本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來自于爬小蟲聯盟,作者:Code皮皮蝦

前言
“ 相信各位爬蟲小伙伴在作業中,肯定遇到過寫了大半天才出來的爬蟲,好不容易運行起來,結果跑的賊慢,反正我是遇到過的,如今是大資料的時代,光會寫爬蟲根本沒有什么競爭力,所以要學會對爬蟲代碼進行優化,優化爬蟲的健壯性或者爬取速度等等,這些都能提高自己的競爭力!”
本文爬蟲以糗事百科為例,以普通爬蟲和多執行緒爬蟲運行時間相比,相信大家都能領略到多執行緒的厲害之處!
多執行緒表情包分類爬取實戰,話不多說,開干!
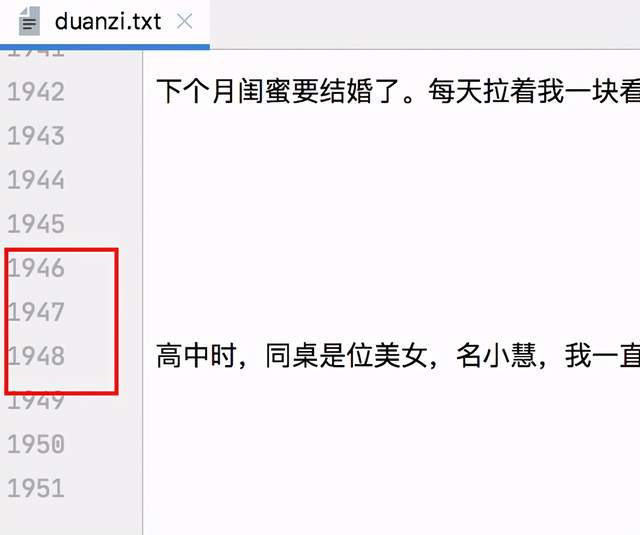
1、普通爬蟲
import requests from lxml import etree import time import sys headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36" } #爬取 def Crawl(response): e = etree.HTML(response.text) #根據class值定位 span_text = e.xpath("//div[@class='content']/span[1]") with open("duanzi.txt", "a", encoding="utf-8") as f: for span in span_text: info = span.xpath("string(.)") f.write(info) #main if __name__ == '__main__': //記下開始時間 start = time.time() base_url = "https://www.qiushibaike.com/text/page/{}" for i in range(1, 14): #列印當前爬取的頁數 print("正在爬取第{}頁".format(i)) new_url = base_url.format(i) #發送get請求 response = requests.get(new_url,headers=headers) Crawl(response) #記下結束時間 end = time.time() #相級訓取運行時間 print(end - start)

2、多執行緒爬蟲
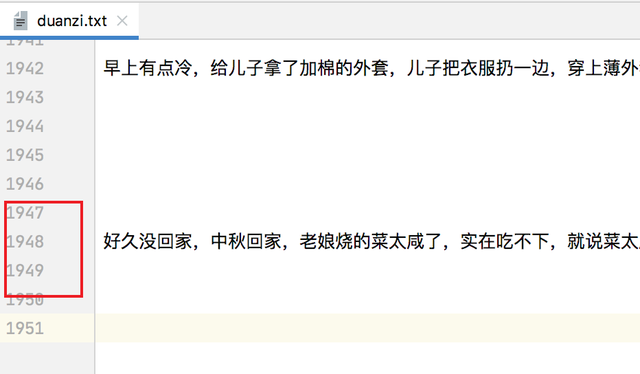
import requests from lxml import etree #Queue佇列,先進先出 from queue import Queue from threading import Thread import time #請求頭 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36" } #資料獲取 #繼承Thread class CrawlInfo(Thread): #重寫init函式 def __init__(self,url_queue,html_queue): Thread.__init__(self) self.url_queue = url_queue self.html_queue = html_queue # 重寫run方法 def run(self): while self.url_queue.empty()== False: url = self.url_queue.get() response = requests.get(url,headers=headers) if response.status_code == 200: #將資料放到佇列中 self.html_queue.put(response.text) #資料決議、保存 #繼承Thread class ParseInfo(Thread): def __init__(self,html_queue): Thread.__init__(self) self.html_queue = html_queue def run(self): #判斷佇列是否為空,不為空則繼續遍歷 while self.html_queue.empty() == False: #從佇列中取最后一個資料 e = etree.HTML(self.html_queue.get()) span_text = e.xpath("//div[@class='content']/span[1]") with open("duanzi.txt", "a", encoding="utf-8") as f: for span in span_text: info = span.xpath("string(.)") f.write(info) #開始 if __name__ == '__main__': start = time.time() #實體化 url_queue = Queue() html_queue = Queue() base_url = "https://www.qiushibaike.com/text/page/{}" for i in range(1,14): print("正在爬取第{}頁".format(i)) new_url = base_url.format(i) url_queue.put(new_url) crawl_list = [] for i in range(3): Crawl = CrawlInfo(url_queue,html_queue) crawl_list.append(Crawl) Crawl.start() for crawl in crawl_list: #join()等到佇列為空,再執行別的操作 crawl.join() parse_list = [] for i in range(3): parse = ParseInfo(html_queue) parse_list.append(parse) parse.start() for parse in parse_list: parse.join() end = time.time() print(end - start)

3、對比運行
普通爬蟲

多執行緒爬蟲

可能還有些小伙伴覺得這幾秒鐘的時間沒什么大不了的,還是那句話,現在是大資料時代,動不動都是上百萬、上千萬的資料量,在采集總量中會有很大的區別, 如有不足之處或更多技巧,歡迎指教補充,愿本文的分享對您之后多執行緒有所幫助,謝謝~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230174.html
標籤:Python
上一篇:Windows下django專案部署 通過Apache2.4+mod_wsgi
下一篇:django--中間件