1. 完成形式
本Fisher二分類判別模型的代碼是利用Python獨立完成撰寫的,基本基于上課所講內容,沒有參考網上代碼,
2. 實作演算法思路
- 資料集選擇與載入初始化
電力行業中,比較適合Fisher分類判別模型的資料集為用戶畫像的分類,然而電力行業由于國家管控的特殊性,導致網路上能夠找到的開源的資料集過少,在Dataju平臺原先有的十多個能源客戶畫像資料集在今年下半年也全部由于著作權、客戶資訊保密原則等原因而下架,在搜索了一段時間之后無奈放棄選擇現成的開源分類資料集,本代碼的資料集采用的是Scikit-Learn包中的乳腺癌資料集,
#資料
#二分類問題
#直接從sklearn.datasets匯入乳腺癌資料集
from sklearn.datasets import load_breast_cancer
以下為乳腺癌資料集中較為重要的資訊
Breast cancer wisconsin (diagnostic) dataset
Data Set Characteristics:
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
The mean, standard error, and "worst" or largest (mean of the three
worst/largest values) of these features were computed for each image,
resulting in 30 features. For instance, field 0 is Mean Radius, field
10 is Radius SE, field 20 is Worst Radius.
- class:
- WDBC-Malignant
- WDBC-Benign
:Summary Statistics:
===================================== ====== ======
Min Max
===================================== ====== ======
radius (mean): 6.981 28.11
texture (mean): 9.71 39.28
perimeter (mean): 43.79 188.5
area (mean): 143.5 2501.0
smoothness (mean): 0.053 0.163
compactness (mean): 0.019 0.345
concavity (mean): 0.0 0.427
concave points (mean): 0.0 0.201
symmetry (mean): 0.106 0.304
fractal dimension (mean): 0.05 0.097
radius (standard error): 0.112 2.873
texture (standard error): 0.36 4.885
perimeter (standard error): 0.757 21.98
area (standard error): 6.802 542.2
smoothness (standard error): 0.002 0.031
compactness (standard error): 0.002 0.135
concavity (standard error): 0.0 0.396
concave points (standard error): 0.0 0.053
symmetry (standard error): 0.008 0.079
fractal dimension (standard error): 0.001 0.03
radius (worst): 7.93 36.04
texture (worst): 12.02 49.54
perimeter (worst): 50.41 251.2
area (worst): 185.2 4254.0
smoothness (worst): 0.071 0.223
compactness (worst): 0.027 1.058
concavity (worst): 0.0 1.252
concave points (worst): 0.0 0.291
symmetry (worst): 0.156 0.664
fractal dimension (worst): 0.055 0.208
===================================== ====== ======
研究資料集可以發現,該資料集由30個指標與一個二分類的target組成表明是否患病,由min&max表可以發現存在方差特別大的指標area,在不確定其對患病影響的情況下,需要考慮是否需要對資料集做標準化處理,
載入資料集之后,將20%的資料作為測驗樣本,
from sklearn.model_selection import train_test_split
x = breast_cancer['data']
y = breast_cancer['target']
#隨機采樣,將20%的資料作為測驗樣本
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0,test_size=0.2)
標準化代碼如下,在實際運行模型的時候根據最后生成結果選擇是否做資料與處理,
# 標準化處理
from sklearn.preprocessing import StandardScaler
ss_x=StandardScaler()
ss_y=StandardScaler()
#分別對訓練和測驗資料的特征以及目標值進行標準化處理
x_train = ss_x.fit_transform(x_train)
x_test = ss_x.transform(x_test)
- 函式設計
根據課堂學到的內容,設計如下函式
| get_mean_vector(target) | 求均值向量|
| get_dispersion_matrix(target, mean_vector) |求樣本內離散度矩陣|
| get_sample_divergence(mean_vector1, mean_vector2) | 求樣本間離散度 |
| get_w_star(dispersion_matrix, mean_vector1, mean_vector2) | 求Fisher準則函式的w_star解|
| get_sample_projection(w_star, x) | 求一特征向量在w_star上的投影|
| get_segmentation_threshold(w_star, way_flag) |求分割閾值 |
