標題無意冒犯,就是覺得這個廣告挺好玩的
上面這張思維導圖喜歡就拿走,反正我也學不了這么多
文章目錄
- 前言
- 歡迎來到我們的圈子
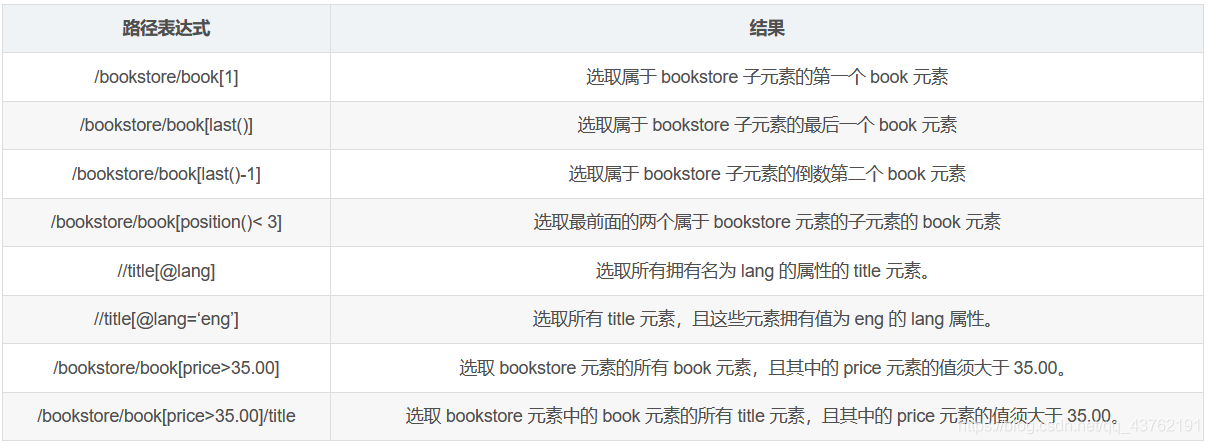
- Xpath
- Xpath基本語法截取
- 路徑運算式
- 路徑運算式栗子
- 選取節點后面的下標
- 選取未知節點,通配符
- 實體
- 選取若干路徑
- 學習案例:抓取百度貼吧->王者榮耀吧的評論
- Xpath常用函式及用例
- 標簽補全
- 獲取所有節點
- 根據屬性獲取
- 獲取父節點
- 獲取文本資訊
- 屬性多值匹配
- 根據順序選擇
- XPath 軸
前言
前期回顧:我要偷偷學Python(第十四天)
第十四天告訴大家我們將進入一個漫長的練習階段,不過不用慌,今天我們來看別人口中“永遠滴神” – Xpath
我也不知道為什么被稱作永遠滴神,但是我知道肯定不是因為它難,
插播一條推送:(如果是小白的話,可以看一下下面這一段)
歡迎來到我們的圈子
我建了一個Python學習答疑群,有興趣的朋友可以了解一下:這是個什么群
群里已經有一千八百多個小伙伴了哦!!!
(嚴格控制群人數,所以今年年底之前不會滿群)
直通群的傳送門:傳送門
本系列文默認各位有一定的C或C++基礎,因為我是學了點C++的皮毛之后入手的Python,這里也要感謝齊鋒學長送來的支持,
本系列文默認各位會百度,
我要的不多,點個關注就好啦
然后呢,本系列的目錄嘛,說實話我個人比較傾向于那兩本 Primer Plus,所以就跟著它們的目錄結構吧,
本系列也會著重培養各位的自主動手能力,畢竟我不可能把所有知識點都給你講到,所以自己解決需求的能力就尤為重要,所以我在文中埋得坑請不要把它們看成坑,那是我留給你們的鍛煉機會,請各顯神通,自行解決,
Xpath
我們剛開始接觸Xpath是什么時候?對,selenium的時候,那時候我們抓不下標簽,就轉方向從Xpath入手,
那么這個Xpath到底是個什么東西竟然如此的神通廣大?
