2020年最新ZooKeeper面試題
1. ZooKeeper 是什么?
ZooKeeper 是一個開源的分布式協調服務,它是一個為分布式應用提供一致性服務的軟體,分布式應用程式可以基于 Zookeeper 實作諸如資料發布/訂閱、負載均衡、命名服務、分布式協調/通知、集群管理、Master 選舉、分布式鎖和分布式佇列等功能,
ZooKeeper 的目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的介面和性能高效、功能穩定的系統提供給用戶,
Zookeeper 保證了如下分布式一致性特性:
(1)順序一致性
(2)原子性
(3)單一視圖
(4)可靠性
(5)實時性(最終一致性)
客戶端的讀請求可以被集群中的任意一臺機器處理,如果讀請求在節點上注冊了監聽器,這個監聽器也是由所連接的 zookeeper 機器來處理,對于寫請求,這些請求會同時發給其他 zookeeper 機器并且達成一致后,請求才會回傳成功,因此,隨著 zookeeper 的集群機器增多,讀請求的吞吐會提高但是寫請求的吞吐會下降,
有序性是 zookeeper 中非常重要的一個特性,所有的更新都是全域有序的,每個更新都有一個唯一的時間戳,這個時間戳稱為 zxid(Zookeeper Transaction Id),而讀請求只會相對于更新有序,也就是讀請求的回傳結果中會帶有這個zookeeper 最新的 zxid,
2. ZooKeeper 提供了什么?
- 檔案系統
- 通知機制
3. Zookeeper 檔案系統
Zookeeper 提供一個多層級的節點命名空間(節點稱為 znode),與檔案系統不同的是,這些節點都可以設定關聯的資料,而檔案系統中只有檔案節點可以存放資料而目錄節點不行,
Zookeeper 為了保證高吞吐和低延遲,在記憶體中維護了這個樹狀的目錄結構,這種特性使得 Zookeeper 不能用于存放大量的資料,每個節點的存放資料上限為1M,
4. Zookeeper 怎么保證主從節點的狀態同步?
Zookeeper 的核心是原子廣播機制,這個機制保證了各個 server 之間的同步,實作這個機制的協議叫做 Zab 協議,Zab 協議有兩種模式,它們分別是恢復模式和廣播模式,
- 恢復模式
當服務啟動或者在領導者崩潰后,Zab就進入了恢復模式,當領導者被選舉出來,且大多數 server 完成了和 leader 的狀態同步以后,恢復模式就結束了,狀態同步保證了 leader 和 server 具有相同的系統狀態,
- 廣播模式
一旦 leader 已經和多數的 follower 進行了狀態同步后,它就可以開始廣播訊息了,即進入廣播狀態,這時候當一個 server 加入 ZooKeeper 服務中,它會在恢復模式下啟動,發現 leader,并和 leader 進行狀態同步,待到同步結束,它也參與訊息廣播,ZooKeeper 服務一直維持在 Broadcast 狀態,直到 leader 崩潰了或者 leader 失去了大部分的 followers 支持,
5. 四種型別的資料節點 Znode
(1)PERSISTENT-持久節點
除非手動洗掉,否則節點一直存在于 Zookeeper 上
(2)EPHEMERAL-臨時節點
臨時節點的生命周期與客戶端會話系結,一旦客戶端會話失效(客戶端與zookeeper 連接斷開不一定會話失效),那么這個客戶端創建的所有臨時節點都會被移除,
(3)PERSISTENT_SEQUENTIAL-持久順序節點
基本特性同持久節點,只是增加了順序屬性,節點名后邊會追加一個由父節點維護的自增整型數字,
(4)EPHEMERAL_SEQUENTIAL-臨時順序節點
基本特性同臨時節點,增加了順序屬性,節點名后邊會追加一個由父節點維護的自增整型數字,
6. Zookeeper Watcher 機制 – 資料變更通知
Zookeeper 允許客戶端向服務端的某個 Znode 注冊一個 Watcher 監聽,當服務端的一些指定事件觸發了這個 Watcher,服務端會向指定客戶端發送一個事件通知來實作分布式的通知功能,然后客戶端根據 Watcher 通知狀態和事件型別做出業務上的改變,
作業機制:
(1)客戶端注冊 watcher
