文章目錄
- 前言
- 一、解線性方程組的方法
- 二、解線性方程組的迭代法及其代碼實作
- 1. 迭代法的收斂性
- 2. 基本引數設定
- 3. 雅克比(Jacobi)迭代
- 4. 高斯-塞德爾(Gauss-Seidel)迭代
- 5. 超松弛(SOR)迭代
- 總結
前言
近期在上南方科技大學何炳生老師的數值分析課程時,學習了解線性方程組的三種迭代方法,即:雅克比(Jacobi)迭代;高斯-塞德爾(Gauss-Seidel)迭代以及超松弛(SOR)迭代,并按要求使用MATLAB對這三種迭代方法進行了仿真設計,通過仿真設計也對這三種迭代法有了一定的認識,希望通過此貼以通俗的形式分享自己對于這類方法的理解,文中一些不夠準確或錯誤的表達,還望大家指證,
一、解線性方程組的方法
求解線性方程組在很多工程領域都是很重要的內容,無論是機器學習也好亦或是其他的工程優化也好,通常來說,對于一個線性方程組 A X = b AX=b AX=b,對其的數值解法一般有兩類:直接法和迭代法,
- 直接法實際就是通過使用各種線性代數知識在有限步算數運算,計算出該線性方程組精確解的辦法(在計算程序中沒有舍入誤差的情況下),例如本科線性代數中的克拉默法則以及考研線性代數大題最常用的高斯消去法,
- 迭代法則是用某種極限程序去逐步逼近線性方程組的精確解的方法,也就是最后得到的是一個無限逼近與精確解的近似解,這個解只有在迭代無窮次下可以看做是精確解(一般有限步內得不到精確解),
對于熟悉直接法的人而言,可以發現這種方法的求解程序在計算機下編程實際是較為復雜的,例如:高斯消去法常規的求解程序就要求先構建增廣矩陣,而后做初等行變換消元將系數矩陣化為一個上三角矩陣,然后再回代求解出解向量
X
X
X,并且從計算量而言也是較為復雜的,盡管之后變形出了例如三角分解(LU分解)這樣的變形解法,但從編程的角度考慮依然是不直觀的,
而迭代法,其基本思想是將線性方程組轉化為便于迭代的等價方程組,然后基于初始
X
X
X值即
X
=
x
i
(
0
)
=
0
(
i
=
1
,
2
,
3
,
.
.
.
n
)
X = x_{i}^{(0)} = 0 (i = 1,2,3,...n)
X=xi(0)?=0(i=1,2,3,...n),然后按照一定的計算規則,不斷地修正得到新的解
X
X
X,最終得到滿足精度要求的方程組的近似解,這顯然是更加直觀且易于編程設計的一種方法,而這其中就有三種最常見的迭代方式,即:
- 雅克比(Jacobi)迭代
- 高斯-塞德爾(Gauss-Seidel)迭代
- 超松弛(SOR)迭代
二、解線性方程組的迭代法及其代碼實作
1. 迭代法的收斂性
在直接引入三種迭代法及其MATLAB實作之前,需要先提到一點就是迭代法的收斂性,簡單的理解其實就是迭代法并不適用于所有線性方程組,即對于一類方程組迭代時會收斂,近似解會不斷逼近精確解,但是對于另外一類方程組則會發散,近似解不斷遠離精確解,而決定迭代法是否收斂,是否可用于該方程組,主要需要考慮的其實就是系數矩陣 A A A,這里直接給出使上述三種迭代法收斂的充分條件:系數矩陣 A A A按行(或列)嚴格對角占優或滿足弱對角占優不可約,
