在互聯網后端日常開發介面的時候中,不管你使用的是C、Java、PHP還是Golang,都避免不了需要呼叫mysql、redis等組件來獲取資料,可能還需要執行一些rpc遠程呼叫,或者再呼叫一些其它restful api, 在這些呼叫的底層,基本都是在使用TCP協議進行傳輸,這是因為在傳輸層協議中,TCP協議具備可靠的連接,錯誤重傳,擁塞控制等優點,所以目前應用比UDP更廣泛一些,
相信你也一定聽聞過TCP也存在一些缺點,那就是老生常談的開銷要略大,但是各路技術博客里都在單單說開銷大、或者開銷小,而少見不給出具體的量化分析,不客氣一點,這都是營養不大的廢話,經過日常作業的思考之后,我更想弄明白的是,開銷到底多大,一條TCP連接的建立需要耗時延遲多少,是多少毫秒,還是多少微秒?能不能有一個哪怕是粗略的量化估計?當然影響TCP耗時的因素有很多,比如網路丟包等等,我今天只分享我在作業實踐中遇到的比較高發的各種情況,
正常TCP連接建立程序
要想搞清楚TCP連接的建立耗時,我們需要詳細了解連接的建立程序,在前文《圖解Linux網路包接收程序》中我們介紹了資料包在接收端是怎么被接收的,資料包從發送方出來,經過網路到達接收方的網卡,在接收方網卡將資料包DMA到RingBuffer后,內核經過硬中斷、軟中斷等機制來處理(如果發送的是用戶資料的話,最后會發送到socket的接收佇列中,并喚醒用戶行程),
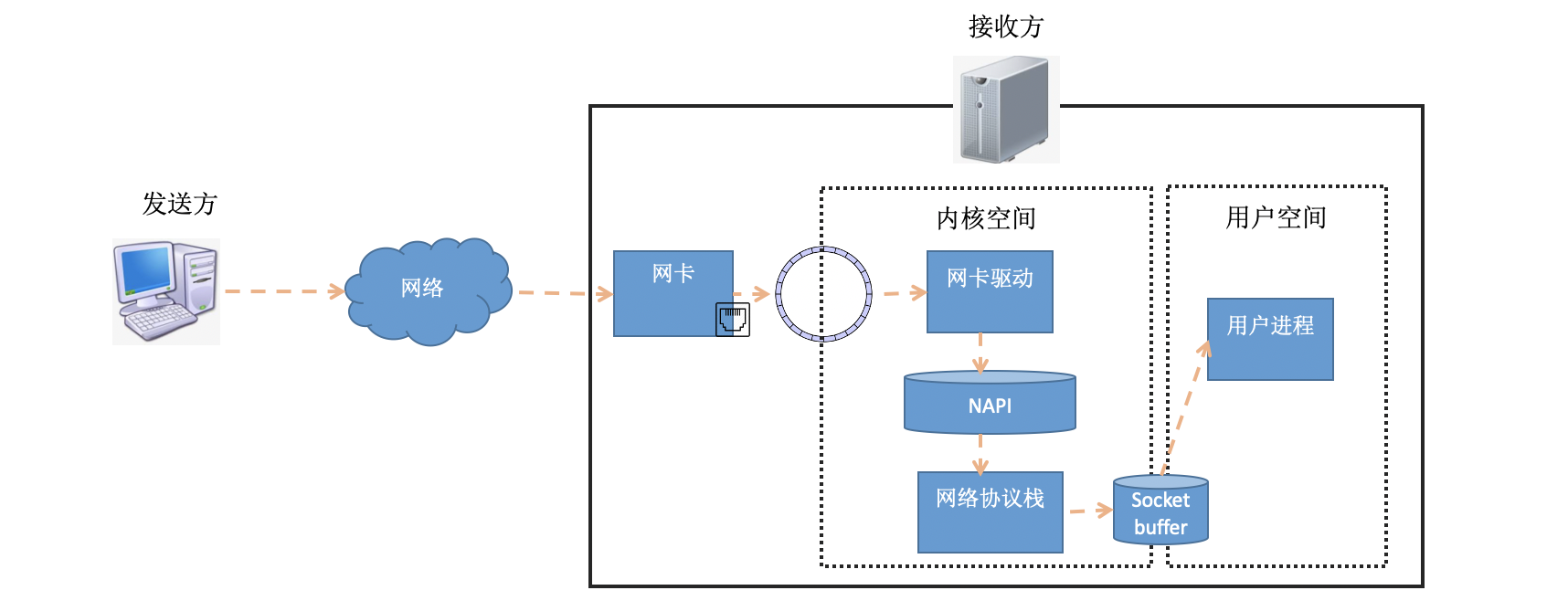
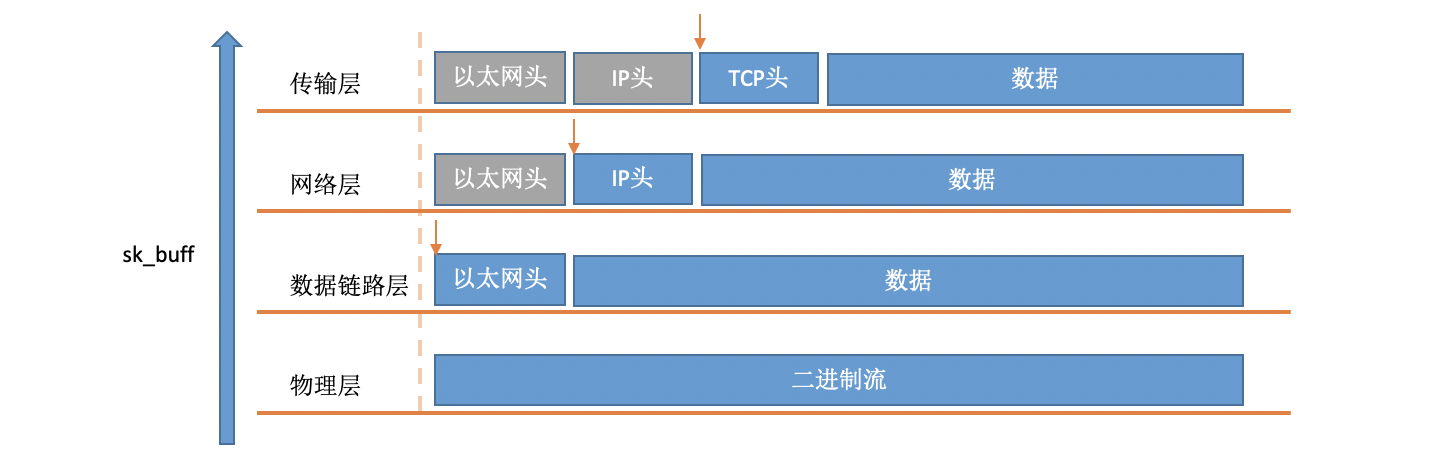
在軟中斷中,當一個包被內核從RingBuffer中摘下來的時候,在內核中是用struct sk_buff結構體來表示的(參見內核代碼include/linux/skbuff.h),其中的data成員是接收到的資料,在協議堆疊逐層被處理的時候,通過修改指標指向data的不同位置,來找到每一層協議關心的資料,
對于TCP協議包來說,它的Header中有一個重要的欄位-flags,如下圖:
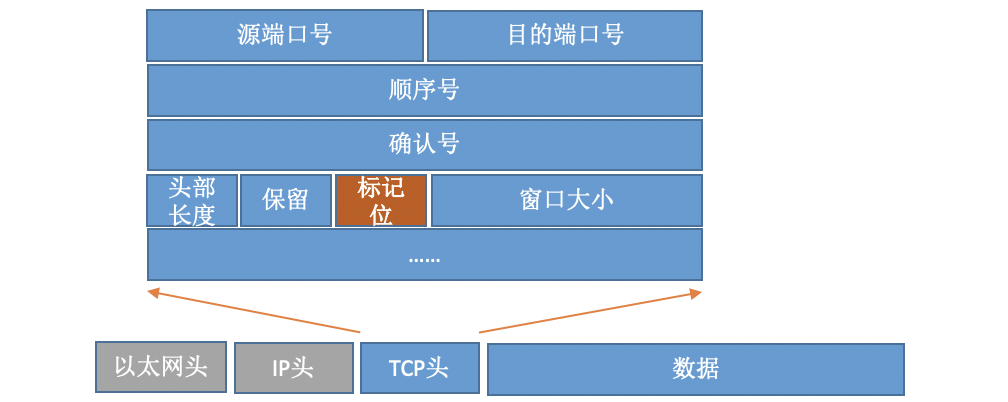
通過設定不同的標記為,將TCP包分成SYNC、FIN、ACK、RST等型別,客戶端通過connect系統呼叫命令內核發出SYNC、ACK等包來實作和服務器TCP連接的建立,在服務器端,可能會接收許許多多的連接請求,內核還需要借助一些輔助資料結構-半連接佇列和全連接佇列,我們來看一下整個連接程序:
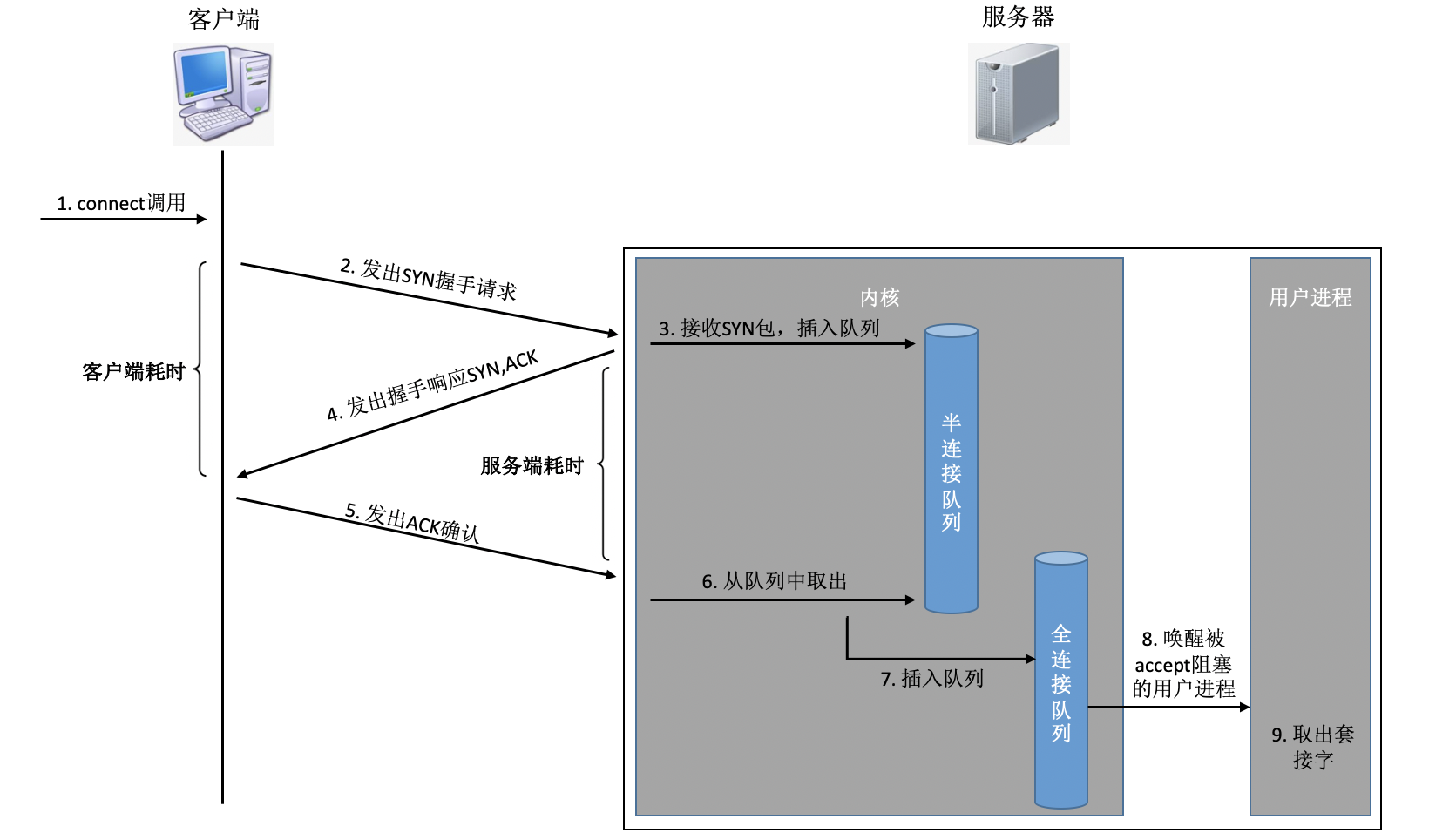
在這個連接程序中,我們來簡單分析一下每一步的耗時
- 客戶端發出SYNC包:客戶端一般是通過connect系統呼叫來發出SYN的,這里牽涉到本機的系統呼叫和軟中斷的CPU耗時開銷
- SYN傳到服務器:SYN從客戶端網卡被發出,開始“跨過山和大海,也穿過人山人海......”,這是一次長途遠距離的網路傳輸
- 服務器處理SYN包:內核通過軟中斷來收包,然后放到半連接佇列中,然后再發出SYN/ACK回應,又是CPU耗時開銷
- SYC/ACK傳到客戶端:SYC/ACK從服務器端被發出后,同樣跨過很多山、可能很多大海來到客戶端,又一次長途網路跋涉
- 客戶端處理SYN/ACK:客戶端內核收包并處理SYN后,經過幾us的CPU處理,接著發出ACK,同樣是軟中斷處理開銷
- ACK傳到服務器:和SYN包,一樣,再經過幾乎同樣遠的路,傳輸一遍, 又一次長途網路跋涉
- 服務端收到ACK:服務器端內核收到并處理ACK,然后把對應的連接從半連接佇列中取出來,然后放到全連接佇列中,一次軟中斷CPU開銷
- 服務器端用戶行程喚醒:正在被accpet系統呼叫阻塞的用戶行程被喚醒,然后從全連接佇列中取出來已經建立好的連接,一次背景關系切換的CPU開銷
以上幾步操作,可以簡單劃分為兩類:
- 第一類是內核消耗CPU進行接收、發送或者是處理,包括系統呼叫、軟中斷和背景關系切換,它們的耗時基本都是幾個us左右,具體的分析程序可以參見《一次系統呼叫開銷到底有多大?》、《軟中斷會吃掉你多少CPU?》、《行程/執行緒背景關系切換會用掉你多少CPU?》這三篇文章,