(2)服務端處理 watcher
(3)客戶端回呼 watcher
Watcher 特性總結:
(1)一次性
無論是服務端還是客戶端,一旦一個 Watcher 被 觸 發 ,Zookeeper 都會將其從相應的存盤中移除,這樣的設計有效的減輕了服務端的壓力,不然對于更新非常頻繁的節點,服務端會不斷的向客戶端發送事件通知,無論對于網路還是服務端的壓力都非常大,
(2)客戶端串行執行
客戶端 Watcher 回呼的程序是一個串行同步的程序,
(3)輕量
3.1、Watcher 通知非常簡單,只會告訴客戶端發生了事件,而不會說明事件的具體內容,
3.2、客戶端向服務端注冊 Watcher 的時候,并不會把客戶端真實的 Watcher 物件物體傳遞到服務端,僅僅是在客戶端請求中使用 boolean 型別屬性進行了標記,
(4)watcher event 異步發送 watcher 的通知事件從 server 發送到 client 是異步的,這就存在一個問題,不同的客戶端和服務器之間通過 socket 進行通信,由于網路延遲或其他因素導致客戶端在不通的時刻監聽到事件,由于 Zookeeper 本身提供了 ordering guarantee,即客戶端監聽事件后,才會感知它所監視 znode發生了變化,所以我們使用 Zookeeper 不能期望能夠監控到節點每次的變化,Zookeeper 只能保證最終的一致性,而無法保證強一致性,
(5)注冊 watcher getData、exists、getChildren
(6)觸發 watcher create、delete、setData
(7)當一個客戶端連接到一個新的服務器上時,watch 將會被以任意會話事件觸發,當與一個服務器失去連接的時候,是無法接收到 watch 的,而當 client 重新連接時,如果需要的話,所有先前注冊過的 watch,都會被重新注冊,通常這是完全透明的,只有在一個特殊情況下,watch 可能會丟失:對于一個未創建的 znode的 exist watch,如果在客戶端斷開連接期間被創建了,并且隨后在客戶端連接上之前又洗掉了,這種情況下,這個 watch 事件可能會被丟失,
7. 客戶端注冊 Watcher 實作
(1)呼叫 getData()/getChildren()/exist()三個 API,傳入 Watcher 物件
(2)標記請求 request,封裝 Watcher 到 WatchRegistration
(3)封裝成 Packet 物件,發服務端發送 request
(4)收到服務端回應后,將 Watcher 注冊到 ZKWatcherManager 中進行管理
(5)請求回傳,完成注冊,
8. 服務端處理 Watcher 實作
(1)服務端接收 Watcher 并存盤
接收到客戶端請求,處理請求判斷是否需要注冊 Watcher,需要的話將資料節點的節點路徑和 ServerCnxn(ServerCnxn 代表一個客戶端和服務端的連接,實作了 Watcher 的 process 介面,此時可以看成一個 Watcher 物件)存盤在WatcherManager 的 WatchTable 和 watch2Paths 中去,
(2)Watcher 觸發
以服務端接收到 setData() 事務請求觸發 NodeDataChanged 事件為例:
2.1 封裝 WatchedEvent
將通知狀態(SyncConnected)、事件型別(NodeDataChanged)以及節點路徑封裝成一個 WatchedEvent 物件
2.2 查詢 Watcher
從 WatchTable 中根據節點路徑查找 Watcher
2.3 沒找到;說明沒有客戶端在該資料節點上注冊過 Watcher
2.4 找到;提取并從 WatchTable 和 Watch2Paths 中洗掉對應 Watcher(從這里可以看出 Watcher 在服務端是一次性的,觸發一次就失效了)
(3)呼叫 process 方法來觸發 Watcher
這里 process 主要就是通過 ServerCnxn 對應的 TCP 連接發送 Watcher 事件通知,
9. 客戶端回呼 Watcher
