目錄
一、List 介面
1. 概述
2. List 介面中的抽象方法(特有)
3. List 遍歷
二、ListIterator 介面
1.概述
2. ListIterator 介面的抽象方法
3. List 逆向遍歷:
三、迭代器的并發修改例外
1. 迭代器的并發修改例外
2. 出現場景:
3. 原因:
四、ArrayList 、LinkedList 集合
1. ArrayList 集合
2. LinkedList 集合
3. Vector 集合(基本不用)
五、Set 介面
六、 HashSet (哈希表)
1. 特點
2. 哈希表的資料結構
3. 字串物件的哈希值
4. 哈希表的存盤程序
5. 哈希表的存盤自定義物件
6. LinkedHashSet 集合
7. ArrayList,HashSet 判斷物件是否重復的原因
七、TreeSet
1.概述
2. TreeSet如何實作,不能存盤重復元素
3. 向TreeSet中放入,自定義的類的物件
4. 注意事項
一、List 介面
1. 概述
- 繼承 Collection 介面,它是一個元素存取 有序 的集合
例如,存元素的順序是11、22、33,那么集合中,元素的存盤就是按照11、22、33的順序完成的)
-
它是一個 帶有索引 的集合,通過索引就可以精確的操作集合中的元素(與陣列的索引是一個道理)
-
與 set 不同,List 中 可以有重復的元素,通過元素的
equals方法,來比較是否為重復的元素 -
List 介面的常用實作類有:
-
ArrayList 集合
-
LinkedList 集合
2. List 介面中的抽象方法(特有)
add(int index, Object e): 向集合指定索引處,添加指定的元素,原元素依次 后移remove(int index):將指定索引處的元素,從集合中洗掉,回傳值為被洗掉的元素set(int index,E element):將指定索引處的元素,替換成指定的元素,回傳值為替換前的元素get(int index):獲取指定索引處的元素,并回傳該元素
3. List 遍歷
List<Person> a = new LinkedList<>();
a.add(new Person("zs",10));
a.add(new Person("lisi",20));
a.add(new Person("wangwu",30));
//利用Iterator來遍歷List
Iterator<Person> iterator = a.iterator();
//利用迭代器物件遍歷
while(listItr.hasNext()) {
System.out.println(listItr.next());
}
//List獨有的遍歷方式
for (int i = 0; i < a.size(); i++) {
System.out.println(a.get(i));
}
二、ListIterator 介面
1.概述
- List 不僅有自己獨有的迭代方式,還有自己獨有的迭代器:
ListIterator
2. ListIterator 介面的抽象方法
add(E, e):將指定元素插入串列boolean hasPrevious():逆向遍歷串列,若串列迭代器有多個元素,則回傳 true,也就是判斷是否有前一個元素previous():回傳串列的前一個元素
3. List 逆向遍歷:
Iterator<Person> iterator = a.iterator();
ListIterator<Person> listItr = a.listIterator(a.size());
//先順序遍歷,讓 cursor 到最后
while(listItr.hasNext()) {
System.out.println(listItr.next());
}
//逆向遍歷
//先previous向前移動一個位置,再訪問cursor指向的元素
while(listItr.hasPrevious()) {
System.out.println(listItr.previous());
}
三、迭代器的并發修改例外
1. 迭代器的并發修改例外
java.util.ConcurrentModificationException
- 就是在遍歷的程序中,使用了集合方法 修改了 集合的長度
2. 出現場景:
首先,在遍歷集合的程序中修改集合;其次,修改集合行為,不是迭代器物件來完成的,而是直接修改 Collection 物件
//場景實作
List<String> list = new ArrayList<String>();
list.add("abc1");
list.add("abc2");
list.add("abc3");
list.add("abc4");
//對集合使用迭代器進行獲取,獲取時候判斷集合中是否存在 "abc3"物件
//如果有,添加一個元素 "ABC3"
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
//對獲取出的元素s,進行判斷,是不是有"abc3"
if(s.equals("abc3")){
list.add("ABC3");
}
System.out.println(s);
}
3. 原因:
在迭代程序中,使用了集合的方法對元素進行操作,導致迭代器并不知道集合中的變化,容易引發資料的不確定性,迭代器物件,是依賴與當前的資料集合產生的(換言之,迭代器依賴于資料集,它們必須對應)
public class ListDemo{
public static void main(String[] args) {
List<Person> a = new LinkedList<>();
