歡迎訪問我的GitHub
https://github.com/zq2599/blog_demos
內容:所有原創文章分類匯總及配套原始碼,涉及Java、Docker、Kubernetes、DevOPS等;
在學習和開發flink的程序中,經常需要準備資料集用來驗證我們的程式,阿里云天池公開資料集中有一份淘寶用戶行為資料集,稍作處理后即可用于flink學習;
下載
-
下載地址:
https://tianchi.aliyun.com/dataset/dataDetail?spm=a2c4e.11153940.0.0.671a1345nJ9dRR&dataId=649 -
如下圖所示,點擊紅框中的圖示下載(名為UserBehavior.csv.zip的檔案太大無法在excel打開,因此下載體積小一些的UserBehavior.csv):
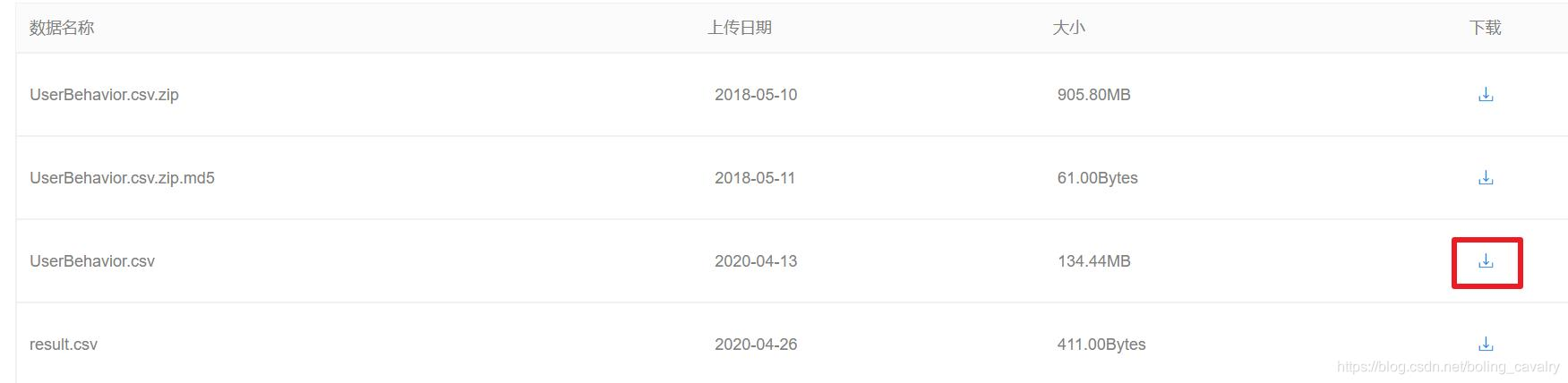
-
該CSV檔案的內容,一共有五列,每列的含義如下表:
| 列名稱 | 說明 |
|---|---|
| 用戶ID | 整數型別,序列化后的用戶ID |
| 商品ID | 整數型別,序列化后的商品ID |
| 商品類目ID | 整數型別,序列化后的商品所屬類目ID |
| 行為型別 | 字串,列舉型別,包括('pv', 'buy', 'cart', 'fav') |
| 時間戳 | 行為發生的時間戳 |
| 時間字串 | 根據時間戳欄位生成的時間字串 |
- 下載完畢后用excel打開,如下圖所示:
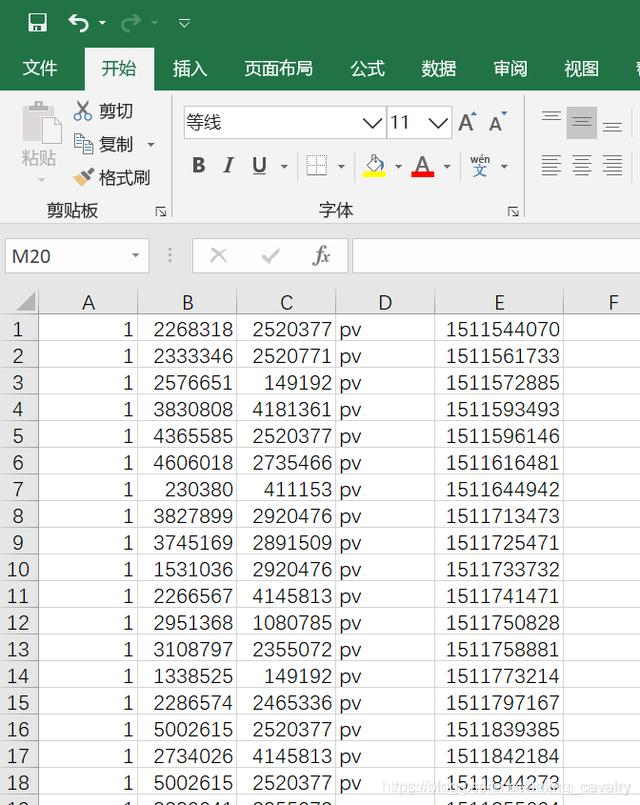
