前言
資料結構,一門資料處理的藝術,精巧的結構在一個又一個演算法下發揮著他們無與倫比的高效和精密之美,在為資訊技術打下堅實地基的同時,也令無數開發者和探索者為之著迷,
也因如此,它作為博主大二上學期最重要的必修課出現了,由于大家對于上學期C++系列博文的支持,我打算將這門課的筆記也寫作系列博文,既用于整理、消化,也用于同各位交流、展示資料結構的美,
此系列文章,將會分成兩條主線,一條“資料結構基礎”,一條“資料結構拓展”,“資料結構基礎”主要以記錄課上內容為主,“拓展”則是以課上內容為基礎的更加高深的資料結構或相關應用知識,
歡迎關注博主,一起交流、學習、進步,往期的文章將會放在文末,
基于圖的基礎概念,要在計算機中存盤一個圖,需要保存這個圖的點集和邊集,
保存所有節點的資訊是容易的,節點總是有編號或者可編號的,因此可以考慮使用鏈表或者線性表來存盤和快速檢索節點資訊,
大多數情況下對圖不涉及頻繁的增刪節點,而是頻繁的檢索各個節點的資訊,所以還是推薦使用陣列來存盤接地那資訊,
相較于節點,保存邊集總不是那么容易,一方面邊不能脫離節點單獨存盤,一條邊連接兩個節點,是兩個節點間的一個關系;另一方面,邊集的規模比較大,在沒有重邊的情況下,完全無向圖邊的數量為 C n 2 = n ( n + 1 ) 2 C^2_n=\frac{n(n+1)}{2} Cn2?=2n(n+1)?條邊,這個規模是 n 2 n^2 n2級別,如果選擇了不恰當的存盤結構,冗余的空間將會是巨大的浪費,
那么這一節,我們將介紹兩種存盤圖的方法:鄰接矩陣和鄰接表
鄰接矩陣
鄰接矩陣是使用一個 n ? n n*n n?n的矩陣 A = ( a i j ) A=(a_{ij}) A=(aij?)來表示一張圖,用矩陣中的每一個元素就表示了一對點之間的邊資訊,
無權圖的鄰接矩陣
對于無權圖,鄰接矩陣有:
- a i j = 0 a_{ij}=0 aij?=0,節點i和節點j之間不存在邊
- a i j = 1 a_{ij}=1 aij?=1,節點i和節點j之間有一條邊由i指向j
對于下面的有向圖:
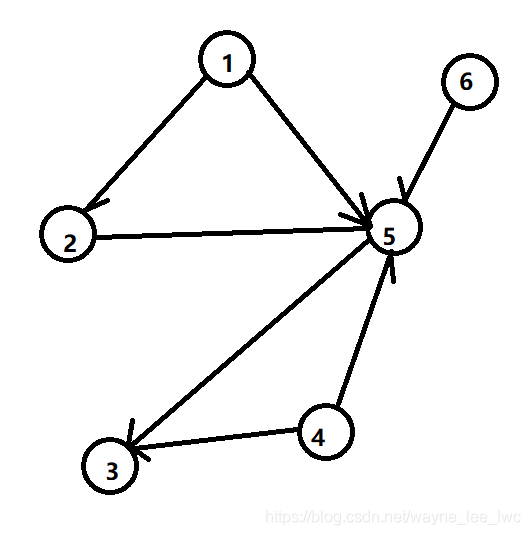
其鄰接矩陣為:
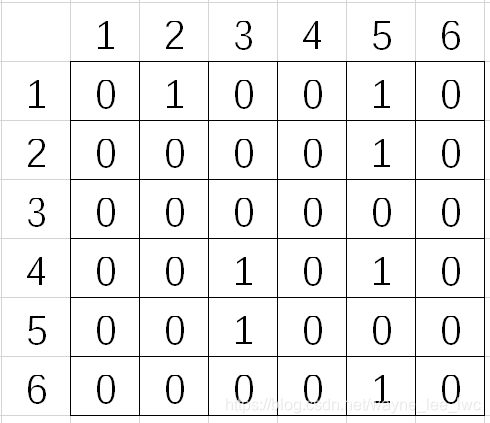
從該圖中我們可以看到,由于不存在指向自己的邊,所以矩陣的主對角元素都是0
對于如下無向圖:
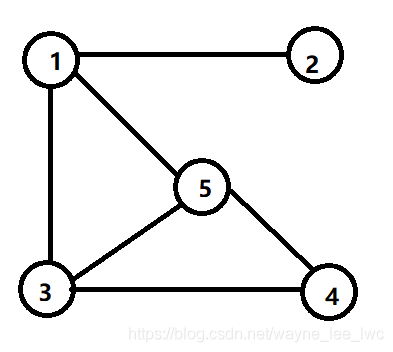
其鄰接矩陣為:
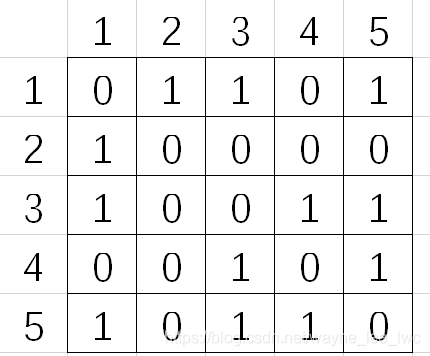
可以發現,對于無向圖,鄰接矩陣總是對稱的,如果節點i和節點j之間存在無向邊,則
a
i
j
=
a
j
i
=
1
a_{ij}=a_{ji}=1
