要成為自己的光呀
文章目錄
- 一、查看資料
- 二、線性回歸分析與預測
- 對 baseball_02.csv 里面的資料進行分析,并利用 sklearn 的線性回歸模型預測球隊的表現
- 有關MLB的詳細資訊,請參閱以下中文維基百科頁面: https://bk.tw.lvfukeji.com/wiki/MLB 你也可以看電影《金錢球》,了解奧克蘭田徑隊是如何利用分析來重塑棒球隊的管理的
- 分析和代碼測驗都是在 jupyter notebook 環境中進行的
一、查看資料
# 匯入需要用到的包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import linear_model
%matplotlib inline
# 讀取資料 查看前5行資料
baseball = pd.read_csv('baseball_02.csv')
baseball.head(5)
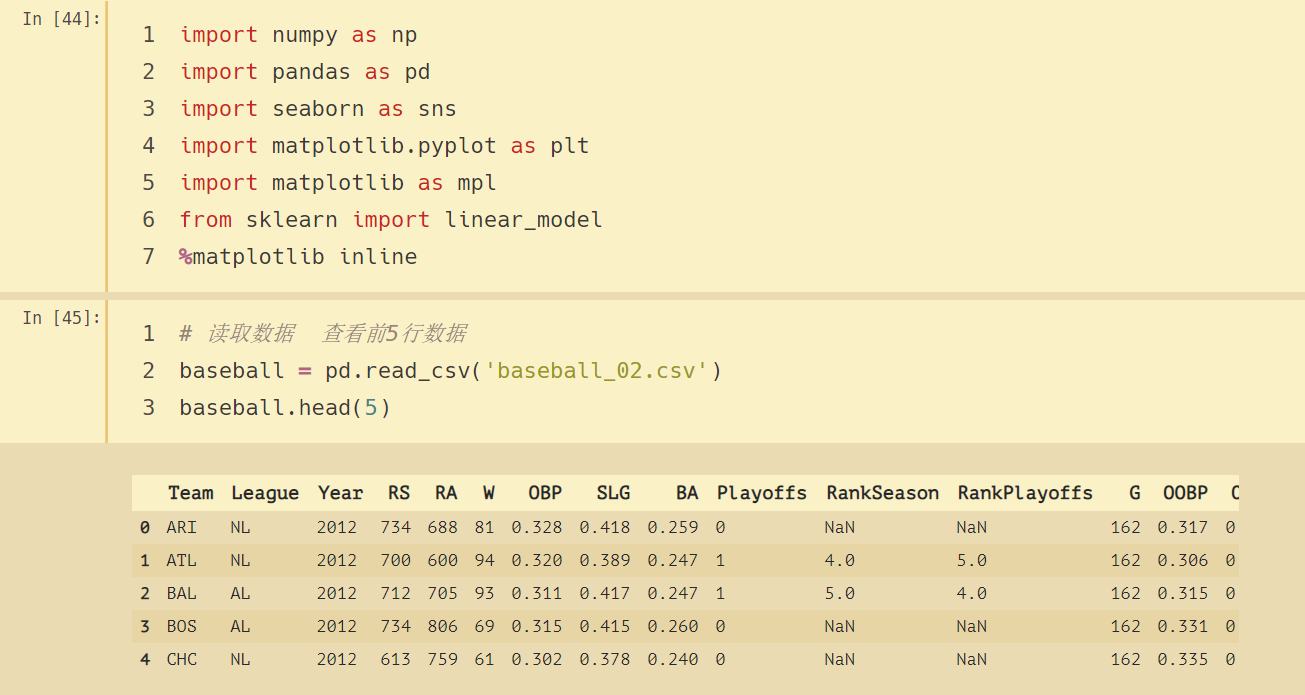
分析時需要用到的欄位的含義
- RS:run scored 得分
- RA:run allowes 失分
- W:win 獲勝次數
- OBP上壘率/打者不出局率:安打數+保送數+觸身球數/打數+保送數+觸身球數
- SLG長打率/衡量打者長打能力:一壘打數+二壘打數2+三壘打數3+全壘打數*4/該打者的打數
- BA打擊率:安打數/打數
- Playoffs 季后賽:0:未進入季后賽 1:進入季后賽
- OOBP:對手的基本百分比
- OSLG:對手的重擊百分比
二、線性回歸分析與預測
第一個預測問題是
一支球隊要在常規賽中贏多少場才能進入季后賽?
