身為一個有夢想的Java程式員,去大廠作業是我們的目標,去大廠面試是一個必要的環節,這次我就準備了一些高級的Java開發面試題,包含了資料結構與演算法,jvm,多執行緒,面試基礎等,希望對大家有所幫助,

點個小贊,好運不斷,來個關注,青春常駐
另外本人整理了20年面試題大全,包含spring、并發、資料庫、Redis、分布式、dubbo、JVM、微服務等方面總結,下圖是部分截圖,需要的話點這里點這里,暗號CSDN,
一、資料結構與演算法基礎
1.用Java寫一個冒泡排序演算法
/**
現在有一個包含1000個數的陣列,僅前面100個無序,后面900個都已排好序且都大于前面100個數字,那么在第一趟遍歷后,最后發生交換的位置必定小于100,且這個位置之后的資料必定已經有序了,也就是這個位置以后的資料不需要再排序了,于是記錄下這位置,第二次只要從陣列頭部遍歷到這個位置就可以了,如果是對于上面的冒泡排序演算法2來說,雖然也只排序100次,但是前面的100次排序每次都要對后面的900個資料進行比較,而對于現在的排序演算法3,只需要有一次比較后面的900個資料,之后就會設定尾邊界,保證后面的900個資料不再被排序,
*/
public static void bubbleSort(int [] a, int n){
int j , k;
int flag = n ;//flag來記錄最后交換的位置,也就是排序的尾邊界
while (flag > 0){//排序未結束標志
k = flag; //k 來記錄遍歷的尾邊界
flag = 0;
for(j=1; j<k; j++){
if(a[j-1] > a[j]){//前面的數字大于后面的數字就交換
//交換a[j-1]和a[j]
int temp;
temp = a[j-1];
a[j-1] = a[j];
a[j]=temp;
//表示交換過資料;
flag = j;//記錄最新的尾邊界.
}
}
}
}
2.描述一下鏈式存盤結構
它不要求邏輯上相鄰的元素在物理位置上也相鄰,因此它沒有順序存盤結構所具有的弱點,同時也失去了順序表可隨機存取的優點,
其特點主要表現為:
1、比順序存盤結構的存盤密度小;
2、插入、洗掉靈活,結點可以被插入到鏈表的任何位置,首、中、末都可以,而且不必要移動結點中的指標;
3、鏈表的大小可以按需伸縮,是一種動態存盤結構,其實作的集合在增、刪方面性能更高;
4、查找結點時的效率就相對陣列較低,只能從第一個結點開始順著鏈表逐個查找(這是他的缺點),
3.如何遍歷一棵二叉樹?
二叉樹的遍歷分為三種:
前序遍歷:按照“根左右”,先遍歷根節點,再遍歷左子樹 ,再遍歷右子樹
中序遍歷:按照“左根右“,先遍歷左子樹,再遍歷根節點,最后遍歷右子樹
后續遍歷:按照“左右根”,先遍歷左子樹,再遍歷右子樹,最后遍歷根節點
其中前,后,中指的是每次遍歷時候的根節點被遍歷的順序
package com.tree;
import java.util.ArrayList;
import java.util.List;
public class Tree {
private Node root;
private List<Node> list=new ArrayList<Node>();
public Tree(){
init();
}
//樹的初始化:先從葉節點開始,由葉到根
public void init(){
Node x=new Node("X",null,null);
Node y=new Node("Y",null,null);
Node d=new Node("d",x,y);
Node e=new Node("e",null,null);
Node f=new Node("f",null,null);
Node c=new Node("c",e,f);
Node b=new Node("b",d,null);
Node a=new Node("a",b,c);
root =a;
}
//定義節點類:
private class Node{
private String data;
private Node lchid;//定義指向左子樹的指標
private Node rchild;//定義指向右子樹的指標
public Node(String data,Node lchild,Node rchild){
this.data=data;
this.lchid=lchild;
this.rchild=rchild;
}
}
/**
* 對該二叉樹進行前序遍歷 結果存盤到list中 前序遍歷:ABDXYCEF
*/
public void preOrder(Node node)
{
list.add(node); //先將根節點存入list
//如果左子樹不為空繼續往左找,在遞回呼叫方法的時候一直會將子樹的根存入list,這就做到了先遍歷根節點
if(node.lchid != null)
{
preOrder(node.lchid);
}
//無論走到哪一層,只要當前節點左子樹為空,那么就可以在右子樹上遍歷,保證了根左右的遍歷順序
if(node.rchild != null)
{
preOrder(node.rchild);
}
}
/**
* 對該二叉樹進行中序遍歷 結果存盤到list中
*/
public void inOrder(Node node)
{
if(node.lchid!=null){