- 第二類是網路傳輸,當包被從一臺機器上發出以后,中間要經過各式各樣的網線、各種交換機路由器,所以網路傳輸的耗時相比本機的CPU處理,就要高的多了,根據網路遠近一般在幾ms~到幾百ms不等,,
1ms就等于1000us,因此網路傳輸耗時比雙端的CPU開銷要高1000倍左右,甚至更高可能還到100000倍,所以,在正常的TCP連接的建立程序中,一般可以考慮網路延時即可,一個RTT指的是包從一臺服務器到另外一臺服務器的一個來回的延遲時間,所以從全域來看,TCP連接建立的網路耗時大約需要三次傳輸,再加上少許的雙方CPU開銷,總共大約比1.5倍RTT大一點點,不過從客戶端視角來看,只要ACK包發出了,內核就認為連接是建立成功了,所以如果在客戶端打點統計TCP連接建立耗時的話,只需要兩次傳輸耗時-既1個RTT多一點的時間,(對于服務器端視角來看同理,從SYN包收到開始算,到收到ACK,中間也是一次RTT耗時)
TCP鏈接建立時的例外情況
上一節可以看到在客戶端視角,,在正常情況下一次TCP連接總的耗時也就就大約是一次網路RTT的耗時,如果所有的事情都這么簡單,我想我的這次分享也就沒有必要了,事情不一定總是這么美好,總會有意外發生,在某些情況下,可能會導致連接時的網路傳輸耗時上漲、CPU處理開銷增加、甚至是連接失敗,現在我們說一下我在線上遇到過的各種溝溝坎坎,
1)客戶端connect系統呼叫耗時失控
正常一個系統呼叫的耗時也就是幾個us(微秒)左右,但是在《追蹤將服務器CPU耗光的兇手!》一文中筆者的一臺服務器當時遇到一個狀況,某次運維同學轉達過來說該服務CPU不夠用了,需要擴容,當時的服務器監控如下圖:
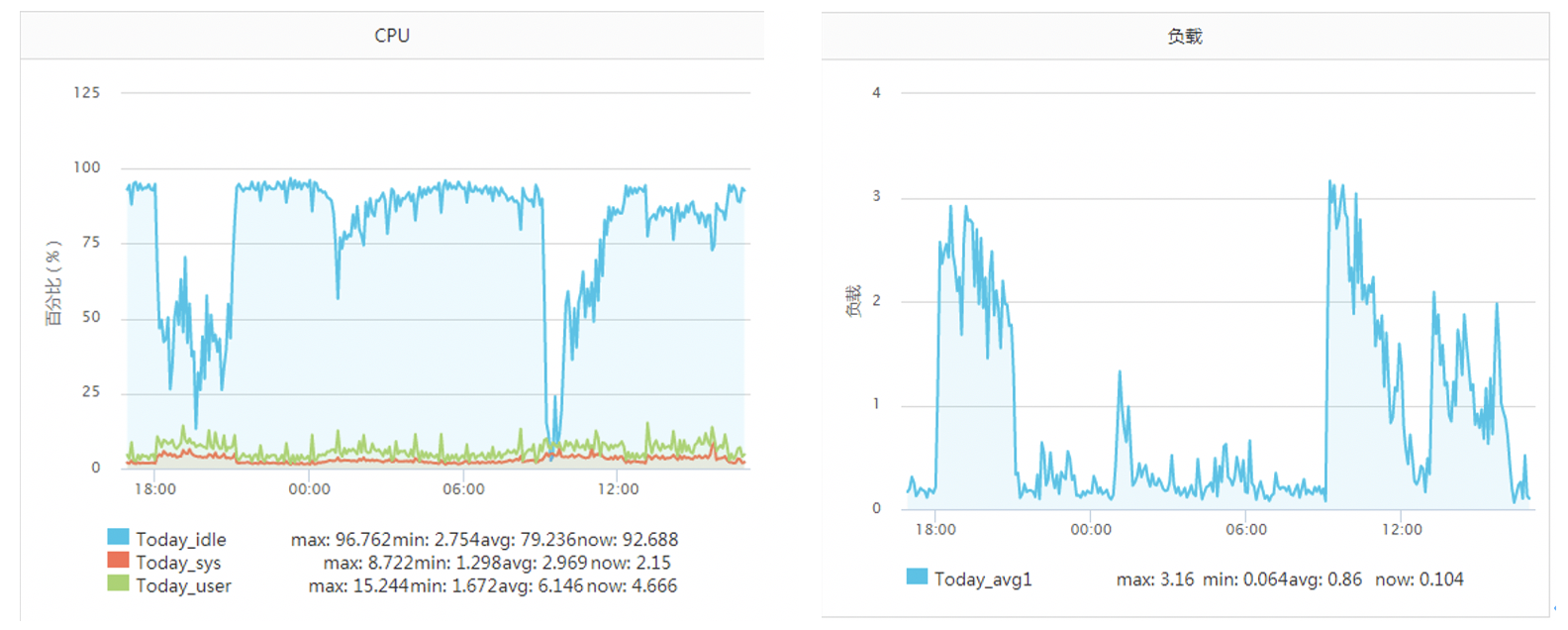
該服務之前一直每秒抗2000左右的qps,CPU的idel一直有70%+,怎么突然就CPU一下就不夠用了呢,而且更奇怪的是CPU被打到谷底的那一段時間,負載卻并不高(服務器為4核機器,負載3-4是比較正常的), 后來經過排查以后發現當TCP客戶端TIME_WAIT有30000左右,導致可用埠不是特別充足的時候,connect系統呼叫的CPU開銷直接上漲了100多倍,每次耗時達到了2500us(微秒),達到了毫秒級別,
