一.布隆過濾器
布隆過濾器(Bloom Filter)是1970年由布隆提出的,它實際上是一個很長的二進制向量和一系列隨機映射函式,布隆過濾器可以用于檢索一個元素是否在一個集合中,它的優點是空間效率和查詢時間都遠遠超過一般的演算法,缺點是有一定的誤識別率和洗掉困難,
如果想判斷一個元素是不是在一個集合里,一般想到的是將集合中所有元素保存起來,然后通過比較確定,鏈表、樹、散串列(又叫哈希表,Hash table)等等資料結構都是這種思路,但是隨著集合中元素的增加,我們需要的存盤空間越來越大,同時檢索速度也越來越慢,上述三種結構的檢索時間復雜度分別為:O(n), O(log n), O(n/k),
布隆過濾器的原理是,當一個元素被加入集合時,通過K個Hash函式將這個元素映射成一個位陣列中的K個點,把它們置為1,檢索時,我們只要看看這些點是不是都是1就(大約)知道集合中有沒有它了:如果這些點有任何一個0,則被檢元素一定不在;如果都是1,則被檢元素很可能在,這就是布隆過濾器的基本思想,
布隆過濾器資料結構
布隆過濾器是一個 bit 向量或者說 bit 陣列,長這樣:
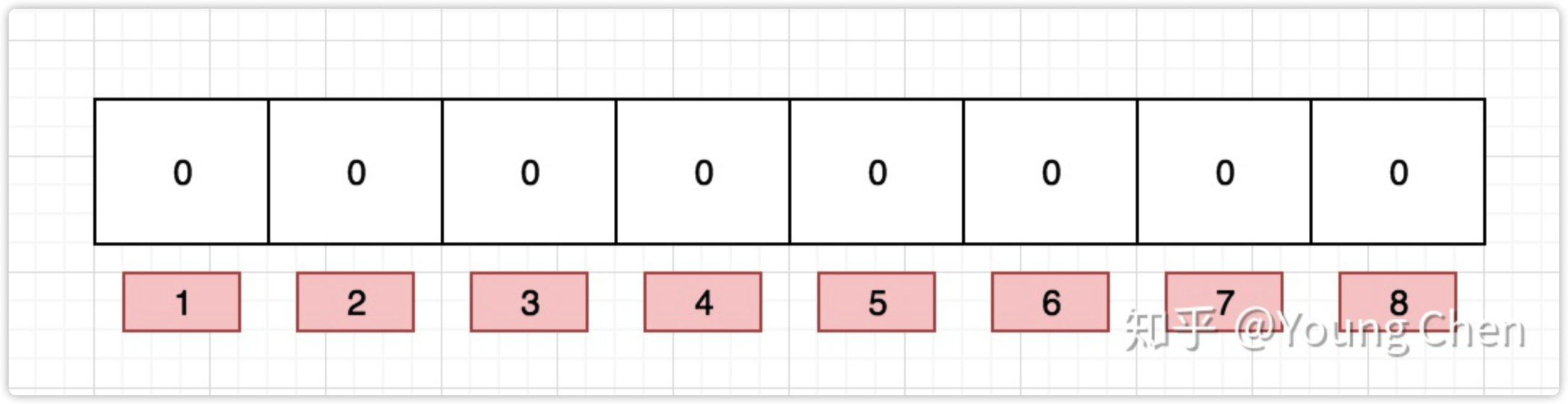
如果我們要映射一個值到布隆過濾器中,我們需要使用多個不同的哈希函式生成多個哈希值,并對每個生成的哈希值指向的 bit 位置 1,例如針對值 “baidu” 和三個不同的哈希函式分別生成了哈希值 1、4、7,則上圖轉變為:
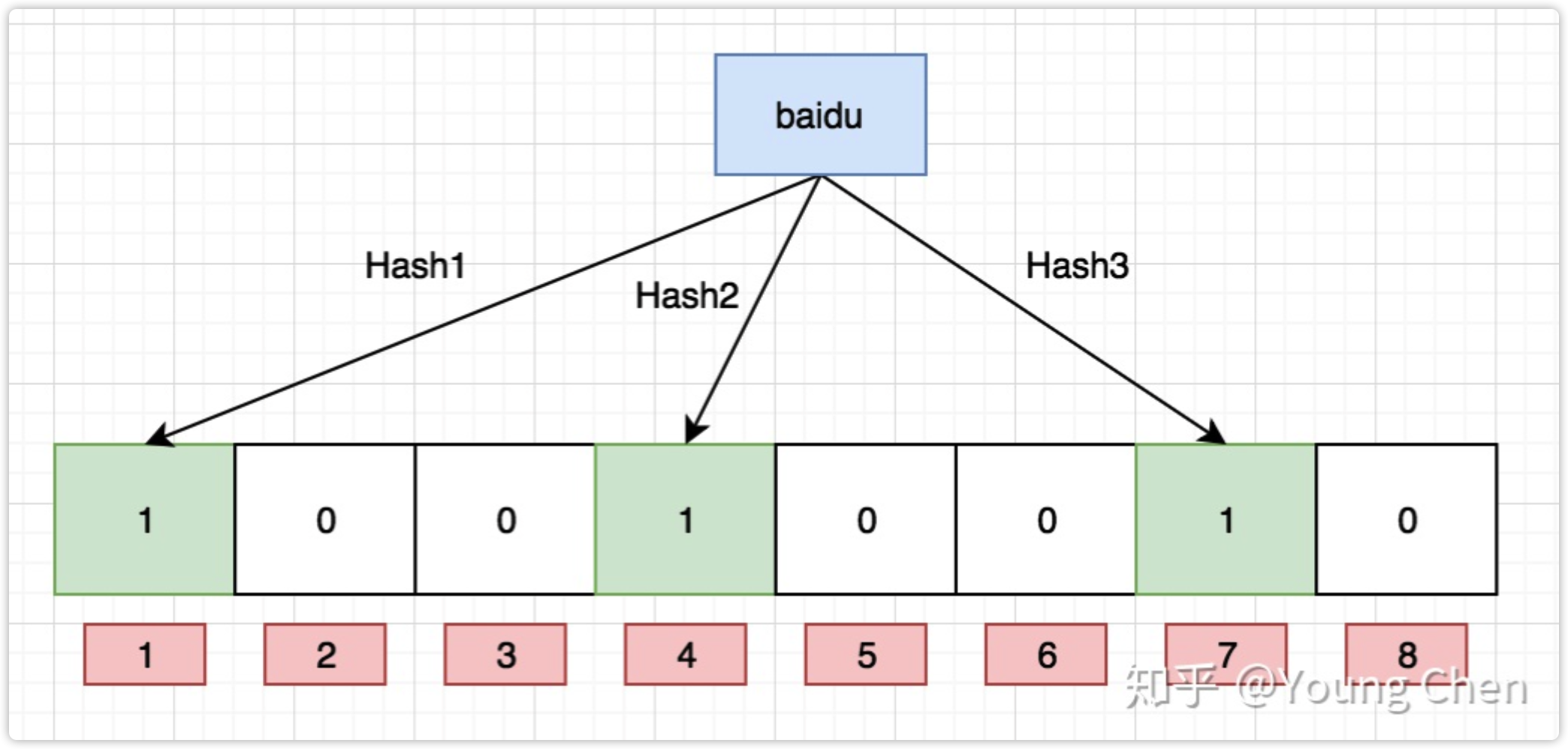
Ok,我們現在再存一個值 “tencent”,如果哈希函式回傳 3、4、8 的話,圖繼續變為:
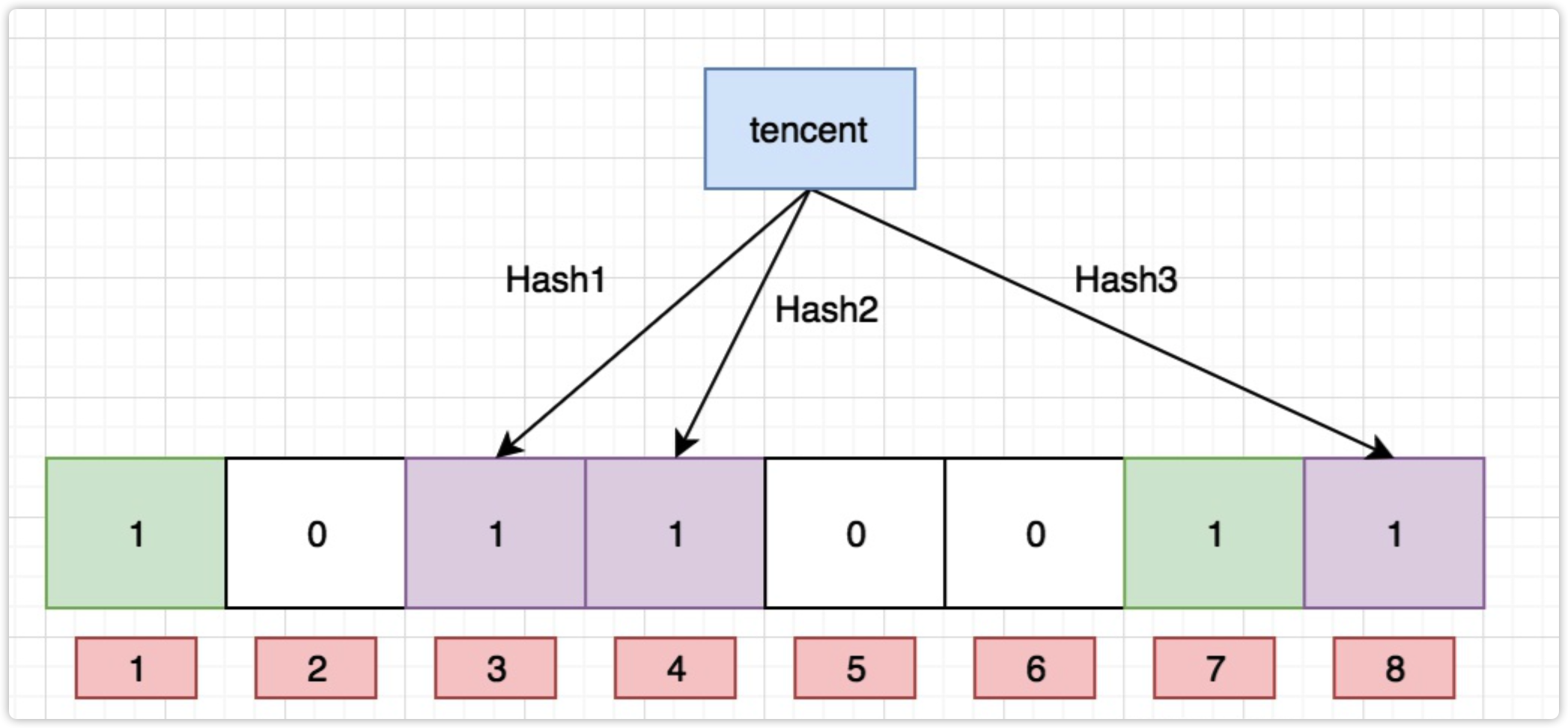
值得注意的是,4 這個 bit 位由于兩個值的哈希函式都回傳了這個 bit 位,因此它被覆寫了,現在我們如果想查詢 “dianping” 這個值是否存在,哈希函式回傳了 1、5、8三個值,結果我們發現 5 這個 bit 位上的值為 0,說明沒有任何一個值映射到這個 bit 位上,因此我們可以很確定地說 “dianping” 這個值不存在,而當我們需要查詢 “baidu” 這個值是否存在的話,那么哈希函式必然會回傳 1、4、7,然后我們檢查發現這三個 bit 位上的值均為 1,那么我們可以說 “baidu” 存在了么?答案是不可以,只能是 “baidu” 這個值可能存在,