//迭代器
ListIterator<Person> listItr = a.listIterator();
a.add(new Person("zs",10));
a.add(new Person("lisi",20));
a.add(new Person("wangwu",30));
while(listItr.hasNext()){
Person p = listItr.next();
//這種添加元素的方式,會產生例外
//a.add(new Person("zhaoliu", 40));
//解決: 利用ListIterator物件添加元素
listItr.add(new Person("zhaoliu", 40));
}
}
System.out.println(s);
//針對List還有另外一種,在遍歷集合同時修改集合的解決方案
for (int i = 0; i < a.size(); i++){
if("lisi".equals(a.get(i).name)){
a.add(new Person("zhaoliu", 40));
}
}
System.out.println(a);
//如果使用 ListIterator 的add方法向集合中添加元素,這個元素的位置處在當前遍歷到的元素之后的位置
//如果使用 集合物件的 add(e) 方法添加元素,插入的元素處在表尾位置
}
四、ArrayList 、LinkedList 集合
1. ArrayList 集合
- 底層采用的是 陣列 結構,執行緒不安全,查詢快,增刪慢
//創建了一個長度為0的Object型別陣列
ArrayList al=new ArrayList();
al.add("abc");
//本質:
//底層會創建一個長度為10的Object陣列 Object[] obj=new Object[10]
//obj[0]="abc"
//如果添加的元素的超過10個,底層會開辟一個1.5*10的長度的新陣列
//把原陣列中的元素拷貝到新陣列,再把最后一個元素添加到新陣列中
2. LinkedList 集合
- 底層采用 鏈表 結構,執行緒不安全,查詢慢,增刪快
- 每次查詢都要從鏈頭或鏈尾找起,查詢相對陣列較慢,但是洗掉直接修改元素記錄的地址值即可,不要大量移動元素
- LinkedList 的索引決定是從鏈頭開始找還是從鏈尾開始找,如果該元素小于元素長度一半,從鏈頭開始找起,如果大于元素長度的一半,則從鏈尾找起
- LinkedList 提供了大量的操作開始和結尾的方法
- 子類的特有功能:不能多型呼叫:
addFirst(E) 添加到鏈表的開頭
addLast(E) 添加到鏈表的結尾
E getFirst() 獲取鏈表的開頭
E getLast() 獲取鏈表的結尾
E removeFirst() 移除并回傳鏈表的開頭
E removeLast() 移除并回傳鏈表的結尾
3. Vector 集合(基本不用)
- Vector 集合資料存盤的結構是 陣列 結構,為JDK中最早提供的集合,它是執行緒同步的,執行緒安全的
- Vector 集合已被 ArrayList 替代
五、Set 介面
1. 特點
-
它是個 不包含重復元素 的集合,沒索引
-
是一個不包含重復元素的 collection
-
無序集合,沒有索引,不存盤重復元素
-
Set無序:存盤和取出的順序不同,
-
Set集合取出元素的方式可以采用:迭代器、增強for
-
代碼的撰寫上,和 ArrayList 完全一致
-
Set集合常用實作類:
-
HashSet 集合 -
LinkedHashSet 集合
六、 HashSet (哈希表)
1. 特點:
- 底層資料結構為 哈希表
- 存盤、取出都比較快
- 執行緒不安全,運行速度快
- 不保證 set 的迭代順序
- 不保證該順序的恒久不變
2. 哈希表的資料結構:
- 加載因子:表中填入的記錄數/哈希表的長度
例如:加載因子是 0.75 代表:陣列中的16個位置, 其中存入 16 * 0.75 = 12個元素, - 如果在存入第十三個( > 12 )元素,導致存盤鏈子過長,會降低哈希表的性能,那么此時會擴充哈希表(再哈希),底層會開辟一個長度為原長度2倍的陣列,把老元素拷貝到新陣列中,再把新元素添加陣列中,
當存入元素數量 > 哈希表長度 * 加載因子,就要擴容,因此加載因子決定擴容時機
3. 字串物件的哈希值:
- 物件的哈希值,是普通的十進制整數,Object 類的方法
public int hashCode()來計算,計算結果 int 整數 - String 類重寫了
hashCode()方法,見原始碼
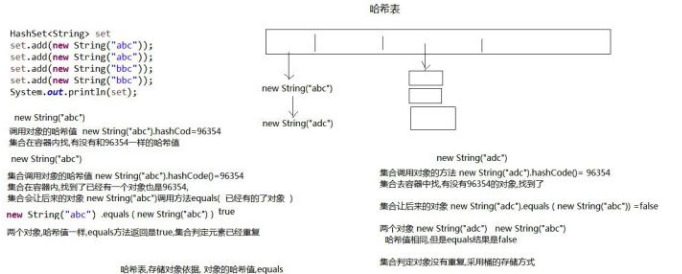
4. 哈希表的存盤程序
存取原理:
每存入一個新的元素都要走以下三步:
1. 首先呼叫本類的hashCode()方法算出哈希值
2. 在容器中找是否與新元素哈希值相同的老元素,如果沒有直接存入,如果有轉到第三步
3. 新元素會與該索引位置下的老元素利用equals 方法一一對比,一旦新元素.equals(老元素),回傳 true,停止對比,說明重復,不再存入,如果與該索引位置下的老元素都通過 equals 方法對比回傳 false,說明沒有重復,存入
哈希表的存盤程序
5. 哈希表的存盤自定義物件
- 自定義物件需要重寫 hashCode() 和 equals(),來保證存入物件的不重復
//重寫hachCode() 方法
public int hashCode(){
return name.hashCode() +age +id; //演算法為name的hashCode值+age+id
}
//重寫equals