現在,你可以將常規賽簡化成一道數學題,利用1995年至2001年的資料繪制散點圖,
# 分組 進入季后賽 與 未進入季后賽分組 統計各自最小的勝投次數
baseball.groupby('Playoffs').min()['W']
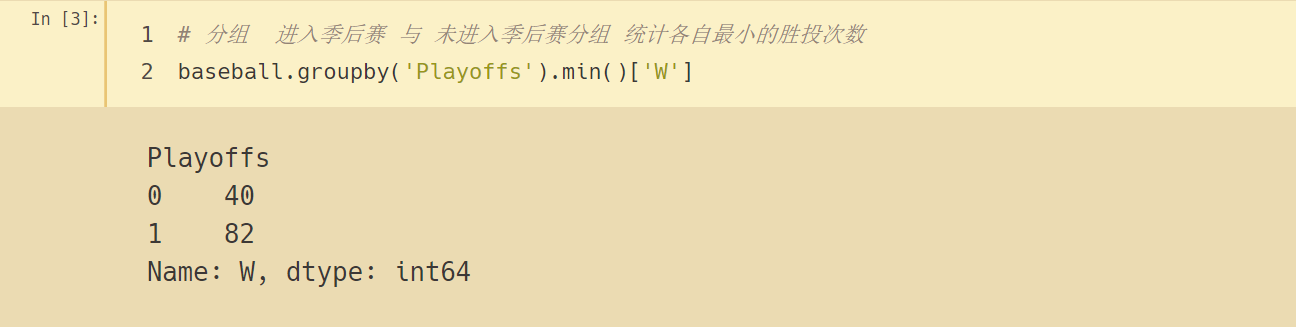
從歷史資料來看,要進入季后賽,至少需要贏 82 場
# 條件篩選 從1995年至2001年且進入季后賽的隊伍 統計這些隊伍的獲勝次數 散點圖可視化
baseball2 = baseball[baseball["Year"]>=1995].copy()
baseball2 = baseball2[baseball2["Year"]<=2001].copy()
baseball2 = baseball2[baseball2["Playoffs"]==1].copy()
plt.figure(figsize=(12, 8), dpi=120)
mpl.rcParams['font.family'] = 'SimHei'
plt.style.use('ggplot')
plt.scatter(range(baseball2.shape[0]),baseball2["W"],color='red')
plt.xlabel('各個隊伍')
plt.ylabel('勝投數')
plt.savefig('test_01.png')
baseball2.shape # (48, 15)
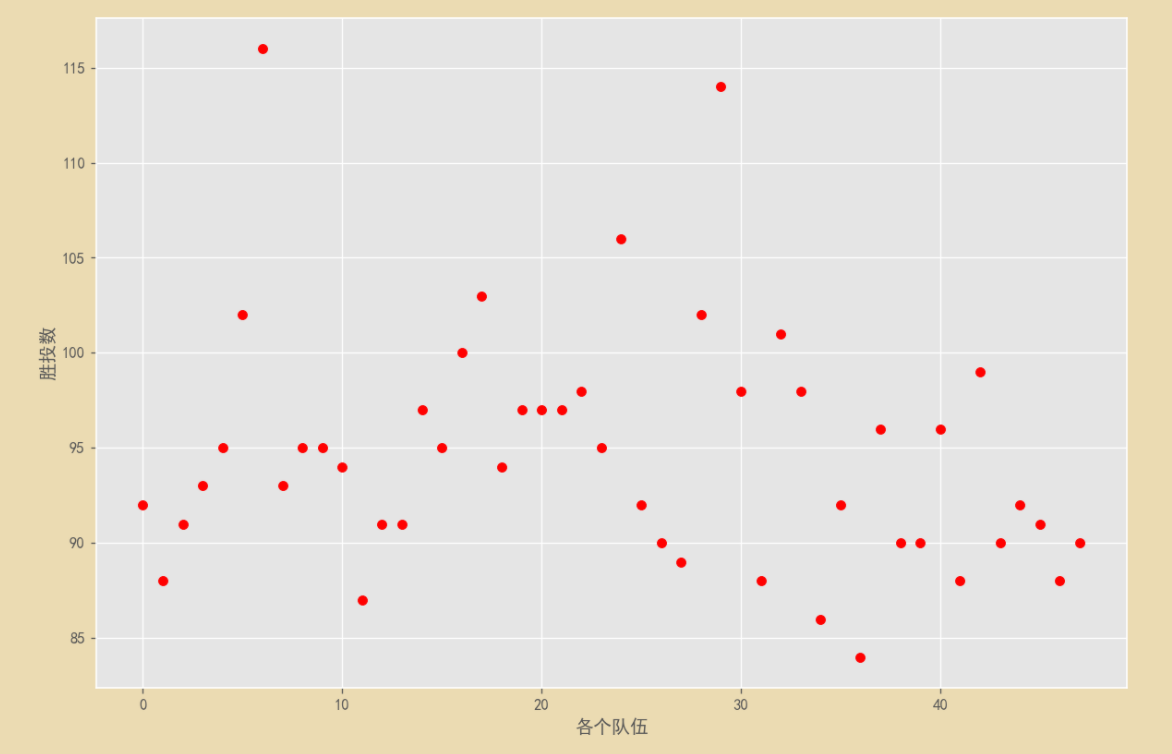
從散點圖容易看出,有一個最小值82,但大部分散點在 85 以上,所以一支球隊要在常規賽中獲勝 85 場以上,進入季后賽的概率很大,
思考一個團隊如何才能取得 X 場勝利
當一個隊的得分比對手多時,它就會獲勝,但是,球隊要贏了多少次?
使用一個線性回歸模型,回答一個問題:如何能使一個球隊獲勝,在常規賽中,它的得分需要比失分多多少分?