客戶端 SendThread 執行緒接收事件通知,交由 EventThread 執行緒回呼 Watcher,
客戶端的 Watcher 機制同樣是一次性的,一旦被觸發后,該 Watcher 就失效了,
10. ACL 權限控制機制
UGO(User/Group/Others)
目前在 Linux/Unix 檔案系統中使用,也是使用最廣泛的權限控制方式,是一種粗粒度的檔案系統權限控制模式,
ACL(Access Control List)訪問控制串列
包括三個方面:
權限模式(Scheme)
(1)IP:從 IP 地址粒度進行權限控制
(2)Digest:最常用,用類似于 username:password 的權限標識來進行權限配置,便于區分不同應用來進行權限控制
(3)World:最開放的權限控制方式,是一種特殊的 digest 模式,只有一個權限標識“world:anyone”
(4)Super:超級用戶
授權物件
授權物件指的是權限賦予的用戶或一個指定物體,例如 IP 地址或是機器燈,
權限 Permission
(1)CREATE:資料節點創建權限,允許授權物件在該 Znode 下創建子節點
(2)DELETE:子節點洗掉權限,允許授權物件洗掉該資料節點的子節點
(3)READ:資料節點的讀取權限,允許授權物件訪問該資料節點并讀取其資料內容或子節點串列等
(4)WRITE:資料節點更新權限,允許授權物件對該資料節點進行更新操作
(5)ADMIN:資料節點管理權限,允許授權物件對該資料節點進行 ACL 相關設定操作
11. Chroot 特性
3.2.0 版本后,添加了 Chroot 特性,該特性允許每個客戶端為自己設定一個命名空間,如果一個客戶端設定了 Chroot,那么該客戶端對服務器的任何操作,都將會被限制在其自己的命名空間下,
通過設定 Chroot,能夠將一個客戶端應用于 Zookeeper 服務端的一顆子樹相對應,在那些多個應用公用一個 Zookeeper 進群的場景下,對實作不同應用間的相互隔離非常有幫助,
12. 會話管理
分桶策略:將類似的會話放在同一區塊中進行管理,以便于 Zookeeper 對會話進行不同區塊的隔離處理以及同一區塊的統一處理,
分配原則:每個會話的“下次超時時間點”(ExpirationTime)
計算公式:
ExpirationTime_ = currentTime + sessionTimeout
ExpirationTime = (ExpirationTime_ / ExpirationInrerval + 1) *
ExpirationInterval , ExpirationInterval 是指 Zookeeper 會話超時檢查時間間隔,默認 tickTime
13. 服務器角色
Leader
(1)事務請求的唯一調度和處理者,保證集群事務處理的順序性
(2)集群內部各服務的調度者
Follower
(1)處理客戶端的非事務請求,轉發事務請求給 Leader 服務器
(2)參與事務請求 Proposal 的投票
(3)參與 Leader 選舉投票
Observer
(1)3.0 版本以后引入的一個服務器角色,在不影響集群事務處理能力的基礎上提升集群的非事務處理能力
(2)處理客戶端的非事務請求,轉發事務請求給 Leader 服務器
(3)不參與任何形式的投票
14. Zookeeper 下 Server 作業狀態
服務器具有四種狀態,分別是 LOOKING、FOLLOWING、LEADING、OBSERVING,
(1)LOOKING:尋 找 Leader 狀態,當服務器處于該狀態時,它會認為當前集群中沒有 Leader,因此需要進入 Leader 選舉狀態,
(2)FOLLOWING:跟隨者狀態,表明當前服務器角色是 Follower,
(3)LEADING:領導者狀態,表明當前服務器角色是 Leader,
(4)OBSERVING:觀察者狀態,表明當前服務器角色是 Observer,
15. 資料同步
整個集群完成 Leader 選舉之后,Learner(Follower 和 Observer 的統稱)回向Leader 服務器進行注冊,當 Learner 服務器想 Leader 服務器完成注冊后,進入資料同步環節,
資料同步流程:(均以訊息傳遞的方式進行)