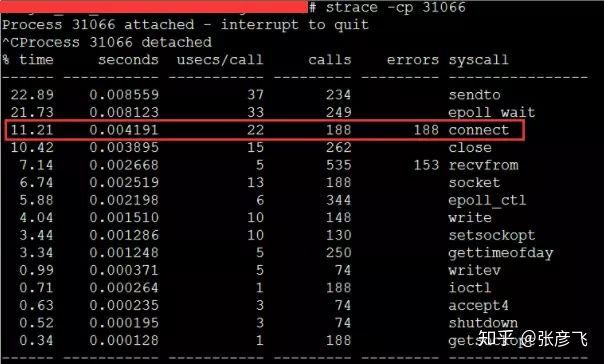
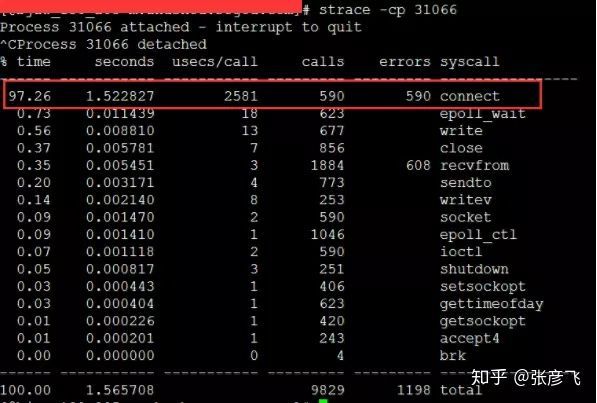
當遇到這種問題的時候,雖然TCP連接建立耗時只增加了2ms左右,整體TCP連接耗時看起來還可接受,但是這里的問題在于這2ms多都是在消耗CPU的周期,所以問題不小,
解決起來也非常簡單,辦法很多:修改內核引數net.ipv4.ip_local_port_range多預留一些埠號、改用長連接都可以,
2)半/全連接佇列滿
如果連接建立的程序中,任意一個佇列滿了,那么客戶端發送過來的syn或者ack就會被丟棄,客戶端等待很長一段時間無果后,然后會發出TCP Retransmission重傳,拿半連接佇列舉例:
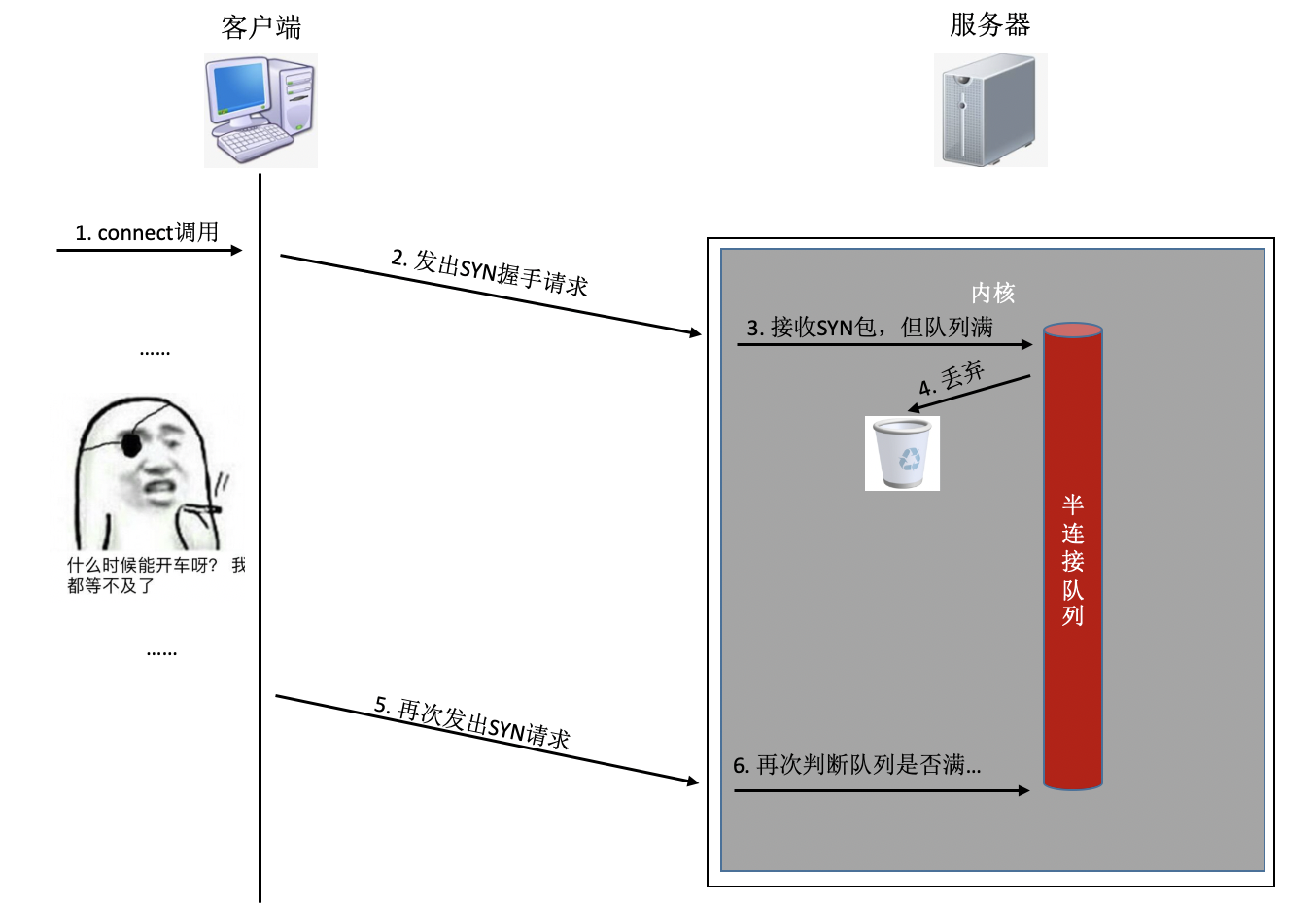
要知道的是上面TCP握手超時重傳的時間是秒級別的,也就是說一旦server端的連接佇列導致連接建立不成功,那么光建立連接就至少需要秒級以上,而正常的在同機房的情況下只是不到1毫秒的事情,整整高了1000倍左右,尤其是對于給用戶提供實時服務的程式來說,用戶體驗將會受到較大影響,如果連重傳也沒有握手成功的話,很可能等不及二次重試,這個用戶訪問直接就超時了,
還有另外一個更壞的情況是,它還有可能會影響其它的用戶,假如你使用的是行程/執行緒池這種模型提供服務,比如php-fpm,我們知道fpm行程是阻塞的,當它回應一個用戶請求的時候,該行程是沒有辦法再回應其它請求的,假如你開了100個行程/執行緒,而某一段時間內有50個行程/執行緒卡在和redis或者mysql服務器的握手連接上了(注意:這個時候你的服務器是TCP連接的客戶端一方),這一段時間內相當于你可以用的正常作業的行程/執行緒只有50個了,而這個50個worker可能根本處理不過來,這時候你的服務可能就會產生擁堵,再持續稍微時間長一點的話,可能就產生雪崩了,整個服務都有可能會受影響,