首先,您只使用2002年以前的資料
baseball2 = baseball[baseball["Year"]<=2002].copy()
baseball2.head()
為了使問題更簡單,您可以創建一個變數來保存球隊得分和球隊失分的差,
然后,您可以將該變數用作線性回歸模型中的單個自變數,因變數是獲勝次數,
baseball2["newVar"] = baseball2["RS"] - baseball2["RA"]
reg1 = linear_model.LinearRegression()
# 球隊得分和球隊失分的差
x = baseball2["newVar"].values.reshape(-1,1)
# 獲勝次數
y = baseball2["W"].values.reshape(-1,1)
reg1.fit(x,y)
yPred = reg1.predict(x)
# 預測至少勝 85 場進季后賽 在常規賽中,球隊的得分需要比失分多89.858009分
predict_sample = reg1.predict([[85]])
print(predict_sample[0][0])
plt.figure(figsize=(12, 8), dpi=120)
plt.rcParams['axes.unicode_minus']=False # 用于解決不能顯示負號的問題
plt.clf()
# fig,ax = plt.subplots(1,1)
plt.scatter(x,y,label="true",color='blue')
plt.scatter(x,yPred,label="pred",color='red')
plt.xlabel('得分與失分之差')
plt.ylabel('獲勝次數')
plt.savefig('test_02.png') # 保存圖片
