● 研二在讀學生,非工科非計算機專業,故代碼簡陋初級勿噴,本文僅為記錄和快樂分享,
○ 感謝肯定,感謝點贊收藏分享,轉載請注明本頁出處即可, ____?即刻@王昭沒有君

本文僅為筆者摸索總結-歡迎訂正補充交流討論-
?python識別word檔案格式 ——(專欄:基于python撰寫簡單office閱卷程式①)
————————
一、整體思路:
🍒1. 使用python第三方庫docx識別盡可能多的word格式;(更簡單方便)
- 使用 dir() 查看當級存在的屬性或下級物件(不含雙下劃線__的)
- 使用 (.屬性)試圖呼叫查看屬性,或(.物件)進入下級物件
🍒2. 將.docx轉為.xml格式檔案,讀取標簽,補充識別docx庫無法識別的格式;
- 解壓word.docx檔案為xml檔案(不止一個,有好幾個檔案夾)
- 找到相應的屬性在xml檔案中的存盤標簽名和層級
- 使用(層級.tag)(層級.attrib)(層級.text) 試圖取出該屬性
🍒3. office有個懶惰且簡潔的規則是,很多默認屬性和格式,若該檔案中作者未修改默認格式或屬性,則在xml檔案中該屬性或格式的標簽不存在 ,則在用python抽取該格式或屬性時,回傳值為None或不存在,有時還會報錯,例如:
- 默認字體為宋體(有的版本是宋體(標題)或宋體(正文))
- 默認字號小三(也可能因版本不同而不同或.doc和.docx差異)
- 默認無首行縮進、默認行間距1.0倍等
而在修改了這些格式后,該屬性標簽會存盤在.docx和.xml檔案中,又不像是完全的日志檔案,
————————
二、使用python庫情況
此處均為撰寫閱卷程式用到的,若只識別word格式,并不需要以下全部:
import docx # 讀取word檔案
import xlrd # 讀取excel檔案,主要是獲取名單和創建地址用
import openpyxl # 讀取/寫入 excel檔案,主要是記錄成績用
import os # 使用檔案路徑等
import xml.etree.ElementTree as ET # 讀取xml檔案
除此之外,在解壓轉為xml檔案時還用到以下庫:
import os # 因筆者分開寫的解壓程式,解壓也用到os庫
import xlrd # 因筆者分開寫的解壓程式,解壓也用到xlrd庫,主要是獲取名單和創建地址用
import shutil # 洗掉組態檔
import zipfile
# 解壓word(.docx)、excel(.xlsx)、ppt(.pptx)檔案成為.xml格式檔案
————————
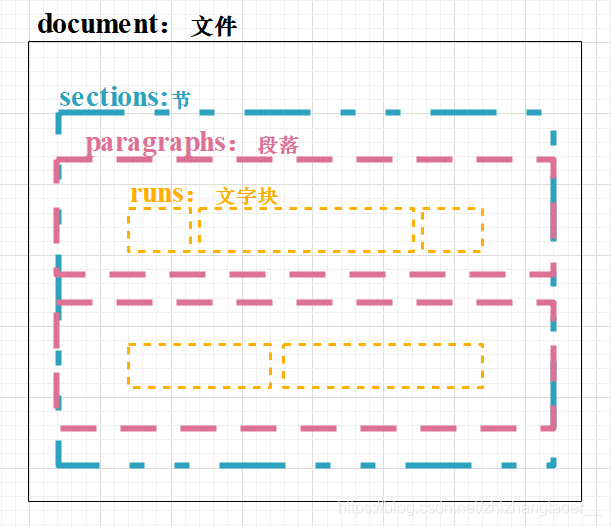
三、docx庫識別檔案結構:
-
document:
- sections:
- parapraphs:
- runs:
-
sections和paragraphs是同級關系
-
表格和圖片游離于sections和paragraphs
例如 :

🍍1.讀取檔案:docx.Document ( ’ 檔案地址 ’ )
file = docx.Document(r"F:\檔案地址\word.docx")
🍍2.讀取節們:檔案.sections
sections = file.sections # 節們
for section in sections: # 遍歷節
print(section.page_height) # 頁高
(1)分節符是分割節與節的標志(未嘗試過分頁符,歡迎補充);
(2)有關頁面的屬性基本都在sections部分里;
(3)節屬性包括但不僅限于: # 使用print(dir(section)) 、print(dir(sections))查看更多屬性和下級物件
- 頁高 :section.page_height
- 頁寬 :section.page_width
- 頁面橫縱 :section.orientation
- 裝訂線 :section.gutter
- 左邊距 :section.left_margin
- 右邊距 :section.right_margin
- 上邊距 :section.top_margin
- 下邊距 :section.bottom_margin
- 頁眉:section.header
- 頁腳 :section.footer
?——其中頁眉: # 使用print(dir(section.header)) 查看更多屬性和下級物件
- 頁眉頂端距離 :section.header_distance
- 頁腳底端距離 :section.footer_distance
- 頁眉內容 :section.header.paragraphs[0].text
- 頁眉對齊 :section.header.paragraphs[0].alignment
- 頁眉字號:section.header.paragraphs[0].runs[0].font.size
