
?
往期推薦:
Flink基礎:入門介紹
Flink基礎:DataStream API
Flink基礎:實時處理管道與ETL
Flink深入淺出:資源管理
Flink深入淺出:部署模式
Flink深入淺出:記憶體模型
Flink深入淺出:JDBC Source從理論到實戰
Flink深入淺出:Sql Gateway原始碼分析
Flink深入淺出:JDBC Connector原始碼分析
本篇終于到了Flink的核心內容:時間與水印,最初接觸這個概念是在Spark Structured Streaming中,一直無法理解水印的作用,直到使用了一段時間Flink之后,對實時流處理有了一定的理解,才想清楚其中的緣由,接下來就來介紹下Flink中的時間和水印,以及基于時間特性支持的視窗處理,
1 時間和水印
1.1 介紹
Flink支持不同的時間型別:
- 事件時間:事件發生的時間,是設備生產或存盤事件的時間,一般都直接存盤在事件上,比如Mysql Binglog中的修改時間;或者用戶訪問日志的訪問時間等,
- 攝入時間:事件進入Flink的時間,這個時間不常用,
- 處理時間:某個特殊的算子處理事件的時間,當不在意事件的順序時,為了保證高吞吐低延遲,會采用這種時間,
比如想要計算給定某天的第一個小時的股票價格趨勢,就需要使用事件時間,如果選擇處理時間進行計算,那么將會按照當前Flink應用處理的時間進行統計,就可能會造成資料一致性問題,歷史資料的分析也很難復現,還有個典型的場景是流式處理往往是7*24小時不間斷的運行,加入使用處理時間,當中間停機進行代碼更新或者BUG處理時,再次啟動,中間未處理的資料會堆積當重啟時間一次性處理,這樣對統計結果就造成大大的干擾,
1.2 使用EventTime
Flink默認使用的是處理時間,可以通過下面的方法修改成事件時間:
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
如果需要使用事件時間,還需要提供時間抽取器和水印生成器,這樣Flink才可以追蹤到事件時間的處理進度,
1.3 水印
通過下面的例子,可以了解為什么需要水印,水印是怎么作業的,在這個例子中,每個事件都帶有一個時間標識,下面的數字就是事件上的時間,很明顯它們是亂序到達的,第一個到達的是4,然后是2:
23 19 22 24 21 14 17 13 12 15 9 11 7 2 4(第一個事件)
加入現在希望對流進行排序,那么每個事件到達的時候,就需要產生一個流,按照時間戳排好序輸出每個到達的事件,
- 上帝視角:第一個到達的事件是4,但是不能立刻就把它當做第一個元素放入排序流中,因為現在事件是亂序的,無法確定前面的事件是否已經到達,當然現在你已經看到完整的事件順序,當然會知道只要再等待一個事件,4之前的事件就都處理完了(這就是上帝視角),但在現實中我們是一條條接收的資料,無法知道4后面出現的是2,
- 快取和延遲:如果使用快取,那么很有可能會永遠停止等待,第一個事件是4,第二個事件是2,我們是不是只需要等待一個事件就能保證事件的完整?可能是,也可能不是,比如現在事件就永遠等待不到1,
- 排序策略:對于任何給定的時間事件停止等待之前的資料,直接進行排序,這就是水印的作用:用來定義何時停止等待更早的資料,Flink中的事件時間處理依賴于水印生成器,每當元素進入到Flink,會根據其事件時間,生成一個新的時間戳,即水印,對于t時間的水印,意味著Flink不會再接收t之前的資料,那么t之前的資料就可以進行排序產出順序流了,在上面的例子中,當水印的時間戳到達2時,就會把2事件輸出,
- 水印策略:每當事件延遲到達時,這些延遲都不是固定的,一種簡單的方式是按照最大的延遲事件來判斷,對于大部分的應用,這種固定水印都可以作業的比較好,
1.4 延遲和完整性
在批處理中,用戶可以一次性看到全部的資料,因此可以很容易的知道事件的順序,在流處理中總需要等待一段時間,確定事件完整后才能產生結果,可以很激進的配置一個較短的水印延遲時間,這樣雖然輸入結果不完整(有的時間延遲還未到達就已經開始計算),但是速度會很快,或者設定較長的延遲,資料會相對完整,但是會有一定的延遲,也可以采用混合的策略,剛開始延遲小一點,當處理了部分資料后,延遲增加,
1.5 延時
延時通過水印來定義,Watermark(t)代表了t時間的事件是完整的,即小于t的事件都可以開始處理了,
1.6 使用水印
為了支撐事件時間機制的處理,Flink需要知道每個事件的時間,然后為其產生一個水印,
DataStream<Event> stream = ...