這是為什么呢?答案跟簡單,因為隨著增加的值越來越多,被置為 1 的 bit 位也會越來越多,這樣某個值 “taobao” 即使沒有被存盤過,但是萬一哈希函式回傳的三個 bit 位都被其他值置位了 1 ,那么程式還是會判斷 “taobao” 這個值存在,
支持洗掉么
目前我們知道布隆過濾器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上圖中的 bit 位 4 被兩個值共同覆寫的話,一旦你洗掉其中一個值例如 “tencent” 而將其置位 0,那么下次判斷另一個值例如 “baidu” 是否存在的話,會直接回傳 false,而實際上你并沒有洗掉它,
如何解決這個問題,答案是計數洗掉,但是計數洗掉需要存盤一個數值,而不是原先的 bit 位,會增大占用的記憶體大小,這樣的話,增加一個值就是將對應索引槽上存盤的值加一,洗掉則是減一,判斷是否存在則是看值是否大于0,
代碼簡單實作布隆過濾器
package com.jd.demo.test;
import java.util.Arrays;
import java.util.BitSet;
import java.util.concurrent.atomic.AtomicBoolean;
public class MyBloomFilter {
//你的布隆過濾器容量
private static final int DEFAULT_SIZE = 2 << 28;
//bit陣列,用來存放結果
private static BitSet bitSet = new BitSet(DEFAULT_SIZE);
//后面hash函式會用到,用來生成不同的hash值,可隨意設定,別問我為什么這么多8,圖個吉利
private static final int[] ints = {1, 6, 16, 38, 58, 68};
//add方法,計算出key的hash值,并將對應下標置為true
public void add(Object key) {
Arrays.stream(ints).forEach(i -> bitSet.set(hash(key, i)));
