如果你想批量的獲取整個網站的資源,逐個打開網頁進行下載,那樣子耗時又耗力,因此python爬蟲可以代替人去自動完成下載任務,話不多說,直接見代碼:
一、匯入模板
import re
from bs4 import BeautifulSoup
import requests
二、設定請求頭
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.68 Safari/538.36'}
response=requests.get(url,params=headers)
if response.status_code==200:
print("狀態碼成功")
if "驗證" in response.text:
print("被驗證")
return None
else:
return response.text
else:
print("狀態碼失敗"+str(response.status_code))
三、決議HTML檔案
def parse_html(html,name):
soup=BeautifulSoup(html,'lxml')
results=soup.select(name)
with open('黃圖地址.txt','w') as f:
for result in results:
print(result['src'])
f.write(result['src']+'\n')
四、運行
url='https://www.16df.xyz/pic/5/2020-01-10/25477.html'
html=get_html(url)
if html==None:
print('none')
pass
else:
parse_html(html,name='img')
運行之后我們可以得到一個黃圖地址.txt的檔案
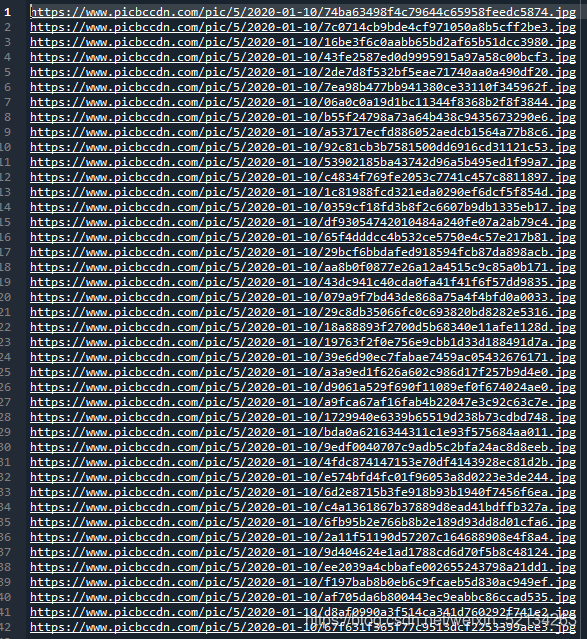
打開某一鏈接就會得到想要的美圖
 完整代打如下:
完整代打如下:
import re
from bs4 import BeautifulSoup
import requests
def get_html(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.68 Safari/538.36'}
response=requests.get(url,params=headers)
if response.status_code==200:
print("狀態碼成功")
if "驗證" in response.text:
print("被驗證")
return None
else:
return response.text
else:
print("狀態碼失敗"+str(response.status_code))
def parse_html(html,name):
soup=BeautifulSoup(html,'lxml')
results=soup.select(name)
with open('黃圖地址.txt','w') as f:
for result in results:
print(result['src'])
f.write(result['src']+'\n')
url='https://www.16df.xyz/pic/5/2020-01-10/25477.html'
html=get_html(url)
if html==None:
print('none')
pass
else:
parse_html(html,name='img')
六、復盤(詳細解讀)
①請求頭:
如果你直接在Python的編輯器中用get方法獲取目標html檔案,則服務器端會準確識別你為爬蟲,很多網站有反爬措施,則會將你拒之門外,那么正確使用請求頭則會在一定程度上避免這種不友好行為,但是目前很多服務器會識別你的請求頭,也會將你拒之門外,我們可以使用代理來解決這種問題,對于絕大多數小型網站來說,只需要一個簡單的請求頭,則可以獲取目標html檔案,下圖就是一個非常簡單的請求頭,
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.68 Safari/538.36'}
response=requests.get(url,params=headers)
如果不知道請求頭在哪里找,我們可以打開某一個網站,如下圖,紅圈內的代碼即為請求頭:
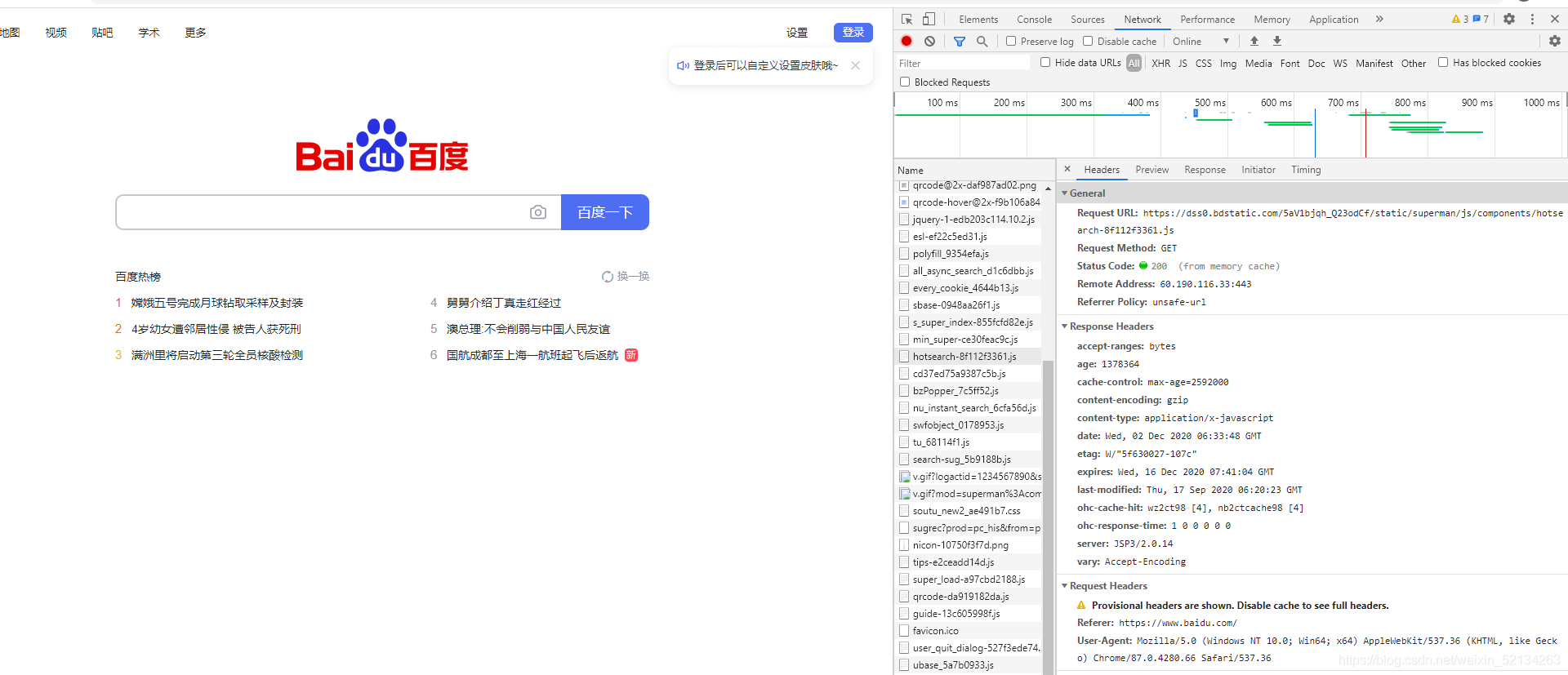
 ②獲取html檔案
②獲取html檔案
首先,我們使用requests.get(url,params=headers)方法來獲取目標html的資訊,值得一提的是狀態碼,如果我們能正常訪問網站的話,那么狀態碼即為200,如常見的404、405等即為不正確訪問,
如果狀態碼為200時,我們就會獲取目標html檔案,
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.68 Safari/538.36'}
response=requests.get(url,params=headers)
if response.status_code==200:
print("狀態碼成功")
if "驗證" in response.text:
print("被驗證")