| test_single_smaple(w_star, y0, test_sample, test_target) | 單例測驗 |
| test_single_smaple_check(w_star, y0, test_sample, test_target)|單例測驗(用于統計) |
| test_check(w_star, y0) | 統計測驗樣本 |
具體實作如下:
def get_mean_vector(target):
'''
求均值向量
:param target:
:return:
'''
m_target_list = [0 for i in range(x_train.shape[1])]
count = 0
for i in range(x_train.shape[0]):
if y_train[i] == target:
count = count + 1
temp = x_train[i].tolist()
m_target_list = [m_target_list[j] + temp[j] for j in range(x_train.shape[1])]
m_target_list = [x / count for x in m_target_list]
# 其實可以用類似torch的壓縮維度的函式直接求和
return m_target_list
通過target的值選擇計算標簽為target的均值向量,
def get_dispersion_matrix(target, mean_vector):
'''
求樣本內離散度矩陣
:param target:
:param mean_vector:
:return:
'''
s_target_matrix = np.zeros((x_train.shape[1], x_train.shape[1]))
for i in range(x_train.shape[0]):
if y_train[i] == target:
temp = np.multiply(x_train[i] - mean_vector, (x_train[i] - mean_vector).transpose())
s_target_matrix = s_target_matrix + temp
return s_target_matrix
通過target和與其匹配的mean_vector計算求得樣本內離散度矩陣,
def get_sample_divergence(mean_vector1, mean_vector2):
'''
求樣本間離散度
:param mean_vector1:
:param mean_vector2:
:return:
'''
return np.multiply((mean_vector1 - mean_vector2), (mean_vector1 - mean_vector2).transpose())
計算兩個均值向量的樣本間離散度,
def get_w_star(dispersion_matrix, mean_vector1, mean_vector2):
'''
求Fisher準則函式的w_star解
:param dispersion_matrix:
:param mean_vector1:
:param mean_vector2:
:return:
'''
return np.matmul(np.linalg.inv(dispersion_matrix), (mean_vector1 - mean_vector2))
由樣本內離散度矩陣和兩個均值向量,根據Fisher準則逆向求解被投影向量的最優解w_star,
def get_sample_projection(w_star, x):
'''
求一特征向量在w_star上的投影
:param w_star:
:param x:
:return:
'''
return np.matmul(w_star.transpose(), x)
利用求得的w_star求一特征向量在w_star上的投影值,
def get_segmentation_threshold(w_star, way_flag):
'''
求分割閾值
:param w_star:
:param way_flag:
:return:
'''
if way_flag == 0:
y0_list = []
y1_list = []
for i in range(x_train.shape[0]):
if y_train[i] == 0:
y0_list.append(get_sample_projection(w_star, x_train[i]))
else:
y1_list.append(get_sample_projection(w_star, x_train[i]))
ny0 = len(y0_list)
ny1 = len(y1_list)
my0 = sum(y0_list) / ny0
my1 = sum(y1_list) / ny1
segmentation_threshold = (ny0 * my0 + ny1 * my1) / (ny0 + ny1)
return segmentation_threshold
elif way_flag == 1:
y0_list = []
y1_list = []
for i in range(x_train.shape[0]):
if y_train[i] == 0:
y0_list.append(get_sample_projection(w_star, x_train[i]))
else:
y1_list.append(get_sample_projection(w_star, x_train[i]))
ny0 = len(y0_list)
ny1 = len(y1_list)
my0 = sum(y0_list) / ny0
my1 = sum(y1_list) / ny1
py0 = ny0 / (ny0 + ny1)
py1 = ny1 / (ny0 + ny1)
segmentation_threshold = (my0 + my1) / 2 + math.log(py0 / py1) / (ny0 - ny1 - 2)
return segmentation_threshold
else:
return 0
利用w_star投影標簽內的原特征向量用來求分割閾值,該函式提供了兩種分割閾值的實作方法,
def test_single_smaple(w_star, y0, test_sample, test_target):
'''
單例測驗
:param y0:
:param x:
:return:
'''
y_test = get_sample_projection(w_star, test_sample)
