前言:
由于電腦發生故障,重裝了一下系統,所以最近需要重新搭建深度學習環境,剛好趁此機會,記錄一下我的安裝的和配置程序,給剛入門深度學習的小伙伴們一個參考,
文章目錄
- 一、安裝Anaconda3
- 二、安裝PyCharm
- 三、安裝TensorFlow2.2
- 3.1 創建虛擬環境
- 3.2 安裝TensorFlow2.2
- 3.3 檢查是否安裝成功
- 四、安裝nvidia驅動
- 五、安裝Cuda10.1
- 5.1.查看電腦已裝的cuda版本
- 5.2 安裝Cuda
- 六、安裝Cudnn7.6
- 七、檢查安裝與配置是否成功
一、安裝Anaconda3
首先去Anaconda官網下載Anaconda3,我安裝的版本是Anaconda3 2020.02
具體安裝步驟,可以參考我之前的記錄:
Anaconda3+tensorflow2.0.0+PyCharm安裝與環境搭建
二、安裝PyCharm
首先去PyCharm官網下載PyCharm社區版,我安裝的版本是pycharm-community-2020.1.3
按照提示直接安裝即可,這個步驟就不贅述了!
三、安裝TensorFlow2.2
首先說明一點,對于版本TensorFlow <= 2.0.0,安裝TensorFlow是區分cpu和gpu的,到TF2.0.0版本之后,cpu和gpu合并了,也就是說采用命令pip install tensorflow默認安裝的是最穩定的TF2版本,同時支持cpu和gpu,
3.1 創建虛擬環境
由于不同的深度學習專案可能需要配置不同的版本,所以這里推薦使用conda建立虛擬環境,讓專案間的環境隔離,互不干擾,
1)首先,從開始選單找到并打開Anaconda Prompt,
2)然后,輸入以下命令,新建一個虛擬環境
conda create -n tf2.2 python==3.7
3)等創建完畢后,進入虛擬環境
conda activate tf2.2
3.2 安裝TensorFlow2.2
沒有換源的情況直接下載速度會非常慢,所以這里使用國內源下載:
pip install -i https://pypi.douban.com/simple tensorflow==2.2.0
下載完成后,可以看到如下資訊:
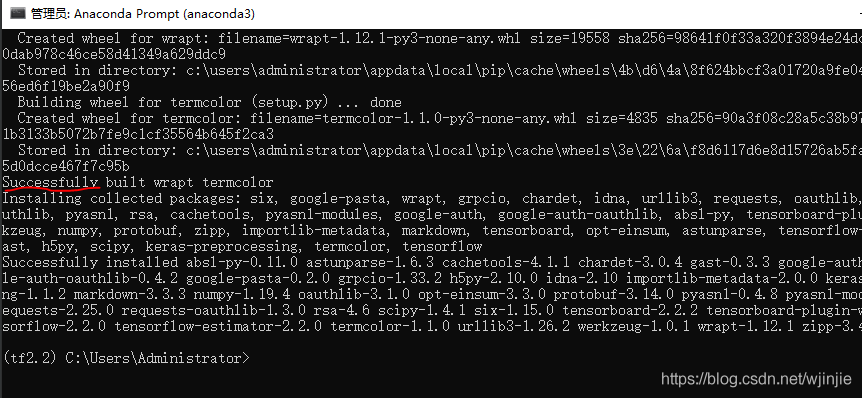
一般情況下,這就意味著安裝成功了!
3.3 檢查是否安裝成功
1)打開PyCharm,新建一個工程 First_Project

2)配置虛擬環境
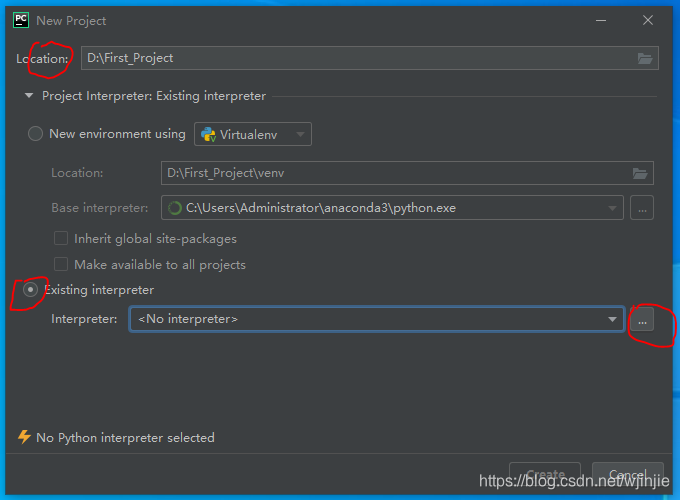
3)選擇合適的解釋器,然后點擊OK
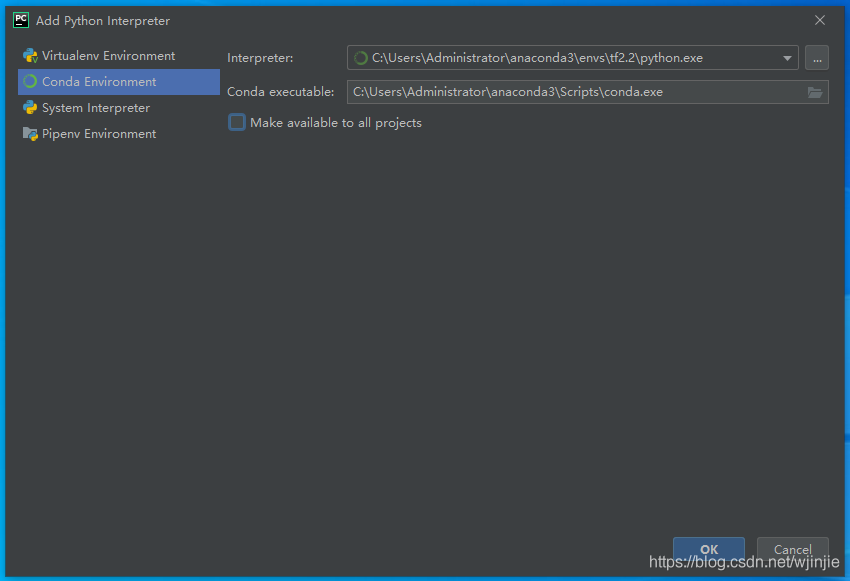
4)進入剛才新建的工程First_Project,新建一個python腳本mian.py,輸入:
import tensorflow as tf
print(tf.__version__)
點擊運行,出現以下結果表示安裝成功!