inOrder(node.lchid);
}
list.add(node);
if(node.rchild!=null){
inOrder(node.rchild);
}
}
/**
* 對該二叉樹進行后序遍歷 結果存盤到list中
*/
public void postOrder(Node node)
{
if(node.lchid!=null){
postOrder(node.lchid);
}
if(node.rchild!=null){
postOrder(node.rchild);
}
list.add(node);
}
/**
* 回傳當前數的深度
* 說明:
* 1、如果一棵樹只有一個結點,它的深度為1,
* 2、如果根結點只有左子樹而沒有右子樹,那么樹的深度是其左子樹的深度加1;
* 3、如果根結點只有右子樹而沒有左子樹,那么樹的深度應該是其右子樹的深度加1;
* 4、如果既有右子樹又有左子樹,那該樹的深度就是其左、右子樹深度的較大值再加1,
*
* @return
*/
public int getTreeDepth(Node node) {
if(node.lchid == null && node.rchild == null)
{
return 1;
}
int left=0,right = 0;
if(node.lchid!=null)
{
left = getTreeDepth(node.lchid);
}
if(node.rchild!=null)
{
right = getTreeDepth(node.rchild);
}
return left>right?left+1:right+1;
}
//得到遍歷結果
public List<Node> getResult()
{
return list;
}
public static void main(String[] args) {
Tree tree=new Tree();
System.out.println("根節點是:"+tree.root);
//tree.preOrder(tree.root);
tree.postOrder(tree.root);
for(Node node:tree.getResult()){
System.out.println(node.data);
}
System.out.println("樹的深度是"+tree.getTreeDepth(tree.root));
}
}
二叉樹與一般樹的區別
- 一般樹的子樹不分次序,而二叉樹的子樹有左右之分.
- 由于二叉樹也是樹的一種,所以大部分的樹的概念,對二叉樹也適用.
- 二叉樹的存貯:每個節點只需要兩個指標域(左節點,右節點),有的為了操作方便也會 增加指向父級節點的指標,除了指標域以外,還會有一個資料域用來保存當前節點的資訊
二叉樹的特點:
- 性質1:在二叉樹的第i層上至多有2^(i-1)個節點(i >= 1)
- 性質2:深度為k的二叉樹至多有2^k-1個節點(k >=1)
- 性質3:對于任意一棵二叉樹T而言,其葉子節點數目為N0,度為2的節點數目為N2,則有N0 = N2 + 1,
- 性質4:具有n個節點的完全二叉樹的深度,
4.倒排一個LinkedList,
根據LinkedList的實作,LinkedList的底層是雙向鏈表,它在get任何一個位置的資料的時候,都會把前面的資料走一遍,用迭代器或者foreach回圈(foreach回圈的原理就是迭代器)去遍歷LinkedList即可,這種方式是直接按照地址去找資料的,將會大大提升遍歷LinkedList的效率,
public static <T> LinkedList<T> reverse(LinkedList<T> linkedList)
{
if (linkedList == null) return linkedList;
LinkedList<T> temp_linkedlist = new LinkedList<T>();
for (T item: linkedList) {
temp_linkedlist.addLast(item);
}
return temp_linkedlist;
}
5.用Java寫一個遍歷目錄下面的所有檔案,
public static void foreachFileList(String filePath) throws IOException {
LinkedList<File> linkedList = new LinkedList<File>();
File file = new File(filePath);
if (file.exists()) {
linkedList.add(file);
while (true) {
file = linkedList.poll();
if (file == null) break;
File[] fileList = file.listFiles();
for (File fileItem : fileList) {
if (fileItem.isDirectory()) {
linkedList.add(fileItem);
continue;//for
}
if (fileItem.isFile())
System.out.println(fileItem.getCanonicalPath());
}
}
}
}
二、Java基礎
1.介面與抽象類的區別?