- 頁眉字體:section.header.paragraphs[0].runs[0].font.name
?——頁腳類似,但頁碼只能從xml檔案識別,
🍍3.讀取段落們:檔案.paragraphs
paragraphs = file.paragraphs # 段落們
for i in range(len(paragraphs)): # 遍歷段落 也可以寫成上面節的遍歷形式,此處須為后續保留段號i,故寫成這種形式,
paragraph = paragraphs[i]
if paragraphs[i].text != "": # 篩選非空段
print(paragraph.text) # 段落內容
(1)有關段落的屬性基本都在paragraphs部分里;
(2)節屬性包括但不僅限于: # 使用print(dir(paragraph)) 、使用print(dir(paragraphs))查看更多屬性和下級物件
- 整段內容 :paragraph.text
- 對齊方式 :paragraph.alignment
- 段前距 :paragraph.paragraph_format.space_before
- 段后距 :paragraph.paragraph_format.space_after
- 左側縮進 :paragraph.paragraph_format.left_indent
- 右側縮進 :paragraph.paragraph_format.right_indent
- 首行縮進 :paragraph.paragraph_format.first_line_indent
- 行間距 :paragraph.paragraph_format.line_spacing
(3)分欄、專案符號不在paragraphs屬性里,只能從xml檔案識別,
🍍4.讀取字塊們:檔案.paragraphs
paragraphs = file.paragraphs # 段落們
for i in range(len(paragraphs)): # 遍歷段落
paragraph = paragraphs[i]
if paragraph.text!="": # 篩選非空段
for run in paragraph.runs: # 遍歷字塊
print(run.text) # 字塊內容
break
(1)有關字的屬性基本都在runs部分里;
(2)runs字塊在切割時,常以相同屬性分割,遇到不同屬性時分割,如:
-
全球超級計算機500強榜單20日公布,“神威太湖之光”登上榜首,
-
若設定中英文不同字體,則該段落字塊被分成:全球超級計算機///500///強榜單///20///日公布,“神威太湖之光”登上榜首,
-
原理上筆者猜測各屬性完全一致的一個段落會被劃分為一個整字塊,
而在筆者實際操作閱卷時,學生總有離奇的神操作,同樣的段落常被分割為不同的字塊,且同一檔案運行幾次每次結果都不一樣,令人咬牙切齒,故在實際運用時,筆者只取首字塊的首字調取其屬性,
-
(3)字塊屬性包括但不僅限于: # 使用print(dir(run)) 、使用print(dir(runs))查看更多屬性和下級物件
- 內容 :run.text
- 字體 :run.font.name # font
- 字號 :run.font.size
- 斜體 :run.font.italic
- 加粗 :run.font.bold
- 下劃線 :run.font.underline
- 顏色 :run.font.color.rgb # 顏色RGB值
🍍5.讀取表格們:檔案.tables
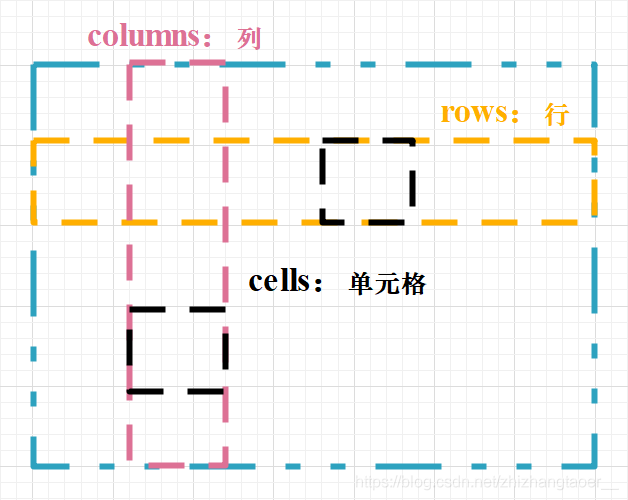
tables = file.tables # 表格們
for table in tables: # 遍歷表格
for row in table.rows: # 遍歷表格行
r1 = r1 + 1
for cells in row.cells:
print(cell.text) # 逐行列印表格內容
for column in table.columns: # 遍歷表格列
r2 = r2 + 1
print(r1,r2) # r1行數 r2列數
(1)表格屬性 在tables中:
- 表格對齊方式 :table.alignment # 區別于單元格對齊方式
(2)行列屬性 在rows和columns中:
- 表格行高 :row.height
- 表格列寬 :column.width
(3)單元格屬性 在cells中:
- 單元格內容 :cell.text
- 單元格對齊方式 :cell.alignment
🍍6.讀取圖片們:檔案.inline_shapes
pics = file.inline_shapes # 圖片們
for pic in pics: # 遍歷圖片
- 圖片長 :pic.width
- 圖片寬 :pic.height