輸出的2.2.0即表示已安裝的TensorFlow版本,紅色警告是因為還沒有安裝Cuda和Cudnn,不能支持gpu訓練,接下面就來講解如何配置gpu,
注:如果報錯提示numpy有問題,多半是因為不兼容,這時需要卸載numpy,再重新安裝對應版本的numnpy1.19.3
四、安裝nvidia驅動
首先,在設備管理器中查看電腦是否已經安裝驅動,如果安裝了就跳過這一步
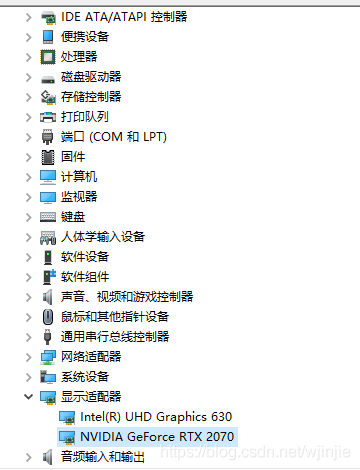
如果沒有安裝,就需要去英偉達官網下載對應對應版本的驅動,我的顯卡是RTX 2070,所以我選擇對應版本的:
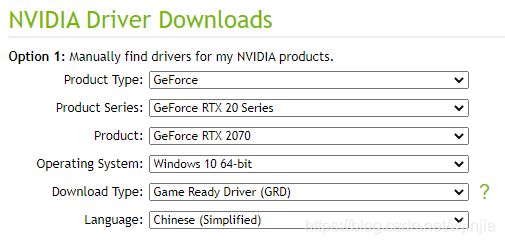
驅動安裝的教程網上比較多,這里就不做展開了,
五、安裝Cuda10.1
查看TensorFlow官網得知,TensorFlow2.2支持Cuda10.1以及Cudnn7.6.x,如下圖所示:

5.1.查看電腦已裝的cuda版本
Win+R—輸入cmd—輸入:nvcc --version
檢查看到,我這臺機器上的cuda是8.0版本的,比較老了,所以下面我要先進行卸載,
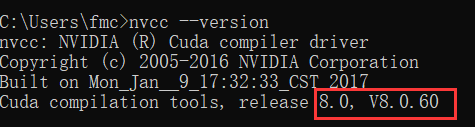
如果之前沒有裝過cuda,則掉過這一步,
5.2 安裝Cuda
根據版本要求,選擇 Cuda10.1下載下來,然后點擊exe運行,選擇自定義安裝:
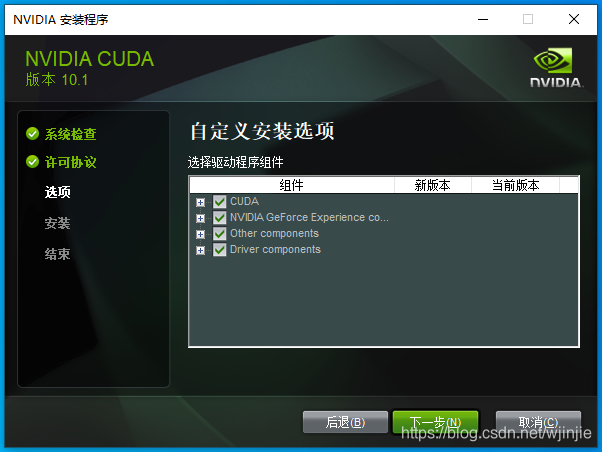
選擇下一步,然后等待安裝完成,安裝完成后,在C:\Program Files目錄下可以看到這兩個檔案:

六、安裝Cudnn7.6
首先下載 Cudnn7.6,然后進行解壓,解壓后如下:

然后,將解壓后的檔案全部復制粘貼至C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1目錄下,如下圖所示:
完成之后,可再用nvcc --version查看cuda是否安裝成功:

七、檢查安裝與配置是否成功
在剛才新建的工程First_Project中,復制一個簡單的深度學習demo至main檔案中,代碼如下:
代碼來源:TF2.0深度學習實戰(一):分類問題之手寫數字識別:
import tensorflow as tf # 匯入TF庫
from tensorflow.keras import layers, optimizers, datasets, Sequential, metrics # 匯入TF子庫
# 1.資料集準備
(x, y), (x_val, y_val) = datasets.mnist.load_data() # 加載資料集,回傳的是兩個元組,分別表示訓練集和測驗集
x = tf.convert_to_tensor(x, dtype=tf.float32)/255. # 轉換為張量,并縮放到0~1
y = tf.convert_to_tensor(y, dtype=tf.int32) # 轉換為張量(標簽)
print(x.shape, y.shape)
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 構建資料集物件
train_dataset = train_dataset.batch(32).repeat(10) # 設定批量訓練的batch為32,要將訓練集重復訓練10遍
# 2.網路搭建
network = Sequential([
layers.Dense(256, activation='relu'), # 第一層
layers.Dense(128, activation='relu'), # 第二層
layers.Dense(10) # 輸出層
])
network.build(input_shape=(None, 28*28)) # 輸入
# network.summary()
# 3.模型訓練(計算梯度,迭代更新網路引數)
optimizer = optimizers.SGD(lr=0.01) # 宣告采用批量隨機梯度下降方法,學習率=0.01
acc_meter = metrics.Accuracy() # 創建準確度測量器
for step, (x, y) in enumerate(train_dataset): # 一次輸入batch組資料進行訓練
with tf.GradientTape() as tape: # 構建梯度記錄環境
x = tf.reshape(x, (-1, 28*28)) # 將輸入拉直,[b,28,28]->[b,784]
out = network(x) # 輸出[b, 10]
y_onehot = tf.one_hot(y, depth=10) # one-hot編碼
loss = tf.square(out - y_onehot)
loss = tf.reduce_sum(loss)/32 # 定義均方差損失函式,注意此處的32對應為batch的大小
grads = tape.gradient(loss, network.trainable_variables) # 計算網路中各個引數的梯度
optimizer.apply_gradients(zip(grads, network.trainable_variables)) # 更新網路引數
acc_meter.update_state(tf.argmax(out, axis=1), y) # 比較預測值與標簽,并計算精確度
if step % 200 == 0: # 每200個step,列印一次結果
print('Step', step, ': Loss is: ', float(loss), ' Accuracy: ', acc_meter.result().numpy())
acc_meter.reset_states() # 每一個step后準確度清零
點擊運行,開始訓練,可得到如下結果:
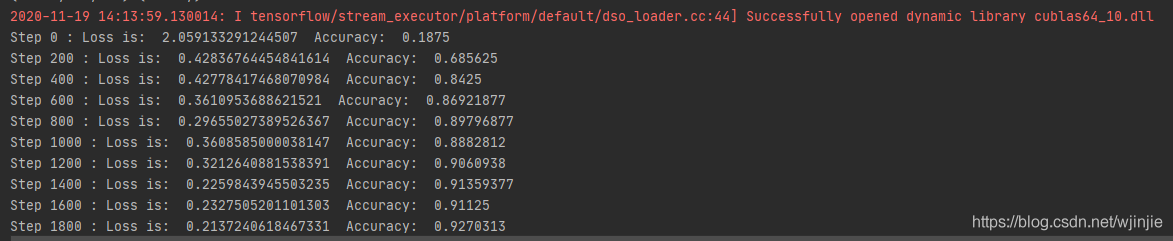
第一行紅色的字體,表明這次成功的加載了動態庫,可以使用GPU進行訓練了,
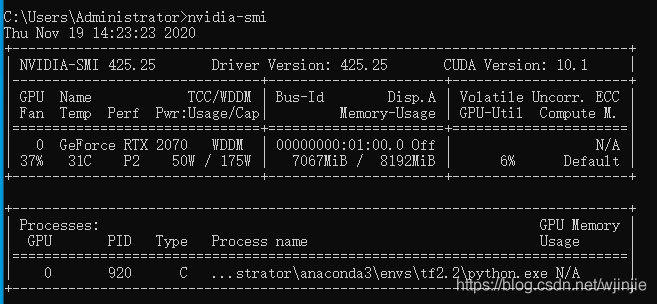
如果你想進一步確定GPU的使用狀態,可以在cmd命令列輸入:nvidia-smi 進行查看,如下圖所示:
最后,如果你在學習AI之路上,有任何問題,可以加入群聊,我們一起討論~
 CSDN認證博客專家
CSDN博客專家
CSDN簽約作者
演算法實習生
CSDN認證博客專家
CSDN博客專家
CSDN簽約作者
演算法實習生
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/225348.html
標籤:python