今天我們爬圖片
- 開始
- 分析
- 實踐
開始
大家好鴨,又是新的一天!
無論做什么事情,都要恪守初心,要知道我們是為了什么才學爬蟲的,比如我,就是為了爬取一些好看的圖片……
所以,今天帶大家一起爬一些好看的,圖片~
話不多說,直接高速!
http://www.win4000.com/zt/dongman.html
作為一個老二刺猿,當然是直接找動漫圖片~
分析
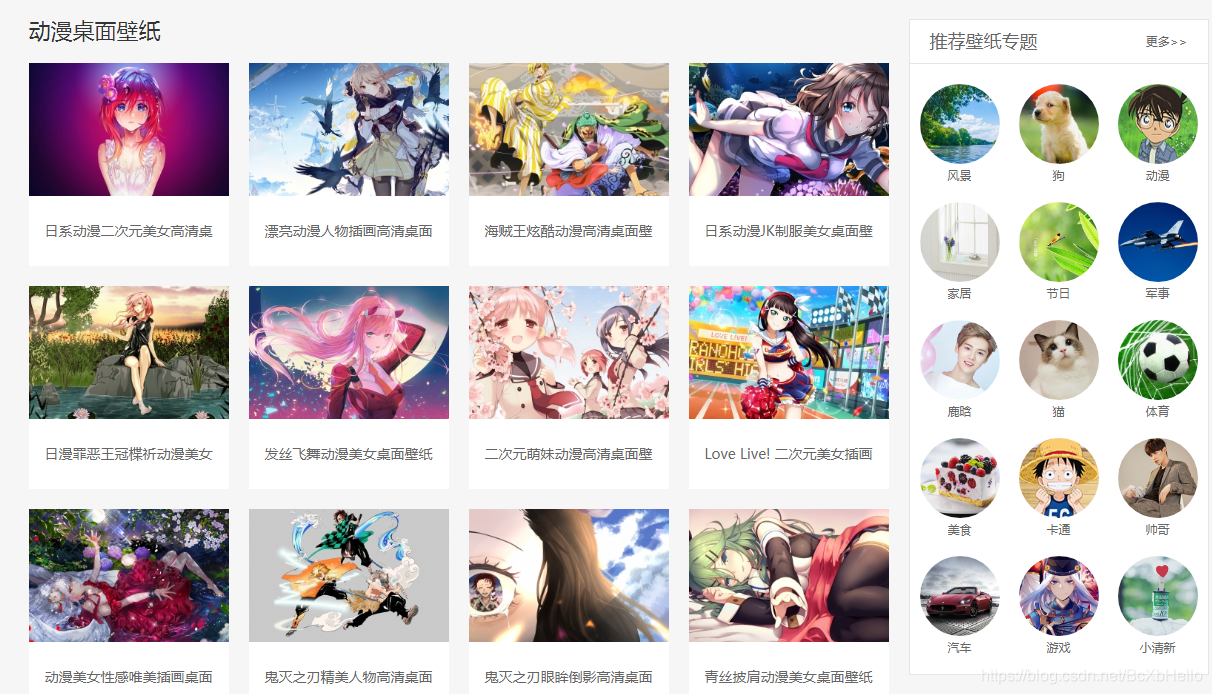
打開頁面后往下拉,發現圖片是真滴好看……
里面還有我的02老婆~
