前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,

基本開發環境
- Python 3.6
- Pycharm
import requests import parsel import threading
相關模塊 pip 安裝即可
目標網頁分析
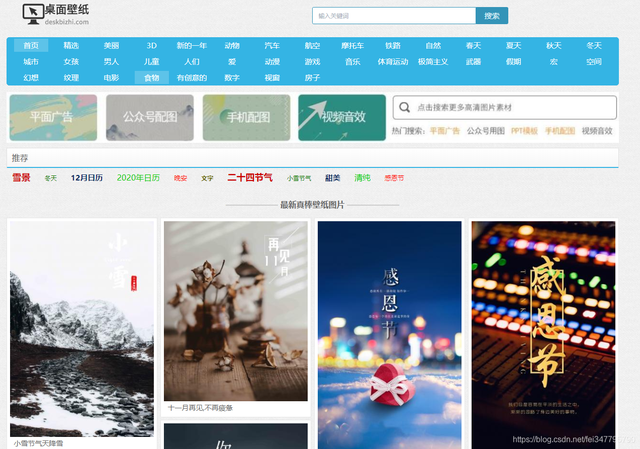
這個網站有電腦壁紙也有手機壁紙,還是不錯的,
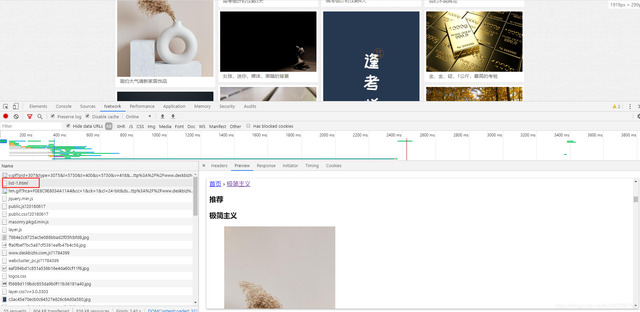
網站是靜態網站,沒有加密,可以直接爬取
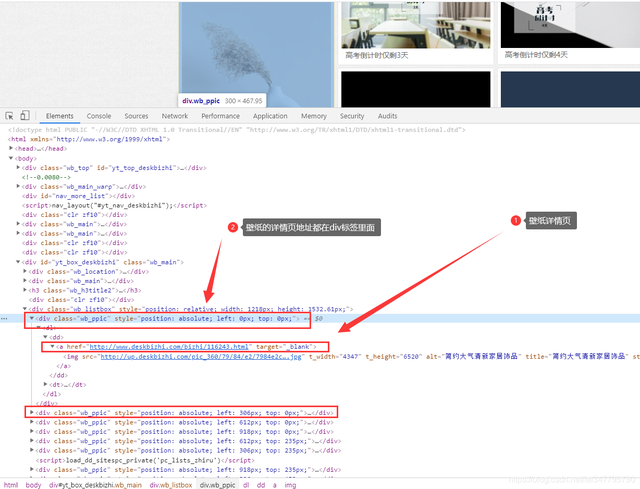
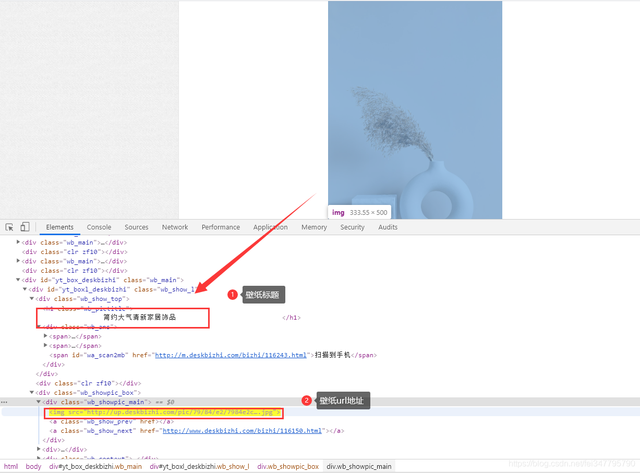
整體思路
1、先在串列頁面獲取每張壁紙的詳情地址
2、在壁紙詳情頁面獲取壁紙真實高清url地址
3、保存壁紙
代碼實作
模擬瀏覽器請求網頁,獲取網頁資料
def get_html(html_url): ''' 獲取網頁源代碼 :param html_url: 網頁url :return: ''' response = requests.get(url=html_url, headers=headers) return response
決議網頁資料
def get_par(html_data): ''' 把 response.text 轉換成 selector 物件 決議提取資料 :param html_data: response.text :return: selector 物件 ''' selector = parsel.Selector(html_data) return selector
保存資料
def download(img_url, title): ''' 保存資料 :param img_url: 圖片地址 :param title: 圖片標題 :return: ''' content = get_html(img_url).content path = '壁紙\\' + title + '.jpg' with open(path, mode='wb') as f: f.write(content) print('正在保存', title)
主函式
def main(url): ''' 主函式 :param url: 串列頁面 url :return: ''' html_data = get_html(url).text selector = get_par(html_data) lis = selector.css('.wb_listbox div dl dd a::attr(href)').getall() for li in lis: img_data = get_html(li).text img_selector = get_par(img_data) img_url = img_selector.css('.wb_showpic_main img::attr(src)').get() title = img_selector.css('.wb_pictitle::text').get().strip() download(img_url, title) end_time = time.time() - s_time print(end_time)
啟動多執行緒運行代碼
if __name__ == '__main__': for page in range(1, 11): url = 'http://www.deskbizhi.com/min/list-{}.html'.format(page) main_thread = threading.Thread(target=main, args=(url,)) main_thread.start()
這里只選擇爬取前10頁的資料
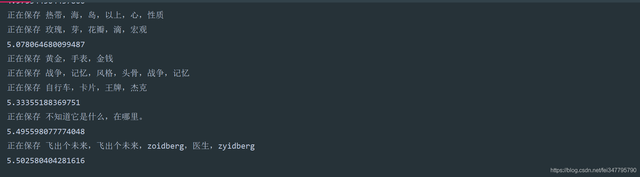
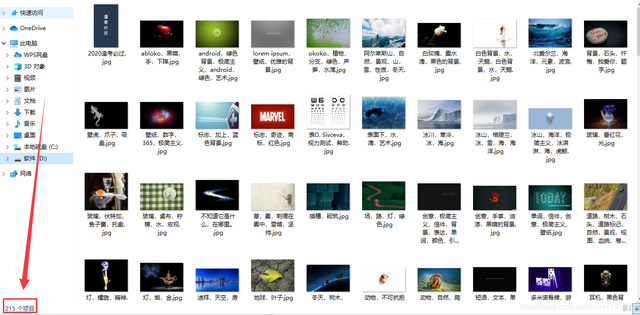
從運行截圖和壁紙保存來看,5.5秒的時間,下載了215張圖片,效率上面還是可以的,平均計算下來每秒鐘下載40張圖片,,,
可以自己去試試多執行緒爬取資料哈,效率還是非常高的
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/226054.html
標籤:其他