plt.legend() # 顯示圖例
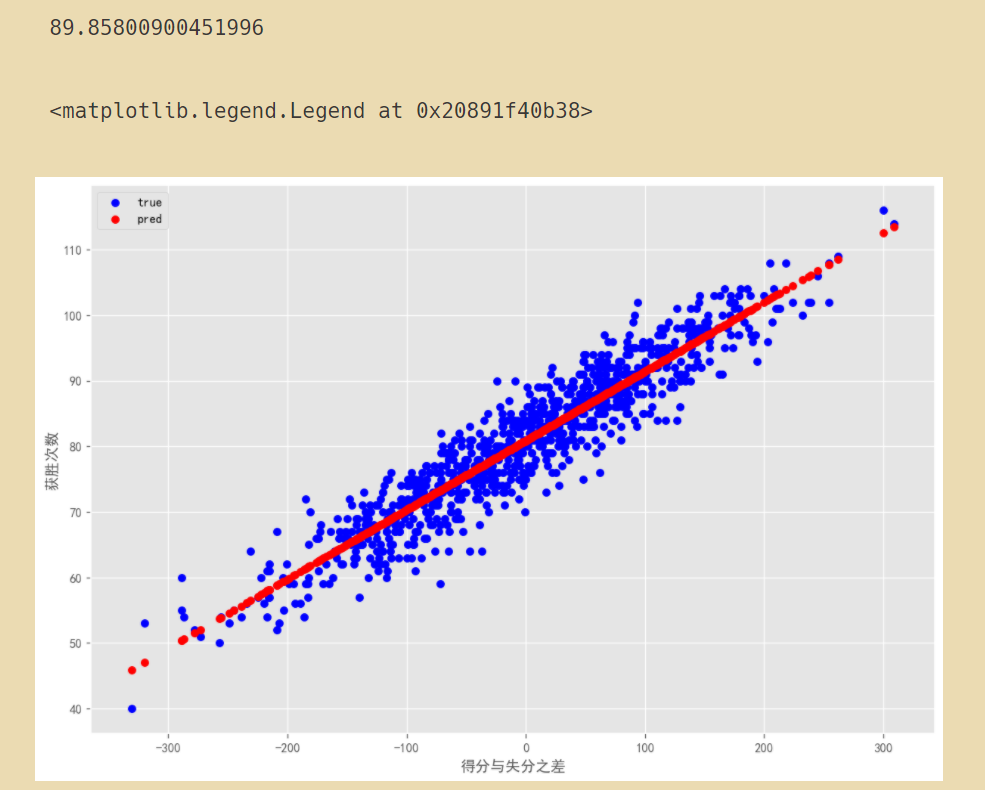
根據擬合的線性回歸模型,如果一支球隊想要贏得 85 場勝利,它球隊的得分比失分需要多大約 90 分,
現在,從上面的線性回歸模型中,你知道一個團隊應該比它允許的 X 勝是多少次,
從本質上講,一支球隊的得分應該超過它允許的獲勝次數,接下來,我們要預測球隊的得分和允許的失分,
關于得分,假設兩個棒球統計資料比其他任何東西都重要:
(1)上壘百分比(OBP):玩家在壘上的時間百分比(包括步行)
(2)重擊百分比(SLG):玩家在回合中繞壘的距離(測量力量)
(3)對于你的回歸模型,你還包括另一個變數,(BA):擊球得分
# 運行一個帶有上述三個變數的線性回歸模型來預測得分
x = baseball2[["OBP","SLG","BA"]].values.reshape(-1,3)
y = baseball2[["RS"]].values.reshape(-1,1)
reg2 = linear_model.LinearRegression()
reg2.fit(x,y)
yPred = reg2.predict(x)
baseball2["3var_pred"] = yPred
baseball2[["OBP","SLG","BA","RS","3var_pred"]].head()

# 運行另一個只有兩個變數的線性回歸模型,OBP和SLG
x = baseball2[["OBP","SLG"]].values.reshape(-1,2)
y = baseball2[["RS"]].values.reshape(-1,1)
reg3 = linear_model.LinearRegression()
reg3.fit(x,y)
yPred = reg3.predict(x)
baseball2["OBP SLG pred"] = yPred