Learner 向 Learder 注冊
資料同步
同步確認
Zookeeper 的資料同步通常分為四類:
(1)直接差異化同步(DIFF 同步)
(2)先回滾再差異化同步(TRUNC+DIFF 同步)
(3)僅回滾同步(TRUNC 同步)
(4)全量同步(SNAP 同步)
在進行資料同步前,Leader 服務器會完成資料同步初始化:
peerLastZxid:
· 從 learner 服務器注冊時發送的 ACKEPOCH 訊息中提取 lastZxid(該Learner 服務器最后處理的 ZXID)
minCommittedLog:
· Leader 服務器 Proposal 快取佇列 committedLog 中最小 ZXIDmaxCommittedLog:
· Leader 服務器 Proposal 快取佇列 committedLog 中最大 ZXID直接差異化同步(DIFF 同步)
· 場景:peerLastZxid 介于 minCommittedLog 和 maxCommittedLog之間先回滾再差異化同步(TRUNC+DIFF 同步)
· 場景:當新的 Leader 服務器發現某個 Learner 服務器包含了一條自己沒有的事務記錄,那么就需要讓該 Learner 服務器進行事務回滾–回滾到 Leader服務器上存在的,同時也是最接近于 peerLastZxid 的 ZXID僅回滾同步(TRUNC 同步)
· 場景:peerLastZxid 大于 maxCommittedLog
全量同步(SNAP 同步)
· 場景一:peerLastZxid 小于 minCommittedLog
· 場景二:Leader 服務器上沒有 Proposal 快取佇列且 peerLastZxid 不等于 lastProcessZxid
16. zookeeper 是如何保證事務的順序一致性的?
zookeeper 采用了全域遞增的事務 Id 來標識,所有的 proposal(提議)都在被提出的時候加上了 zxid,zxid 實際上是一個 64 位的數字,高 32 位是 epoch( 時期; 紀元; 世; 新時代)用來標識 leader 周期,如果有新的 leader 產生出來,epoch會自增,低 32 位用來遞增計數,當新產生 proposal 的時候,會依據資料庫的兩階段程序,首先會向其他的 server 發出事務執行請求,如果超過半數的機器都能執行并且能夠成功,那么就會開始執行,
17. 分布式集群中為什么會有 Master主節點?
在分布式環境中,有些業務邏輯只需要集群中的某一臺機器進行執行,其他的機器可以共享這個結果,這樣可以大大減少重復計算,提高性能,于是就需要進行 leader 選舉,
18. zk 節點宕機如何處理?
Zookeeper 本身也是集群,推薦配置不少于 3 個服務器,Zookeeper 自身也要保證當一個節點宕機時,其他節點會繼續提供服務,
如果是一個 Follower 宕機,還有 2 臺服務器提供訪問,因為 Zookeeper 上的資料是有多個副本的,資料并不會丟失;
如果是一個 Leader 宕機,Zookeeper 會選舉出新的 Leader,
ZK 集群的機制是只要超過半數的節點正常,集群就能正常提供服務,只有在 ZK節點掛得太多,只剩一半或不到一半節點能作業,集群才失效,
所以
3 個節點的 cluster 可以掛掉 1 個節點(leader 可以得到 2 票>1.5)
2 個節點的 cluster 就不能掛掉任何 1 個節點了(leader 可以得到 1 票<=1)
19. zookeeper 負載均衡和 nginx 負載均衡區別
zk 的負載均衡是可以調控,nginx 只是能調權重,其他需要可控的都需要自己寫插件;但是 nginx 的吞吐量比 zk 大很多,應該說按業務選擇用哪種方式,
20. Zookeeper 有哪幾種幾種部署模式?
Zookeeper 有三種部署模式:
- 單機部署:一臺集群上運行;
- 集群部署:多臺集群運行;
- 偽集群部署:一臺集群啟動多個 Zookeeper 實體運行,
21. 集群最少要幾臺機器,集群規則是怎樣的?集群中有 3 臺服務器,其中一個節點宕機,這個時候 Zookeeper 還可以使用嗎?