return None
else:
return response.text
else:
print("狀態碼失敗"+str(response.status_code))
一般很多網站都會有反爬機制,在短時間內多次訪問很有可能會被拒之門外,你獲取的html檔案則會是一堆無用的代碼,所以可以使用上述代碼來確定我們得到的代碼是否被驗證,是否為目標代碼,值得注意的是,訪問方式methods如果服務器指定只可以POST訪問,則我們會獲得405狀態碼,所以在這之前,我們需要知道網站的訪問方式,根據methods來確定訪問方式,
③決議html
pyhton的第三方庫是非常強大的,如urllib、requests、re正則運算式用來獲得html,如Beautiful Soup、XPath、pyquery等用來決議html,
def parse_html(html,name):
soup=BeautifulSoup(html,'lxml')
results=soup.select(name)
with open('黃圖地址.txt','w') as f:
for result in results:
print(result['src'])
f.write(result['src']+'\n')
將BeautifulSoup(html,‘lxml’)實體化,然后使用soup.select()篩選器來獲得我們想要的東西,熟練掌握html/css/javascript的,可以非常熟練的使用pyquery來篩選,一般常用的的格式如下:
Beautiful:
find_all(name,attrs,recursive,text,**kwargs)
XPath:
html.xpath(’//x/x’)
pyquery:
doc=pq(url)
doc(‘goal’)
re:
re.findall(‘goal’,html,…)
④保存目標資源
我們已經決議了html代碼,那么就可以獲得想要得到的資源,如圖片,視頻,鏈接等,如果資源太多的話,我們可以將獲得的資源保存到資料庫中,
此實體中,我們獲取的是一大堆鏈接,打開鏈接,我么就可以看到圖片,如果想要直接獲取照片的話,我們可以利用以下代碼來完成:
with open('黃圖地址.txt','r')as f:
readlines=f.readlines()
lens=len(readlines)
print(lens)
for i in range(lens):
url=readlines[i].rstrip()
print(url)
filename=str(i+1)+'.jpg'
with open(filename,'wb')as f1:
print("正在下載{}".format(i+1))
f1.write(requests.get(url).content)
print("下載完成")
接下來你就可以在所在檔案的目錄里看到照片一張接著一張被下載下來,再次就不再展示美圖了,
完整代碼:
import re
from bs4 import BeautifulSoup
import requests
def get_html(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.68 Safari/538.36'}
response=requests.get(url,params=headers)
if response.status_code==200:
print("狀態碼成功")
if "驗證" in response.text:
print("被驗證")
return None
else:
return response.text
else:
print("狀態碼失敗"+str(response.status_code))
def parse_html(html,name):
soup=BeautifulSoup(html,'lxml')
results=soup.select(name)
with open('黃圖地址.txt','w') as f:
for result in results:
print(result['src'])
f.write(result['src']+'\n')
url='https://www.16df.xyz/pic/5/2020-01-10/25477.html'
html=get_html(url)
if html==None:
print('none')
pass
else:
parse_html(html,name='img')
with open('黃圖地址.txt','r')as f:
readlines=f.readlines()
lens=len(readlines)
print(lens)
for i in range(lens):
url=readlines[i].rstrip()
print(url)
filename=str(i+1)+'.jpg'
with open(filename,'wb')as f1:
print("正在下載{}".format(i+1))
f1.write(requests.get(url).content)
print("下載完成")
**Thanks**
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/229867.html
標籤:python