認真分析,看到這一張張的圖片,我們是不是可以認為這些圖片是放在一個串列里的,所以一會我們爬取這個串列,然后把每一張圖片遍歷出來就可以了,對吧!(遍歷大意:用回圈把串列中每一個元素列出來)
好,打開我們的抓包工具!(審查元素 或 檢查)
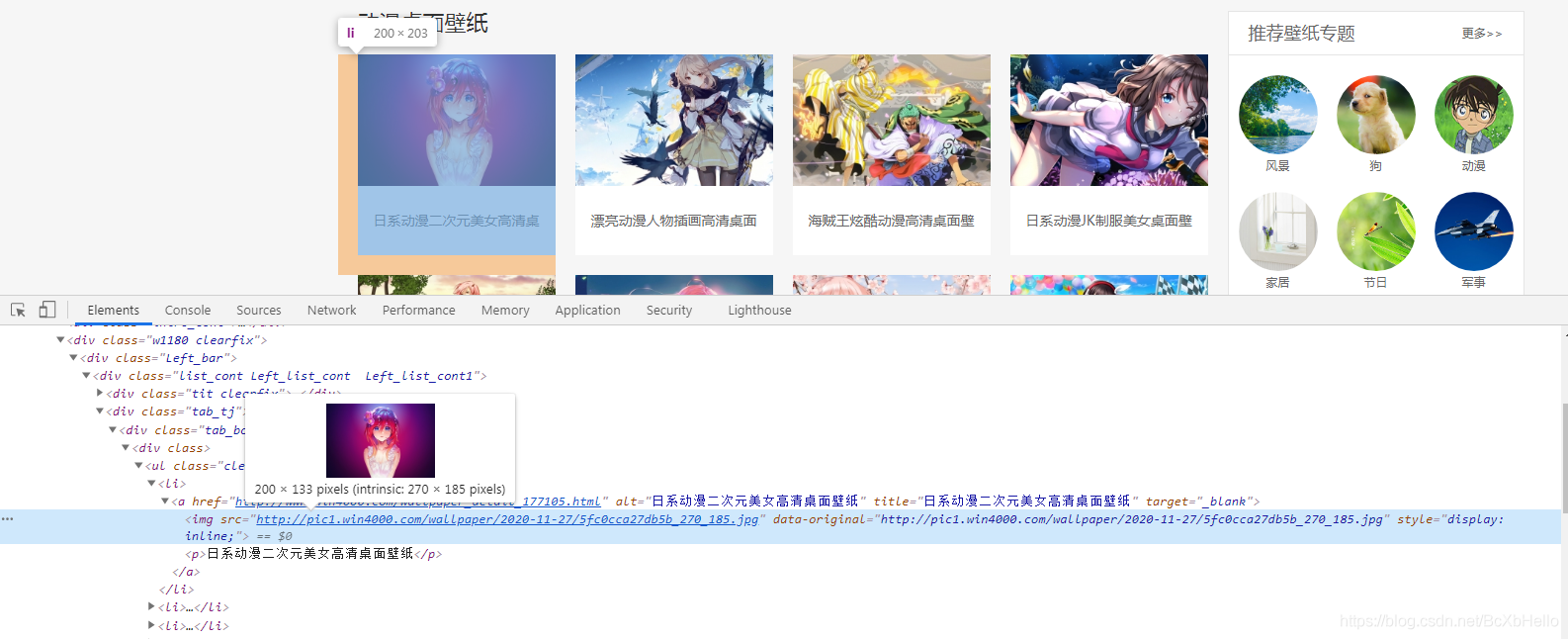
找到圖片所對應的位置,發現直接就有圖片了,那我們直接爬取整個頁面,再把爬取到的資料篩選一下,只要圖片的網址然后再單獨下載不就好啦~
這個想法是對的,但是打開那個網址會發現……

我們上當了!
