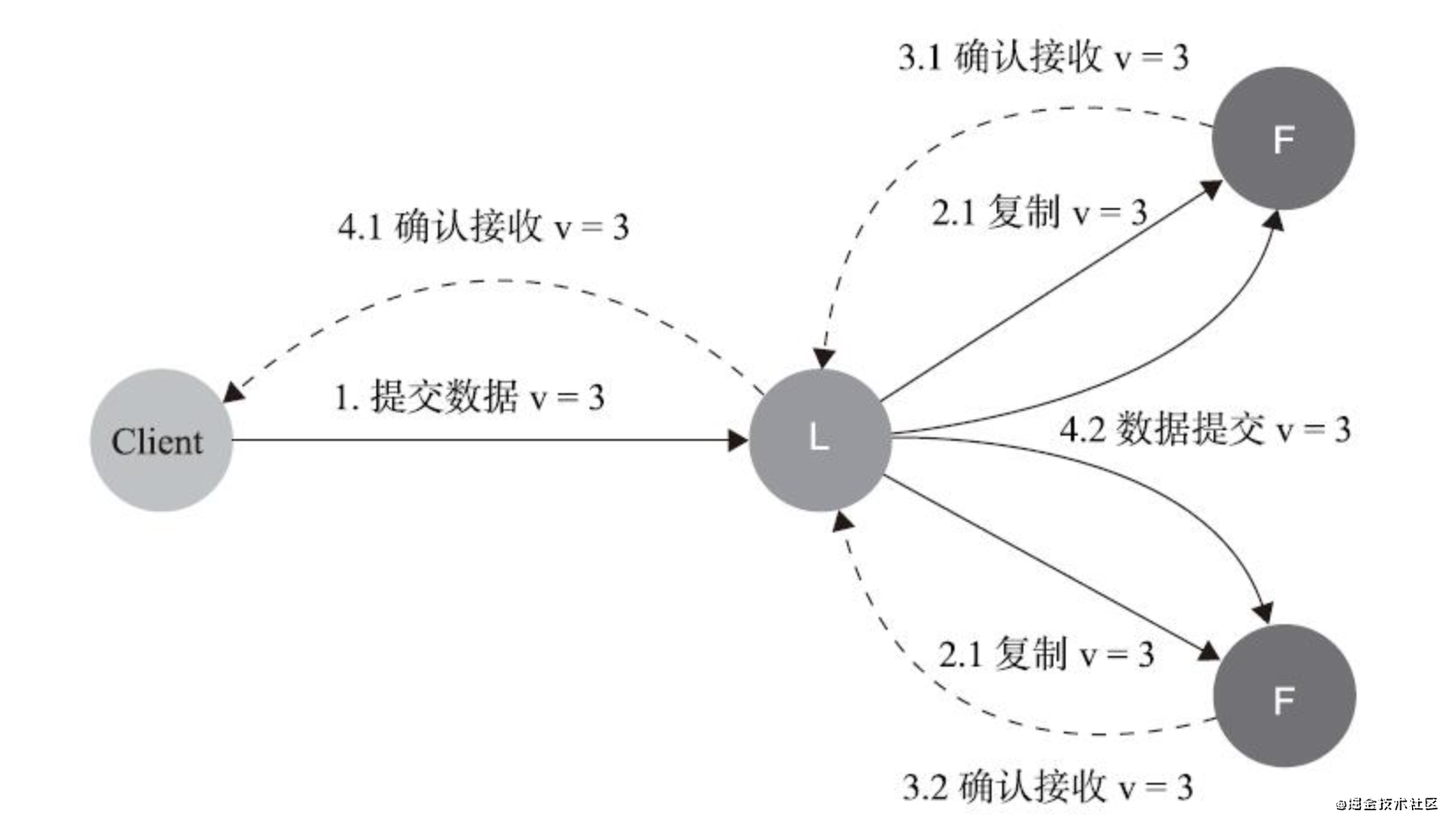
Raft資料交換流程如上圖所示,在任何時刻,領匯入都有可能崩潰,
- 資料在到達Leader之前
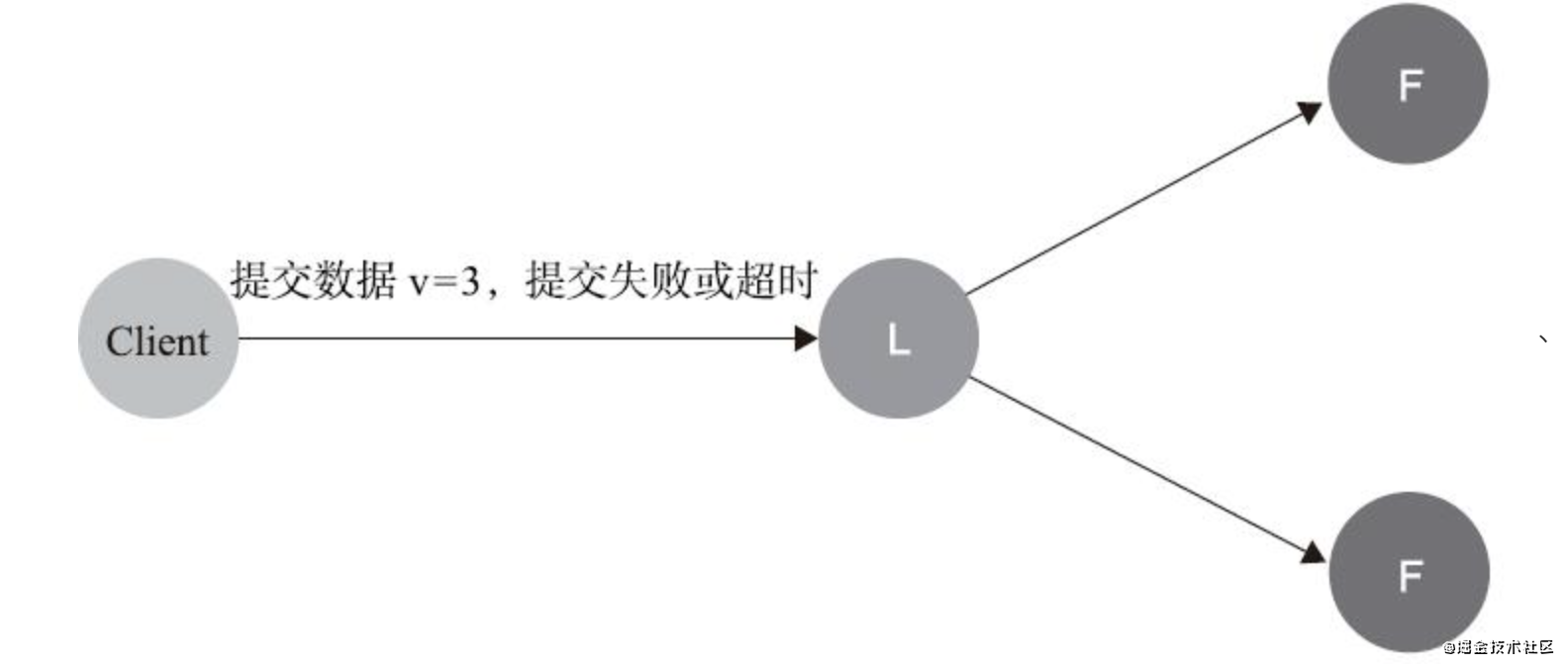
不影響一致性
- 資料到達Leader節點,但未復制到Follower節點
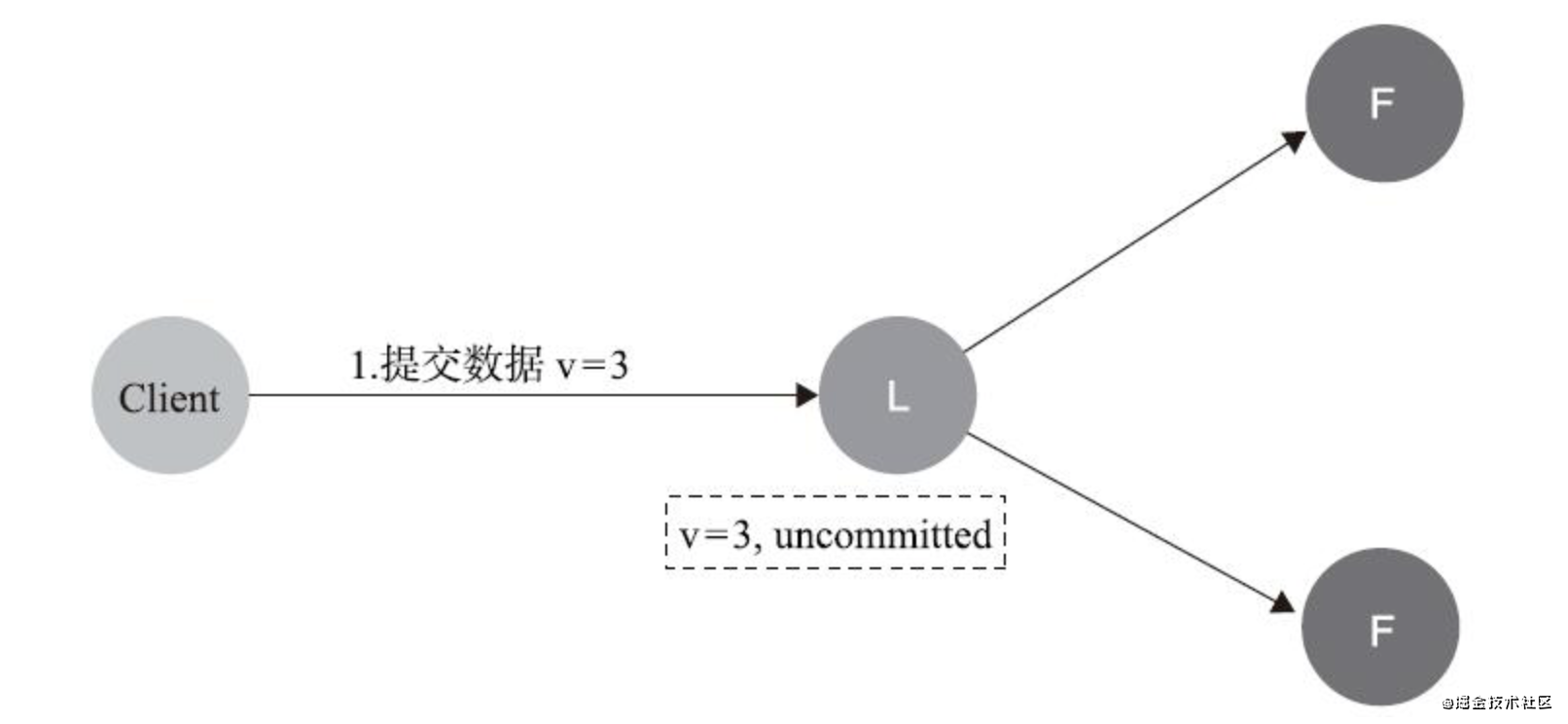
不影響一致性
如果在這個階段Leader出現故障,此時資料屬于未提交狀態,那么Client不會收到ACK,而是會認為超時失敗可安全發起重試,Follower節點上沒有該資料,重新選主后Client重試重新提交可成