集群規則為 2N+1 臺,N>0,即 3 臺,可以繼續使用,單數服務器只要沒超過一半的服務器宕機就可以繼續使用,
22. 集群支持動態添加機器嗎?
其實就是水平擴容了,Zookeeper 在這方面不太好,兩種方式:
全部重啟:關閉所有 Zookeeper 服務,修改配置之后啟動,不影響之前客戶端的會話,
逐個重啟:在過半存活即可用的原則下,一臺機器重啟不影響整個集群對外提供服務,這是比較常用的方式,
3.5 版本開始支持動態擴容,
23. Zookeeper 對節點的 watch 監聽通知是永久的嗎?為什么不是永久的?
不是,官方宣告:一個 Watch 事件是一個一次性的觸發器,當被設定了 Watch的資料發生了改變的時候,則服務器將這個改變發送給設定了 Watch 的客戶端,以便通知它們,
為什么不是永久的,舉個例子,如果服務端變動頻繁,而監聽的客戶端很多情況下,每次變動都要通知到所有的客戶端,給網路和服務器造成很大壓力,
一般是客戶端執行 getData(“/節點 A”,true),如果節點 A 發生了變更或洗掉,客戶端會得到它的 watch 事件,但是在之后節點 A 又發生了變更,而客戶端又沒有設定 watch 事件,就不再給客戶端發送,
在實際應用中,很多情況下,我們的客戶端不需要知道服務端的每一次變動,我只要最新的資料即可,
24. Zookeeper 的 java 客戶端都有哪些?
java 客戶端:zk 自帶的 zkclient 及 Apache 開源的 Curator,
25. chubby 是什么,和 zookeeper 比你怎么看?
chubby 是 google 的,完全實作 paxos 演算法,不開源,zookeeper 是 chubby的開源實作,使用 zab 協議,paxos 演算法的變種,
26. 說幾個 zookeeper 常用的命令,
常用命令:ls get set create delete 等,
27. ZAB 和 Paxos 演算法的聯系與區別?
相同點:
(1)兩者都存在一個類似于 Leader 行程的角色,由其負責協調多個 Follower 行程的運行
(2)Leader 行程都會等待超過半數的 Follower 做出正確的反饋后,才會將一個提案進行提交
(3)ZAB 協議中,每個 Proposal 中都包含一個 epoch 值來代表當前的 Leader周期,Paxos 中名字為 Ballot
不同點:
ZAB 用來構建高可用的分布式資料主備系統(Zookeeper),Paxos 是用來構建分布式一致性狀態機系統,
28. Zookeeper 的典型應用場景
Zookeeper 是一個典型的發布/訂閱模式的分布式資料管理與協調框架,開發人員可以使用它來進行分布式資料的發布和訂閱,
通過對 Zookeeper 中豐富的資料節點進行交叉使用,配合 Watcher 事件通知機制,可以非常方便的構建一系列分布式應用中年都會涉及的核心功能,如:
(1)資料發布/訂閱
(2)負載均衡
(3)命名服務
(4)分布式協調/通知
(5)集群管理
(6)Master 選舉
(7)分布式鎖
(8)分布式佇列
資料發布/訂閱
介紹
資料發布/訂閱系統,即所謂的配置中心,顧名思義就是發布者發布資料供訂閱者進行資料訂閱,
目的
動態獲取資料(配置資訊)
實作資料(配置資訊)的集中式管理和資料的動態更新
設計模式
Push 模式
Pull 模式
資料(配置資訊)特性
(1)資料量通常比較小
(2)資料內容在運行時會發生動態更新
(3)集群中各機器共享,配置一致
如:機器串列資訊、運行時開關配置、資料庫配置資訊等
基于 Zookeeper 的實作方式
· 資料存盤:將資料(配置資訊)存盤到 Zookeeper 上的一個資料節點
