文章目錄
- 寫在前面
- 一、需求分析
- 二、編程思路
- 1.翻頁問題
- 2.內容分析
- 三、具體步驟
- 1.用到的庫
- 2.提取資訊的正則運算式
- 3.得到指定的url網頁內容
- 4.提取內容
- 5.保存封面圖片到本地
- 6.資訊保存為Excel格式
- 四、完整代碼
- 寫在最后
寫在前面
??爬取豆瓣資訊的例子之前也有人做過,只不過大多數用的是xpath,還有就是很多博主寫的不夠細(劃重點:細)😃 這里我在查找了各種資料之后寫這篇文章,主要功能就是爬取豆瓣top250電影資訊保存為excel格式,并且將每部電影的封面保存在本地,最后本著互聯網開放共享的原則,我也會將完整原始碼無償奉上,謝謝支持~
一、需求分析
??爬取豆瓣top250的基本資訊,包括電影的名稱、豆瓣評分、評價數、電影概況、電影連接、圖片鏈接和一些其他資訊,
網站鏈接: https://movie.douban.com/top250
先帶大家看一下最后的效果:
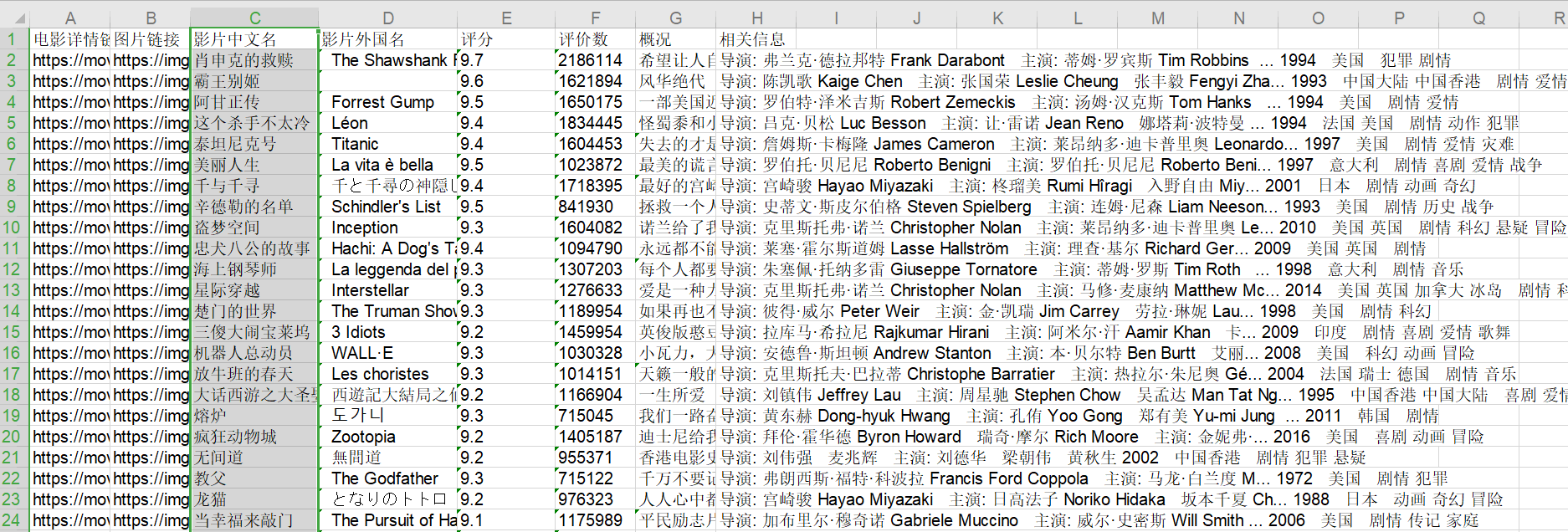
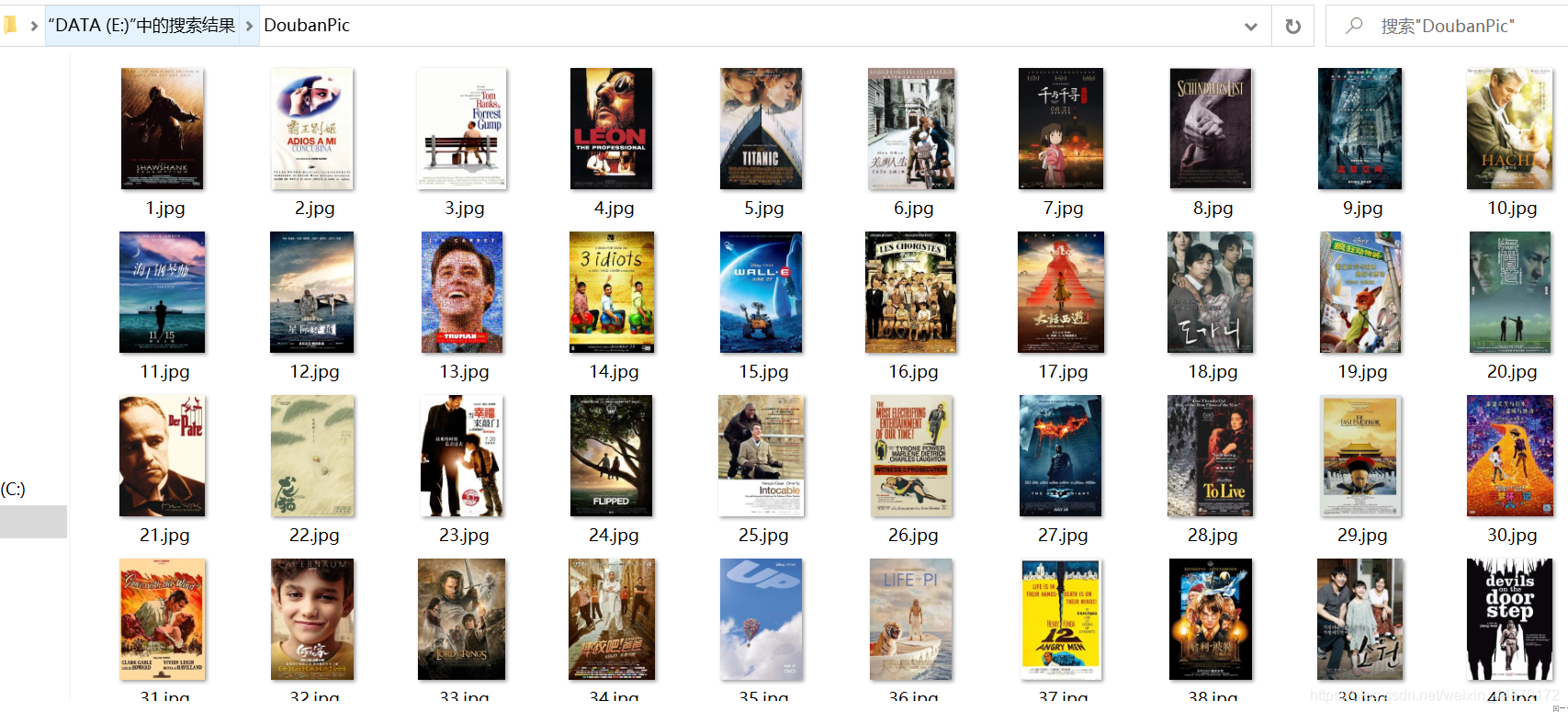
可以看到資訊已經保存在了excel中,影片的封面圖片也全部存在了本地,下面來看具體的實作程序,
二、編程思路
??每個爬蟲最開始的時候都要看網站結構,所以我們先看一下豆瓣的網站結構,主要找到我們要的資訊保存在了哪個部分,
1.翻頁問題
??大家仔細觀察一下top250的網站就是會發現,每個網頁展示25條電影資訊,共25頁,
第一頁url:https://movie.douban.com/top250
第二頁url:https://movie.douban.com/top250?start=25&filter=
第三頁url:https://movie.douban.com/top250?start=50&filter=
通過我列出的上述3頁,其實每一頁網址的變化規律就顯而易見了,一頁可以顯示25部電影,就是說這250部電影一共有10頁,觀察前第一頁的網址,filter去掉并不影響,第一頁也可以按照我們發現的規律在后邊加上?start=25即https://movie.douban.com/top250?start=0,完全也可以進入,
所以很容易發現規律:就是start后面跟的引數變化,等于(頁數-1)*25,
??有了這個規律,我們就很容易解決翻頁問題了,只需要定義變數按照網頁變化的規律去回圈即可,
2.內容分析
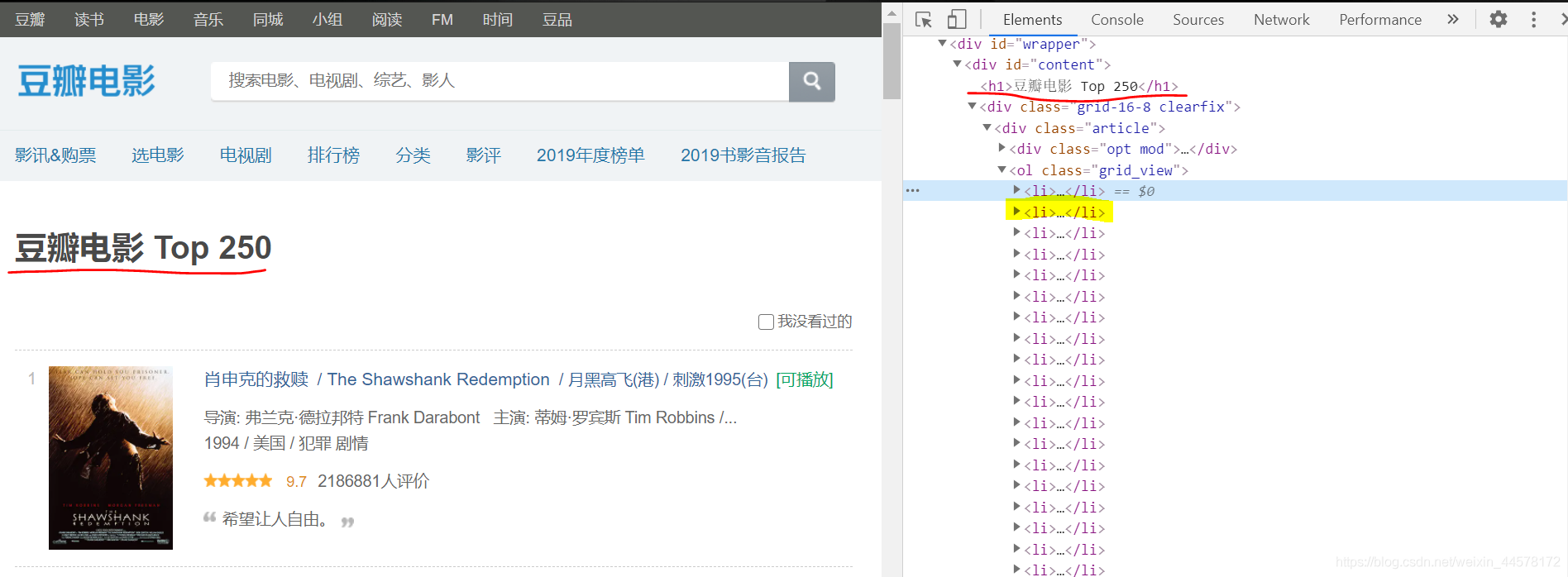
??對第一頁網站觀察其實不難發現所有的這一頁電影資訊都存在了<li>標簽下,以第一部電影(肖申克的救贖)為例,為例方便觀察我把關于這一部電影的有關資訊原始碼復制了下來
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救贖" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救贖</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飛(港) / 刺激1995(臺)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
導演: 弗蘭克·德拉邦特 Frank Darabont 主演: 蒂姆·羅賓斯 Tim Robbins /...<br>
1994 / 美國 / 犯罪 劇情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2186881人評價</span>
</div>
<p class="quote">
<span class="inq">希望讓人自由,</span>