(由于本人能力有限,具體的關于于迭代法收斂的充要條件,請參照清華大學出版,李慶陽、王能超、易大義老師編的《數值分析》第五版內容)
2. 基本引數設定
基本引數:矩陣階數,計算誤差,最大迭代次數,其中計算誤差和最大迭代次數是迭代終止的判斷要求,達到精度或者迭代到最大次數時停止迭代并輸出結果,此處對計算誤差進行說明,當計算精度滿足 m a x 1 ? i ? n ∣ x i ( k + 1 ) ? x i ( k ) ∣ < e p s \mathop{max}\limits_{1\leqslant i\leqslant n}\left | x_{i}^{(k+1)} - x_{i}^{(k)}\right | < eps 1?i?nmax?∣∣∣?xi(k+1)??xi(k)?∣∣∣?<eps 時結束迭代,
%==基本引數
%矩陣階數n
n = 4;
%計算誤差
eps = 0.000005;
%最大迭代次數
Nmax = 10000;
矩陣設定:由于以下三種迭代法收斂的充分條件為系數矩陣A滿足嚴格對角占優或按行(或列)滿足若對角占優不可約,故在引數設定上設計了兩種方法,為方便對比計算結果,之后采用的均是方法一所設定的矩陣,
方法一:手動輸入系數矩陣
A
A
A及結果向量
b
b
b
% 方法一 : 自行設定矩陣
A = [-4,1,1,1;
1,-4,1,1;
1,1,-4,1;
1,1,1,-4];
B = [1,1,1,1];
方法二:根據設定的矩陣階數,自動生成強對角占優矩陣
% 方法二:隨機生成矩陣
% 系數矩陣(默認生成一個對角占優矩陣)
A = 100 * rand(n) - 50;
for i=1:n
A(i,i) = sum(abs(A(i,:)))+25 * rand(1);
end
%結果向量
B = 100 * rand([n 1]);
3. 雅克比(Jacobi)迭代
雅克比迭代實際是將系數矩陣A分解為了三個矩陣的組合,如下圖
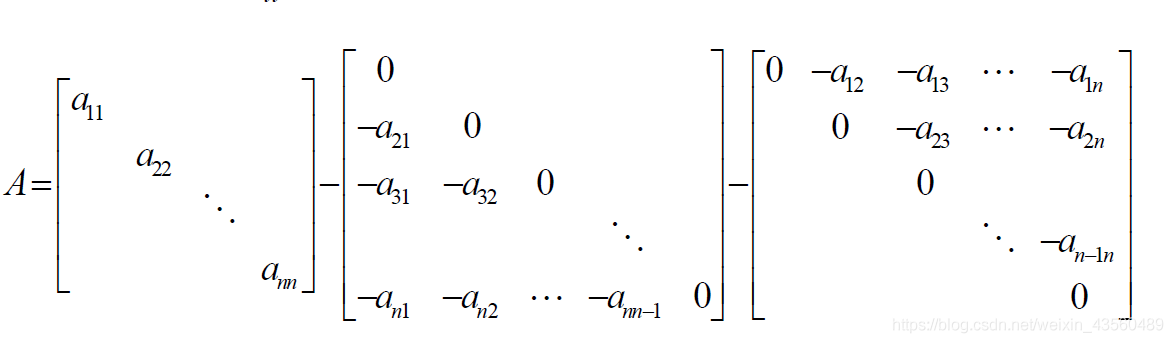
將其記做
A
=
D
?
L
?
U
A = D-L-U
A=D?L?U,則原方程組
A
X
=
b
AX=b
AX=b 等價于
(
D
?
L
?
U
)
X
=
b
(D-L-U)X = b
(D?L?U)X=b,即
D
X
=
(
L
+
U
)
X
+
b
DX = (L+U)X+b
DX=(L+U)X+b
因為
a
i
i
≠
0
(
i
=
1
,
2
,
.
.
.
n
)
a_{ii}\neq 0 (i = 1,2,...n)
aii??=0(i=1,2,...n),故
X
=
D
?
1
(
L
+
U
)
X
+
D
?
1
b
X = D^{-1}(L+U)X+D^{-1}b
X=D?1(L+U)X+D?1b
由此便可以得到一個迭代公式
X
(
k
+
1
)
=
D
?
1
(
L
+
U
)
X
(
k
)
+
D
?