· 資料獲取:應用在啟動初始化節點從 Zookeeper 資料節點讀取資料,并在該節點上注冊一個資料變更 Watcher
· 資料變更:當變更資料時,更新 Zookeeper 對應節點資料,Zookeeper會將資料變更通知發到各客戶端,客戶端接到通知后重新讀取變更后的資料即可,
負載均衡
zk 的命名服務
命名服務是指通過指定的名字來獲取資源或者服務的地址,利用 zk 創建一個全域的路徑,這個路徑就可以作為一個名字,指向集群中的集群,提供的服務的地址,或者一個遠程的物件等等,
分布式通知和協調
對于系統調度來說:操作人員發送通知實際是通過控制臺改變某個節點的狀態,然后 zk 將這些變化發送給注冊了這個節點的 watcher 的所有客戶端,
對于執行情況匯報:每個作業行程都在某個目錄下創建一個臨時節點,并攜帶作業的進度資料,這樣匯總的行程可以監控目錄子節點的變化獲得作業進度的實時的全域情況,
zk 的命名服務(檔案系統)
命名服務是指通過指定的名字來獲取資源或者服務的地址,利用 zk 創建一個全域的路徑,即是唯一的路徑,這個路徑就可以作為一個名字,指向集群中的集群,提供的服務的地址,或者一個遠程的物件等等,
zk 的配置管理(檔案系統、通知機制)
程式分布式的部署在不同的機器上,將程式的配置資訊放在 zk 的 znode 下,當有配置發生改變時,也就是 znode 發生變化時,可以通過改變 zk 中某個目錄節點的內容,利用 watcher 通知給各個客戶端,從而更改配置,
Zookeeper 集群管理(檔案系統、通知機制)
所謂集群管理無在乎兩點:是否有機器退出和加入、選舉 master,
對于第一點,所有機器約定在父目錄下創建臨時目錄節點,然后監聽父目錄節點
的子節點變化訊息,一旦有機器掛掉,該機器與 zookeeper 的連接斷開,其所創建的臨時目錄節點被洗掉,所有其他機器都收到通知:某個兄弟目錄被洗掉,于是,所有人都知道:它上船了,
新機器加入也是類似,所有機器收到通知:新兄弟目錄加入,highcount 又有了,對于第二點,我們稍微改變一下,所有機器創建臨時順序編號目錄節點,每次選取編號最小的機器作為 master 就好,
Zookeeper 分布式鎖(檔案系統、通知機制)
有了 zookeeper 的一致性檔案系統,鎖的問題變得容易,鎖服務可以分為兩類,一個是保持獨占,另一個是控制時序,
對于第一類,我們將 zookeeper 上的一個 znode 看作是一把鎖,通過 createznode的方式來實作,所有客戶端都去創建 /distribute_lock 節點,最終成功創建的那個客戶端也即擁有了這把鎖,用完洗掉掉自己創建的 distribute_lock 節點就釋放出鎖,
對于第二類, /distribute_lock 已經預先存在,所有客戶端在它下面創建臨時順序編號目錄節點,和選 master 一樣,編號最小的獲得鎖,用完洗掉,依次方便,
Zookeeper 佇列管理(檔案系統、通知機制)
兩種型別的佇列:
(1)同步佇列,當一個佇列的成員都聚齊時,這個佇列才可用,否則一直等待所有成員到達,
(2)佇列按照 FIFO 方式進行入隊和出隊操作,
第一類,在約定目錄下創建臨時目錄節點,監聽節點數目是否是我們要求的數目,
第二類,和分布式鎖服務中的控制時序場景基本原理一致,入列有編號,出列按編號,在特定的目錄下創建 PERSISTENT_SEQUENTIAL 節點,創建成功時Watcher 通知等待的佇列,佇列洗掉序列號最小的節點用以消費,此場景下Zookeeper 的 znode 用于訊息存盤,znode 存盤的資料就是訊息佇列中的訊息內容,SEQUENTIAL 序列號就是訊息的編號,按序取出即可,由于創建的節點是持久化的,所以不必擔心佇列訊息的丟失問題,