- 一個類可以實作多個介面,但只能繼承最多一個抽象類
- 抽象類可以包含具體的方法;介面所有的方法都是抽象的(不管是否對介面宣告都是抽象的)(jdk1.7以前,jdk1.8開始新增功能介面中有default 方法,有興趣自己研究)
- 抽象類可以宣告和使用欄位;介面則不能,但是可以創建靜態的final常量
- 抽象類中的方法可以是public、protected、private或者默認的package;介面的方法都是public(不管是否宣告,介面都是公開的)
- 抽象類可以定義建構式,介面不能,
- 介面被宣告為public,省略后,包外的類不能訪問介面
2.Java中的例外有哪幾類?分別怎么使用?
- Throwable包含了錯誤(Error)和例外(Excetion兩類)
- Exception又包含了 運行時例外(RuntimeException, 又叫非檢查例外) 和 非運行時例外(又叫檢查例外)
- Error是程式無法處理了, 如果OutOfMemoryError、OutOfMemoryError等等, 這些例外發生時, java虛擬機一般會終止執行緒 .
- 運行時例外都是RuntimeException類及其子類,如 NullPointerException、IndexOutOfBoundsException等, 這些例外是不檢查的例外, 是在程式運行的時候可能會發生的, 所以程式可以捕捉, 也可以不捕捉. 這些錯誤一般是由程式的邏輯錯誤引起的, 程式應該從邏輯角度去盡量避免.
- 檢查例外是運行時例外以外的例外, 也是Exception及其子類, 這些例外從程式的角度來說是必須經過捕捉檢查處理的, 否則不能通過編譯. 如IOException、SQLException等
3.常用的集合類有哪些?比如List如何排序?
常用的集合分為List(有序排放)、Map(以名和值一一對應的存放)、Set(既無序也沒名).在這三者之中其中List和Set是Collection介面的子介面,而Map不是Collection介面的子介面.
- List常用有:ArrayList和LinkedList,Vecotr(執行緒安全)
- Set常用有: TreeSet, HashSet 元素不可重復,內部結構用HashMap,Key為Set的item值,value為一個固定的常量,java.util.Collections.newHashSetFromMap(),內部其實質還是通過ConcurrentHashMap實作執行緒安全的,
- Map: TreeMap和LinkedHashMap,HashMap,HashTable(執行緒安全)
- sort()方法排序的本質其實也是借助Comparable介面和Comparator介面的實作,一般有2種用法:
- 直接將需要排序的list作為引數傳入,此時list中的物件必須實作了Comparable介面,然后sort會按升序的形式對元素進行排序;
- 傳入list作為第一個引數,同時追加一個Comparator的實作類作為第二個引數,然后sort方法會根據Comparator介面的實作類的邏輯,按升序進行排序;
4.ArrayList和LinkedList內部的實作大致是怎樣的?他們之間的區別和優缺點?
- Linkedlist集合的優勢:添加元素時可以指定位置,比ArrayList集合添加元素要快很多,
- Linkedlist在get很慢,LinkedList在get任何一個位置的資料的時候,都會把前面的資料走一遍,盡量不使用,而使用foreach LinkedList的方式來直接取得資料,
- 這兩種方式各有優缺,為更好的使用可以將這兩者進行聯合使用,使用Linkedlist集合進行存盤和添加元素,使用Arraylist集合進行get獲取元素,
5.記憶體溢位是怎么回事?請舉一個例子?
- 記憶體溢位(out of memory)通俗理解就是記憶體不夠,在計算機程式中通俗的理解就是開辟的記憶體空間得不到釋放,
- OOM有堆溢位,堆疊溢位,方法區溢位(主要是動態生成class的處理過多)
6.= =和equals的區別?