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML檔案中某部分位置的語言,
也不多嗶嗶,就知道Xpath是網頁內容的導航就好,
Xpath基本語法截取
以下內容部分出自百度百科,截取適用于爬蟲的部分,
畢竟人家都整理好了,咱也難出其右,
路徑運算式
選取節點 XPath 使用路徑運算式在 XML 檔案中選取節點,節點是通過沿著路徑或者 step 來選取的, [1]
下面列出了最有用的路徑運算式:
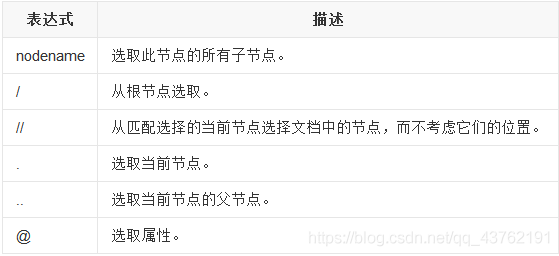
路徑運算式栗子

選取節點后面的下標
選取未知節點,通配符

實體

選取若干路徑

學習案例:抓取百度貼吧->王者榮耀吧的評論
找的時候是一篇偽代碼,我做了微調,加了點注釋,
也可以自己去除錯一遍,自己動手的話印象會比較深刻,
# element tree: 檔案樹物件
import requests
from lxml import etree
# 爬取百度貼吧資料
class Tieba(object):
def __init__(self,key):
self.url = "https://tieba.baidu.com/"+key #動態url,理論上可以獲取任一貼吧的網頁
#print(self.url)
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"
}
# 獲取資料
def get_data(self, url):
response = requests.get(url, headers=self.headers)
return response.content #以二進制形式回傳(大可以用text去試一下,回傳文本形式)
# 資料提取
def parse_data(self, data):
# 解碼,并洗掉源代碼中的注釋
data = data.decode().replace("<!--", "").replace("-->", "")
# 創建element物件
html = etree.HTML(data)
# 根據xpath語法提取每頁標題物件的貼吧標題xpath物件
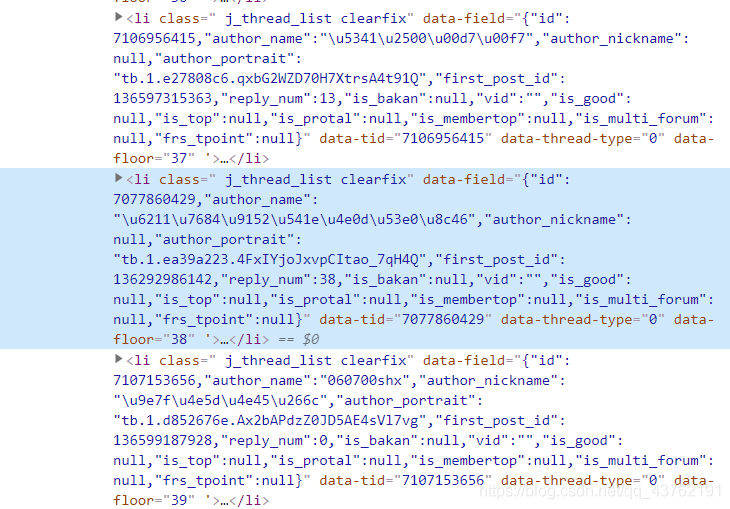
# 關于這個xpath是如何確定的,代碼后面會放上一張圖,自己悟一下
el_list = html.xpath("//li[@class=' j_thread_list clearfix']/div/div[2]/div[1]/div[1]/a")
print(el_list)
# 遍歷每頁的貼吧標題xpath物件
data_list = []
for el in el_list:
# 根據每個xpath物件獲取每個標題的titile屬性和link屬性
temp = {}
temp["title"] = el.xpath("./text()")[0] #取第一個文本
temp["link"] = "http://tieba.baidu.com" + el.xpath("./@href")[0] #同
# 將每個標題屬性字典添加到串列中
data_list.append(temp)
# 獲取下一頁url
try:
next_url = "https:" + html.xpath('//a[contains(text(),"下一頁>")]/@href')[0] #contains()函式,后面講
except:
next_url = None
# 回傳每頁的標題屬性字典和下一頁的url
return data_list, next_url
# 保存 偽代碼
def save_data(self, data_list):
for data in data_list:
print(data)
# 運行
def run(self):
# 第一次的url是self.url
next_url = self.url
# 實作翻頁 直到next_url == None 結束翻頁
while True:
# 發送請求,獲取回應
data = self.get_data(next_url)
# 從回應中提取資料(資料和翻頁用的url)
data_list, next_url = self.parse_data(data)
self.save_data(data_list)
print(next_url)
# 判斷是否結束
if next_url == None:
break
if __name__ == '__main__':
tieba = Tieba("f?kw=王者榮耀")
tieba.run() #函式入口
Xpath常用函式及用例
以下皆為偽代碼,測驗檔案木有,留著當工具書使用
標簽補全
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('UTF-8'))
獲取所有節點
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//*')#'//'表示獲取當前節點子孫節點,'*'表示所有節點,'//*'表示獲取當前節點下所有節點
for item in result:
print(item)
result = html.xpath('//li')#將*改為li,表示只獲取名稱為li的子孫節點
#回傳一個串列
for item in result:
print(item)
result = html.xpath('//li/a')#//li選擇所有的li節點,/a選擇li節點下的直接子節點a
for item in result:
print(item)
我們也可以使用//ul//a首先選擇所有的ul節點,再獲取ul節點下的的所有a節點,最后結果也是一樣的,但是使用//ul/a就不行了,首先選擇所有的ul節點,再獲取ul節點下的直接子節點a,然而ul節點下沒有直接子節點a,當然獲取不到,需要深刻理解//和/的不同之處,/用于獲取直接子節點,//用于獲取子孫節點,
根據屬性獲取
根據XPath常用規則可以通過@匹配指定的屬性,我們通過class屬性找最后一個li節點,
result = html.xpath('//li[@class="item-3"]')#最后一個li的class屬性值為item-3,回傳串列形式
print(result)
獲取父節點
根據XPath常用規則可以通過…獲取當前節點的父節點,現在我要獲取最后一個a節點的父節點下的class屬性,
result = html.xpath('//a[@href="https://hao.360.cn/?a1004"]/../@class')