增加一個欄位
為了便于檢查資料,接下來在時間戳欄位之后新增一個欄位,內容是將該行的時間戳轉成時間字串
- 如下圖,在F列的第一行位置輸入運算式,將E1的時間戳轉成字串:
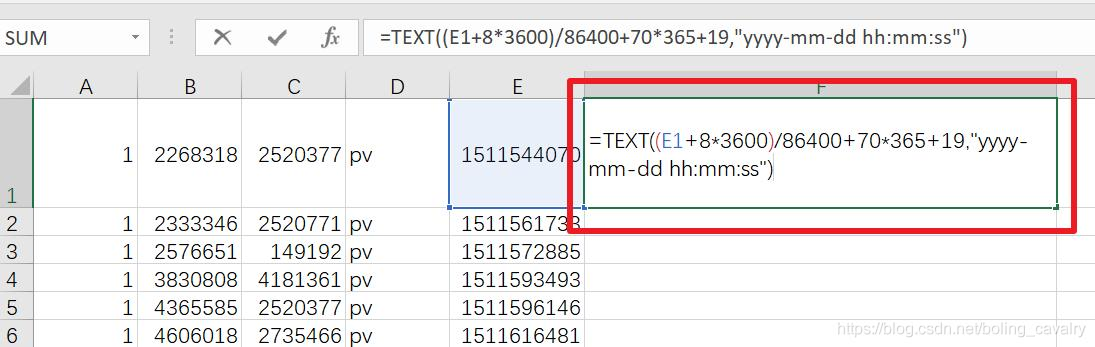
- 上圖紅框中的運算式內容如下:
=TEXT((E1+8*3600)/86400+70*365+19,"yyyy-mm-dd hh:mm:ss")
- !!!有個問題要格外注意!!!:上述運算式中,由于8*3600的作用,得到的時間字串實際上是東八區時區的時間,在flink sql中,如果用DATE_FORMAT函式計算timestamp也能得到時間字串,但是這個字串是格林尼治時區,此時兩個時間字串的值就不同了,例如從F列看2017/11/12和2017/11/13各一條記錄,但是DATE_FORMAT函式計算timestamp得到的卻是2017/11/12有兩條記錄,解決這個問題的辦法就是將運算式中的8*3600去掉,大家都用格林尼治時區;
- 運算式生效后,F1的內容就是E1的時間字串,接下來F列的所有記錄都作轉換,滑鼠放在下圖紅框位置時,會出現十字架標志,在此標志上雙擊滑鼠:
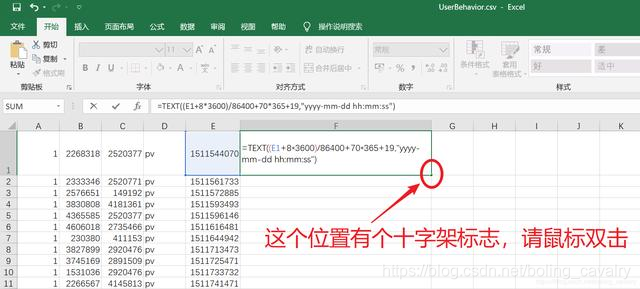
5. 完成后如下圖,F列的時間資訊更利于我們開發程序中核對資料:
修復亂序
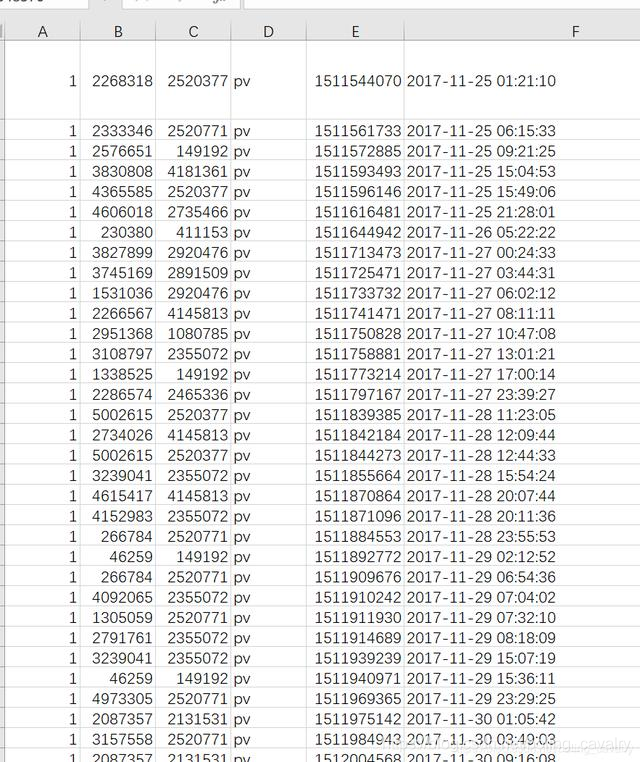
- 此時的CSV檔案中的資料并不是按時間欄位排序的,如下圖:
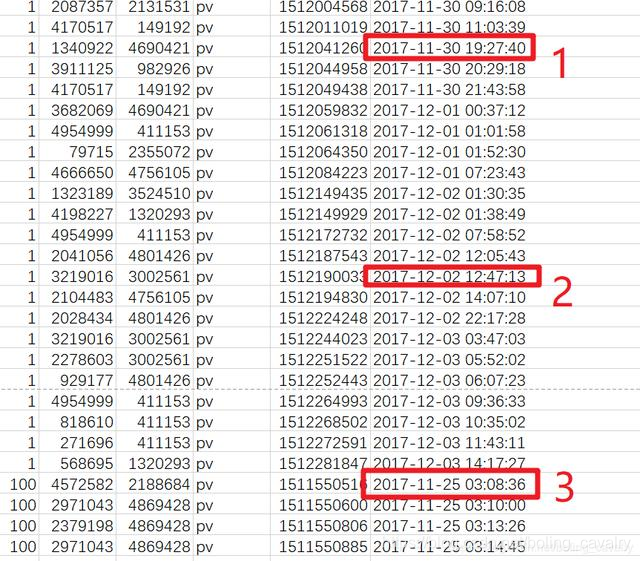