功,原來的Leader節點恢復之后將作為Follower加入集群,重新從當前任期的新Leader處同步資料,與Leader資料強制保持一致,
- 資料到達Leader節點,成功復制到Follower的部分節點上,但還未向Leader回應接收
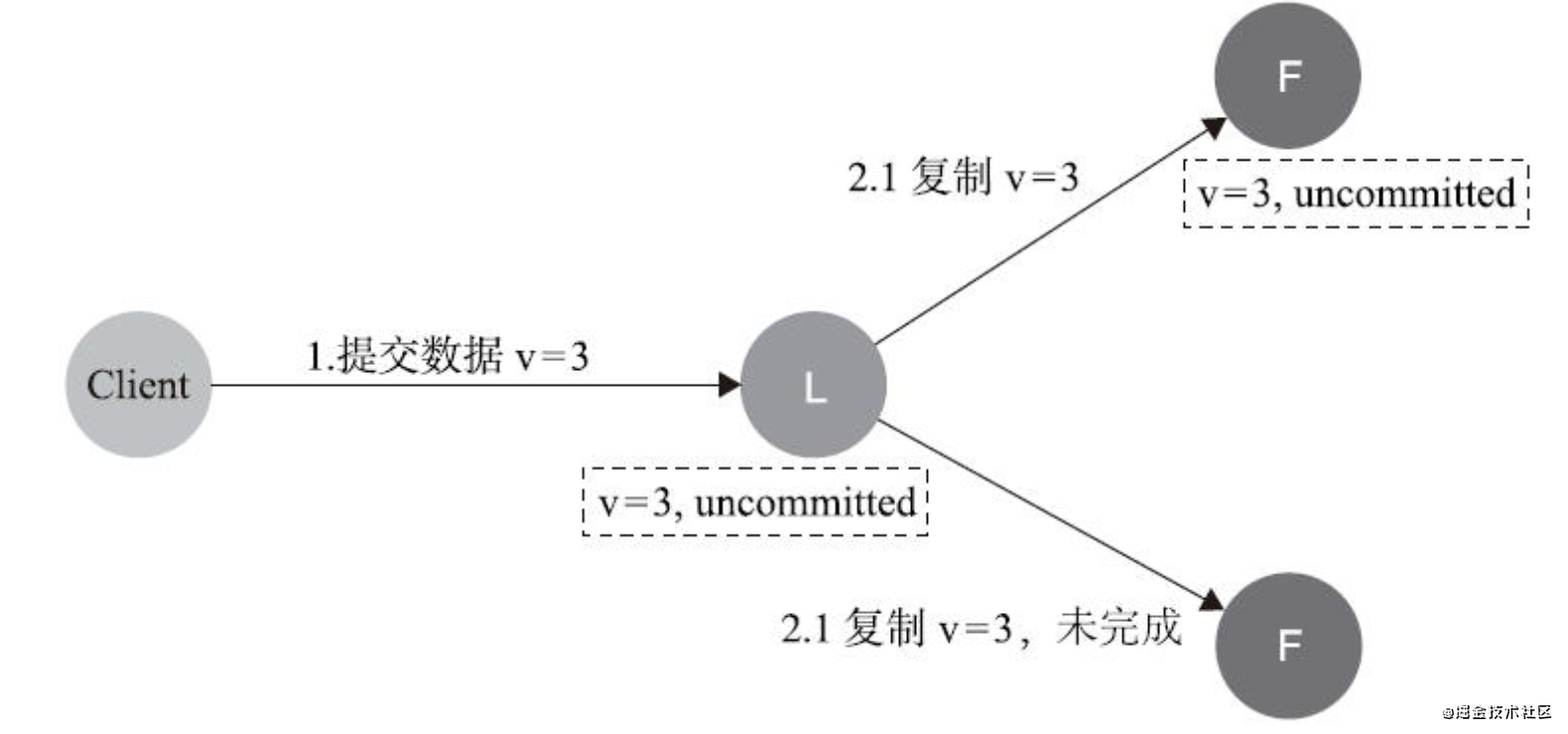
資料不丟失,也不影響一致性
如果在這個階段Leader出現故障,此時資料在Follower節點處于未提交狀態(Uncommitted)且不一致,那么Raft協議要求投票只能投給擁有最新資料的節點,所以擁有最新資料的節點會被選為Leader,再將資料強制同步到Follower,資料不會丟失并且能夠保證最終一致,