1
b
X^{(k+1)}=D^{-1}(L+U)X^{(k)}+D^{-1}b
X(k+1)=D?1(L+U)X(k)+D?1b
令
B
=
D
?
1
(
L
+
U
)
B = D^{-1}(L+U)
B=D?1(L+U),
f
=
D
?
1
b
f = D^{-1}b
f=D?1b,即可得到雅克比迭代公式
X
(
k
+
1
)
=
B
X
(
k
)
+
f
X^{(k+1)}=BX^{(k)}+f
X(k+1)=BX(k)+f
寫成便于編程理解的形式即:
X
i
(
k
+
1
)
=
1
a
i
i
(
b
i
?
∑
j
=
1
j
≠
i
n
a
i
j
X
j
(
k
)
)
X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{\mathop{j=1}\limits_{j\neq i}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)?=aii?1?(bi??j?=ij=1?∑n?aij?Xj(k)?)
代碼:
x(n) = 0;
y(n) = 0;
count = 1;
while(1)
for i = 1:n
for j = 1:n
%j≠k時
if i ~= j
y(i) = y(i) + A(i,j)*x(j);
end
end
y(i)=( B(i) - y(i))/A(i,i);
end
if max(abs(x-y)) < eps
%c為將結果回帶到方程組中求解的結果向量,以確認結果無誤
c = A * y';
fprintf('迭代結束,次數%d,最終結果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代結果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超過最大迭代次數,迭代結束,最終結果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
y(1: n) = 0;
end
仿真結果:

4. 高斯-塞德爾(Gauss-Seidel)迭代
在雅克比迭代中,我們可以看出,每一次迭代得到的新的解向量 X ( k + 1 ) X^{(k+1)} X(k+1)中的每一個元素均是由上一個解向量 X ( k ) X^{(k)} X(k)的所有元素計算得出,但實際上計算新的解向量 X ( k + 1 ) X^{(k+1)} X(k+1)的一個元素時,其前面的元素實際已經計算得出了,所以高斯-塞德爾(Gauss-Seidel)迭代的核心思想即:將本次迭代中前面已經計算出來的元素加入到迭代公式中,替代掉相對應的上一個解向量中的元素,從而實作加速收斂,
高斯-塞德爾(Gauss-Seidel)迭代迭代公式可以寫作
X
i
(
k
+
1
)
=
1
a
i
i
(
b
i
?
∑
j
=
1
i
?
1
a
i
j
X
j
(
k
+
1
)
?
∑
j
=
i
+
1
n
a
i
j
X
j
(
k
)
)
X_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)})
Xi(k+1)?=aii?1?(bi??j=1∑i?1?aij?Xj(k+1)??j=i+1∑n?aij?Xj(k)?)
代碼:
x(n) = 0;
y(n) = 0;
count = 1;
%中間變數
x1(n) = 0;
x2(n) = 0;
while(1)
x1(1:n) = 0;
x2(1:n) = 0;
for i = 1:n
for j = 1: i-1
x1(i) =x1(i) + A(i,j) * y(j);
end
for k = i + 1 : n
x2(i) = x2(i) + A(i,k) * x(k);
end
y(i)=(B(i) - x1(i) - x2(i))/A(i,i);
end
if max(abs(x-y)) < eps
c = A * y';
fprintf('迭代結束,次數%d,最終結果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代結果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超過最大迭代次數,迭代結束,最終結果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
end
仿真結果:

5. 超松弛(SOR)迭代
超松弛迭代法實際是在高斯-塞德爾迭代的基礎上的一個加速方法,可以看做是帶引數的高斯-塞德爾迭代,是求解大型稀疏矩陣方程組的有效方法,有著很廣泛的應用,其核心思想為將高斯-塞德爾迭代求解出的新的解向量元素與上一個解向量中相對應的元素,做加權平均組合成一個全新的解向量的元素,這個全新的解向量即為超松弛迭代法的解,其中的權重被稱為松弛因子
其具體計算公式如下:
- 用高斯-塞德爾迭代公式定義一個輔助量
X ~ i ( k + 1 ) = 1 a i i ( b i ? ∑ j = 1 i ? 1 a i j X j ( k + 1 ) ? ∑ j = i + 1 n a i j X j ( k ) ) \widetilde{X}_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)}) X i(k+1)?=aii?1?(bi??j=1∑i?1?aij?Xj(k+1)??j=i+1∑n?aij?Xj(k)?) - 將
X
i
(
k
+
1
)
X_{i}^{(k+1)}
Xi(k+1)?取做
X
~
i
(
k
+
1
)
\widetilde{X}_{i}^{(k+1)}
X
i(k+1)?與
X
i
(
k
)
X_{i}^{(k)}
Xi(k)?的加權平均
X i ( k + 1 ) = ( 1 ? ω ) X i ( k ) + ω X ~ i ( k + 1 ) X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \omega\widetilde{X}_{i}^{(k+1)} Xi(k+1)?=(1?ω)Xi(k)?+ωX i(k+1)?