aij?=aji?=1,這個也給了我們一個啟示,即無向邊可以看作兩條方向相反的兩條有向邊,
代碼實作
在程式中,完全可以使用二維陣列來模擬矩陣,我們用矩陣a[i][j]來表示 a i j a_{ij} aij?,
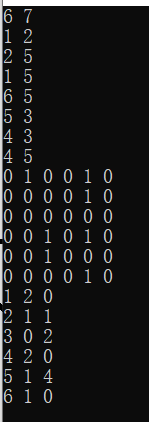
例如,統計一張圖每個結點的入度和出度:
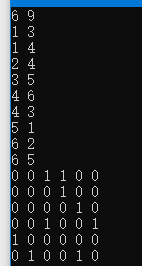
輸入格式:首行為兩個整數n,m表示圖中點的數量和邊的數量,接下來m行,每行兩個整數i和j,代表一條有向邊從i指向j
輸出格式:輸出包含2*n行,前n行為該圖的鄰接矩陣,后n行每行三個整數k,a,b,k表示結點編號,a為該節點入讀,b為出度
#include<stdio.h>
int a[100][100];
int main(){
int n,m;
scanf("%d%d",&n,&m);
for(int i = 0,x,y;i < m;i++){
scanf("%d%d",&x,&y);
a[x][y] = 1;
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
printf("%d ",a[i][j]);
}
printf("\n");
}
for(int i = 1,rd,cd;i <= n;i++){
rd = 0;
for(int j = 1;j <= n;j++){
rd += a[i][j];
}
cd = 0;
for(int j = 1;j <= n;j++){
cd += a[j][i];
}
printf("%d %d %d\n",i,rd,cd);
}
}
運行結果如下:
有權圖的鄰接矩陣
對于有權圖來說,僅僅記錄兩個結點之間是否存在邊已經不足以記錄足夠的資訊了,還需要記錄這些邊的權重,于是不妨規定:
- a i j = ∞ a_{ij}=\infty aij?=∞,節點i和節點j之間沒有邊
- a i i = 0 a_{ii}=0 aii?=0
- a i j = v a l a_{ij}=val aij?=val,節點i和節點j之間存在邊,權重為val
例如對下面的權圖:
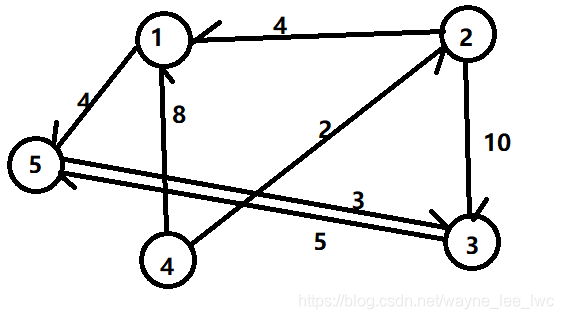
其鄰接矩陣為:
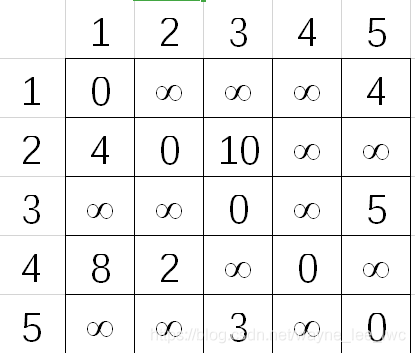
對于無窮大的設定,一般來說,可以取int的上限,起到標記的作用,其本質是取一個邊權值無法達到的一個值,通常取一個大值,這樣便于后續有關圖演算法的設計,
代碼實作
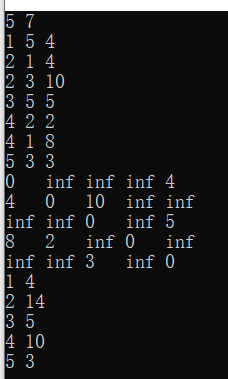
例如,統計一張有向有權圖每個結點的出度邊權和:
輸入格式:首行為兩個整數n,m表示圖中點的數量和邊的數量,接下來m行,每行兩個整數i,j和v,代表一條有向邊從i指向j,權值為v
輸出格式:輸出包含2*n行,前n行為該圖的鄰接矩陣,后n行每行三個整數k,a,k表示結點編號,a為出度邊權和
#include<stdio.h>
int a[100][100];
const int inf = 1 << 30;
int main(){
int n,m;
scanf("%d%d",&n,&m);
for(int i = 1;i <= n;i++){
for(int j = 0;j <= n;j++){
a[i][j] = i == j ? 0 : inf;
}
}
for(int i = 0,x,y,v;i < m;i++){
scanf("%d%d%d",&x,&y,&v);
a[x][y] = v;
}
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
if(a[i][j] == inf){
printf("inf ");
}else{
printf("%-4d",a[i][j]);
}
}
printf("\n");
}
for(int i = 1,cd;i <= n;i++){
cd = 0;
for(int j = 1;j <= n;j++){
cd += a[i][j] == inf ? 0 : a[i][j];
}
printf("%d %d\n",i,cd);
}
}
鄰接表
不難發現使用鄰接矩陣存盤圖結構由于需要表示每一個可能存在的邊,需要開 n 2 n^2 n2個空間,當圖中點較多且較為稀疏時,這樣的存盤方式將會是極大地浪費,
此時可以使用鄰接表來存盤圖結構
鄰接表的思想簡單來說就是為每一個節點提供一個長度可變的線性結構,每添加一個新邊,就放置在線性表后面,而這個長度可變的線性結構通常使用鏈表來實作,
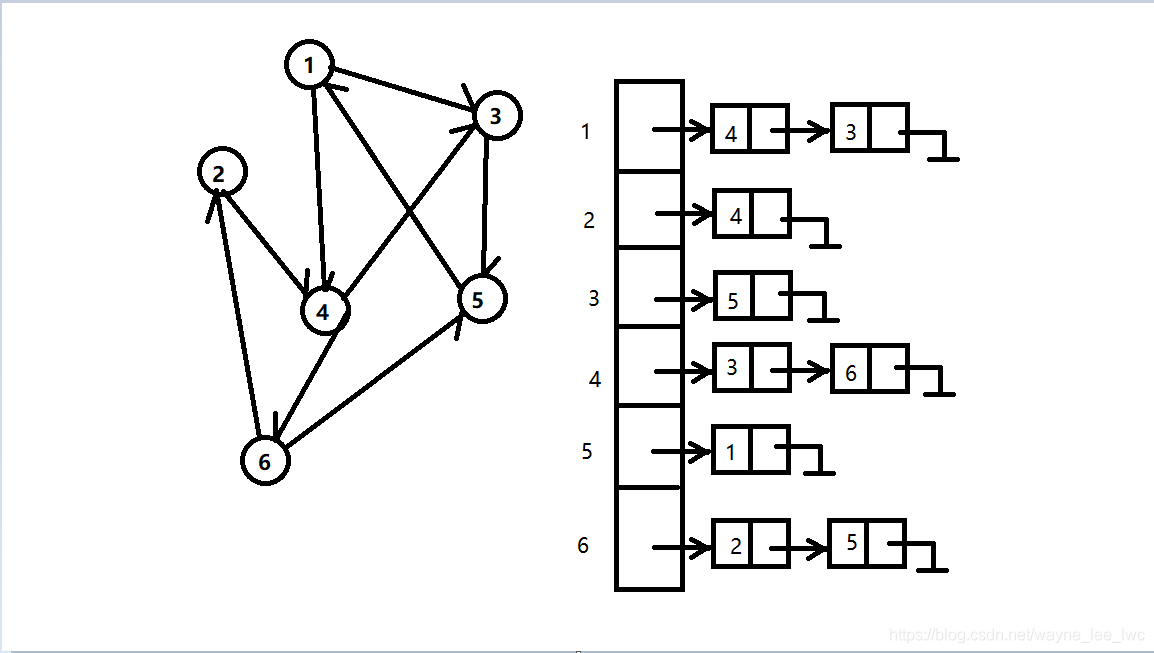
它的鄰接矩陣為:
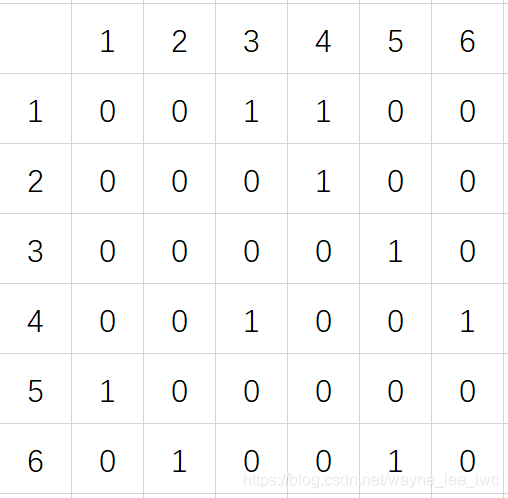
其實對比觀察不難發現,鄰接表就是將鄰接矩陣每一行中的“1”用鏈表串聯起來且不分順序,
代碼實作
首先,使用鄰接表存盤邊資訊,其結構為鏈表,所以每個鏈節點除了要存盤指向節點的之外至少需要有next指標,為什么是至少呢?因為一條邊可能還有邊權等等其他欄位,所以至少是指向節點和next指標,最后一個結點指向NULL
typedef struct _Edge{
int vertex;
struct _Edge * next;
}Edge;
為了存盤鄰接表,還需要一個鏈首陣列存放每個節點鄰接鏈表的鏈首,
Edge * head[N];
則初始化圖的時候需要給head陣列置空:
void init(int n){
for(int i = 1;i <= n;i++){
head[i] = NULL;
}
}
當追加一條邊時,在起點的邊鏈表中插入一個節點,
void link(int x,int y){
Edge * edge = (Edge*)malloc(sizeof(Edge));
edge->vertex = y;
edge->next = head[x];
head[x] = edge;
}
當需要遍歷一個結點的以其為起點的邊時,使用指標進行迭代:
void getEdges(int k){
for(Edge* edge = head[k];edge != NULL;edge = edge->next){
printf("%d ",edge->vertex);
}
}
//node != NULL 可簡寫為node
示例:
輸入格式:第一行為兩個整數n,m代表結點個數和邊的數量,接下來m行,每行兩個整數,表示邊的起點和終點,
輸出格式:該圖的鄰接矩陣
#include<stdio.h>
#include<malloc.h>
const int N = 1000;
typedef struct _Edge{
int vertex;
struct _Edge * next;
}Edge;
Edge * head[N];
int matrix[N][N];
void link(int x,int y){
Edge * edge = (Edge*)malloc(sizeof(Edge));
edge->vertex = y;
edge->next = head[x];
head[x] = edge;
}
int main(){
int n,m;
scanf("%d%d",&n,&m);
//初始化鄰接表
for(int i = 1;i <= n;i++){
head[i] = NULL;
}
//讀入邊
for(int i = 0,x,y;i < m;i++){
scanf("%d%d",&x,&y);
link(x,y);
}
//構建鄰接矩陣
for(int i = 1;i <= n;i++){
for(Edge * edge = head[i];edge;edge = edge->next){
matrix[i][edge->vertex] = 1;
}
}
//列印鄰接矩陣
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
printf("%-2d",matrix[i][j]);
}
printf("\n");
}
}
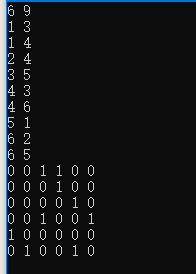
當圖無向時,可以將一條無向邊轉化為兩條方向相反的有向邊進行存盤,
...
