不識有話說
作為一個爬蟲萌新,第一個小專案當然是爬一爬我們的萌新之友-《新筆趣閣》
雖然沒什么難度,
不過還是分享一下自己的代碼歷程,
希望能給予大家一些思路或幫助,
當然,如果有大佬能夠指出錯誤或可以改進的地方,
那當然更好了,
等你呦~
專案展示
在講解專案之前,
先給你們展示一下功能,
不然看了半天,
結果不是自己想要的那不是自閉了,
<----------------------------------分割線------------------------------------->

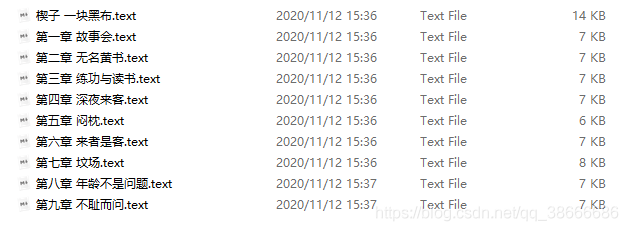

說實話,感覺我挺憨的才能寫出這種代碼,誰下載小說不是一整本一整本下,
結果也就我傻大憨的一章一章下,甚至還覺得自己好牛,害
代碼思路講解
專案要用到的模塊
import os
from time import sleep
import requests
from lxml import etree
沒有的話可以自行安裝,雖然大部分小伙伴應該都知道,但還是說一下
pip/pip3 install 想要安裝的模塊名
模塊安裝好了接下來講解代碼了
import os
from time import sleep
import requests
from lxml import etree
# 新筆趣閣的全部小說界面鏈接,所有小說鏈接都在這里
url = 'http://www.xbiquge.la/xiaoshuodaquan/'
# 請求頭
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
# 向新筆趣閣發送get請求
all_book_r = requests.get(url, headers=headers)
# 決議回傳的HTML頁面資料
all_book_html = etree.HTML(all_book_r.content.decode('utf-8'))
首先進入新筆趣閣全部小說頁面 >>>點擊進入
點擊鍵盤右上方的f12鍵或者滑鼠右鍵點擊檢查進入頁面除錯界面(右邊白色部分),
接下來單擊除錯臺左上角的選中按鈕,先隨便選中一篇小說,
點擊后發現左邊除錯臺中的html界面已經跳轉到了我們選中的地方,
我們可以發現這是一個ul串列下的一個a標簽,并且這個ul串列儲存著所有小說的鏈接,
那這就好辦了~
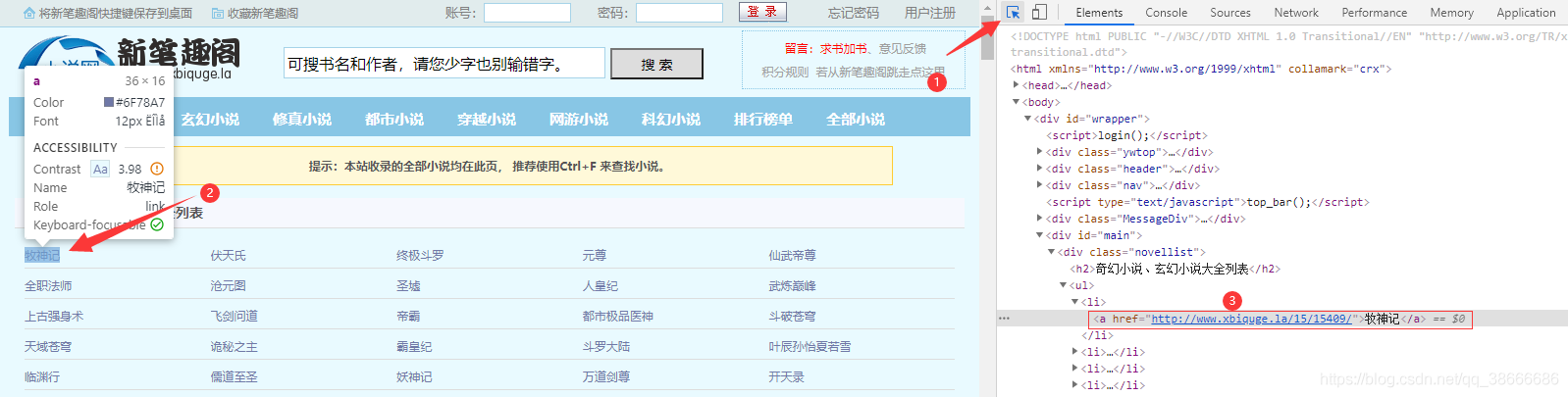
我們通過Chrome的xpath插件獲取到新筆趣閣所有小說的鏈接
沒有的可以自己下載安裝一下(強烈推薦,特別好用)
鏈接: https://pan.baidu.com/s/1_HzBzOp-vaWFkiuE2U9yFQ
提取碼: sb7p
xpath使用:這里是一個大佬的博客,不懂的可以看看

我們將可以正確獲取到自己需要資訊的代碼放入到xpath方法中,
xpath方法會將獲取到的HTML頁面里自己需要的所有資訊放入到一個串列里,
這個串列也就是你設定的變數名
# 儲存所有小說鏈接的串列
all_book_url = all_book_html.xpath('//div[@class="novellist"]/ul/li/a/@href')
# 儲存所有小說名的串列
all_book_title = all_book_html.xpath('//div[@class="novellist"]/ul/li/a/text()')
print(all_book_url) # 下圖