</p>
</div>
</div>
</div>
</li>
我們發現所有的資訊都在一個<div>標簽下,并且標簽的屬性名是item,這就很簡單了,我們可以用find_all方法去遍歷所有的class="item"就能拿到每一步電影的所有資訊,然后再用正則運算式去提取我們想要的資訊放到串列中即可,以上就是一些核心的思路,光說沒什么意思,下面我們來具體看代碼,
三、具體步驟
1.用到的庫
import os
from bs4 import BeautifulSoup #網頁決議,獲取資料
import re
import xlwt #進行excel操作
import urllib.request,urllib.error #指定url,獲取網頁資料
2.提取資訊的正則運算式
#影片詳情鏈接規則
findLink = re.compile(r'<a href="(.*?)">') #創建正則運算式物件,表示規則(字串的模式)r表示忽視特殊符號避免需要重新轉義
#影片圖片的鏈接
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)#re.S表示讓換行符包含在字符中
#影片片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
#影片評分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#評價人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#概況
findInq = re.compile(r'<span class="inq">(.*)</span>')
#找到影片的相關內容
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
這里我將用到的正則運算式直接給出,大家可以對照上面貼出來的html代碼一一對應,還有問題的話評論私信我都可以~
3.得到指定的url網頁內容
#得到指定一個url的網頁內容
def askURL(url):
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)#列印錯誤資訊
if hasattr(e, "reason"):
print(e.reason)#列印錯誤原因
return html
將獲取指定的url功能封裝成函式主要是為了方便我們后邊對每一個網頁中的內容提取更加方便,
4.提取內容
??利用第二步制定好的正則運算式規則,提取網頁標簽內我們想要的所有資訊,
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url) #保存獲取到的網頁原始碼
#逐一決議資料
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):#查找符合要求的字串,形成串列,class加下劃線表示屬性值
data = [] #保存一部電影的所有資訊
item = str(item) #將item轉換為字串
#影片詳情鏈接
link = re.findall(findLink, item)[0]
#追加內容到串列
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2 ):
ctitle = titles[0]
data.append(ctitle) #添加中文名
otitle = titles[1].replace("/", "") #去掉無關符號
data.append(otitle) #添加外國名
else:
data.append(titles[0])
data.append(' ') #外國名如果沒有則留空