這只是一個縮略圖,那么真正的圖片在哪里呢?學過html的同學應該能直接找到,沒學過的呢,就跟著小澤一起往下走,
我們點開某一張圖片,會發現跳到了另一個頁面,
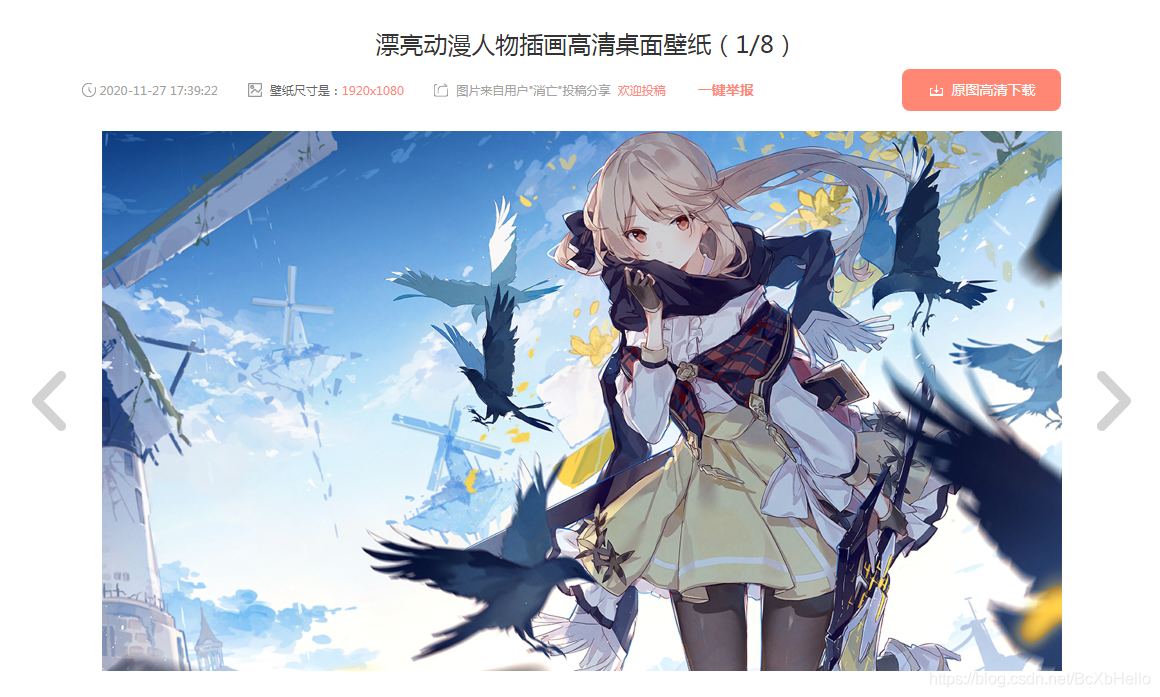
在新的頁面,我們會發現有個下載按鈕,還有個左右切換的按鈕,
先點擊一下下載按鈕試試……
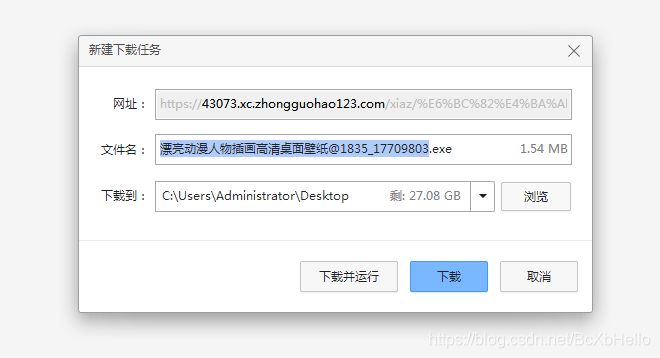
好家伙,直接好家伙,
一看后綴名就知道,我們又上當了!
這個按鈕或許會給你一種錯覺,跟昨天的翻譯按鈕一樣,會不會回傳一個圖片,我們只要接收了再保存就好了,
這個想法是沒錯的,但是奈何這個網站太狡猾,實在是狡猾!
