步驟
(本次爬蟲僅以一個視頻為示例:鏈接)
- 查找評論請求api
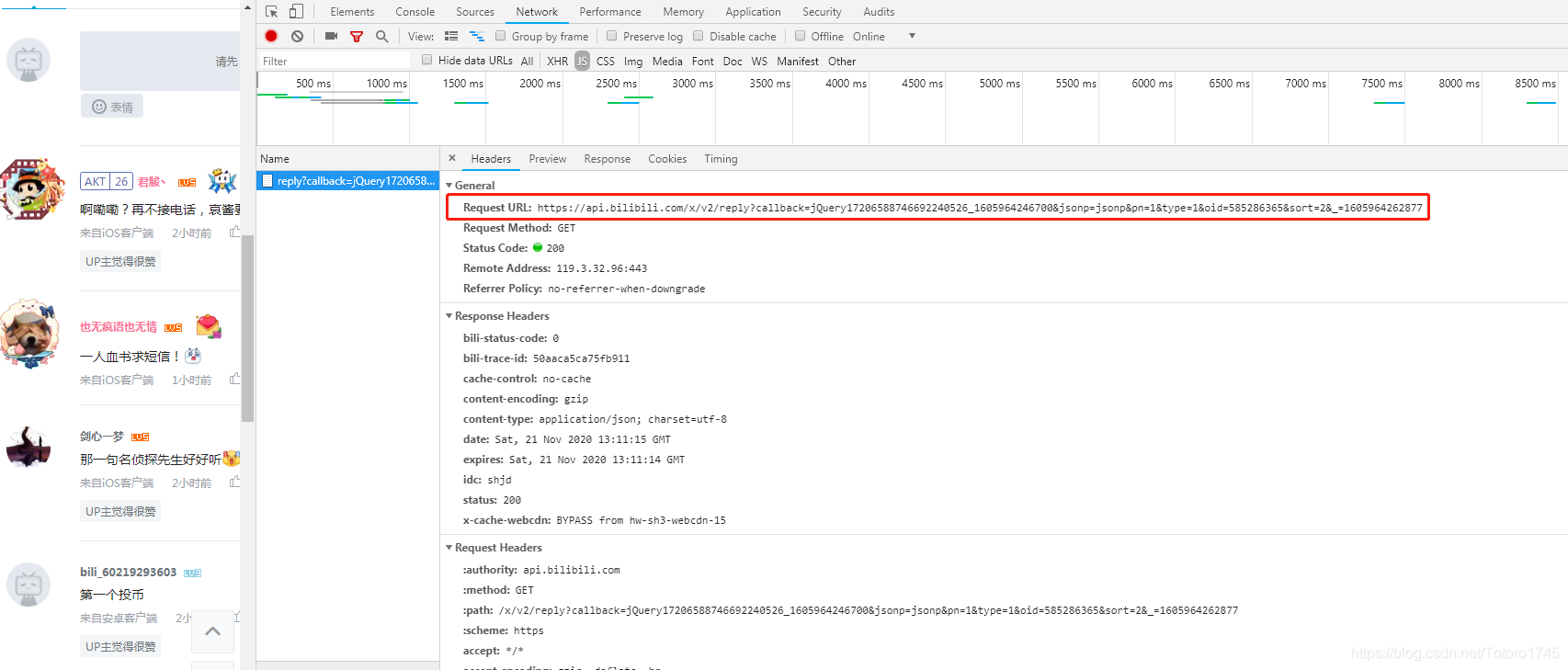
- 決議URL
去掉第一個和最后一個引數可得評論URL,即:https://api.bilibili.com/x/v2/reply?jsonp=jsonp&pn=1&type=1&oid=585286365&sort=2
【其中pn是頁碼;sort控制排序順序,1按時間排序,2按熱度排序;oid代碼視頻編號】
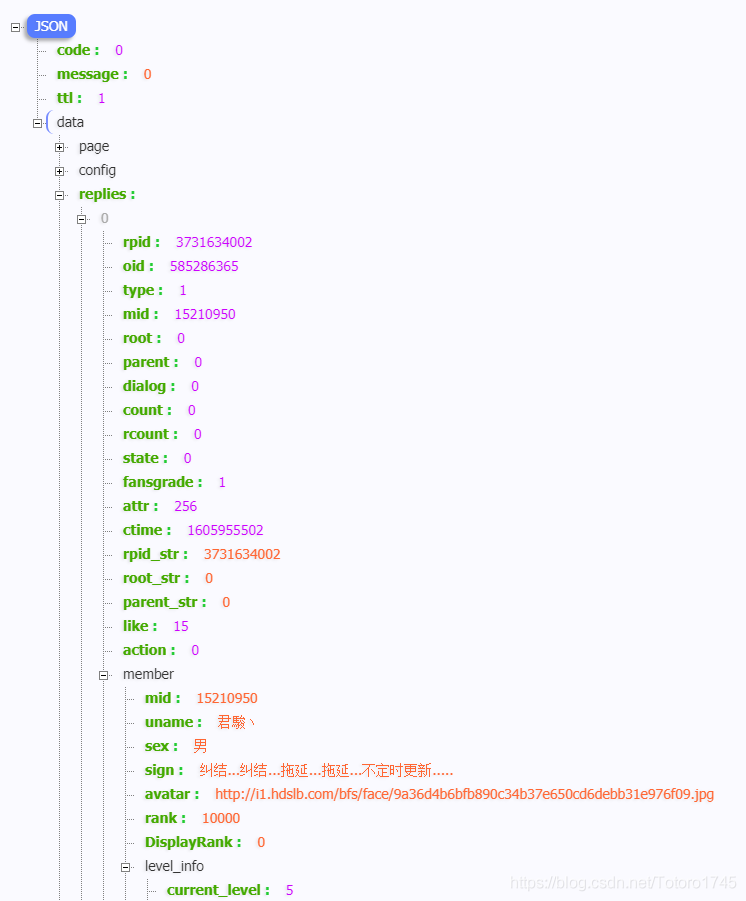 - 開始敲代碼
- 開始敲代碼
import requests
header = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0",
"Cookie": ""}
comments = []
original_url = "https://api.bilibili.com/x/v2/reply?jsonp=jsonp&type=1&oid=585286365&sort=2&pn="
for page in range(1, 39): # 頁碼這里就簡單處理了
url = original_url + str(page)
print(url)
try:
html = requests.get(url, headers=header)
data = html.json()
if data['data']['replies']:
for i in data['data']['replies']:
comments.append(i['content']['message'])
except Exception as err:
print(url)
print(err)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/226224.html
標籤:python
上一篇:手把手教你用python實作json串(pandas.DataFrame)列序更換
下一篇:計算機的小知識