scanf("%d%d",&x,&y);
link(x,y);
link(y,x);
...
當邊具有邊權等其他欄位時,需要在邊結構體中加入對應欄位定義,并在創建邊的時候將這些屬性賦予邊,
void link(int x,int y,int len...){
Edge * edge = (Edge*)malloc(sizeof(Edge));
edge->vertex = y;
edge->len = len;
...
edge->next = head[x];
head[x] = edge;
}
陣列模擬鄰接表
鄰接表很好,但有時候他也會戳到我們的軟肋——動態記憶體管理
每一個存盤的邊都是塊動態記憶體,當圖不再使用的時候能想起來釋放他們總是一件難事,除此之外,當需要頻繁的創建新圖時,不斷地申請和釋放也會占據不少的時間,
那么有沒有靜態記憶體的替代方案呢?答案是肯定的,可以使用陣列來模擬鏈表,
其實說來,就是預先開辟足夠大小的陣列模擬邊結點將會申請到的記憶體,并定義一個指標指向當前可以用的位置,那么邊結點中的next指標含義也變成了下一個邊結點在陣列中的下標
typedef struct _Edge{
int vertex;
int next;
}Edge;
Edge edges[M];
int pointer = 0;
為了表示鏈表中的最后一個元素,我們規定邊結點下標從1開始計數,這樣最后一個元素的next值可以指向0表示結束,
與鄰接表類似,仍需要一個head陣列記錄所有結點邊鏈表的鏈首,只不過這回他不用是指向該節點的指標,而是它在陣列中的下標,
int head[N];
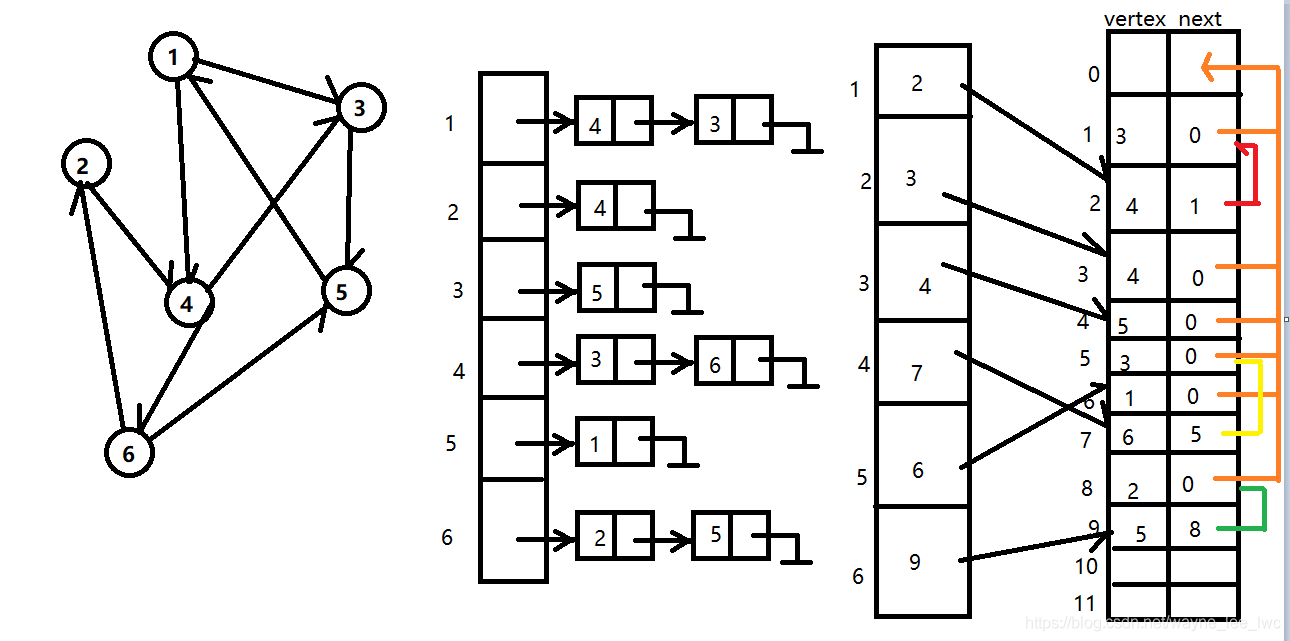
同理,我們需要在初始化時將所有結點邊鏈表置空,前面約定0表示結束,所以在這里就是head陣列置零,計數指標置零
void init(int n){
for(int i = 1;i <= n;i++){
head[i] = 0;
}
pointer = 0;
}
當添加一個元素時,直接將指標后移一個指向新邊結點,新節點的插入和鏈表插入操作類似,方便的是,給結構體賦值可以使用大括號式:
void link(int x,int y){
nodes[++pointer] = {y,head[x]};
head[x] = pointer;
}
遍歷時,同樣采用迭代的方式:
void getEdge(int k){
for(int i = head[k];i;i = edges[i].next){
