本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于鄉村四十二,作者至善
背景
最近在調研電商平臺黑豬肉市場需求情況,電商平臺有效的用戶評論,可以用來輔助理解客戶需求,
下面對網易未央的一款豬肉評論進行抓取,并做簡單分析,

網頁分析
京東商城的資訊儲存在JSON里面,我們首先要找到儲存評論的JSON,
使用谷歌瀏覽器,點擊檢查—Network,重繪進入,搜索發現儲存評論的網址,
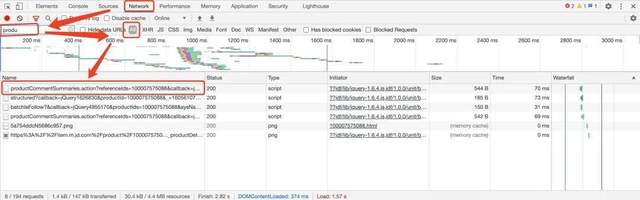
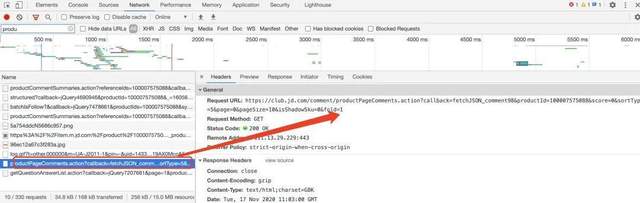
第一個網頁鏈接打開后,發現搜索錯了,并非是評論儲存的地方,我們繼續往下找,如下圖所示的便是商品評論儲存的地方了,觀察URL,最后一個數字是“1”,表示評論的頁數,我們可以通過for回圈,爬取需要的資料,
代碼如下
import urllib.request import json import time import xlwt # 爬取評論資訊 page = int(input('請輸入爬取的結束頁碼:')) for i in range(0,page): print('第%s頁開始爬取'%(i+1)) url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=5461917&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1' url = url.format(i) headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36', 'Referer': 'https://item.jd.com/' } request = urllib.request.Request(url=url,headers=headers) content = urllib.request.urlopen(request).read().decode('gbk') content = content.strip('fetchJSON_comment98vv385();') obj = json.loads(content) comments = obj['comments'] fp = open('京東.text','a',encoding='utf8') for comment in comments: #評論內容 contents = comment['content'] item = { # '評論時間': creationTime, # '用戶': nickname, '評論內容': contents, } string = str(item) fp.write(string + '\n') print('第%s頁完成' %(i+1)) time.sleep(2) fp.close()
分析結論
因需要分析的是“評論內容”,所以未爬取“評論時間”,“用戶”等資訊,
爬取得完后,常規操作是利用Matplotlib、Pandas等進行資料分析及可視化,現在我們用最簡單的詞頻統計工具分析,后面學會了這些工具,在完善,
此次爬取了200頁,總共2000條的評論,生成的詞云如下:

從中可以得出用戶購買豬肉關注的點:味道、價格、送貨速度、外觀、健康、售后服務、服務穩定性,這些指標在一定程度為生產經營提供了方向性參考,當然還需要進一步把這些指標拆解成具體的行動,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/224436.html
標籤:Python