}
//判斷key是否存在,true不一定說明key存在,但是false一定說明不存在
public boolean isContain(Object key) {
boolean result = true;
for (int i : ints) {
//短路與,只要有一個bit位為false,則回傳false
result = result && bitSet.get(hash(key, i));
}
return result;
}
//hash函式,借鑒了hashmap的擾動演算法
private int hash(Object key, int i) {
int h;
return key == null ? 0 : (i * (DEFAULT_SIZE - 1) & ((h = key.hashCode()) ^ (h >>> 16)));
}
}
測驗
public static void main(String[] args) {
MyNewBloomFilter myNewBloomFilter = new MyNewBloomFilter();
myNewBloomFilter.add("張學友");
myNewBloomFilter.add("郭德綱");
myNewBloomFilter.add(666);
System.out.println(myNewBloomFilter.isContain("張學友"));//true
System.out.println(myNewBloomFilter.isContain("張學友 "));//false
System.out.println(myNewBloomFilter.isContain("張學友1"));//false
System.out.println(myNewBloomFilter.isContain("郭德綱"));//true
System.out.println(myNewBloomFilter.isContain(666));//true
System.out.println(myNewBloomFilter.isContain(888));//false
}
二.具體代碼使用
在實際應用當中,我們不需要自己去實作BloomFilter,可以使用Guava提供的相關類別庫即可,
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>12345
判斷一個元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 獲取開始時間
//判斷這一百萬個數中是否包含29999這個數
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 獲取結束時間
System.out.println("程式運行時間: " + (endTime - startTime) + "納秒");
}
}
運行結果如下:
命中了
程式運行時間: 441616納秒
自定義錯誤率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000個不在過濾器里的值,看看有多少個會被認為在過濾器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("誤判的數量:" + list.size());
}
}
運行結果如下:
誤判的數量:941
對于快取宕機的場景,使用白名單或者布隆過濾器都有可能會造成一定程度的誤判,原因是除了Bloom Filter 本身有誤判率,宕機之前的快取不一定能覆寫到所有DB中的資料,當宕機后用戶請求了一個以前從未請求的資料,這個時候就會產生誤判,當然,快取宕機時使用白名單/布隆過濾器作為應急的方式,這種情況應該也是可以忍受的,
站在巨人肩膀上摘蘋果
https://blog.csdn.net/qq_33709582/article/details/108407706
https://blog.csdn.net/fouy_yun/article/details/81075432
https://blog.csdn.net/qq_34707456/article/details/102831753?utm_medium=distribute.pc_relevant.none-task-blog-title-3&spm=1001.2101.3001.4242
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/225558.html
標籤:Java