
論文:TDAN:視頻超分中的時空可變形對齊網路
文章檢索出處:2020 Conference on Computer Vision and Pattern Recognition(CVPR)
摘要和簡介
先前的VSR通常使用光流的方法進行對齊,所以模型的性能將高度依賴光流的精度,不正確的光流將會導致支持幀中包含偽影,進而影響重建的HR幀,本文中提出了一種時間可變形對齊網路(TDAN),它使用參考幀和支持幀的特征來動態預測采樣卷積核的offsets,使得它可以在不計算光流的情況下自適應的對齊參考幀和支持幀,本文的貢獻包括三個方面:
(1)我們提出了一種用于特征級對齊的新型時間可變形對齊網路(TDAN),它避免了以前基于光流的方法所采用的兩階段程序;
(2)我們提出了基于TDAN的端到端可培訓VSR框架;
(3)我們的方法在Vid4基準資料集上實作了sotr, 源代碼和預訓練的模型發布于 https://github.com/YapengTian/TDAN-VSR-CVPR-2020,
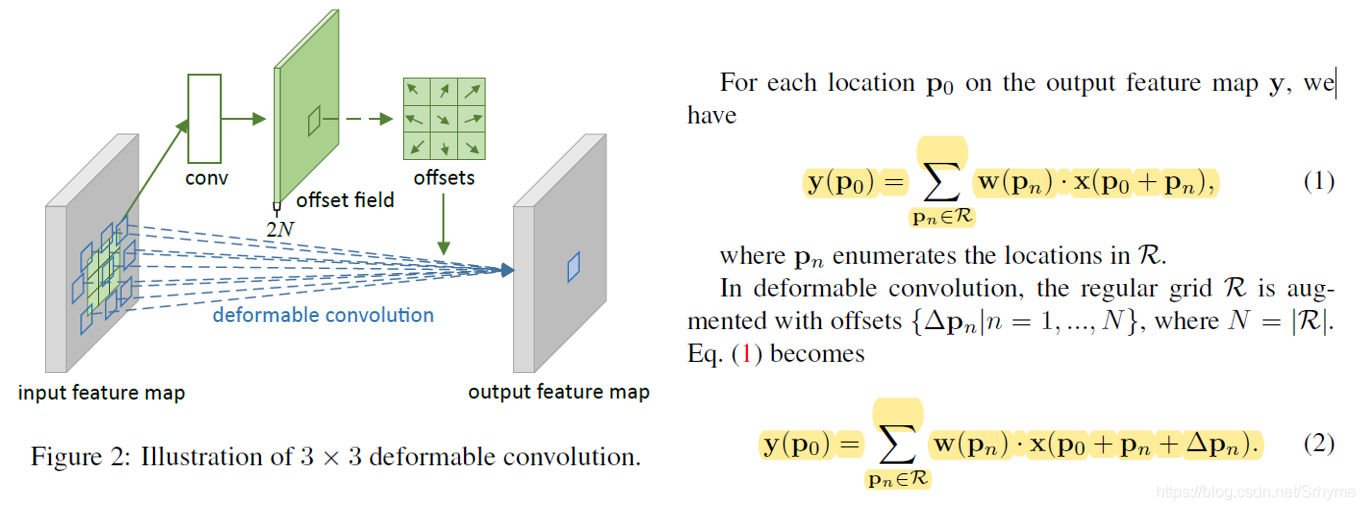
可變形卷積
相比conv2d引入了學習空間幾何形變的能力,通過學習引數 Δ p n \Delta p_n Δpn?從而能更好地解決具有空間形變的影像識別任務,
概述
模型將連續的2N+1幀 { I i L R } i = t + N t + R \{{I^{LR}_i}\}^{t+R}_{i=t+N} {IiLR?}i=t+Nt+R? 作為輸入去預測HR幀 I t H R I^{HR}_t ItHR?,它由兩個子網路構成: temporally deformable alignment network (TDAN) 和 SR reconstruction network,
TDAN將支持幀 I i L R I^{LR}_i IiLR? 和參考幀 I t L R I^{LR}_t ItLR?作為輸入,以預測支撐幀對應的對齊幀 I i L R ′ I^{LR'}_i IiLR′?,I i L R ′ = f T D A N ( I t L R , I i L R ) I^{LR'}_i = f_{TDAN}(I^{LR}_t,I^{LR}_i) IiLR′?=fTDAN?(ItLR?,IiLR?)