public boolean equals(Object obj){
if(this == obj)
return true;
if(obj == null)
return false;
if(obj instanceof Student){
Student s = (Student)obj;
return name.equals(s.name) && age == s.age && id == s.id;
}
return false;
}
6. LinkedHashSet 集合
-
LinkedHashSet基于鏈表的哈希表實作,繼承自HashSet -
LinkedHashSet 自身特性:
-
具有順序,存盤和取出的順序相同的,執行緒不安全,運行速度塊
public class LinkedHashSetDemo {
public static void main(String[] args) {
LinkedHashSet<Integer> link = new LinkedHashSet<Integer>();
link.add(123);
link.add(44);
link.add(33);
link.add(33);
System.out.println(link);
}
}
7. ArrayList,HashSet 判斷物件是否重復的原因
- ArrayList 的
contains()原理:底層依賴于equals()
ArrayList的 contains方法 呼叫時,傳入的元素的呼叫 equals方法 依次與集合中的舊元素所比較,從而根據回傳的布林值判斷是否有重復元素,
此時,當ArrayList存放自定義型別時,由于自定義型別在未重寫equals方法前, 判斷是否重復的依據是地址值,所以如果想根據內容判斷是否為重復元素,需要重寫元素的 equals方法,
- HashSet 的
add()和contains()底層都依賴hashCode()與equals()
Set集合不能存放重復元素,其添加方法在添加時會判斷是否有重復元素,有重復不添加,沒重復則添加,
HashSet集合由于是無序的,其判斷唯一的依據是元素型別的hashCode與equals方法的回傳結果,規則如下:1. 先判斷新元素與集合內已經有的舊元素的HashCode值
2. 如果不同,說明是不同元素,添加到集合,
3. 如果相同,再判斷equals比較結果,回傳true則相同元素;回傳false則不同元素,添加到集合,
所以,使用HashSet存盤自定義型別,如果沒有重寫該類的 hashCode()與equals(),則判斷重復時,使用的是地址值,如果想通過內容比較元素是否相同,需要重寫該元素類的 hashcode()與equals(),
七、TreeSet
1.概述
-
Set 的另外一種實作,底層由 紅黑樹 實作;也就是說TreeSet會根據元素的大小關系,將元素默認從小到大排列
-
特點:
-
元素無序(迭代或者存盤順序和插入順序)
-
不能存盤重復元素
-
沒有位序
-
Comparator comparator();如果TreeSet采用了定制排序,則該方法回傳定制排序所使用 Comparator;如果TreeSet采用了自然排序,則回傳null;
2. TreeSet如何實作,不能存盤重復元素
- 其實,在真正的添加元素,treeset 的 add方法 會搜索整顆紅黑樹(這個元素值,是否已經存在于當前集合,如果存在,則不添加,不存在,就添加)
3. 向TreeSet中放入,自定義的類的物件
- 如果試圖把一個物件添加到 TreeSet 時,則該物件的類必須實作Comparable介面,否則程式會拋出例外
java.lang.ClassCastException
現象:直接向一個 TreeSet 中放入自定義型別的物件,發現直接拋出例外
原因:TreeSet 不知道如何對自定義的類物件進行排序,不像字串可以根據字典順序
- 如何向TreeSet中放入自定義型別的物件?
通過某種方式告訴 TreeSet 我們 自定義物件的比較規則
- 如何自定義比較規則?
- 第一種方式:放入TreeSet 中的元素實作
Comparable介面,根據CompareTo 方法來指定比較規則:比較此物件與指定物件的順序,如果該物件小于、等于或大于指定物件,則分別回傳負整數、零或正整數,負整數 -> 小于,0 -> 等于,正整數 -> 大于
//compareTo方法
@Override
public int compareTo(Student o) {
int result;
if(age == o.age) {
//當兩個同學的年齡形同的時候,進一步按照名字排序
result = name.compareTo(o.name);
} else if(age > o.age) {
result = 100;
} else {
result = -34;
}
return result;
}
- 第二種方式:給 TreeSet 物件定義比較器
Comparator
//通過比較器,來制定比較的規則
TreeSet<Student> students = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getAge() - o2.getAge();
}
});
4. 注意事項
- 約定俗成:一旦元素添加到 TreeSet 之后,禁止修改TreeSet中的元素值
- 原因:修改完TreeSet中的物件后,TreeSe t不會重新調整該元素在樹中的位置
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229843.html
標籤:java