bcc是eBPF的一種前端,當然這個前端特別地簡單好用,可以直接在python里面嵌入通過C語言寫的BPF程式,并幫忙產生BPF bytecode和load進入kernel掛載kprobe、tracepoints等上面執行,之后,還可以從python取出來C函式里面匯出的maps資料以及per-event資料并進行列印,
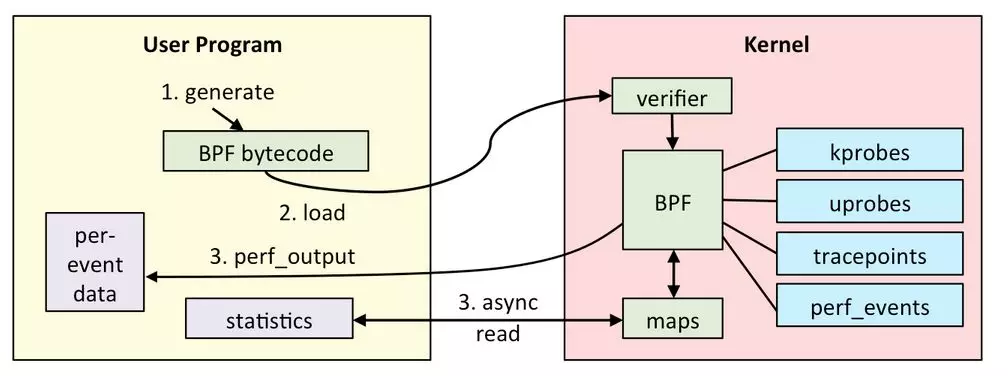
我們特別看一下其中的bitehist.py例子:

上述程式通過kprobe截獲了內核的blk_account_io_completion()函式,并將每個request的data_len轉換為單位KBytes后,進行取對數,加入一個HISTOGRAM(屬于maps中的一種),之后python會呼叫
b[“dist”].print_log2_hist(“kbytes”)
列印出這個hist圖,從而可以給用戶呈現出request磁盤請求的size分布情況:
另外一個經典的例子是通過kprobe截獲函式的入口和回傳點,得到函式的呼叫延遲:

上面的這個BPF C程式把在函式進入(kprobe)的時候,把當前時間加入一個start HASH(key是行程的pid,value是函式的開始時間),在函式出口的地方(kretprobe)通過start.loopup(&pid)取得函式入口時間,然后在函式出口的時候,把出口時間減去入口時間的結果求對數后放入一個HISTOGRAM,之后python可以獲取這個HIST并列印:

這樣可以呈現出延遲的熱點分布,
anyway,了解了BPF c和python的語法后,這樣的程式并不難寫,但是,很多時候,其實我們并沒有必要自己寫代碼,因為牛人們已經給我們寫了很多現成的工具了,
比如,分析bio的延遲:
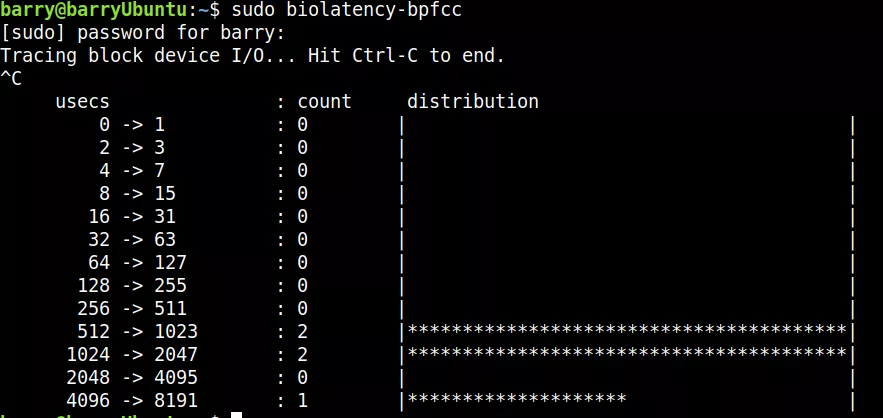
大量的延遲集中在512-1023和1024-2047之間,另外4096-8191也是這個multimodal延遲的另外一個熱點,
這個東西就要比iostat命令更加細致靠譜一些,因為iostat命令只是簡單地顯示平均延遲啥的,并不顯示延遲的分布情況,比如man iostat可以獲知:
await - The average time (in milliseconds) for I/O requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them.
但是,很多時候延遲呈現為一個multimodal的特點,會有多個峰值區域:
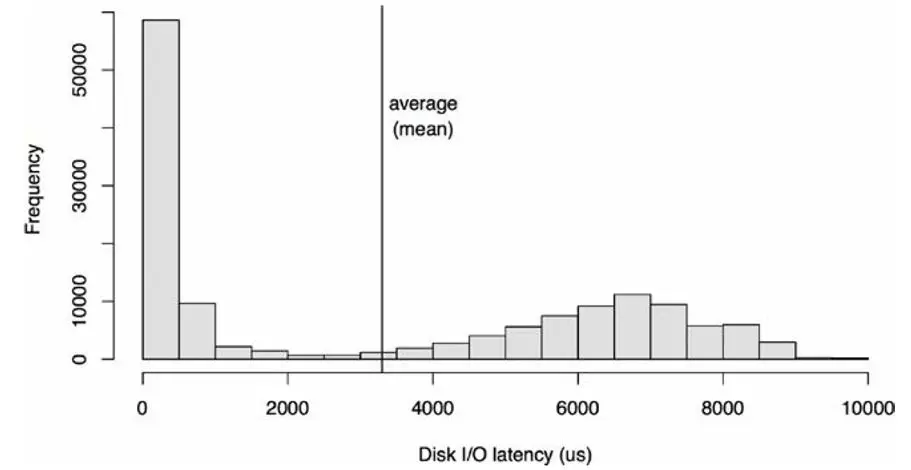
平均值,看起來,有時候沒有那么accurate,比如一個班上的學生,平均分70分,但是無法呈現這個班的童鞋的如下特點:
-
有一堆差生都是30分左右
-
有一堆中等生都是60分左右
-
有一堆優等生都是90分左右
如果是HIST圖的話,它的分布會類似:
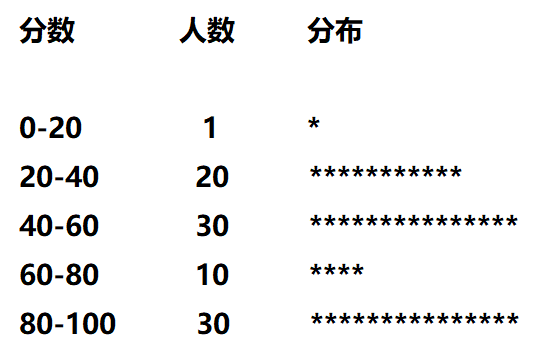
看起來更加精確一些,
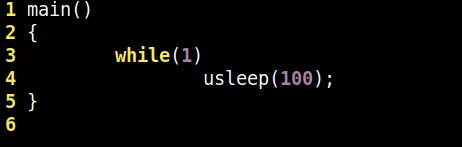
下面我們嘗試用funclatency這個現成的工具來分析代碼里面的usleep(100)究竟真正延遲多少,寫一個最簡單的應用程式,編譯為a.out:
運行后,我們來得到usleep(100)呼叫內核do_nanosleep的真實延遲:
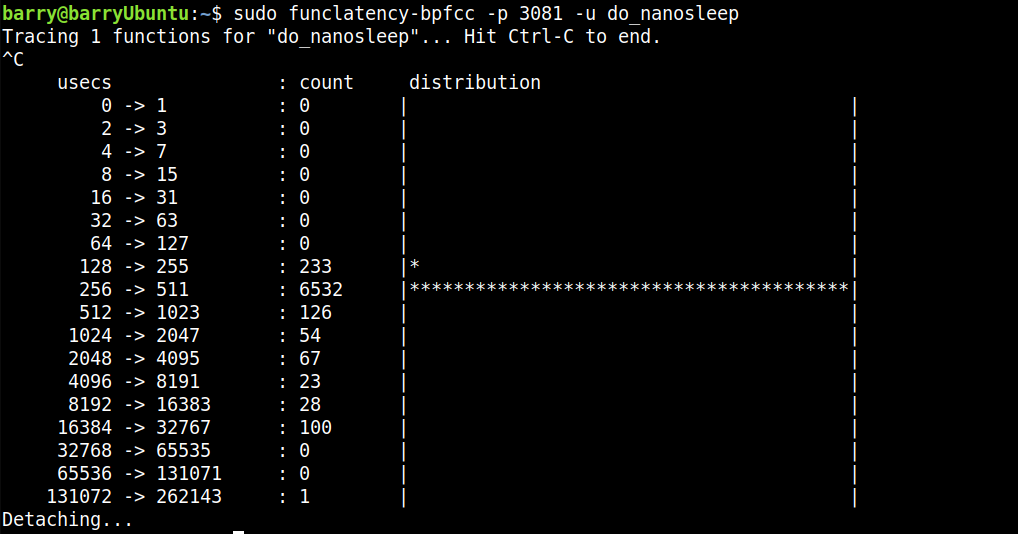
其實usleep(100)大面積集中在256-511us,所以,這個usleep(100)究竟有多準,天知道,
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??

本文來自:Linux閱碼場,作者:宋寶華
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/226050.html
標籤:Java