baseball2[["OBP","SLG","RS","OBP SLG pred"]].head()
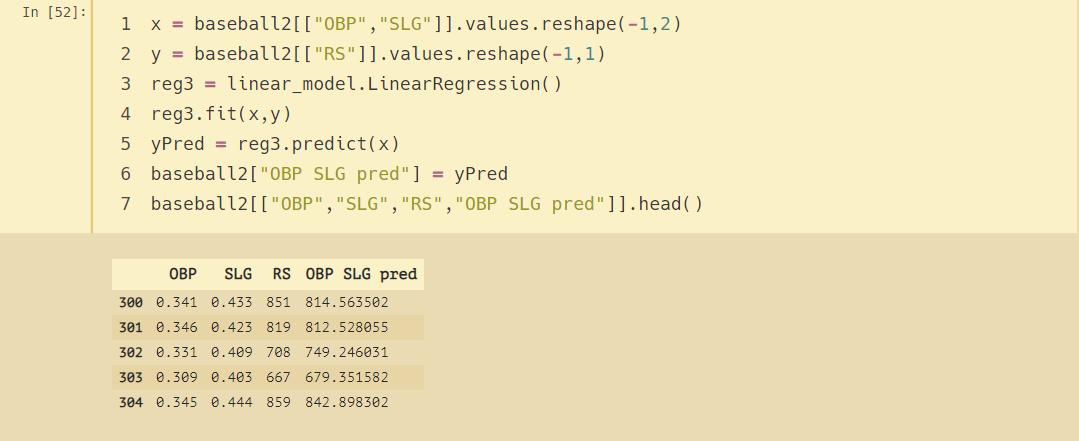
如果一支棒球隊的OBP為0.311,SLG為0.405,我們期望該隊得分多少分?
x = np.array([0.311,0.405]).reshape(-1,2)
var2_Pred = reg3.predict(x)
print(var2_Pred[0][0])

我們可以使用線性回歸模型來預測允許的失分,
使用以下兩個變數,OOBP(對手的基本百分比)和OSLG(對手的重擊百分比),
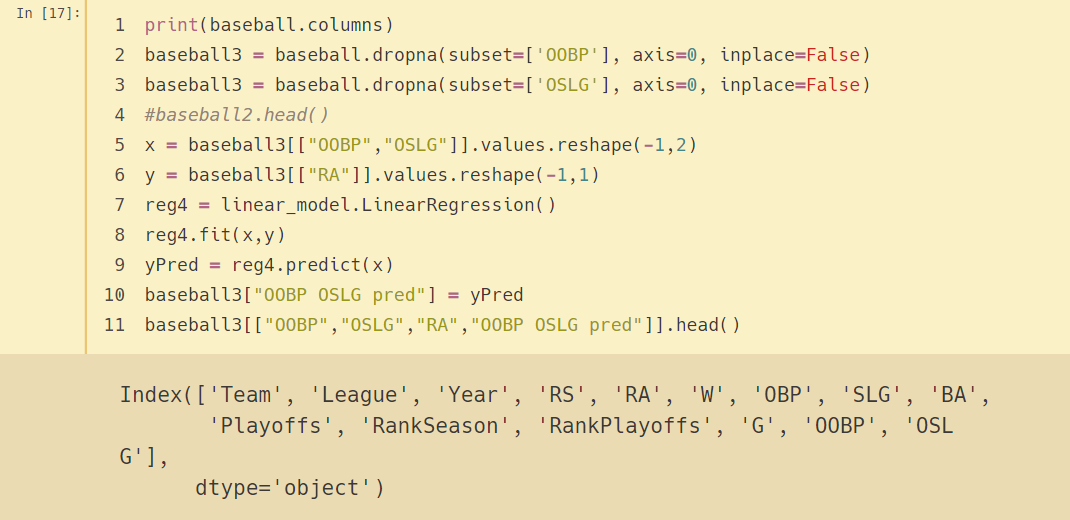
print(baseball.columns)
baseball3 = baseball.dropna(subset=['OOBP'], axis=0, inplace=False)
baseball3 = baseball.dropna(subset=['OSLG'], axis=0, inplace=False)
#baseball2.head()
x = baseball3[["OOBP","OSLG"]].values.reshape(-1,2)
y = baseball3[["RA"]].values.reshape(-1,1)
reg4 = linear_model.LinearRegression()
reg4.fit(x,y)
yPred = reg4.predict(x)
baseball3["OOBP OSLG pred"] = yPred
baseball3[["OOBP","OSLG","RA","OOBP OSLG pred"]].head()

如果一支棒球隊的對手OBP(OOBP)為0.297,對手SLG(OSLG)為0.370,預期球隊允許失分多少?