rating = re.findall(findRating,item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0 :
inq = inq[0].replace(",", "")
data.append(inq)
else:
data.append(' ')
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ", bd) #去掉<br/>
bd = re.sub('/', " ", bd) # 去掉/
data.append(bd.strip()) #去掉前后空格
datalist.append(data) #把處理好的一部電影資訊放入datalist
#print(link)
5.保存封面圖片到本地
??在第四步中我們其實已經獲取到了圖片的鏈接就是imgSrc,所以在這里我們直接用urllib的urlretrieve方法來下載并保存在想要的路徑,
root = "自己定義"#我的是"E://DoubanPic//"
path = root + str(x) + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
#r = requests.get(imgSrc, headers=head)
urllib.request.urlretrieve(imgSrc,path)
#with open(path, 'wb') as f:
# f.write(r.content)
# f.close()
print("下載第%d部電影封面"%(x))
x += 1
else:
print("檔案保存成功")
except:
print("下載失敗")
6.資訊保存為Excel格式
??這一部分就是對excel檔案的操作,呼叫xlwt庫創建一個excel物件,再創建一個sheet表單,在excel中所有的單元格都可以看作是一個二維矩陣,第一行第一列就是(0,0),定位好單元格的位置,我們用write方法往里面寫內容就好了,
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 創建workbook物件
sheet = book.add_sheet("豆瓣電影Top250",cell_overwrite_ok=True) # 創建作業表
col = ('電影詳情鏈接',"圖片鏈接","影片中文名","影片外國名","評分","評價數","概況","相關資訊")#定義元組
try:
for i in range(0,8):
sheet.write(0,i,col[i]) #輸入列名
for i in range(0,250):
print("第%d條" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
except:
print("爬取例外")
四、完整代碼
'''
需求分析:
爬取豆瓣top250的基本資訊,包括電影的名稱、豆瓣評分、評價數、電影概況、電影連接等
網站鏈接:https://movie.douban.com/top250
'''
#-*- coding = utf-8 -*-
# 宣告編碼方式
import os
from bs4 import BeautifulSoup #網頁決議,獲取資料
import re
import xlwt #進行excel操作
import urllib.request,urllib.error #指定url,獲取網頁資料
def main():
baseurl = "https://movie.douban.com/top250?start="
#獲取網頁
datalist = getDate(baseurl)
