前言
先說一下自己的個人情況,18屆應屆生,通過校招進入到了蘑菇街,然后一待就待了差不多2年多的時間,可惜的是今年4月份受疫情影響遇到了大裁員,而我也是其中一員,好在早有預感,提前做了準備,之前一直想去位元組跳動,年前就已經在做準備了,這場持久戰拉得很長,也最終以7個月的時間取得勝利,在踏入位元組跳動,辦理入職手續的那一天,作為一個男子漢,確實是落淚了,特分享一波我的真實經歷,共勉,
小tip:
其實一個公司要進行裁員通常都會出現一些前期征兆:業務發展遇到較大瓶頸,并且難以突破、頻繁調整戰略目標、高管開始陸續離職、開始嚴抓考勤、開始部分同事勸退,如果你現在的公司也開始出現這些癥狀,別想了,是時候開始做準備了,
以下內容涉及4大環節:
- 環節一:制定計劃,做足準備
- 環節二:實施計劃,準備實戰
- 環節三:制定簡歷,投遞簡歷
- 環節四:位元組跳動面試經歷,真實記錄還原
四個環節中,內容中包含了很多檔案資料,由于文章篇幅有限,全整理在檔案內,包括Java學習資料、學習筆記、演算法寶典、面試題合集、思維導圖(Xmind)等,需要這些資料的朋友可【見下圖后】免費獲取
環節一:制定計劃,做足準備
1.梳理知識體系
現在大部分的程式員的現狀都特別奇怪,自己所掌握的知識是比較零散的,或者對某個知識點只知其表不知其里,其實這都是對自己掌握的技術內容沒有進行一個系統的梳理,所以制定計劃的第一步就是要梳理好自己的知識體系,關于梳理知識體系,要做到以下2點:
- 你是否了解這個知識點的why、where、how
- 你能否能將這些概念和知識能簡單通俗易懂的講給另一個完全不理解的人聽懂
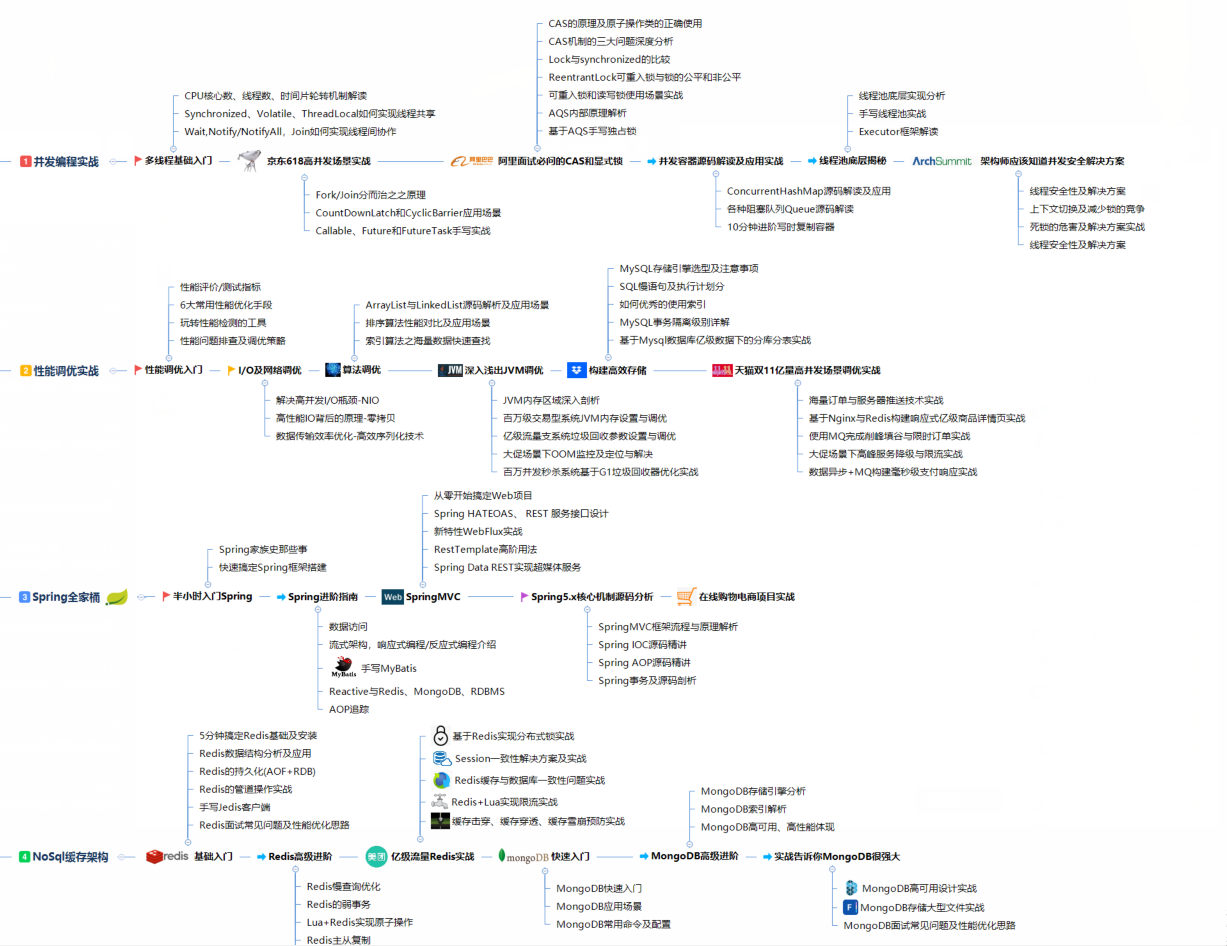
系統知識圖
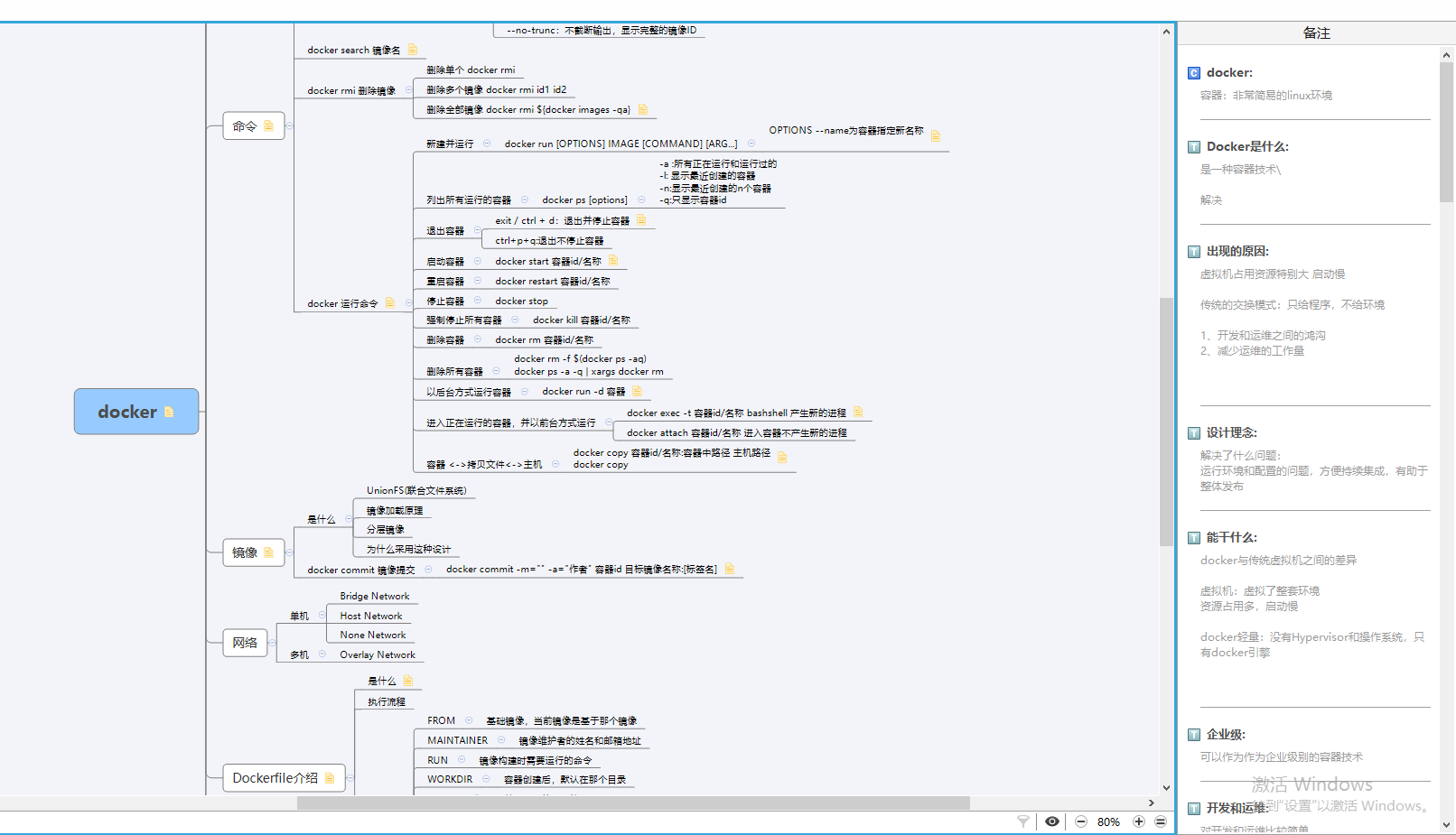
Docker思維圖(xmid)
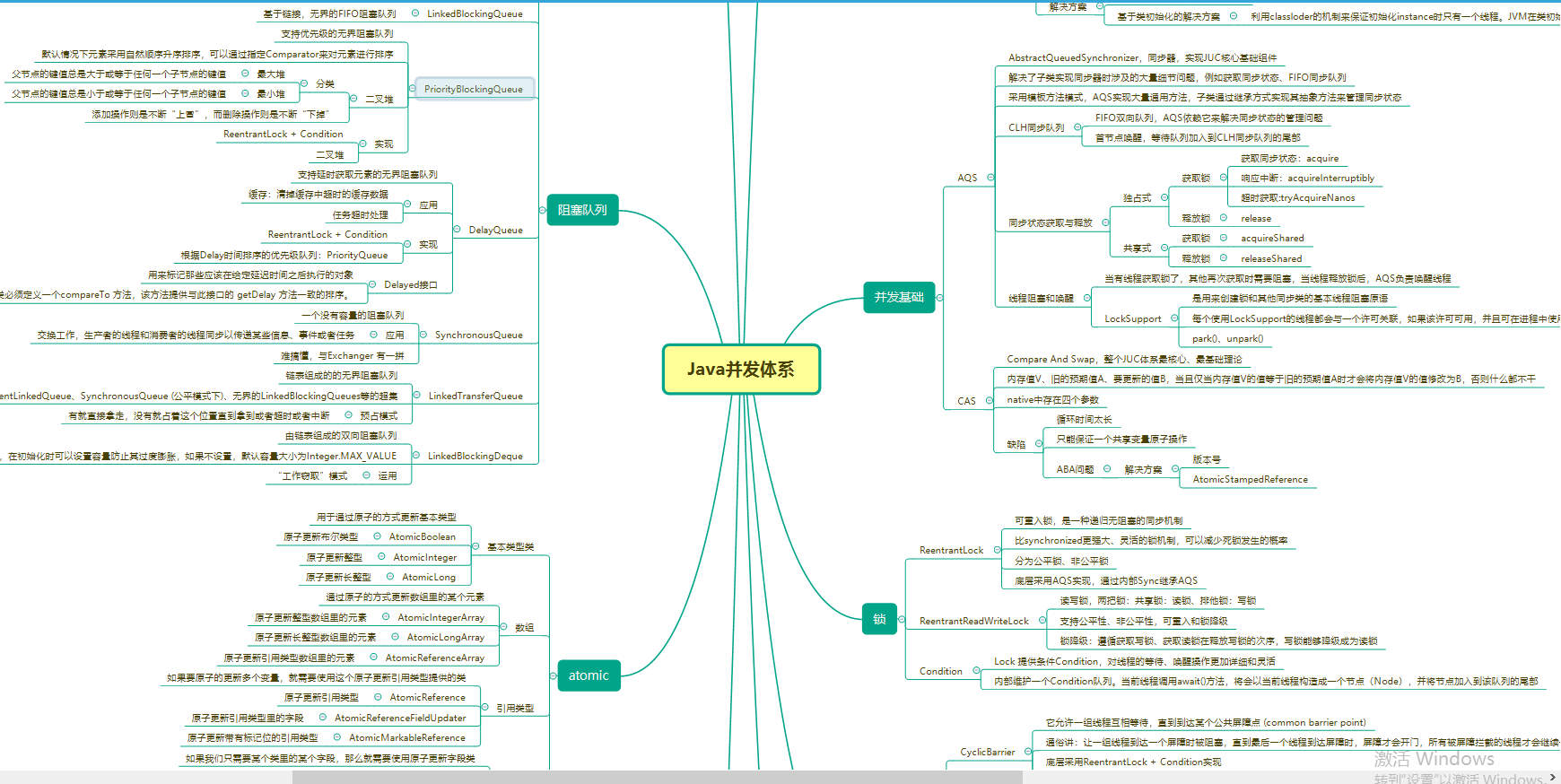
Java并發體系圖(xmind)
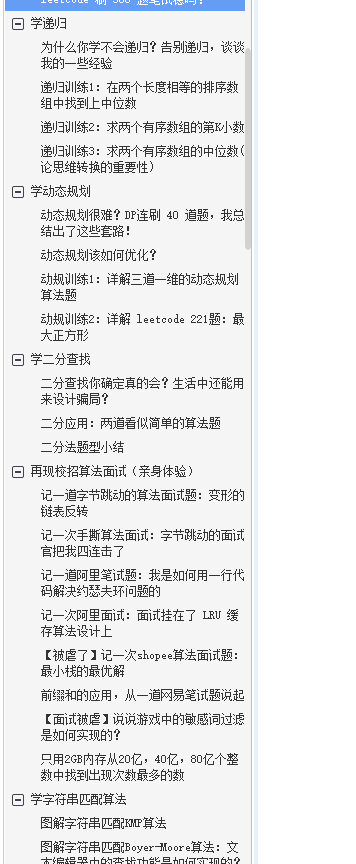
2.準備演算法
- 該如何學習演算法?