x = np.array([0.297,0.370]).reshape(-1,2)
yPred = reg4.predict(x)
print(yPred[0][0])

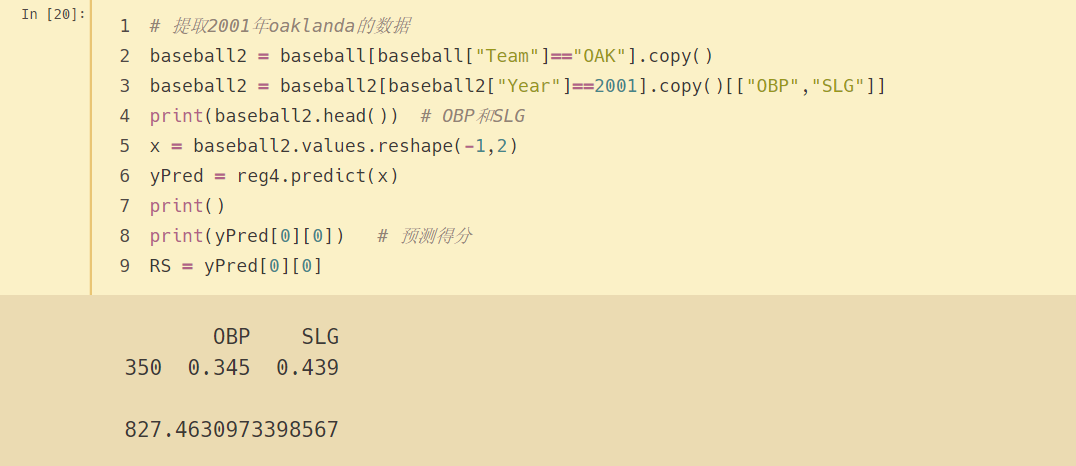
現在讓我們假設我們使用線性回歸模型來預測2002年奧克蘭A隊將贏得多少場比賽
在我們的資料中,‘Team’ 變數中的 OAK 代表oaklanda,
運行的模型使用團隊統計資料,我們將使用 2001 年的團隊統計資料來預測 2002 年的情況,
2001年奧克蘭A隊的 OBP 和 SLG 是多少?根據我們的得分模型,這個隊預計能得分多少?
# 提取2001年oaklanda的資料
baseball2 = baseball[baseball["Team"]=="OAK"].copy()
baseball2 = baseball2[baseball2["Year"]==2001].copy()[["OBP","SLG"]]
print(baseball2.head()) # OBP和SLG
x = baseball2.values.reshape(-1,2)
yPred = reg4.predict(x)
print()
print(yPred[0][0]) # 預測得分
RS = yPred[0][0]
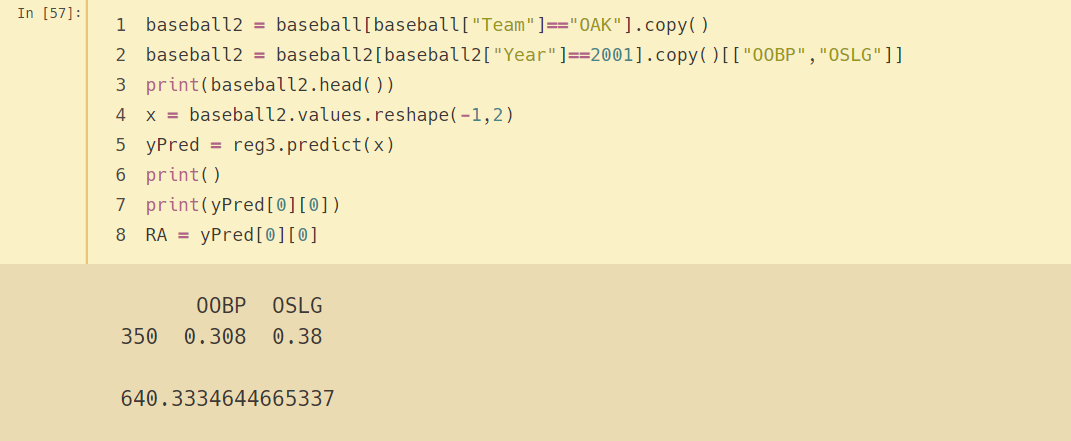
2001年奧克蘭A隊的OOBP和OSLG是多少?根據我們的允許失分模型,該球隊預計失分多少
baseball2 = baseball[baseball["Team"]=="OAK"].copy()
baseball2 = baseball2[baseball2["Year"]==2001].copy()[["OOBP","OSLG"]]
print(baseball2.head())
x = baseball2.values.reshape(-1,2)
yPred = reg3.predict(x)
print()
print(yPred[0][0]) # 預測失分
RA = yPred[0][0]
現在我們已經預測了2002年奧克蘭A的得分和失分,根據預測和我們的獲勝模型,預計球隊會贏多少場?