- (不知道是什么type) :pic.type
docx庫里能識別到的格式并不完整,本文有提到可識別的大部分格式,其余多數只能通過讀取xml檔案調取,雖然xml檔案可以識別到全部格式,但使用docx庫讀取還是更加簡便,能不用xml就盡量不用,
然而庫功能并不完全,此時需要讀取.docx檔案轉成的.xml檔案,識別其中格式,其中最常用的格式是頁碼,本文以識別頁碼為例,
————————
四、讀取xml檔案識別檔案結構:
🍋1.檔案轉換
(1)最直接的方法:手工將word.docx檔案重命名為word.zip檔案,再解壓縮,
①原檔案

②是
③解壓到當前檔案夾,或你選擇的地方

④我們需要使用到的xml檔案都在解壓后的word檔案夾里
⑤根據檔案的不同,里面的xml檔案數量和內容均有差異,例如筆者這個檔案有頁眉和頁腳,故該檔案夾下才有footer123.xml和header123.xml,若無頁眉頁腳且無修改頁眉頁腳歷史記錄,則該檔案夾下不含footer123.xml和header123.xml,用記事本可以簡單地打開查看內容,
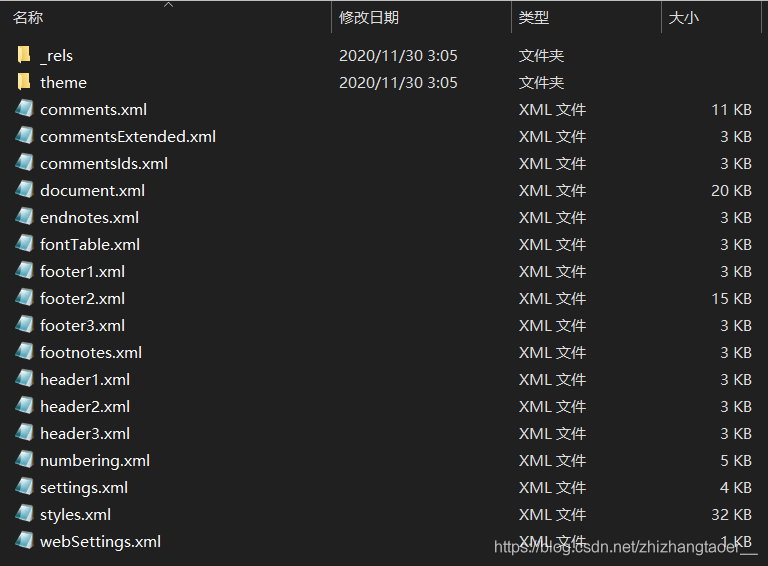
(2)使用代碼批量轉換,在CSDN上有很多代碼分享,可自行查閱word轉xml檔案等關鍵字,此處貼筆者使用的代碼,尷尬的是筆者找不到原出處了,若原作者看見本文請聯系筆者填寫出處或洗掉本部分,非常抱歉,
- 因筆者將試卷檔案夾設定為學生學號,每個學號的檔案夾里有三個需要讀取的檔案,故先讀取名單中學號,以學號作為試卷地址路徑的一部分,批量每個學號解壓檔案夾里的三個檔案,
import os
import zipfile
import shutil
import xlrd
class Name_list():
def __init__(self, file_address):
self.file_address = file_address
pass
def read(self, sheet_name):
workbook = xlrd.open_workbook(self.file_address)
sheet = workbook.sheet_by_name(sheet_name)
data = []
for i in range(0, sheet.nrows):
data.append(sheet.row_values(i))
return data
pass
def unzip_file(path, filenames):
print(path)
#print(os.listdir(path))
for filename in filenames:
filepath = os.path.join(path,filename)
if os.path.exists(filepath):
zip_file = zipfile.ZipFile(filepath) # 獲取壓縮檔案
#print(filename)
newfilepath = filename.split(".",1)[0] # 獲取壓縮檔案的檔案名
newfilepath = os.path.join(path,newfilepath)
#print(newfilepath)
if os.path.isdir(newfilepath): # 根據獲取的壓縮檔案的檔案名建立相應的檔案夾
pass
else:
os.mkdir(newfilepath)
for name in zip_file.namelist(): # 解壓檔案
zip_file.extract(name,newfilepath)
zip_file.close()
Conf = os.path.join(newfilepath,'conf')
if os.path.exists(Conf): # 如存在組態檔,則洗掉(需要刪則刪,不要的話不刪)
shutil.rmtree(Conf)
print("解壓{0}成功".format(filename))
def main():
for j in range(int(len(student_list) - 2)):
stu_id = student_idlist[j]
address_stu_id = str(address_beforeid + str(stu_id)) # 試卷地址
if os.path.exists(address_stu_id):
filenames = ['excel操作題.xlsx', 'PPT操作題.pptx', 'word操作題.docx'] # 目錄下需要解壓的檔案名
unzip_file(address_stu_id, filenames)
pass
if __name__ == '__main__':
address_idlist = r"F:\名單.xlsx" # 名單
address_beforeid = 'F:\\試卷\\' # 試卷路徑學號檔案夾之前的部分