savepath = "excel保存路徑自己定義"#我的是".\\豆瓣電影Top250.xls"
#保存資料
saveData(datalist, savepath)
head = {
"User-Agent":"Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 85.0.4183.121Safari / 537.36"
}#用戶代理:表示告訴豆瓣服務器是什么型別的瀏覽器(本質上是告訴瀏覽器可接收什么型別的檔案)
#影片詳情鏈接規則
findLink = re.compile(r'<a href="(.*?)">') #創建正則運算式物件,表示規則(字串的模式)r表示忽視特殊符號避免需要重新轉義
#影片圖片的鏈接
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)#re.S表示讓換行符包含在字符中
#影片片名
findTitle = re.compile(r'<span class="title">(.*)</span>')
#影片評分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#評價人數
findJudge = re.compile(r'<span>(\d*)人評價</span>')
#概況
findInq = re.compile(r'<span class="inq">(.*)</span>')
#找到影片的相關內容
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
#爬取網頁
def getDate(baseurl):
datalist = []
x = 1
#呼叫獲取頁面資訊的函式(10次)
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url) #保存獲取到的網頁原始碼
#逐一決議資料
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('div', class_="item"):#查找符合要求的字串,形成串列,class加下劃線表示屬性值
data = [] #保存一部電影的所有資訊
item = str(item) #將item轉換為字串
#影片詳情鏈接
link = re.findall(findLink, item)[0]
#追加內容到串列
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2 ):
ctitle = titles[0]
data.append(ctitle) #添加中文名
otitle = titles[1].replace("/", "") #去掉無關符號
data.append(otitle) #添加外國名
else:
data.append(titles[0])
data.append(' ') #外國名如果沒有則留空
rating = re.findall(findRating,item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0 :
inq = inq[0].replace(",", "")
data.append(inq)
else:
data.append(' ')
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ", bd) #去掉<br/>
bd = re.sub('/', " ", bd) # 去掉/
data.append(bd.strip()) #去掉前后空格
datalist.append(data) #把處理好的一部電影資訊放入datalist
#print(link)