#a[@href="https://hao.360.cn/?a1004"]:選擇href屬性為https://hao.360.cn/?a1004的a節點
#..:選取父節點
#@class:選取class屬性,獲取屬性值
print(result)
獲取文本資訊
很多時候我們找到指定的節點都是要獲取節點內的文本資訊,我們使用text()方法獲取節點中的文本,現在獲取所有a標簽的文本資訊,
result = html.xpath('//ul//a/text()')
print(result)
屬性多值匹配
在上面的例子中所有的屬性值都只有一個,如果屬性值有多個還能匹配的上嗎?(上面代碼里面翻頁看不懂的注意了啊)
遇到屬性值有多個的情況我們需要使用contains()函式了,contains()匹配一個屬性值中包含的字串 ,包含的字串,而不是某個值,
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidu</a>
<li class="spitem-1"><a href="https://blog.csdn.net/qq_25343557">myblog</a>
<li class="item-2"><a href="https://www.csdn.net/">csdn</a>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123</a>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"item-0") and @name="one"]/a/text()')#使用and運算子將兩個條件相連,
print(result)
也許你會說這個直接使用name的屬性值就可以得到了,然而,這里只是作為演示,
根據順序選擇
在上面的操作中我多次找第2個li節點或找最后一個li節點,使用屬性值進行匹配,其實何必呢!我們可以根據順序進行選擇,
result = html.xpath('//li[2]/a/text()')#選擇第二個li節點,獲取a節點的文本
result = html.xpath('//li[last()]/a/text()')#選擇最后一個li節點,獲取a節點的文本
result = html.xpath('//li[last()-1]/a/text()')#選擇倒數第2個li節點,獲取a節點的文本
result = html.xpath('//li[position()<=3]/a/text()')#選擇前三個li節點,獲取a節點的文本
函式太多了,感覺我這里的函式滿足不了你的話可以移步:https://www.w3school.com.cn/xpath/index.asp
XPath 軸
我們可以通過XPath獲取祖先節點,屬性值,兄弟節點等等,這就是XPath的節點軸,軸可定義相對于當前節點的節點集,
result = html.xpath('//li[1]/ancestor::*')
#ancestor表示選取當前節點祖先節點,*表示所有節點,合:選擇當前節點的所有祖先節點,
result = html.xpath('//li[1]/ancestor::div')
#ancestor表示選取當前節點祖先節點,div表示div節點,合:選擇當前節點的div祖先節點,
result = html.xpath('//li[1]/ancestor-or-self::*')
#ancestor-or-self表示選取當前節點及祖先節點,*表示所有節點,合:選擇當前節點的所有祖先節點及本及本身,
result = html.xpath('//li[1]/attribute::*')
#attribute表示選取當前節點的所有屬性,*表示所有節點,合:選擇當前節點的所有屬性,
result = html.xpath('//li[1]/attribute::name')
#attribute表示選取當前節點的所有屬性,name表示name屬性,合:選擇當前節點的name屬性值,
result = html.xpath('//ul/child::*')
#child表示選取當前節點的所有直接子元素,*表示所有節點,合:選擇ul節點的所有直接子節點,
result = html.xpath('//ul/child::li[@name="two"]')
#child表示選取當前節點的所有直接子元素,li[@name="two"]表示name屬性值為two的li節點,合:選擇ul節點的所有name屬性值為two的li節點,
result = html.xpath('//ul/descendant::*')
#descendant表示選取當前節點的所有后代元素(子、孫等),*表示所有節點,合:選擇ul節點的所有子節點,
result = html.xpath('//ul/descendant::a/text()')
#descendant表示選取當前節點的所有后代元素(子、孫等),a/test()表示a節點的文本內容,合:選擇ul節點的所有a節點的文本內容,
result = html.xpath('//li[1]/following::*')
#following表示選取檔案中當前節點的結束標簽之后的所有節點,,*表示所有節點,合:選擇第一個li節點后的所有節點,
result = html.xpath('//li[1]/following-sibling::*')
#following-sibling表示選取當前節點之后的所有同級節點,,*表示所有節點,合:選擇第一個li節點后的所有同級節點,
result = html.xpath('//li[1]/parent::*')
#選取當前節點的父節點,父節點只有一個,祖先節點可能多個,
result = html.xpath('//li[3]/preceding::*')
#preceding表示選取檔案中當前節點的開始標簽之前的所有同級節點及同級節點下的節點,,*表示所有節點,合:選擇第三個li節點前的所有同級節點及同級節點下的子節點,
result = html.xpath('//li[3]/preceding-sibling::*')
#preceding-sibling表示選取當前節點之前的所有同級節點,,*表示所有節點,合:選擇第三個li節點前的所有同級節點,
result = html.xpath('//li[3]/self::*')
#選取當前節點,
弄完這個,接下來就試試看能不能用Xpath將騰訊校園招聘網的資料抓取下來整理起來咯,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/227543.html
標籤:python
上一篇:python-Xpath語法
下一篇:PHP中的static