這個時候打開抓包工具看一下我們要的東西還有沒有,
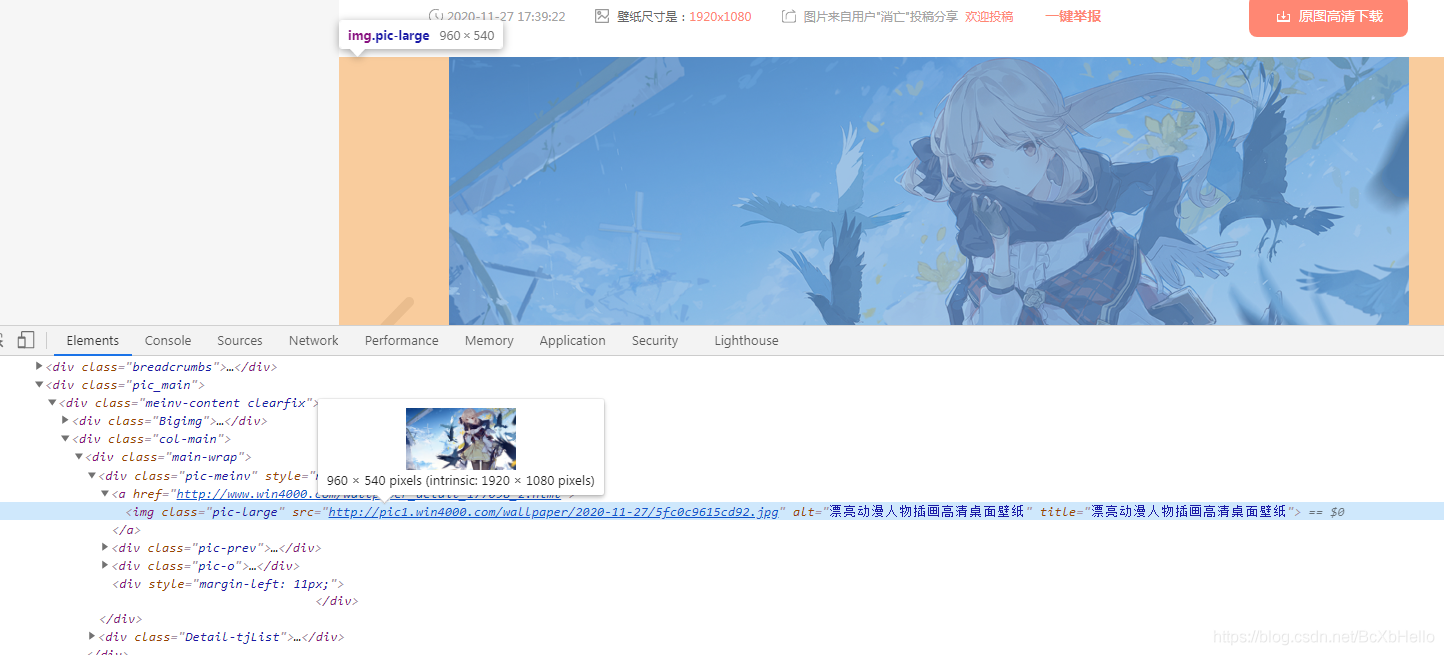
找到你啦,色圖 美圖!
我們再打開這個鏈接,看一下是不是真正的大圖,

可以了可以了,夠大了!
那么我們現在就是找到了真正存放圖片的地址,但是還有一個地方不能忽略,來回切換的那個按鈕,到底有什么用?
我們點一下,注意觀察網址的變化!




發現規律了沒,網址每一次都會在177098_后面加1,那么177098_1是不是就是第一張圖片呢?大家可以試一下,
試完你就會發現還真的是誒,好神奇!
但是還有個問題,這一組圖片是8張,也就是177098_1到177098_8,那么其他的圖組是不是呢(一開始還以為是一張一張圖片,上當啦,hh)

好的,果然讓我們發現一個,那就是說每組圖組里面圖片的數量是不固定的,只爬第一張怎么會滿足呢!
這樣想,如果我們上面那個圖組出現177098_9會怎么樣?
程式不出意外應該會報錯,那我們只要建立一個死回圈,在報錯的時候就終止回圈,就可以不用管它有多少張,我全都要的下載下來啦!
思路很明確,但是實作起來…
嗨,先硬著頭皮上吧,啃!