- 資料到達Leader節點,成功復制到Follower的所有節點上,但還未向Leader回應接收
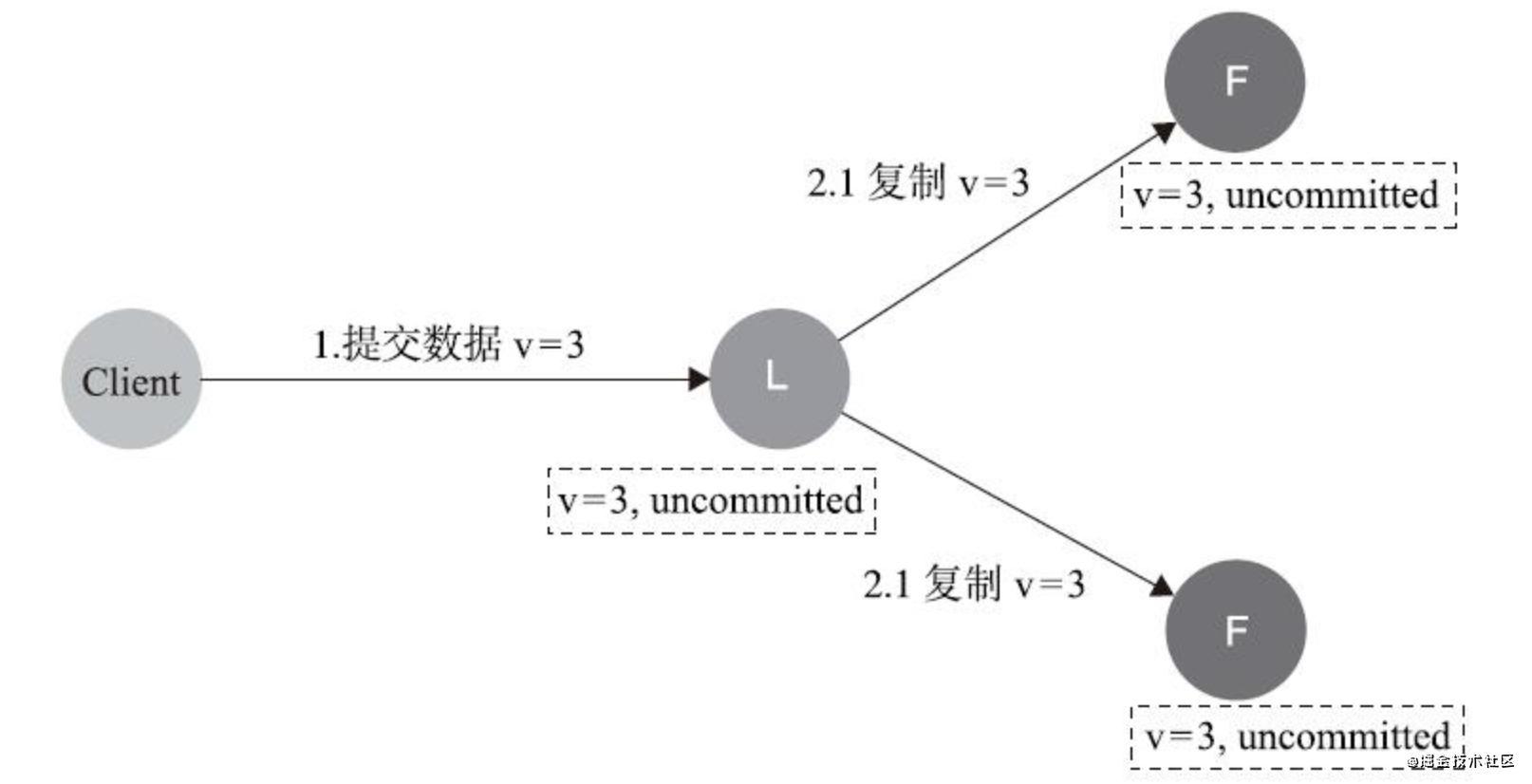
資料不丟失,也不影響一致性
如果在這個階段Leader出現故障,雖然此時資料在Fol-lower節點處于未提交狀態(Uncommitted),但也能保持一致,那么重新選出Leader后即可完成資料提交,由于此時客戶端不知到底有沒有提交成功,因此可重試提交,針對這種情況,Raft要求RPC請求實作冪等性,也就是要實作內部去重機制,
- 資料到達Leader節點,成功復制到Follower的所有或大多數節點上,資料在Leader上處于已提交狀態,但在Follower上處于未提交狀態