向TDAN輸入2N個支持幀后,我們可以獲得2N個相應的對齊幀 { I t ? N L R ′ , . . . , I t ? 1 L R ′ , I t L R , I t + 1 L R ′ . . . , I t + N L R ′ I^{LR'}_{t-N},...,I^{LR'}_{t-1},I^{LR}_{t},I^{LR'}_{t+1}...,I^{LR'}_{t+N} It?NLR′?,...,It?1LR′?,ItLR?,It+1LR′?...,It+NLR′?},然后SR重建網路將利用2N個對齊幀以及參考幀來還原HR視頻幀,
I t H R = f S R ( I t ? N L R ′ , . . . , I t ? 1 L R ′ , I t L R , I t + 1 L R ′ , . . . , I t + N L R ′ ) I^{HR}_t = f_{SR}(I^{LR'}_{t-N},...,I^{LR'}_{t-1},I^{LR}_{t},I^{LR'}_{t+1},...,I^{LR'}_{t+N}) ItHR?=fSR?(It?NLR′?,...,It?1LR′?,ItLR?,It+1LR′?,...,It+NLR′?)

Temporally Deformable Alignment Network
TDAN主要包含三個模塊:特征提取、變形對齊和對齊幀重建
特征提取:通過一個共享的特征抽取網路,從 I i L R I^{LR}_i IiLR?和 I t L R I^{LR}_t ItLR?提取視覺特征 F i L R F^{LR}_i FiLR?和 F t L R F^{LR}_t FtLR?,該網路由一個卷積層和 k 1 k_1 k1?個殘差塊(with ReLU)組成,在作者的實作中,他使用了來自EDSR的修正殘差塊結構,提取的特征將用于特征方面的時間對齊,
變形對齊:變形對齊模塊將 F i L R F^{LR}_i FiLR?和 F t L R F^{LR}_t FtLR?作為輸入,concat后使用一個3x3的bottleneck層,目的是減少特征圖的通道數量,然后通過一個卷積層去預測輸出通道數量為|R|的采樣引數 Θ \Theta Θ:Θ = f θ ( F i L R , F t L R ) \Theta = f_{\theta}(F^{LR}_i,F^{LR}_t) Θ=fθ?(FiLR?,FtLR?)
其中, Θ = { Δ p n ∣ n = 1 , . . . , ∣ R ∣ } \Theta = \{ \Delta p_n | n = 1,...,|R| \} Θ={Δpn?∣n=1,...,∣R∣},通過變形卷積,使 Θ \Theta Θ和 F i L R F^{LR}_i FiLR?可以計算出支持幀的對齊特征 F i L R ′ F^{LR'}_i FiLR′?:
F i L R ′ = f d c ( F i L R , Θ ) F^{LR'}_i = f_{dc}(F^{LR}_i,\Theta) FiLR′?=fdc?(FiLR?,Θ)