實踐
import requests
url = 'http://www.win4000.com/zt/dongman.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
首先匯入我們的requests模塊,先設好url和回應頭資訊,
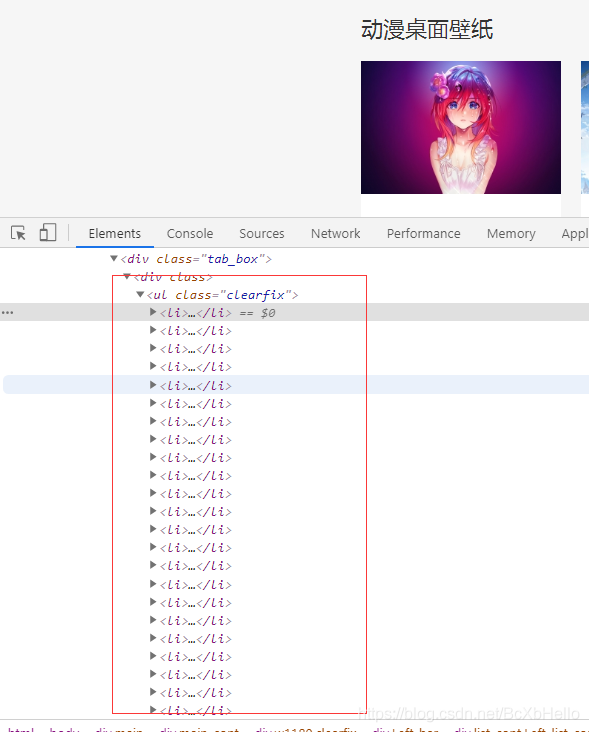
通過抓包工具我們發現,這些圖片確確實實可以當做一個串列,每一個li標簽都在class為clearfix的ul標簽里,
那我們有沒有辦法只獲取這一部分資料呢?
辦法是有的,但是突然告訴你可能會很迷茫,不過不要糾結,先用著,
from lxml import etree
這就是我們的解決方法,etree,我是這樣理解的,把網頁變成一棵樹,很easy的就找到我們要的樹葉,
當然你也可以百度一下這個模塊,多了解一下~
response = requests.get(url=url,headers=headers).text
tree = etree.HTML(response)
leaf = tree.xpath('//div[@class="tab_tj"]//ul[@class="clearfix"]/li/a/@href')
第一句大家應該能看懂吧,把回應的頁面資料以文本的形式給response,
第二句的意思呢,就是把文本形式的網頁資料給變成大樹!可以這么理解哦,因為我們要找的是某一片葉子,所以要用etree.HTML()把它大樹化~
第三句里的leaf是葉子的意思哦,要記住這個xpath,查帕斯查帕斯查帕斯,這是我們找葉子的一種方法,一般來說是可以直接在抓包工具那里直接右鍵復制xpath,就是你要找的地方的xpath,但是這個網站復制過來的xpath并不怎么管用,這也說明了方便不一定好用哈~
所以這里小澤就手打了xpath陳述句,
// 的意思是不用從根目錄開始,如果只打一個斜線就是要從/html開始了,但是我們直接找class為tab_tj的div就行了,中間的//意思就是div和ul中間不是還有東西嘛,直接跳過了,不一一打出來了,一個下劃線就是跳一級,最后的@href就是直接艾特我們要的資料,他就會乖乖過來啦!
上圖~
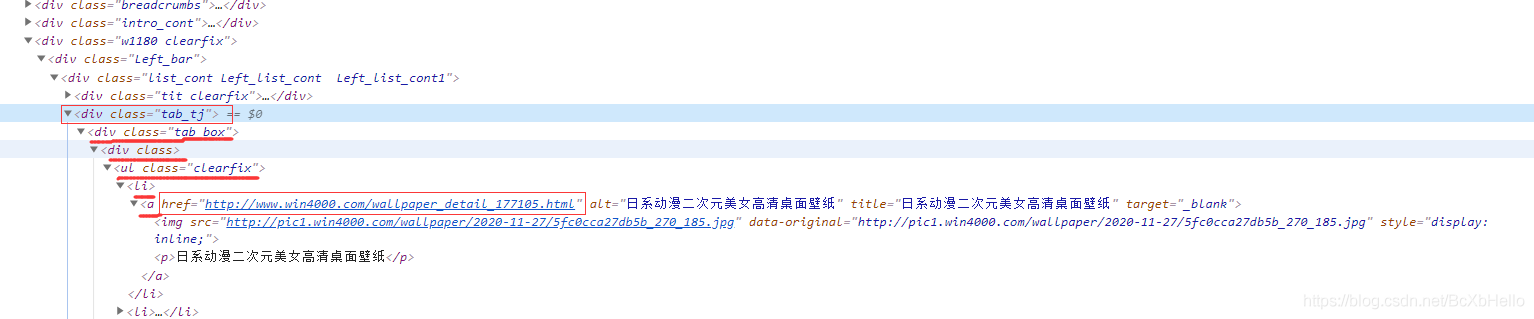
這就是xpath方法哦,記住了,查帕斯!