....
}
}
用這種形式,再來實作一下上面的示例:
#include<stdio.h>
const int N = 1000;
const int M = 10000;
typedef struct _Edge{
int vertex;
int next;
}Edge;
Edge edges[M];
int head[N];
int pointer;
int matrix[N][N];
void link(int x,int y){
edges[++pointer] = {y,head[x]};
head[x] = pointer;
}
int main(){
int n,m;
scanf("%d%d",&n,&m);
//初始化鄰接表
for(int i = 1;i <= n;i++){
head[i] = 0;
}
//讀入邊
for(int i = 0,x,y;i < m;i++){
scanf("%d%d",&x,&y);
link(x,y);
}
//構建鄰接矩陣
for(int i = 1;i <= n;i++){
for(int j = head[i];j;j = edges[j].next){
matrix[i][edges[j].vertex] = 1;
}
}
//列印鄰接矩陣
for(int i = 1;i <= n;i++){
for(int j = 1;j <= n;j++){
printf("%-2d",matrix[i][j]);
}
printf("\n");
}
}
往期博客
- 【資料結構基礎】資料結構基礎概念
- 【資料結構基礎】線性資料結構——線性表概念 及 陣列的封裝
- 【資料結構基礎】線性資料結構——三種鏈表的總結及封裝
- 【資料結構基礎】線性資料結構——堆疊和佇列的總結及封裝(C和java)
- 【演算法與資料結構基礎】模式匹配問題與KMP演算法
- 【資料結構與演算法基礎】二叉樹與其遍歷序列的互化 附代碼實作(C和java)
- 【資料結構與演算法拓展】 單調佇列原理及代碼實作
參考資料:
- 《資料結構》(劉大有,楊博等編著)
- 《演算法導論》(托馬斯·科爾曼等編著)
- 《圖解資料結構——使用Java》(胡昭民著)
- OI WiKi
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/213104.html
標籤:java
上一篇:資料在記憶體中的存盤