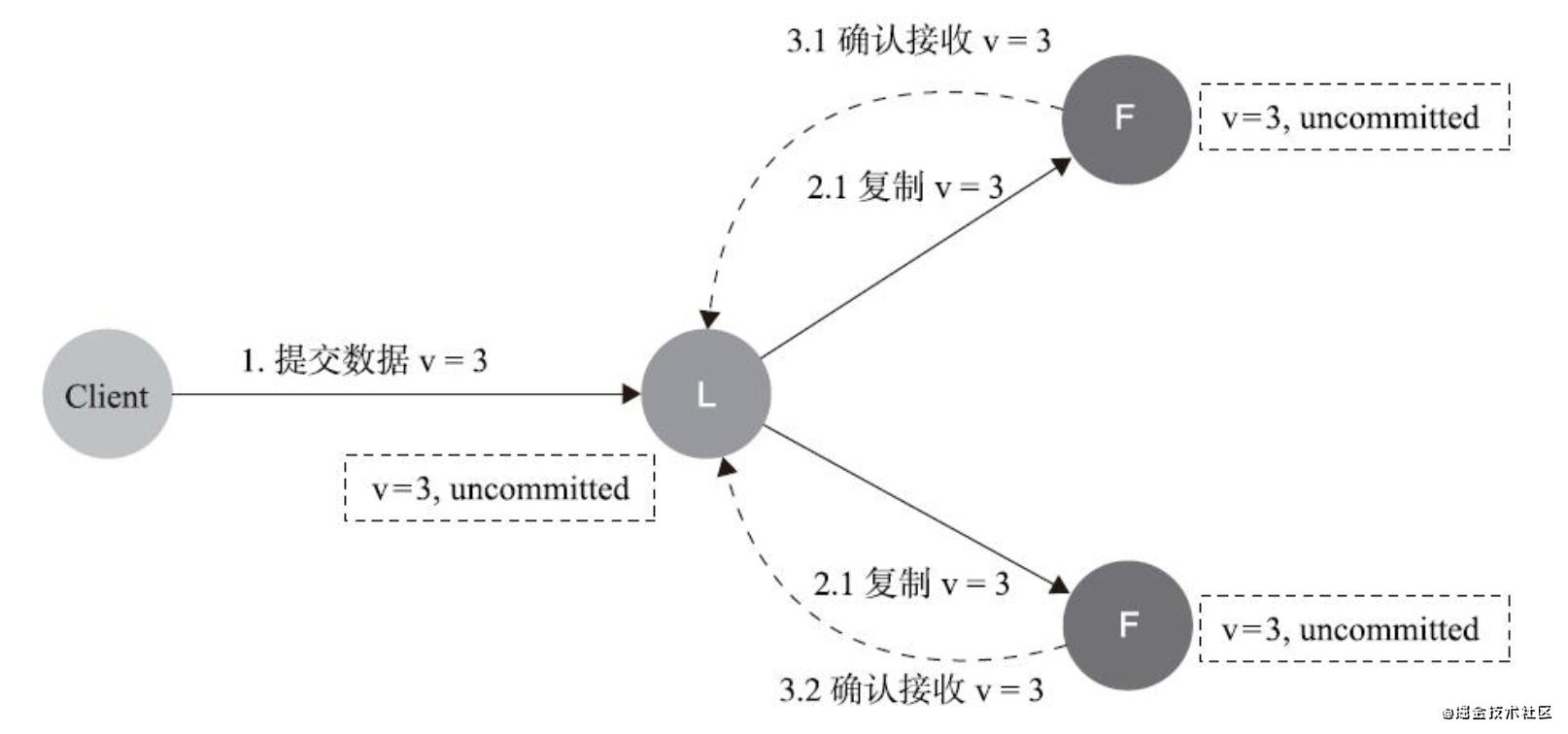
資料不丟失,也不影響一致性
- 資料到達Leader節點,成功復制到Follower的所有或大多數節點上,資料在所有節點都處于已提交狀態,但還未回應Client
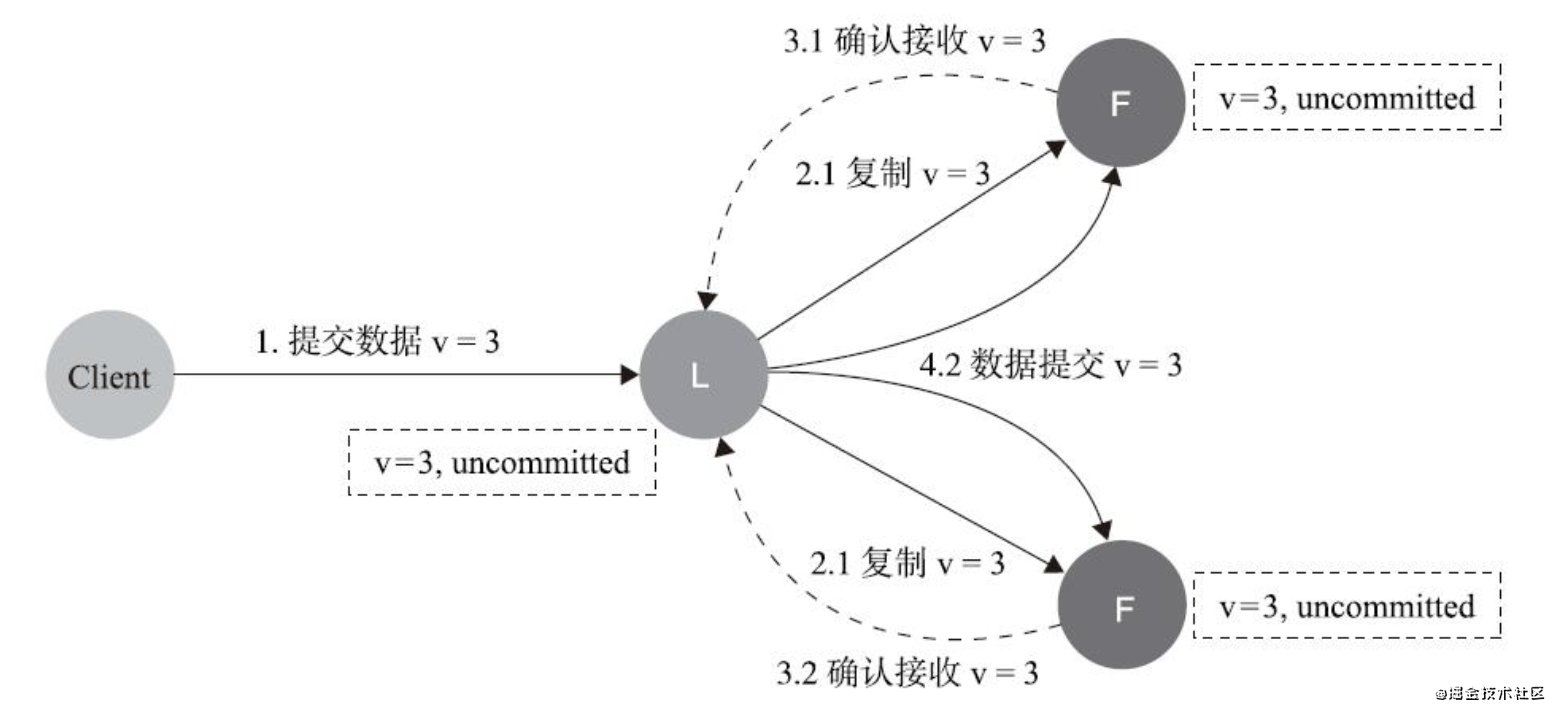
資料不丟失,也不影響一致性
- 網路磁區導致的腦裂情況,出現雙Leader
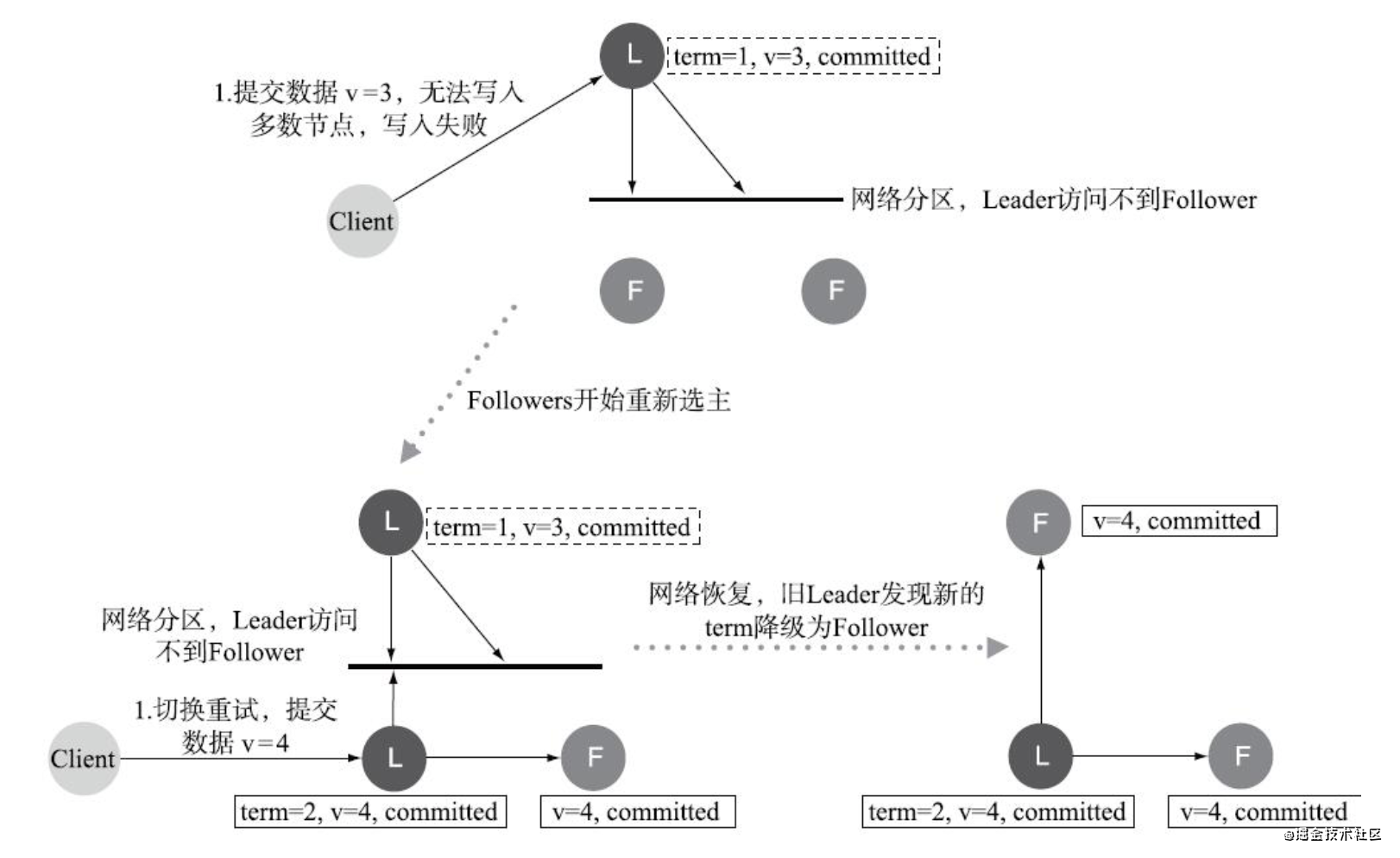
不影響一致性
網路磁區將原先的Leader節點和Follower節點分隔開,Follower收不到Leader