即
X i ( k + 1 ) = ( 1 ? ω ) X i ( k ) + ω a i i ( b i ? ∑ j = 1 i ? 1 a i j X j ( k + 1 ) ? ∑ j = i + 1 n a i j X j ( k ) ) X_{i}^{(k+1)}=(1-\omega )X_{i}^{(k)} + \frac{\omega}{a_{ii}}(b_{i} - \sum\limits_{j = 1}^{i - 1}a_{ij}X_{j}^{(k+1)} - \sum\limits_{\mathop{j=i+1}}^{n}a_{ij}X_{j}^{(k)}) Xi(k+1)?=(1?ω)Xi(k)?+aii?ω?(bi??j=1∑i?1?aij?Xj(k+1)??j=i+1∑n?aij?Xj(k)?)
式中的系數 ω \omega ω被稱為松弛因子,當 ω = 1 \omega = 1 ω=1時即為高斯-塞德爾迭代,為了保證迭代程序收斂,要求 0 < ω < 2 0 < \omega<2 0<ω<2
當 0 < ω < 1 0 < \omega<1 0<ω<1時,是低松弛法;
當 1 < ω < 2 1 < \omega<2 1<ω<2時,是超松弛法;
代碼:
x(n) = 0;
y(n) = 0;
count = 1;
%中間變數
x1(n) = 0;
x2(n) = 0;
%松弛因子w
w = 1.3;
while(1)
x1(1:n) = 0;
x2(1:n) = 0;
for i = 1:n
for j = 1: i-1
x1(i) =x1(i) + A(i,j) * y(j);
end
for k = i + 1 : n
x2(i) = x2(i) + A(i,k) * x(k);
end
temp = (B(i) - x1(i) - x2(i))/A(i,i);
y(i) = (1 - w)* x(i) + w * temp;
end
if max(abs(x-y)) < eps
c = A * y';
fprintf('迭代結束,次數%d,最終結果:\n',count);
disp(y);
disp(c);
break;
else
fprintf('第%d次迭代結果:\n',count);
disp(y)
end
if count == Nmax
c = A * y';
fprintf('超過最大迭代次數,迭代結束,最終結果:\n');
disp(y);
disp(c);
break;
end
count = count + 1;
x = y;
end
仿真結果:

總結
從結果上來看,對于所設定的系數矩陣A,要滿足小數點后6位的精度要求,雅克比迭代法迭代次數39次;高斯賽德爾迭代法迭代次數22次;松弛因子為1.3時的SOR超松弛迭代法迭代12次,可見SOR迭代法是三種迭代法中收斂最快的,
除此之外,在測驗SOR超松弛迭代法時還發現盡管其作為一種高斯賽德爾迭代法的加速,但有時,對于某些矩陣而言,松弛因子
w
>
1
w>1
w>1反而會有反作用,此時使用
w
=
1
w=1
w=1(即高斯賽德爾迭代法)效果會更好,個人認為關于
w
w
w的取值值得思考和探究,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/224271.html
標籤:python
上一篇:條件控制和回圈陳述句
下一篇:YoloV4訓練自己的資料集