- 程式員必須掌握的演算法有哪些?
- Leetcode刷題,到底穩嗎?
關于演算法部分,其實要準備的細節內容非常多,所以我也花了不少心思整理了一份關于演算法方面的寶典,這份資料我對演算法的認識以及我的學習方法,除了Leetcode以外,位元組跳動喜歡問的核心演算法題也進行一道一道的深度決議,
3.收集整理面試題
除了演算法部分以外,要想在實際面試中做到心中有數,大廠的常問的一些面試題或知識點也很有必要看一看,我特意搜集整理了近3年來一線互聯網公司的面試題(技術部分),會發現這些面試題實際問的大同小異,但考察你的內容和技術都是有不同的目的性的,對這一部分的分析,我也有寫在答案里(詳細見檔案),
環節二:實施計劃,準備實戰
前期準備的這些需要一步一步行動起來了,但除了以上肯定是遠遠不夠的,面試官除了技術相關的問題,必問的就是專案相關的內容,那專案相關內容需要怎么來準備呢?除了自己的實戰經驗的積累以外,其實我們還是可以閱讀一些技術大牛寫出來的實戰經驗及筆記,如:Redis筆記、SpringBoot技術筆記等,
Redis筆記
SpringBoot技術筆記
環節三:制定簡歷,投遞簡歷
簡歷對于程式員來說是非常重要的一個環節,一份優秀的簡歷往往能夠幫助我們敲開一線互聯網大廠的大門,簡歷部分我就不做過多的贅述,可以參考《程式員找作業指南》,另外我可以提供18種優秀的簡歷模板,
下載好之后,根據模板來制定自己的簡歷,接下來就可以順利投遞啦!投遞簡歷一定要參考好匹配值,建議最好找熟人內推,
簡歷范本
環節四:位元組跳動面試經歷,真實記錄還原
位元組跳動一面:
第一面我覺得應該是基礎面,重點考察的是自己技術的廣度 和一些技術的掌握情況,一面小哥哥也沒有深究于某個特定的點,面試時間大約1個小時,
- 自我介紹
- 怎么打算投遞后臺崗位的,沒有考慮契合自己研究方向的作業?
- 有了解過OAuth2.0么,說說你對OAuth2.0的理解
- 蘑菇博客開發程序中,有了解或學習其它的開源框架嗎?
- 蘑菇博客文章發布的流程是怎么樣的,是多人博客系統嗎?
- 對其它的一些博客框架有了解嗎?比如hexo
- hexo和蘑菇博客相比有什么區別呢?蘑菇博客多了哪些功能和優勢?
- 看你蘑菇博客用到了RabbitMQ,那談談為什么引入RabbitMQ?
- RabbitMQ和其它訊息佇列,比如ActiveMQ,RocketMQ,Kafka有什么區別?
- Redis在你博客專案中的使用,為什么引入Redis?
- Redis中存盤的是熱門文章,是通過什么來得到的?這樣做會有什么問題么?
- 有聽過長尾效應么?你通過推薦欄位設定的推薦等級,這樣會讓這些文章一直保持在較高的點擊量,而且熱度和點擊量也不會隨著時間而降低,有什么解決方案么?
- 我看到你有用到JustAuth這個登錄授權?說說它會存在賬號泄漏的問題么?