- = =號在比較基本資料型別時比較的是值,而用= =號比較兩個物件時比較的是兩個物件的地址值
- Object類中equals()方法底層依賴的是= =號,那么,在所有沒有重寫equals()方法的類中,呼叫equals()方法其實和使用= =號的效果一樣,然而,Java提供的所有類中,絕大多數類都重寫了equals()方法,重寫后的equals()方法一般都是比較兩個物件的值
7.hashCode方法的作用?
- hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用來在散列存盤結構中確定物件的存盤地址的;
- 如果兩個物件相同,就是適用于equals(Java.lang.Object) 方法,那么這兩個物件的hashCode一定要相同;
- 如果物件的equals方法被重寫,那么物件的hashCode也盡量重寫,并且產生hashCode使用的物件,一定要和equals方法中使用的一致,否則就會違反上面提到的第2點;
- 兩個物件的hashCode相同,并不一定表示兩個物件就相同,也就是不一定適用于equals(java.lang.Object) 方法,只能夠說明這兩個物件在散列存盤結構中,如Hashtable,他們“存放在同一個籃子里”,
8.NIO是什么?適用于何種場景?
- JDK引入了一種基于通道和緩沖區的 I/O 方式,它可以使用 Native 函式庫直接分配堆外記憶體,然后通過一個存盤在 Java 堆的 DirectByteBuffer 物件作為這塊記憶體的參考進行操作,避免了在 Java 堆和 Native 堆中來回復制資料,
- NIO 是一種同步非阻塞的 IO 模型,同步是指執行緒不斷輪詢 IO 事件是否就緒,非阻塞是指執行緒在等待 IO 的時候,可以同時做其他任務,同步的核心就是 Selector,Selector 代替了執行緒本身輪詢 IO 事件,避免了阻塞同時減少了不必要的執行緒消耗;非阻塞的核心就是通道和緩沖區,當 IO 事件就緒時,可以通過寫道緩沖區,保證 IO 的成功,而無需執行緒阻塞式地等待,
9.HashMap實作原理,如何保證HashMap的執行緒安全?
HashMap實際上是一個“鏈表散列”的資料結構,即陣列和鏈表的結合體,HashMap底層就是一個陣列結構,陣列中的每一項又是一個鏈表,
- =使用 java.util.Hashtable 類,此類是執行緒安全的,Hashtable是通過每個方法用synchronized來處理,性能不及ConcurrentHashMap
- 使用 java.util.concurrent.ConcurrentHashMap,此類是執行緒安全的,采用了分段鎖實作同步,
- 使用 java.util.Collections.synchronizedMap() 方法包裝 HashMap object,得到執行緒安全的Map,并在此Map上進行操作,
10.Java中一個字符占多少個位元組,擴展再問int, long, double占多少位元組
Java char: utf-16:2個位元組, int-4, long-8,double-9
11.創建一個類的實體都有哪些辦法?
- 關鍵字 new,工廠模式是對這種方式的包裝;
- 類實作克隆介面,克隆一個實體,原型模式是一個應用實體;
- 用該類的加載器,newinstance,java的反射,反射使用實體:Spring的依賴注入、切面編程中動態代理等取得
- 通過IO流反序列化讀取一個類,獲得實體,
12.final/finally/finalize的區別?
- final:如果一個類被final修飾,意味著該類不能派生出新的子類,不能作為父類被繼承,因此一個類不能被宣告為abstract,又被宣告為final,將變數或方法宣告為final,可以保證他們在使用的時候不被改變,其初始化可以在兩個地方:一是其定義的地方,也就是在final變數在定義的時候就對其賦值;二是在建構式中,這兩個地方只能選其中的一個,被宣告為final的方法也只能使用,不能重寫,
- finally:在例外處理的時候,提供finally塊在成功或失敗都可以執行任何的清除操作,
- finalize:finalize是方法名,java技術允許使用finalize()方法在垃圾收集器將物件從記憶體中清除出去之前做必要的清理作業,finalize()方法是在垃圾收集器洗掉物件之前對這個物件呼叫的,可以從Object.finalize()繼承下來,
13.Session/Cookie的區別?