predection = 1
if y_test > y0:
predection = 0
print("This x_vector's target is {}, and the predection is {}".format(test_target, predection))
測驗函式,該單例測驗函式可以由用戶輸入一個新的特征向量,之后會給出模型的預測結果,
def test_single_smaple_check(w_star, y0, test_sample, test_target):
'''
單例測驗(用于統計)
:param y0:
:param x:
:return:
'''
y_test = get_sample_projection(w_star, test_sample)
predection = 1
if y_test > y0:
predection = 0
if test_target == predection:
return True
else:
return False
該單例測驗函式用于統計資料使用,
def test_check(w_star, y0):
'''
統計測驗樣本
:param w_star:
:param y0:
:return:
'''
right_count = 0
for i in range(x_test.shape[0]):
boolean = test_single_smaple_check(w_star, y0, x_test[i], y_test[i])
if boolean == True:
right_count = right_count + 1
return x_test.shape[0], right_count, right_count / x_test.shape[0]
測驗資料集的測驗統計,通過比對預測結果與實際標簽求得統計樣本數,正確預測樣本數和準確率,
- 演算法實作
if __name__ == "__main__":
m0 = np.array(get_mean_vector(0)).reshape(-1, 1)
m1 = np.array(get_mean_vector(1)).reshape(-1, 1)
s0 = get_dispersion_matrix(0, m0)
s1 = get_dispersion_matrix(1, m1)
sw = s0 + s1
sb = get_sample_divergence(m0, m1)
w_star = np.array(get_w_star(sw, m0, m1)).reshape(-1, 1)
y0 = get_segmentation_threshold(w_star, 0)
print("The segmentation_threshold is ", y0)
test_sum, right_sum, accuracy = test_check(w_star, y0)
print("Total specimen number:{}\nNumber of correctly predicted samples:{}\nAccuracy:{}\n".format(test_sum, right_sum, accuracy))
根據劃分的資料集,利用正反標簽的訓練資料集分別計算均值向量,樣本內離散度矩陣,樣本間離散度矩陣,利用正反標簽的樣本內離散度矩陣求得總樣本內離散度矩陣,之后利用總樣本內離散度矩陣求得被投影向量,根據被投影向量將原特征向量均投影到一維線上,采用閾值割裂的方法加權修正得到分割閾值,之后利用測驗樣本資料集檢驗得到的分割閾值的質量,
- 實驗結果
采用資料標準化和修正加權閾值演算法結果:

采用資料標準化和普通加權閾值演算法結果:

不采用資料標準化,采用修正加權閾值演算法結果:
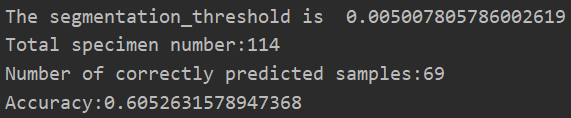
不采用資料標準化,不采用修正加權閾值演算法結果:

- 實驗結論分析
- area這一指標對患病與否并沒有什么影響,而其他指標會由于標準化而被削弱特征差異導致預測質量的下降,
- 不采用資料標準化,不采用修正加權閾值演算法結果的情況下,模型預測準確率可達到93.8596%,超過筆者對此模型的期望,
- 修正加權閾值函式在樣本分布均勻的情況下可能會有更好的效果,但是該樣本資料集可能分布不太均勻,
添加函式:
def analysis_train_set():
train_positive_count = 0
train_negative_count = 0
sum_count = 0
for i in range(x_train.shape[0]):
if y_train[i] == 0:
train_negative_count = train_negative_count + 1
else:
train_positive_count = train_positive_count + 1
sum_count = sum_count + 1
print("Train Set Analysis:\nTotal number:{}\nNumber of positive samples:{}\tProportion of positive samples:{"
"}\nNumber of negative samples:{}\tProportion of negative samples:{}\nPositive and negative sample ratio:{"
"}\n".format(sum_count, train_positive_count, train_positive_count / sum_count, train_negative_count,
train_negative_count / sum_count, train_positive_count / train_negative_count))
觀察輸出結果:
 可以發現,該資料集中,正樣本資料占比達到了63.7%, 正負樣本比率達到了1.76,遠超過1.2的比率閾值,導致了修正加權閾值函式的更偏向性加權從而使得預測質量大幅下降,想要解決這個問題可能需要修改資料集或者做資料增強,此處暫且不提,
可以發現,該資料集中,正樣本資料占比達到了63.7%, 正負樣本比率達到了1.76,遠超過1.2的比率閾值,導致了修正加權閾值函式的更偏向性加權從而使得預測質量大幅下降,想要解決這個問題可能需要修改資料集或者做資料增強,此處暫且不提,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/224273.html
標籤:python
上一篇:YoloV4訓練自己的資料集