- 下面談談Redis,它會存在執行緒切換的問題么?
- 談談Redis單執行緒模型和IO多路復用
- Redis的大Key的問題,如果有個Value的大小是2M,會有什么問題么?最大支持的Value大小是多少?
- 談談Redis集群 Redis Cluster,以及主從復制原理?
- 說說Redis中的哨兵,即Redis Sentinel
- 下面來聊聊Linux,你知道Linux怎么查看當前的負載情況么?
- 你還知道其它的一些Linux命令么?
- cat、tail、vi、vim命令的區別,分別說一說?
- 如果Linux下需要打開或者查看大檔案,你會怎么做?
- 下面聊聊Http Code,你知道 3XX 狀態碼 對應的是什么?
- 談談你知道的其它一些狀態碼,4XX 和 5XX?
- 演算法題:
(1)# 給定一些陣列,例如下面的格式,他們都表示一個區間,然后你需要將區間進行合并
[1,2],[2,4],[3,7],[8,11]
# 如上所示, [1,2] 和 [2,4] = [1,4]
# 然后 [1,4] 和 [3,7] = [1,7]
# 最后 [1,7] 和 [8,11] 無法合并,所以最后結果應該回傳 [1,7],[8,11]
(2)# 給定一個陣列,例如 [1,1,2,2,2,3,3,3,3]這樣的,里面的陣列不一定連續并且有序,假設我輸入 2,這個2表示出現次數最高的兩個
# 那么你需要給我回傳 2,3
位元組跳動二面:
- 自我介紹
- 博客已經開源了么,用的什么開源協議,博客的用戶多么?
- 看你博客中用到了Solr和ElasticSearch,談談它們的原理,以及倒排索引?
- 對于Solr或者ES里面用到的一些中文分詞器有了解過么?
- 談談那些技術堆疊,你比較熟悉的是那些,mysql 和redis?
- 聊聊MySQL的底層索引結構,InnoDB里面的B+Tree?
- B Tree 和 B+ Tree的區別
- 聊聊MySQL索引的發展程序?是一來就是B+Tree的么?從 沒有索引、hash、二叉排序樹、AVL樹、B樹、B+樹 聊,
- 談談MySQL里面的事務,說說什么是事務?
- MySQL里面有哪些事務級別,并且不同的事務級別會出現什么問題?
- 談談可重復讀和幻讀的區別?
- MySQL中如果使用like進行模糊匹配的時候,是否會使用索引?一定不會用么?
- 談談Redis吧,在你專案中的具體使用?
- 談談Redis如何實作分布式鎖?
- 蘑菇博客是否存在快取不一致的情況,你是如何解決的?
- 談談Redis中快取穿透的問題,以及解決的方法?
- 還有其它解決快取穿透的方法么?布隆過濾器有了解過么?
- Redis中大面積的快取失效,然后請求全部打到資料庫,有什么解決方法?
- 如果出現一些熱點資料,比如明星之間的新聞,造成大量的吃瓜用戶涌入后臺,但是服務器還沒有快取對應的資料,這樣可能造成資料庫宕機,如何避免這樣的情況?
- 聊聊 JVM的組成結構?
- 談談垃圾收集原理?以及垃圾收集演算法
- 復制演算法 和 標記整理演算法?
- 為什么不在新生代使用標記整理演算法?或者在老年代使用復制演算法?
- 有了解過Volatile么?談談你對Volatile的理解
- Volatile如何保證可見性的?以及如何實作可見性的機制,
- 如果大量的使用Volatile存在什么問題?
- 談談作業系統的執行緒,以及它的狀態
- 執行緒和行程的區別?
- 為什么提出多執行緒應用,而不是多行程應用呢?
- Linux你平時都有用到什么命令呢?
- 如果我需要查看埠號或者行程號,你會使用什么命令?
- 談談你做的另外一個專案吧?稍微介紹一下
- 來吧,寫個題目試試
# 鏈表的兩兩翻轉 # 給定鏈表: 1->2->3->4->5->6->7 # 回傳結果: 2->1->4->3->6->5->7
位元組跳動第三面:
- 自我介紹
- 好奇一下,用碼/云的人應該不多吧,為什么沒有用Github?
- 你英文水平怎么樣?
- 聊聊開源專案吧?我看這專案已經有800多贊了,你在這開源專案主要做了什么作業?
- 我們找些點來聊聊吧?先從ES和Solr開始,你們這兩個都有在用么?