既然后果有可能這么嚴重,那么我們如何查看我們手頭的服務是否有因為半/全連接佇列滿的情況發生呢?在客戶端,可以抓包查看是否有SYN的TCP Retransmission,如果有偶發的TCP Retransmission,那就說明對應的服務端連接佇列可能有問題了,
在服務端的話,查看起來就更方便一些了,netstat -s可查看到當前系統半連接佇列滿導致的丟包統計,但該數字記錄的是總丟包數,你需要再借助watch命令動態監控,如果下面的數字在你監控的程序中變了,那說明當前服務器有因為半連接佇列滿而產生的丟包,你可能需要加大你的半連接佇列的長度了,
$ watch 'netstat -s | grep LISTEN'
8 SYNs to LISTEN sockets ignored
對于全連接佇列來說呢,查看方法也類似,
$ watch 'netstat -s | grep overflowed'
160 times the listen queue of a socket overflowed
如果你的服務因為佇列滿產生丟包,其中一個做法就是加大半/全連接佇列的長度, 半連接佇列長度Linux內核中,主要受tcp_max_syn_backlog影響 加大它到一個合適的值就可以,
# cat /proc/sys/net/ipv4/tcp_max_syn_backlog
1024
# echo "2048" > /proc/sys/net/ipv4/tcp_max_syn_backlog
全連接佇列長度是應用程式呼叫listen時傳入的backlog以及內核引數net.core.somaxconn二者之中較小的那個,你可能需要同時調整你的應用程式和該內核引數,
# cat /proc/sys/net/core/somaxconn
128
# echo "256" > /proc/sys/net/core/somaxconn
改完之后我們可以通過ss命令輸出的Send-Q確認最終生效長度:
$ ss -nlt
Recv-Q Send-Q Local Address:Port Address:Port