x = np.array(RS - RA).reshape(-1,1)
wPred = reg1.predict(x)[0][0]
print(wPred)
# 大約會贏101場

根據預測的獲勝次數,你預測球隊是否會在2002年進入季后賽?
這支球隊會在2002年進入季后賽,根據線性回歸模型預測出的獲勝的場數約為101場,大于85,
從我們的資料中,你可以了解2002年奧克蘭A隊的實際表現,
你認為你的預測在得分、允許跑數和獲勝數方面是否接近實際表現?
oak2002 = baseball[baseball["Team"]=="OAK"].copy()
oak2002 = oak2002[oak2002["Year"]==2002].copy()
print(f'Playoffs:{oak2002["Playoffs"].values}')
print("事實 RS:%.2f RA:%.2f W:%.2f"%(oak2002["RS"],oak2002["RA"],oak2002["W"]))
print("預測 RS:%.2f RA:%.2f W:%.2f"%(RS,RA,wPred))
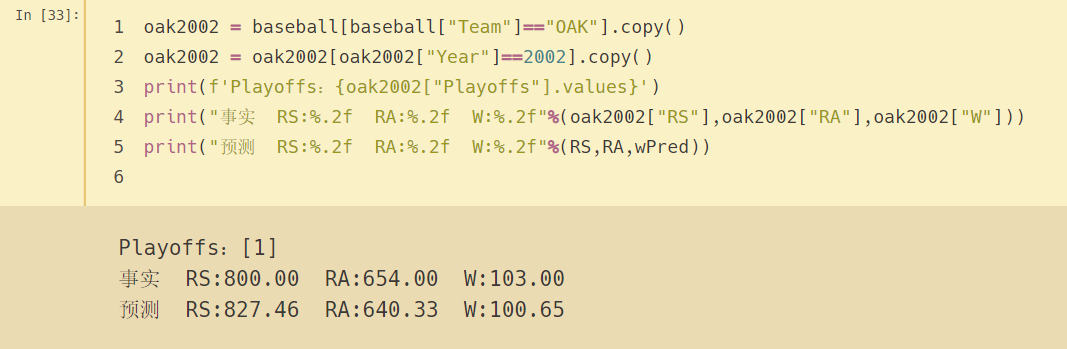
這支球隊2020年的確進入季后賽了,預測的得分、失分、獲勝場數與真實資料相比差異不大,因為每年團隊層面的差異并不大
所以用2001年的資料來預測2002年的資料也不會有太大的差異,誤差較小,

作者:葉庭云
CSDN:https://blog.csdn.net/fyfugoyfa
本文僅用于交流學習,未經作者允許,禁止轉載,更勿做其他用途,違者必究,
文章對你有所幫助的話,歡迎給個贊或者 star 呀,你的支持是對作者最大的鼓勵,不足之處可以在評論區多多指正,交流學習呀,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/212865.html
標籤:python