的心跳將發起選舉產生新的Leader,這時就產生了雙Leader,原先的Leader獨自在一個區,向它提交資料不可能復制到大多數節點上,所以永遠都是提交不成功,向新的Leader提交資料可以提交成功,網路恢復后舊的Leader發現集群中有更新任期(Term)的新Leader,則自動降級為Fol-lower并從新Leader處同步資料達成集群資料一致,
總結
分布式系統和一般的業務系統區別還是挺大的,涉及到更多論文、數理知識,更加偏學術一些,隨著計算機的不斷發展,關于分布式的知識,還是需要進行掌握的,
關于Raft演算法,建議看一下原始碼https://github.com/etcd-io/etcd/tree/master/raft,
Raft通過領導選舉機制,簡化了整體的復雜性,利用日志復制+復制狀態機,保證狀態執行的一致,同時設定了一些對應的安全規則,加強了日志復制的安全,維護了一致性,
如果大家時間有限,可以只看一下CAP、復制狀態機和Raft,
資料
-
https://www.infoq.cn/article/wechat-serial-number-generator-architecture/ 微信序列號生成器架構設計及演變
-
從微信朋友圈的評論可見性,談因果一致性在分布式系統中的應用
-
https://www.jianshu.com/p/ab511132a34f raft 系列解讀(3) 之 代碼實作
-