0 128 *:80 *:*
Recv-Q告訴了我們當前該行程的全連接佇列使用長度情況,如果Recv-Q已經逼近了Send-Q,那么可能不需要等到丟包也應該準備加大你的全連接佇列了,
如果加大佇列后仍然有非常偶發的佇列溢位的話,我們可以暫且容忍,如果仍然有較長時間處理不過來怎么辦?另外一個做法就是直接報錯,不要讓客戶端超時等待,例如將Redis、Mysql等后端介面的內核引數tcp_abort_on_overflow為1,如果佇列滿了,直接發reset給client,告訴后端行程/執行緒不要癡情地傻等,這時候client會收到錯誤“connection reset by peer”,犧牲一個用戶的訪問請求,要比把整個站都搞崩了還是要強的,
連接耗時實測
我寫了一段非常簡單的代碼,用來在客戶端統計每創建一個TCP連接需要消耗多長時間,
<?php
$ip = {服務器ip};
$port = {服務器埠};
$count = 50000;
function buildConnect($ip,$port,$num){
for($i=0;$i<$num;$i++){
$socket = socket_create(AF_INET,SOCK_STREAM,SOL_TCP);
if($socket ==false) {
echo "$ip $port socket_create() 失敗的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
if(false == socket_connect($socket, $ip, $port)){
echo "$ip $port socket_connect() 失敗的原因是:".socket_strerror(socket_last_error($socket))."\n";
sleep(5);
continue;
}
socket_close($socket);
}
}
$t1 = microtime(true);