那我們一會肯定要給圖片起名的嘛,就可以再弄一個葉子,最后改成@alt就行啦~
這里小澤是遍歷了一下葉子,記住嘍,爬下來的是個串列~
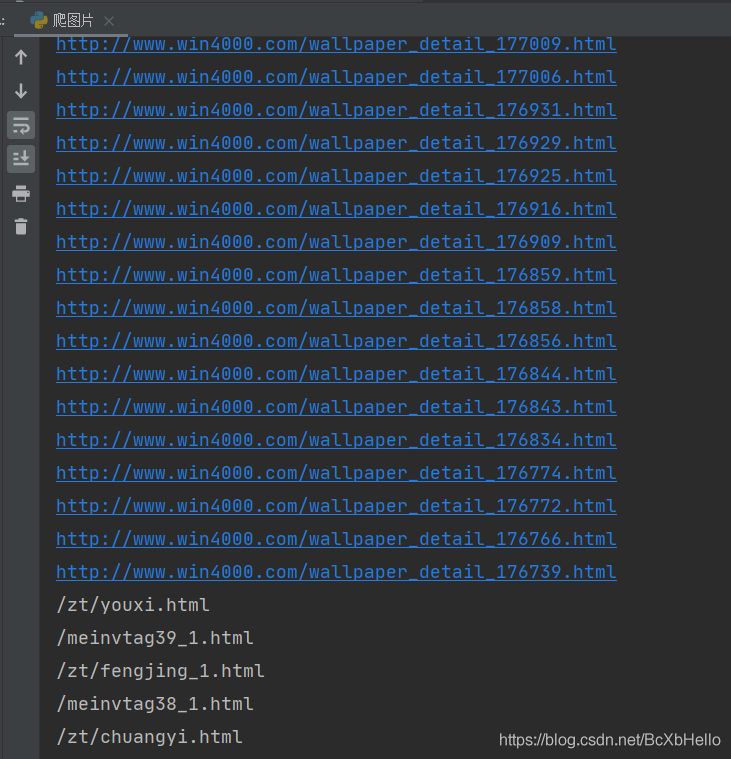
不過爬下來的網址里混入了幾個不明物體,這個小澤也不知道是為什么誒,有會的大佬歡迎留言一下~
一會用處理報錯的那個東西,try和except~
很多同學可能會還處于懵逼狀態,如果是因為對xpath那塊不理解的話,留言一下,如果點贊留言的人多的話,后續會專門寫一篇關于我們去找我們要的資料的方法相關的文章!(誰不喜歡偷懶呢,hhh)
import requests
from lxml import etree
import os
# 指定第一個url
url = 'http://www.win4000.com/zt/dongman.html'
# 指定偽裝頭
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
# 讀取第一個url
response = requests.get(url=url,headers=headers).text
# 樹化第一個頁面
tree = etree.HTML(response)
# 找到圖片對應的第二個頁面(li串列)
leaf = tree.xpath('//div[@class="tab_tj"]//ul[@class="clearfix"]/li/a/@href')
# 創建一個檔案夾
if not os.path.exists('./setu'): # 如果該檔案夾不存在,則創建
os.mkdir('./setu')
# 遍歷每一張圖片所對應的第二個頁面
for a in leaf:
# 防止出錯中止程式
try:
# 設定區域變數,177105_b
b = 1
# 回圈獲取圖集里的每一張圖片,默認最多10張
while b < 11:
# 切割-->拼接
c = a.split('.html')[0]
d = c+'_'+str(b)+'.html'
# 當前圖集的下一張
b += 1
# 對第二個頁面開始讀取,前面的都是為了方便找url
e = requests.get(url=d,headers=headers).text
# 樹化第二個頁面
f = etree.HTML(e)
# 在第二個頁面里找到我們要的圖片地址 [0]是指把串列里第一個元素提取出來,可以這么拼接!!
g = f.xpath('//div[@class="main"]//div[@class="pic-meinv"]/a/img/@src')[0]
# 獲取圖片的二進制資料
h = requests.get(url=g,headers=headers).content
# 給圖片起名
i = 'setu/'+g.split('/')[-1]
# 持久化存盤
with open(i,'wb') as fp:
fp.write(h)
except:
print('出錯啦')
廢話不多說,直接把全部代碼都弄上來啦!