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
// 選擇時間欄位
.withTimestampAssigner((event, timestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks =
// 定義水印生成的策略
stream.assignTimestampsAndWatermarks(strategy);
2 視窗
Flink擁有豐富的視窗語意,接下來將會了解到:
- 如何在無限資料流上使用視窗聚合資料
- Flink都支持什么型別的視窗
- 如何實作一個視窗聚合
2.1 介紹
當進行流處理時很自然的想針對一部分資料聚合分析,比如想要統計每分鐘有多少瀏覽、每周每個用戶有多少次會話、每分鐘每個傳感器的最大溫度等,Flink的視窗分析依賴于兩個抽象概念:視窗分配器Assigner(用來指定事件屬于哪個視窗,在必要的時候新建視窗),視窗函式Function(應用于視窗內的資料),Flink的視窗也有觸發器Trigger的概念,它決定了何時呼叫視窗函式進行處理;Evictor用于剔除視窗中不需要計算的資料,可以像下面這樣創建視窗:
stream.
.keyBy(<key selector>)
.window(<window assigner>)
.reduce|aggregate|process(<window function>)
也可以在非key資料流上使用視窗,但是一定要小心,因為處理程序將不會并行執行:
stream.
.windowAll(<window assigner>)
.reduce|aggregate|process(<window function>)
2.2 視窗分配器
Flink有幾種內置的視窗分配器:
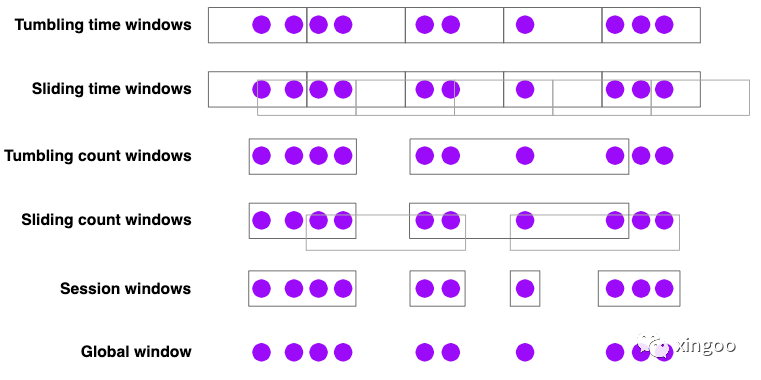
按照視窗聚合的種類可以大致分為:
- 滾動視窗:比如統計每分鐘的瀏覽量,
TumblingEventTimeWindows.of(Time.minutes(1))
- 滑動視窗:比如每10秒鐘統計一次一分鐘內的瀏覽量,
SlidingEventTimeWindows.of(Time.minutes(1), Time.seconds(10))
- 會話視窗:統計會話內的瀏覽量,會話的定義是同一個用戶兩次訪問不超過30分鐘,
EventTimeSessionWindows.withGap(Time.minutes(30))
視窗的時間可以通過下面的幾種時間單位來定義:
- 毫秒,
Time.milliseconds(n)
- 秒,
Time.seconds(n)
- 分鐘,
Time.minutes(n)
- 小時,
Time.hours(n)
- 天,
Time.days(n)
基于時間的視窗分配器支持事件時間和處理時間,這兩種型別的時間處理的吞吐量會有差別,使用處理時間優點是延遲很低,但是也存在幾個缺點:無法正確的處理歷史資料;無法處理亂序資料;結果非冪等,當使用基于數量的視窗,如果數量不夠,可能永遠不會觸發視窗操作,沒有選項支持超時處理或部分視窗的處理,當然你可以通過自定義視窗的方式來實作,全域視窗分配器會在一個視窗內,統一分配每個事件,如果需要自定義視窗,一般會基于它來做,不過推薦直接使用ProcessFunction,
2.3 視窗函式
有三種選擇來處理視窗中的內容:
- 當做批處理,使用
ProcessWindowFunction,基于Iterable處理視窗內容
- 增量的使用
ReduceFunction和AggregateFunction依次處理視窗的每個資料
- 上面兩者結合,使用
ReduceFunction和AggregateFunction進行預聚合,然后使用ProcessFunction進行批量處理,
下面給出了方法1和方法3的例子,需求為在每分鐘內尋找到每個傳感器的值,產生<key,>的結果流,
2.3.1 ProcessWindowFunction的例子
DataStream<SensorReading> input = ...