buildConnect($ip, $port, $count);
echo (($t2-$t1)*1000).'ms';
在測驗之前,我們需要本機linux可用的埠數充足,如果不夠50000個,最好調整充足,
# echo "5000 65000" /proc/sys/net/ipv4/ip_local_port_range
1)正常情況
注意:無論是客戶端還是服務器端都不要選擇有線上服務在跑的機器,否則你的測驗可能會影響正常用戶訪問
首先我的客戶端位于河北懷來的IDC機房內,服務器選擇的是公司廣東機房的某臺機器,執行ping命令得到的延遲大約是37ms,使用上述腳本建立50000次連接后,得到的連接平均耗時也是37ms,這是因為前面我們說過的,對于客戶端來看,第三次的握手只要包發送出去,就認為是握手成功了,所以只需要一次RTT、兩次傳輸耗時,雖然這中間還會有客戶端和服務端的系統呼叫開銷、軟中斷開銷,但由于它們的開銷正常情況下只有幾個us(微秒),所以對總的連接建立延時影響不大,
接下來我換了一臺目標服務器,該服務器所在機房位于北京,離懷來有一些距離,但是和廣東比起來可要近多了,這一次ping出來的RTT是1.6~1.7ms左右,在客戶端統計建立50000次連接后算出每條連接耗時是1.64ms,
再做一次實驗,這次選中實驗的服務器和客戶端直接位于同一個機房內,ping延遲在0.2ms~0.3ms左右,跑了以上腳本以后,實驗結果是50000 TCP連接總共消耗了11605ms,平均每次需要0.23ms,
線上架構提示:這里看到同機房延遲只有零點幾ms,但是跨個距離不遠的機房,光TCP握手耗時就漲了4倍,如果再要是跨地區到廣東,那就是百倍的耗時差距了,線上部署時,理想的方案是將自己服務依賴的各種mysql、redis等服務和自己部署在同一個地區、同一個機房(再變態一點,甚至可以是甚至是同一個機架),因為這樣包括TCP鏈接建立啥的各種網路包傳輸都要快很多,要盡可能避免長途跨地區機房的呼叫情況出現,
2)連接佇列溢位
測驗完了跨地區、跨機房和跨機器,這次為了快,直接和本機建立連接結果會咋樣呢?