設定num值,每回圈判斷一次num值就+1,直到找到該小說,那么num值將作為上圖串列的下標使用,獲取到用戶想要下載的小說的鏈接,進行該小說的資料獲取
# 輸入你想找的小說名
find_book = input('輸入想下載的書名:')
num = 0
# 通過for回圈判斷是否有用戶想找的小說
for book_title in all_book_title:
# 有則獲取該小說你想要的資料
if find_book == book_title:
print('找到了,您要的', book_title)
# 找到該小說的鏈接
book_url = all_book_url[num]
# 向小說頁面發送請求
book_r = requests.get(book_url, headers=headers)
# 決議
book_html = etree.HTML(book_r.content.decode('utf-8'))
# 該小說的章節鏈接串列
book_url = book_html.xpath('//div[@id="list"]/dl/dd/a/@href')
# 該小說的章節名串列
chapter_title = book_html.xpath('//div[@id="list"]/dl/dd/a/text()')
# 回圈一次下標加一
num += 1
為了防止下載的小說都裝在一個檔案夾里,
不僅混亂而且很難找到自己想看的小說章節(其實只要小說內容裝在一起就不用這么麻煩,但是當時我妹想到)
# 判斷該路徑是否存在,存在則回傳true,不存在則回傳flase
judge = os.path.exists('../小說/%s' % str(book_title))
# 判斷judge是否為true,如果不是則創建該路徑
if not judge:
os.makedirs('../小說/%s' % str(book_title))
通過用戶輸入的值,將需要的章節鏈接回圈取出,然后通過xpath獲取小說文本內容
# 告訴用戶小說有多少章節
print('<------請輸入數字(該小說共有%s章)------>' % len(chapter_title))
# 獲取用戶需要下載的章節
download_book_start = int(input('輸入從第幾章開始下載:'))
download_book_end = int(input('輸入到第幾章結束:'))
chapter_num = 0
# download_book_start - 1是因為串列下標是從0開始的
for book_content_url in book_url[download_book_start - 1:download_book_end]:
# 防止獲取太快get不到資料
sleep(2)
new_book_content_url = 'http://www.xbiquge.la' + book_content_url
book_content_r = requests.get(new_book_content_url, headers=headers)
book_content_html = etree.HTML(book_content_r.content.decode('utf-8'))
# 該章節小說內容串列
book_content = book_content_html.xpath('//div[@class="box_con"]/div[@id="content"]/text()')
將內容串列里的資料一個個回圈出來存到all_content字串中,
然后通過with open方法,寫入到text檔案里
with open('../小說/%s/%s.text' % (str(book_title), chapter_title[download_book_start + chapter_num -1]), 'w', encoding='utf-8') as write_content:
# 用來儲存小說內容的字串
all_content = ''
for content in book_content:
all_content += content
write_content.write(all_content)
print(chapter_title[download_book_start + chapter_num -1], '--下載成功')
# 用來獲取小說章節名
chapter_num += 1
print('全部下載完成')
emmm,大概可能也許講完了,應該講的挺詳細的,
萌新第一次寫,如果有什么不足,可以提出來(勿噴),會慢慢改進的
完整代碼
import os
from time import sleep
import requests
from lxml import etree
url = 'http://www.xbiquge.la/xiaoshuodaquan/'
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
all_book_r = requests.get(url, headers=headers)
all_book_html = etree.HTML(all_book_r.content.decode('utf-8'))
all_book_url = all_book_html.xpath('//div[@class="novellist"]/ul/li/a/@href')
all_book_title = all_book_html.xpath('//div[@class="novellist"]/ul/li/a/text()')
print(all_book_url)
find_book = input('輸入想下載的書名:')
num = 0
for book_title in all_book_title:
if find_book == book_title:
print('找到了,您要的', book_title)
book_url = all_book_url[num]
book_r = requests.get(book_url, headers=headers)
book_html = etree.HTML(book_r.content.decode('utf-8'))
book_url = book_html.xpath('//div[@id="list"]/dl/dd/a/@href')
chapter_title = book_html.xpath('//div[@id="list"]/dl/dd/a/text()')
judge = os.path.exists('../小說/%s' % str(book_title))
if not judge:
os.makedirs('../小說/%s' % str(book_title))
print('<------請輸入數字(該小說共有%s章)------>' % len(chapter_title))
download_book_start = int(input('輸入從第幾章開始下載:'))
download_book_end = int(input('輸入到第幾章結束:'))
chapter_num = 0
for book_content_url in book_url[download_book_start - 1:download_book_end]:
sleep(2)
new_book_content_url = 'http://www.xbiquge.la' + book_content_url
book_content_r = requests.get(new_book_content_url, headers=headers)
book_content_html = etree.HTML(book_content_r.content.decode('utf-8'))
book_content = book_content_html.xpath('//div[@class="box_con"]/div[@id="content"]/text()')
with open('../小說/%s/%s.text' % (str(book_title), chapter_title[download_book_start + chapter_num -1]), 'w', encoding='utf-8') as write_content:
all_content = ''
for content in book_content:
all_content += content
write_content.write(all_content)
print(chapter_title[download_book_start + chapter_num -1], '--下載成功')
chapter_num += 1
print('全部下載完成')
break
elif num + 1 == len(all_book_title):
print('查無此書')
num += 1
`
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/220632.html
標籤:python