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.process(new MyWastefulMax());
public static class MyWastefulMax extends ProcessWindowFunction<
SensorReading, // input type
Tuple3<String, Long, Integer>, // output type
String, // key type
TimeWindow> { // window type
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> events,
Collector<Tuple3<String, Long, Integer>> out) {
int max = 0;
for (SensorReading event : events) {
max = Math.max(event.value, max);
}
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
有一些內容需要了解:
-
所有視窗分配的時間都在Flink中按照key快取起來,直到視窗觸發,因此代價很昂貴,
-
ProcessWindowFunction中傳入了Context物件,內部包含了對應的視窗資訊,介面類似:
public abstract class Context implements java.io.Serializable {
public abstract W window();
public abstract long currentProcessingTime();
public abstract long currentWatermark();
public abstract KeyedStateStore windowState();
public abstract KeyedStateStore globalState();
}
其中windowState和globalState會為每個key、每個視窗或者全域存盤資訊,當需要記錄視窗的某些資訊的時候會很有用,
2.3.2 Incremental Aggregation例子
DataStream<SensorReading> input = ...
input
.keyBy(x -> x.key)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.reduce(new MyReducingMax(), new MyWindowFunction());
private static class MyReducingMax implements ReduceFunction<SensorReading> {
public SensorReading reduce(SensorReading r1, SensorReading r2) {
return r1.value() > r2.value() ? r1 : r2;
}
}
private static class MyWindowFunction extends ProcessWindowFunction<
SensorReading, Tuple3<String, Long, SensorReading>, String, TimeWindow> {
@Override
public void process(
String key,
Context context,
Iterable<SensorReading> maxReading,
Collector<Tuple3<String, Long, SensorReading>> out) {
SensorReading max = maxReading.iterator().next();
out.collect(Tuple3.of(key, context.window().getEnd(), max));
}
}
注意iterable只會執行一次,即只有MyReducingMax輸出的值才會傳入這里,
2.4 延遲事件
默認當使用基于事件時間視窗時,延遲事件會直接丟棄,有兩種方法可以處理這個問題:你可以把需要丟棄的事件重新搜集起來輸出到另一個流中,也叫側輸出;或者配置水印的延遲時間,
OutputTag<Event> lateTag = new OutputTag<Event>("late"){};
SingleOutputStreamOperator<Event> result = stream.
.keyBy(...)
.window(...)
.sideOutputLateData(lateTag)
.process(...);
DataStream<Event> lateStream = result.getSideOutput(lateTag);
通過指定允許延遲的間隔時間,當在允許的延遲范圍內,仍然可以分配到對應的視窗(視窗對應的狀態資訊將會保留一段時間),但是會導致對應視窗重新計算(也叫做延遲回應late firing)默認允許的延遲是0,也就是說一旦事件在水印之后就會被丟棄掉,
stream.
.keyBy(...)
.window(...)
.allowedLateness(Time.seconds(10))
.process(...);
當配置延遲后,只有那些在允許的延遲之外的資料會被丟棄或者使用側輸出搜集起來,
3 注意
Flink的視窗處理可能跟你想的不太一樣,基于在flink用戶郵件中常問的問題,整理如下
3.1 滑動視窗造成資料拷貝
滑動視窗會造成大量的視窗物件,并且會拷貝每個物件到對應的視窗中,比如,你的滑動視窗為每15分鐘統計24小時的視窗長度,那么每個時間將會復制到4*24=96個視窗中,
3.2 時間視窗會對齊到系統時間
如果使用1個小時的視窗,那么當應用在12:05啟動時,并不是說第一個視窗的時間范圍是到1:05,事實上第一個視窗的時間是12:05到01:00,只有55分鐘而已,注意,滾動視窗和滑動視窗都支持偏移值的引數配置,
3.3 視窗后面可以接視窗
比如:
stream
.keyBy(t -> t.key)
.timeWindow(<time specification>)
.reduce(<reduce function>)
.timeWindowAll(<same time specification>)
.reduce(<same reduce function>)
這樣的代碼能夠作業主要是因為第一個視窗輸出的內容系統會自動添加一個視窗結束的時間,后面的處理可以基于這個時間再次進行視窗操作,但是需要視窗的配置統一或者整數倍,
3.4 空視窗沒有輸出
只有對應的事件到達時,才會創建對應的視窗,因此如果沒有對應的事件,視窗就不會創建,因此也不會有任何輸出,
3.5 延遲資料造成延遲合并
對于會話視窗,實際上會為每個事件在一開始分配一個新的視窗,當新的事件到達時,會根據時間間隔合并視窗,因此如果事件延遲到達,很有可能會造成視窗的延遲合并,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/221207.html
標籤:java
上一篇:springboot2.x 從零到一(2、插件及基礎環境開發)
下一篇:一點都不趣味的題目