其實都是剛敲的,網站也是剛找的,還有點怕翻車,hhh
上面代碼里跟爬蟲有關的知識已經跟大家說的差不多了,看著注釋應該也能大概明白,要學的不是上面的代碼哦,是思路,
有了思路,就很容易有目標的去學習啦~
由于很多代碼是跟基礎有關的,而且思路也跟大家分析明白了,所以就不多說了,如果你真的真的哪里看不懂,搞不明白的話,不要怕,沒有什么別人都會我不會不好意思問什么的,放心大膽的留言,留言的時候最好帶上自己出錯的代碼或者不明白的代碼,一定鼎力相助!
一起變得更厲害吧!
話說今天沒有加表情包誒……
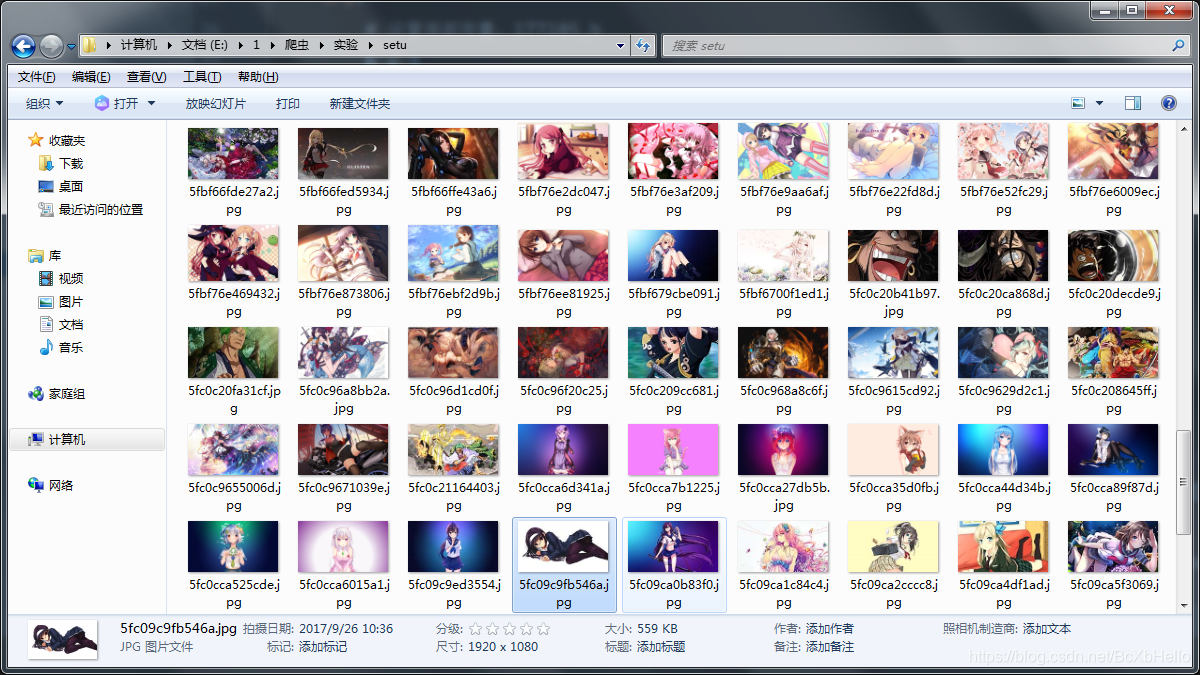
這是小澤剛才爬下來的圖片,都是可以直接當螢屏壁紙的那種哦!
不乏春光乍露之圖,哇哦~

那么,各位晚安嘍~
最后的最后,給個贊和關注再走好不好QAQ
還有已經關注了小澤的粉絲可以任性的提問題和請求哦,比如想爬哪個網站,或者想學哪方面的知識,粉絲專利哦!!!
ByeBye~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229200.html
標籤:python
上一篇:python基本資料型別都在這里