# 下載圖片到本地
root = "路徑自己定義"#我的是"E://DoubanPic//"
path = root + str(x) + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
#r = requests.get(imgSrc, headers=head)
urllib.request.urlretrieve(imgSrc,path)
#with open(path, 'wb') as f:
# f.write(r.content)
# f.close()
print("下載第%d部電影封面"%(x))
x += 1
else:
print("檔案保存成功")
except:
print("下載失敗")
return datalist
#得到指定一個url的網頁內容
def askURL(url):
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)#列印錯誤資訊
if hasattr(e, "reason"):
print(e.reason)#列印錯誤原因
return html
#保存資料
def saveData(datalist, savepath):
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 創建workbook物件
sheet = book.add_sheet("豆瓣電影Top250",cell_overwrite_ok=True) # 創建作業表
col = ('電影詳情鏈接',"圖片鏈接","影片中文名","影片外國名","評分","評價數","概況","相關資訊")#定義元組
try:
for i in range(0,8):
sheet.write(0,i,col[i]) #輸入列名
for i in range(0,250):
print("第%d條" %(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath)
except:
print("爬取例外")
if __name__ == '__main__':
main()
print("爬取完畢")
注:以上代碼中的excel保存路徑和圖片保存路徑我都注釋掉了,大家可以自己定義,千萬不要直接復制原始碼來用哦,如果不太會定義的話,可以參考后邊我注釋里的路徑
寫在最后
??關于圖片下載部分,可以用urllib庫,也可以使用requests庫,urllib庫的方法就是我上邊給出來的(細心的同學應該能看到),注釋的部分就是requests庫的方法,下邊是代碼
root = "路徑自己定義"#我的是"E://DoubanPic//"
path = root + str(x) + '.jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(imgSrc, headers=head)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("下載第%d部電影封面"%(x))
x += 1
else:
print("檔案保存成功")
except:
print("下載失敗")
小知識點:因為圖片是二進制,所以使用了content方法轉換為二進制存盤,在使用requests庫的時候一定記得import requests喔~
??本篇完,如有錯誤歡迎指出~
ps:如果有任何問題,歡迎評論或者私信我哦~如果本篇能夠幫助到你,還希望給一個大大滴贊 :)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/225350.html
標籤:python
下一篇:Python基礎語言概述