https://blog.csdn.net/lanyang123456/article/details/109279234 raft協議中的日志安全性
-
http://www.duokan.com/book/180790 云原生分布式存盤基石:etcd深入決議
最后
大家如果喜歡我的文章,可以關注我的公眾號(程式員麻辣燙)
我的個人博客為:https://shidawuhen.github.io/

往期文章回顧:
技術
- 微服務之服務框架和注冊中心
- Beego框架使用
- 淺談微服務
- TCP性能優化
- 限流實作1
- Redis實作分布式鎖
- Golang原始碼BUG追查
- 事務原子性、一致性、持久性的實作原理
- CDN請求程序詳解
- 記博客服務被壓垮的歷程
- 常用快取技巧
- 如何高效對接第三方支付
- Gin框架簡潔版
- InnoDB鎖與事務簡析
- 演算法總結
- 分布式系統與一致性協議
讀書筆記
- 敏捷革命
- 如何鍛煉自己的記憶力
- 簡單的邏輯學-讀后感
- 熱風-讀后感
- 論語-讀后感
- 孫子兵法-讀后感
思考
- 對專案管理的一些看法
- 對產品經理的一些思考
- 關于程式員職業發展的思考
- 關于代碼review的思考
- Markdown編輯器推薦-typora
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/210400.html
標籤:python