29. Zookeeper 都有哪些功能?
- 集群管理:監控節點存活狀態、運行請求等;
- 主節點選舉:主節點掛掉了之后可以從備用的節點開始新一輪選主,主節點選舉說的就是這個選舉的程序,使用 Zookeeper 可以協助完成這個程序;
- 分布式鎖:Zookeeper 提供兩種鎖:獨占鎖、共享鎖,獨占鎖即一次只能有一個執行緒使用資源,共享鎖是讀鎖共享,讀寫互斥,即可以有多線執行緒同時讀同一個資源,如果要使用寫鎖也只能有一個執行緒使用,Zookeeper 可以對分布式鎖進行控制,
- 命名服務:在分布式系統中,通過使用命名服務,客戶端應用能夠根據指定名字來獲取資源或服務的地址,提供者等資訊,
30. 說一下 Zookeeper 的通知機制?
client 端會對某個 znode 建立一個 watcher 事件,當該 znode 發生變化時,這些 client 會收到 zk 的通知,然后 client 可以根據 znode 變化來做出業務上的改變等,
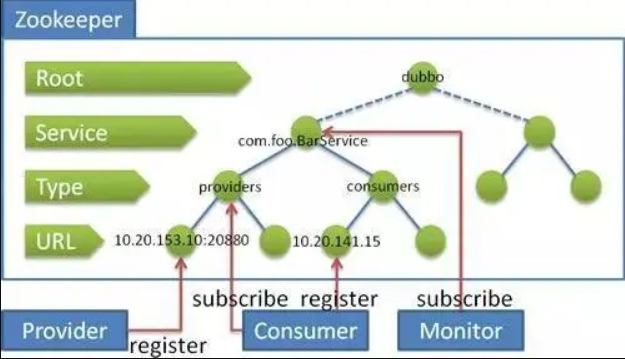
31. Zookeeper 和 Dubbo 的關系?
Zookeeper的作用:
zookeeper用來注冊服務和進行負載均衡,哪一個服務由哪一個機器來提供必需讓呼叫者知道,簡單來說就是ip地址和服務名稱的對應關系,當然也可以通過硬編碼的方式把這種對應關系在呼叫方業務代碼中實作,但是如果提供服務的機器掛掉呼叫者無法知曉,如果不更改代碼會繼續請求掛掉的機器提供服務,zookeeper通過心跳機制可以檢測掛掉的機器并將掛掉機器的ip和服務對應關系從串列中洗掉,至于支持高并發,簡單來說就是橫向擴展,在不更改代碼的情況通過添加機器來提高運算能力,通過添加新的機器向zookeeper注冊服務,服務的提供者多了能服務的客戶就多了,
dubbo:
是管理中間層的工具,在業務層到資料倉庫間有非常多服務的接入和服務提供者需要調度,dubbo提供一個框架解決這個問題,注意這里的dubbo只是一個框架,至于你架子上放什么是完全取決于你的,就像一個汽車骨架,你需要配你的輪子引擎,這個框架中要完成調度必須要有一個分布式的注冊中心,儲存所有服務的元資料,你可以用zk,也可以用別的,只是大家都用zk,
zookeeper和dubbo的關系:
Dubbo 的將注冊中心進行抽象,它可以外接不同的存盤媒介給注冊中心提供服務,有 ZooKeeper,Memcached,Redis 等,
引入了 ZooKeeper 作為存盤媒介,也就把 ZooKeeper 的特性引進來,首先是負載均衡,單注冊中心的承載能力是有限的,在流量達到一定程度的時 候就需要分流,負載均衡就是為了分流而存在的,一個 ZooKeeper 群配合相應的 Web 應用就可以很容易達到負載均衡;資源同步,單單有負載均衡還不 夠,節點之間的資料和資源需要同步,ZooKeeper 集群就天然具備有這樣的功能;命名服務,將樹狀結構用于維護全域的服務地址串列,服務提供者在啟動 的時候,向 ZooKeeper 上的指定節點 /dubbo/${serviceName}/providers 目錄下寫入自己的 URL 地址,這個操作就完成了服務的發布,其他特性還有 Mast 選舉,分布式鎖等,
原文鏈接:https://thinkwon.blog.csdn.net/article/details/104397719
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/225593.html
標籤:Java