- flink在處理上述資料時,由于亂序問題可能會導致計算結果不準,以上圖為例,在處理紅框2中的資料時,紅框3所對應的視窗早就完成計算了,雖然flink的watermark可以容忍一定程度的亂序,但是必須將容忍時間調整為7天才能將紅框3的視窗保留下來不觸發,這樣的watermark調整會導致大量資料無法計算,因此,需要將此CSV的資料按照時間排序再拿來使用;
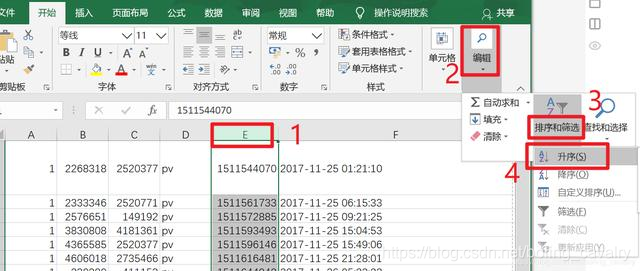
- 如下圖操作即可完成排序:
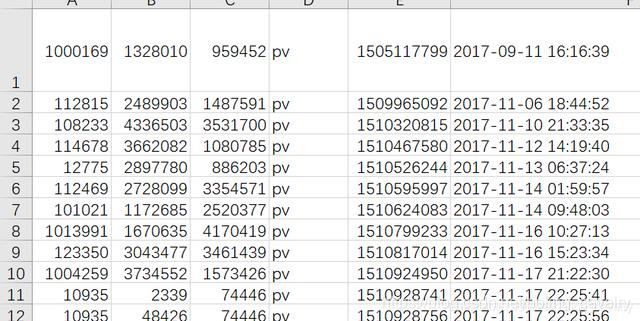
4. 完成排序后如下圖所示:
至此,一份淘寶用戶行為資料集就準備完畢了,接下來的文章將會用此資料進行flink相關的實戰;
直接下載準備好的資料
- 為了便于您快速使用,上述調整過的CSV檔案我已經上傳到CSDN,地址:
https://download.csdn.net/download/boling_cavalry/12381698 - 也可以在我的Github下載,地址:
https://raw.githubusercontent.com/zq2599/blog_demos/master/files/UserBehavior.7z
歡迎關注公眾號:程式員欣宸
微信搜索「程式員欣宸」,我是欣宸,期待與您一同暢游Java世界...
https://github.com/zq2599/blog_demos
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/215154.html
標籤:其他