Ping本機ip或127.0.0.1的延遲大概是0.02ms,本機ip比其它機器RTT肯定要短,我覺得肯定連接會非常快,嗯實驗一下,連續建立5W TCP連接,總時間消耗27154ms,平均每次需要0.54ms左右,嗯!?怎么比跨機器還長很多?
有了前面的理論基礎,我們應該想到了,由于本機RTT太短,所以瞬間連接建立請求量很大,就會導致全連接佇列或者半連接佇列被打滿的情況,一旦發生佇列滿,當時撞上的那個連接請求就得需要3秒+的連接建立延時,所以上面的實驗結果中,平均耗時看起來比RTT高很多,
在實驗的程序中,我使用tcpdump抓包看到了下面的一幕,原來有少部分握手耗時3s+,原因是半連接佇列滿了導致客戶端等待超時后進行了SYN的重傳,

我們又重新改成每500個連接,sleep 1秒,嗯好,終于沒有卡的了(或者也可以加大連接佇列長度),結論是本機50000次TCP連接在客戶端統計總耗時102399 ms,減去sleep的100秒后,平均每個TCP連接消耗0.048ms,比ping延遲略高一些,這是因為當RTT變的足夠小的時候,內核CPU耗時開銷就會顯現出來了,另外TCP連接要比ping的icmp協議更復雜一些,所以比ping延遲略高0.02ms左右比較正常,
結論
TCP連接建立例外情況下,可能需要好幾秒,一個壞處就是會影響用戶體驗,甚至導致當前用戶訪問超時都有可能,另外一個壞處是可能會誘發雪崩,所以當你的服務器使用短連接的方式訪問資料的時候,一定要學會要監控你的服務器的連接建立是否有例外狀態發生,如果有,學會優化掉它,當然你也可以采用本機記憶體快取,或者使用連接池來保持長連接,通過這兩種方式直接避免掉TCP握手揮手的各種開銷也可以,
再說正常情況下,TCP建立的延時大約就是兩臺機器之間的一個RTT耗時,這是避免不了的,但是你可以控制兩臺機器之間的物理距離來降低這個RTT,比如把你要訪問的redis盡可能地部署的離后端介面機器近一點,這樣RTT也能從幾十ms削減到最低可能零點幾ms,
最后我們再思考一下,如果我們把服務器部署在北京,給紐約的用戶訪問可行嗎?
前面的我們同機房也好,跨機房也好,電信號傳輸的耗時基本可以忽略(因為物理距離很近),網路延遲基本上是轉發設備占用的耗時,但是如果是跨越了半個地球的話,電信號的傳輸耗時我們可得算一算了,
北京到紐約的球面距離大概是15000公里,那么拋開設備轉發延遲,僅僅光速傳播一個來回(RTT是Rround trip time,要跑兩次),需要時間 = 15,000,000 *2 / 光速 = 100ms,實際的延遲可能比這個還要大一些,一般都得200ms以上,建立在這個延遲上,要想提供用戶能訪問的秒級服務就很困難了,所以對于海外用戶,最好都要在當地建機房或者購買海外的服務器,

相關閱讀:
- 1.圖解Linux網路包接收程序
- 2.Linux網路包接收程序的監控與調優
- 3.行程/執行緒切換究竟需要多少開銷?
- 4.軟中斷會吃掉你多少CPU?
- 5.一次系統呼叫開銷到底有多大?
- 6.追蹤將服務器CPU耗光的兇手
我的公眾號是「開發內功修煉」,在這里我不是單純介紹技術理論,也不只介紹實踐經驗,而是把理論與實踐結合起來,用實踐加深對理論的理解、用理論提高你的技術實踐能力,歡迎你來關注我的公眾號,也請分享給你的好友~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230164.html
標籤:PHP