- SQL的方式實作搜索,你是怎么做的呢?
- 使用like匹配的時候,會不會查詢非常慢呢?
- ES和Solr的底層都用了lunce,談談你對lunce的理解?
- lunce里面也有用到分詞器,比如一些新的詞 “新冠肺炎” ,它能不能做到很好的劃分呢?
- 除了人為的維護詞庫,來解決最新詞語的分割,你還有知道其它什么更好的方法么?
- 你有了解過其它什么開源的分詞庫么?
- 談談字典樹?
- Solr 和 ES底層都用了Lunce,那他們兩者有什么區別呢?
- Solr所謂的集群環境 和 ES所謂的分布式環境,它們之間有什么區別呢?
- 上面你有提到微服務,你有了解過微服務是個什么樣的理念么?
- 你現在的微服務,也是打包成多個jar包,部署在一個服務器上,如果服務器出現問題了,也會造成服務不可用,有沒有好的解決方法呢?
- 聊聊服務的注冊與發現?
- 服務的注冊和發現,其實依賴于一個注冊中心的概念,會不會出現注冊中心掛掉,而導致整個服務不可用,有沒有什么好的解決方法呢?
- 有了解過Zookeeper整個的選舉程序么?
- 談談Zookeeper的分布式一致性協議?
- 聊聊索引,我給你寫個表,看看下面的查詢陳述句,走了那些索引?
create table 'tb' (
id int,
name varchar(64),
status int,
createtime timestamp,
PRIMARY KEY (`id`)
)
-- 創建了三個普通索引
create index index_name on table('name')
create index index_status on table('status')
create index index_createtime on table('createtime')
-- 給定SQL陳述句,判斷下面查詢會用到幾個索引
select * from tb where status = 1 and name = "zhangsan"
- 上述SQL用到了幾個索引?分別是那幾個?
- 有了解過InnoDB底層的索引結構么?
- 通過兩個索引查詢出來的結果,會進行什么樣的操作?交集,并集?
- 如果你在MySQL中遇到一些慢查詢,有什么解決方法么?
- 談談explain?執行的explain后,出現的那些欄位,能夠幫助我們呢?
- 我看你的博客里面,關于Redis還有好幾篇文章,我們可以聊一聊你對Redis的理解?
- 為什么Redis能夠保持這么高的并發回應?
- 有了解過IO多路復用技術是個什么樣的原理
- 通過一個執行緒,同時連接多個執行緒不會存在多個執行緒切換么?(感覺進坑了,,)
- 當你通過jedis進行連接redis的時候,已經和一個行程連接了 ,redis還能夠和其它的行程進行通信么?
- Redis每秒能夠處理處理十萬請求,如果按照你上面說的,那說明它每次互動只在 1/十萬 秒內完成?
- 有了解過Redis的原始碼么?
- MySQL用了B+Tree,Redis中的SortSet內部用了跳躍表,他們之間有什么差別?為什么MySQL不用跳躍表,或者是Redis不用B+Tree呢?
- 感覺自己編碼功底怎么樣?那我們先聊聊作業系統的知識再給你一道題吧,在作業系統中,有高速快取,主存,虛擬記憶體,外存,知道它們之間有什么樣的關系,以及它們的作用是啥?
- 對它們來說,肯定會存在一個問題,就是當我們的主存滿了,或者虛存滿了,那么需要存在一個換頁操作,你知道有那些換頁演算法么?
- 我們來聊聊LRU?叫你手寫一個LRU演算法談談你的思路?
- 用鏈表的方式實作,時間復雜度是O(N),有沒有什么方式能夠讓它是O(1)的時間復雜度呢?
- OK,思路還可以,那你手寫一個LRU演算法吧?(雙向鏈表 + Hash?)
位元組跳動面試題答案:
以上三輪面試的技術題的詳細答案與決議均整理在檔案內,由于決議文字過多,不在文章中分享,需要這份面試題答案可以私信我,
總結
這次能夠順利入職位元組跳動,可以說是運氣和實力參半,但我一直持有的一個觀念就是:好運永遠是留給有準備的人,
所以,作為一名技術人,對大廠有著執念,那就要落實下來,相信自己付出是會有所回報的,在這,我也祝大家在接下來的金九銀十里,面試順利,過關斬將,拿下offer,
以上文章里寫到的所有檔案資料,均免費分享,有需要的
一鍵三連之后【見下圖】,即可免費領取









轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230161.html
標籤:Java
上一篇:Redis低成本高可用方案設計