student_list = Name_list(address_idlist).read('Sheet1')
student_idlist = [[] for r in range(int(len(student_list) - 2))]
for k in range(int(len(student_list) - 2)):
student_idlist[k] = int(student_list[k + 2][1])
pass
main()
(3)轉換完成后的效果:
🍋2.讀取xml識別word頁碼
————關于格式在哪個xml檔案的哪層標簽、如何找放在下一小節,先上結論,
(1)頁碼的標簽一般在word檔案夾中footer2.xml檔案中,有頁碼但找不到考慮尋找footer1.xml和footer3.xml內容,
(2)根標簽內的< ftr > < /ftr>標簽內的2級< sdt > < /sdt >標簽中存盤頁碼相關屬性,檔案中有< sdt > < /sdt >標簽在閱卷時至少證明該考生對頁碼進行過操作,會使用頁碼功能,
(3)< sdt > < /sdt >標簽內的5級標簽< instrText > < /instrText >記憶體儲頁碼格式資訊,頁碼樣式不同在 instrText標簽例如本題要求學生添加型如 “ - 1 - ” 形式的頁碼,則在instrText中的.text為 :PAGE * MERGEFORMAT,另有5級標簽<jc></jc>中的.attrib存盤頁碼對齊方式,此處默認對齊方式為居中,頁碼默認居中時, xml檔案中無 jc標簽,
- 貼上讀xml檔案的代碼,此處代碼參考:
https://blog.csdn.net/weixin_36279318/article/details/79176475
import xml.etree.ElementTree as ET
class Xml2DataFrame:
def __init__(self,xmlFileName):
self.xmlFileName = xmlFileName
pass
def read_xml(self):
tree = ET.parse(self.xmlFileName)
root = tree.getroot()# 第一層決議
#print('root.tag:', root.tag, ',root-attrib:', root.attrib, ',root-text:', root.text)
for sub1 in root:# 第二層決議
child = sub1
print('sub1.tag:', child.tag, ',sub1.attrib:', child.attrib, ',sub1.text:', child.text)
for sub2 in sub1:# 第三層決議
child = sub2
print('sub2.tag:', child.tag, ',sub2.attrib:', child.attrib, ',sub2.text:', child.text)
(此處繼續嵌套for 略寫)
if __name__ == '__main__':
file_path = r'F:\考試檔案夾\學號\word操作題\word\footer2.xml'
xml_df = Xml2DataFrame(file_path)
xml_df.read_xml()
得以下輸出結果 :
sub1.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}sdt ,sub1.attrib: {} ,sub1.text: None
sub2.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}sdtPr ,sub2.attrib: {} ,sub2.text: None
sub3.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}id ,sub3.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': '-482698706'} ,sub3.text: None
sub3.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}docPartObj ,sub3.attrib: {} ,sub3.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}docPartGallery ,sub4.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': 'Page Numbers (Bottom of Page)'} ,sub4.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}docPartUnique ,sub4.attrib: {} ,sub4.text: None