更具體的:
對于卷積在不規則位置 p n p_n pn?+ Δ p n \Delta p_n Δpn?,其中 Δ p n \Delta p_n Δpn?可能是分數,我們通過雙線性來解決,在實踐中,我們在 f d c f_{dc} fdc?之前和之后添加了三個附加的可變性卷積層,去增強模塊的轉換靈活性和功能,參考幀 F t L R F^{LR}_t FtLR?的特征僅用于計算 Θ \Theta Θ,并不會傳播到支持幀的對其特征中,此外,自適應的學習偏移量將隱式的捕獲運動線索去進行時間對齊,
對齊幀重構:沒有監督的隱式對齊很難學習,所以我們添加對齊損失去強制可變性對齊模塊更加精確,對齊后的特征圖通過一個3x3的卷積層完成幀的重建,
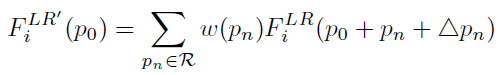
Aligned Frame Reconstruction
SR重建網路包含三個模塊:時間融合、非線性映射和HR幀重構
時間融合:要融合跨時空的不同幀,我們直接將2N + 1幀連接起來,然后將它們輸入3x3卷積層以輸出融合的特征圖,
非線性映射:具有 k 2 k_2 k2?個堆疊殘差塊的非線性映射(EDSR)模塊將采用隱式融合特征作為輸入來預測深度特征,
HR幀重建:在LR空間中提取了深層特征后,我們利用ESPCN,通過亞像素卷積來提高特征圖的解析度,實際上,對于4個放大比例,將使用兩個子像素卷積模塊, 最終的HR幀$ I t H R I^{HR}_t ItHR? 通過卷積層從縮放后的特征圖中獲取,
損失函式
兩個損失函式 L a l i g n L_{align} Lalign?和 L s r L_{sr} Lsr?分別用于訓練TDAN和SR重建網路,
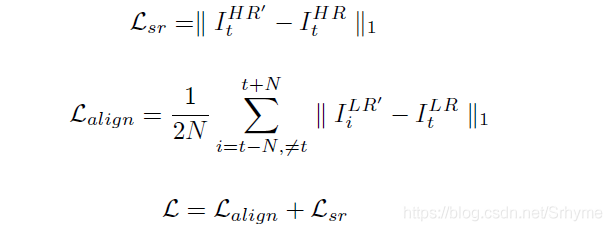
實施
資料集:Vimeo 90k視頻采樣成(64612,448,256)的格式
驗證集:Temple sequence的31影像
測驗集:Vid4、SPMCs-30,前兩個幀不用于評估,并且忽略了四個空間邊界像素
對比模型:VSRnet,ESPCN,VESCPN,TOFlow,DBPN,RND,RCAN,SPMC,FSRVSR 和DUF-16L ,
訓練設定:輸入shape(64,5, 48, 48,3), k 1 k_1 k1? = 5, k 2 k_2 k2? = 10,Adam優化器,在1080TI上每100個epochs大約需要1.7天,
實驗效果和量化評估
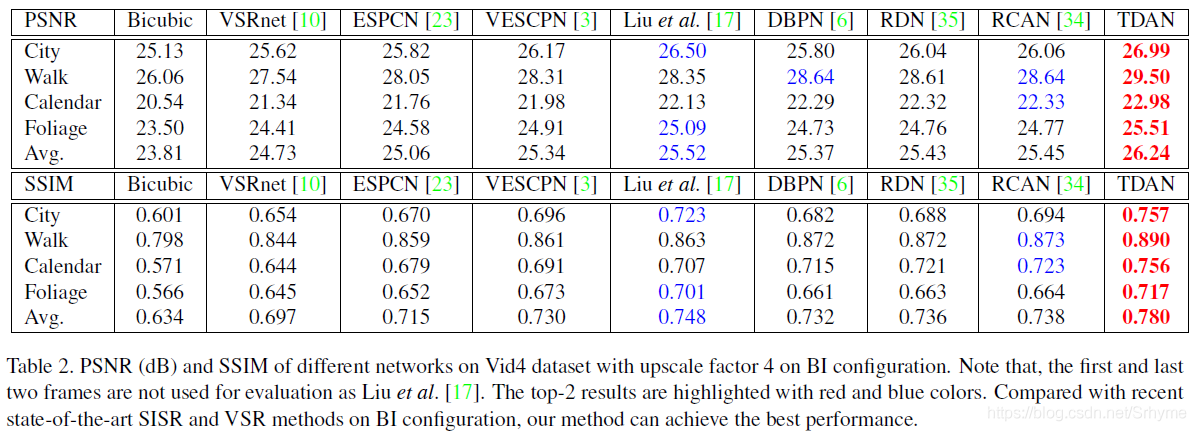
在經過BI處理過的Vid4測驗集上:
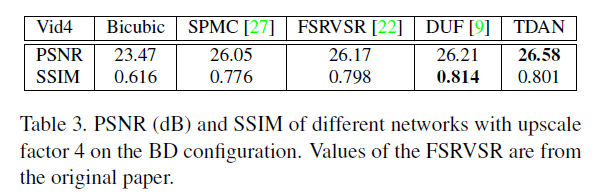
在經過BD處理過的Vid4測驗集上:
輸出影像對比:

原創文章,如需轉載請注明出處,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/22032.html
標籤:java
上一篇:陣列元素的目標和