sub2.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}sdtContent ,sub2.attrib: {} ,sub2.text: None
sub3.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}p ,sub3.attrib: {'{http://schemas.microsoft.com/office/word/2010/wordml}paraId': '57F7B8B0', '{http://schemas.microsoft.com/office/word/2010/wordml}textId': '0880F220', '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}rsidR': '001547AD', '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}rsidRDefault': '001547AD'} ,sub3.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}pPr ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}pStyle ,sub5.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': 'ac'} ,sub5.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}jc ,sub5.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': 'right'} ,sub5.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}r ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldChar ,sub5.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldCharType': 'begin'} ,sub5.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}r ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}instrText ,sub5.attrib: {} ,sub5.text: PAGE \* MERGEFORMAT
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}r ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldChar ,sub5.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldCharType': 'separate'} ,sub5.text: None
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}r ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}rPr ,sub5.attrib: {} ,sub5.text: None
sub6.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}lang ,sub6.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': 'zh-CN'} ,sub6.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}t ,sub5.attrib: {} ,sub5.text: 2
sub4.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}r ,sub4.attrib: {} ,sub4.text: None
sub5.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldChar ,sub5.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}fldCharType': 'end'} ,sub5.text: None
sub1.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}p ,sub1.attrib: {'{http://schemas.microsoft.com/office/word/2010/wordml}paraId': '337E501C', '{http://schemas.microsoft.com/office/word/2010/wordml}textId': '77777777', '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}rsidR': '001547AD', '{http://schemas.openxmlformats.org/wordprocessingml/2006/main}rsidRDefault': '001547AD'} ,sub1.text: None
sub2.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}pPr ,sub2.attrib: {} ,sub2.text: None
sub3.tag: {http://schemas.openxmlformats.org/wordprocessingml/2006/main}pStyle ,sub3.attrib: {'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}val': 'ac'} ,sub3.text: None
(4)在讀取xml每一層內容時,因筆者水平有限,使用for嵌套for嵌套for讀取每一層,在讀取較復雜檔案時不得不嵌套到了20個for,經請教得知可使用遞回寫法,但遞回演算法占用記憶體較多,對電腦要求較高,考慮到學院辦公室的電腦配置,也有筆者水平有限,運用遞回實屬痛苦,此優化暫停,
(5)閱卷抽取關鍵資訊時定義一變數a用以存盤內容,if ‘sdt’ in child.tag : a = str(child.tag + child.attrib + child.text),判斷字串內容,再定標判分即可,
(6)兩個非常相似的.docx可能因為一個小差異,在xml檔案存盤時格式資訊存盤的層數有很大區別,筆者遇見最高相差5層,因此在尋找某標簽的層數時、輸出時若找不到,除了考慮是不是默認屬性,還要考慮是否存盤在相鄰的上下幾層中,
🍋3.查看xml尋找位置
(1)識別某格式,首先需要找到該格式的xml存盤標簽,筆者新建3個空白word,第一個空白保存,第二個添加普通頁尾,第三個添加要求格式頁碼,
(2)上面提到我們可以使用記事本簡單地打開xml檔案查看內容,此處對這三個檔案進行比較,使用記事本打開xml檔案,復制全文粘貼到某新建excel表格中某單元格,使用excel分列功能以’ < '符號分列 , 就可以找到每個標簽中的區別了,在經過篩查后最終確定該格式存盤在某標簽中,
反正是笨辦法英文單詞連蒙帶猜加谷歌翻譯四級水平綽綽有余


(3)下一步我們需要確定標簽大致層數,使用代碼使其xml輸出顯示逐層推進,此處代碼參考:
https://blog.csdn.net/qq_41958123/article/details/105357692
import xml.dom.minidom
uglyxml = '需要輸出的xml內容'
xml = xml.dom.minidom.parseString(uglyxml)
xml_pretty_str = xml.toprettyxml()
print(xml_pretty_str)
輸出如圖:

全選復制粘貼進excel:
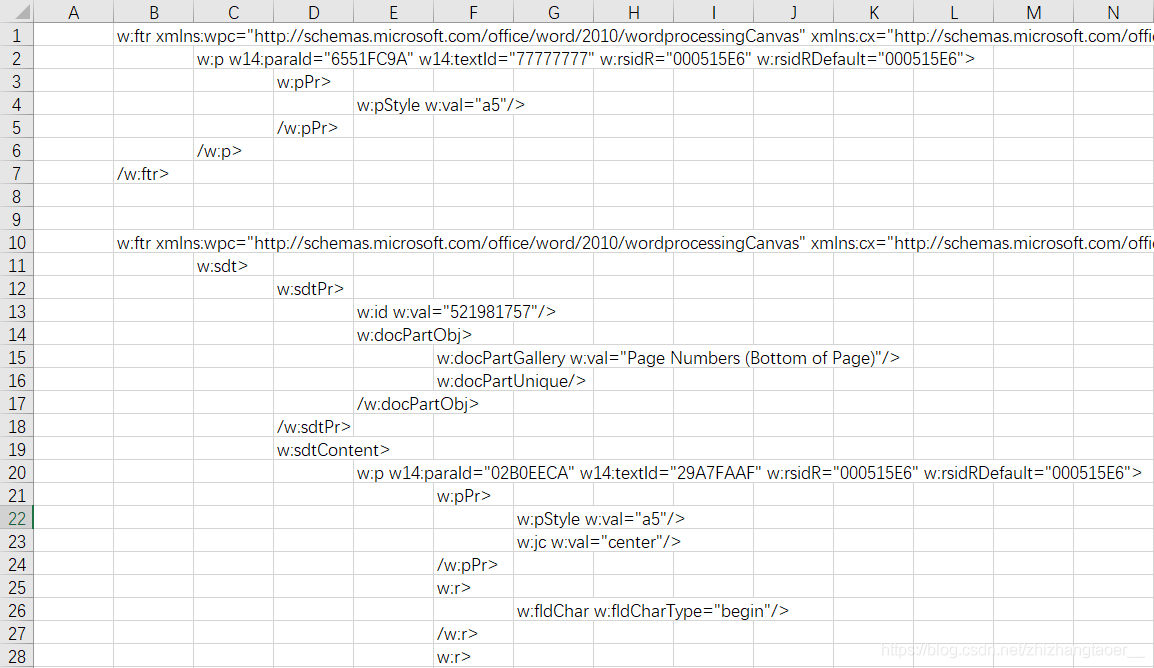
再搜索標簽名確定位置,數列數即可,
————————
五、總結
- 這是office三件套的第①部分——word部分,接下來要去準備網課考試和組會了,有空再梳理excel部分、ppt部分和面對學生們的奇葩操作,為了防止程式崩潰中斷應注意的各種注意事項,
- 反正就是笨辦法只考驗耐心的辦法,從一開始就處處暴露我的非專業性,我也找不到更好的辦法,我就是閑的,不想人工改卷子想一勞永逸,我菜我認了別罵我,不愛看右上角八叉關閉謝謝您的善意,

我終于梳理完了怎么這么長
六、參考鏈接
https://blog.csdn.net/weixin_36279318/article/details/79176475
https://blog.csdn.net/qq_41958123/article/details/105357692
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229198.html
標籤:python
上一篇:無法爬取淘寶商品頁面
下一篇:python基本資料型別都在這里