- cookie是客戶端的會話狀態的一種儲存機制,一般限制4k以內,session是一種服務器端的資訊管理機制,
- session產生的session_id放在cookie里面,如果用戶把cookie禁止掉,可以通過在url中保留session_id
14.String/StringBuffer/StringBuilder的區別,擴展再問他們的實作?
StringBuilder:執行緒非安全的,StringBuffer:執行緒安全的,三者在執行速度方面的比較:StringBuilder > StringBuffer > String
15.Servlet的生命周期?
- Servlet 通過呼叫 init () 方法進行初始化,
- Servlet 呼叫 service() 方法來處理客戶端的請求,
- Servlet 通過呼叫 destroy() 方法終止(結束),
- 最后,Servlet 是由 JVM 的垃圾回收器進行垃圾回收的,
16.Java有自己的記憶體回識訓制,但為什么還存在記憶體泄漏的問題呢?
主要是沒有釋放物件參考造成的記憶體泄漏,比如下例:
class MyList{
/*
* 此處只為掩飾效果,并沒有進行封裝之類的操作
* 將List集合用關鍵字 static 宣告,這時這個集合將不屬于任MyList 物件,而是一個類成員變數
*/
public static List<String> list = new ArrayList<String>();
}
class Demo{
public static void main(String[] args) {
MyList list = new MyList();
list.list.add("123456");
// 此時即便我們將 list指向null,仍然存在記憶體泄漏,因為MyList中的list是靜態的,它屬于類所有而不屬于任何特定的實體
list = null;
}
}
三、JVM
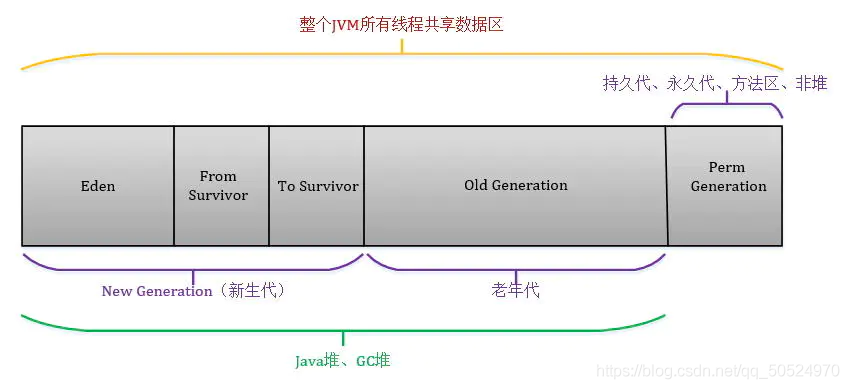
1.JVM堆的基本結構,
2.JVM的垃圾演算法有哪幾種?CMS垃圾回收的基本流程?
基本的演算法有:
標記-清除演算法
等待被回收物件在被標記后直接對物件進行清除,會帶來另一個新的問題——記憶體碎片化,如果下次有比較大的物件實體需要在堆上分配較大的記憶體空間時,可能會出現無法找到足夠的連續記憶體而不得不再次觸發垃圾回收,
復制演算法(Java堆中新生代的垃圾回收演算法)
此GC演算法實際上解決了標記-清除演算法帶來的“記憶體碎片化”問題,首先還是先標記處待回收記憶體和不用回收的記憶體,下一步將不用回收的記憶體復制到新的記憶體區域,這樣舊的記憶體區域就可以全部回收,而新的記憶體區域則是連續的,它的缺點就是會損失掉部分系統記憶體,因為你總要騰出一部分記憶體用于復制,
標記-壓縮演算法(或稱為標記-整理演算法,Java堆中老年代的垃圾回收演算法)
對于新生代,大部分物件都不會存活,所以在新生代中使用復制演算法較為高效,而對于老年代來講,大部分物件可能會繼續存活下去,如果此時還是利用復制演算法,效率則會降低,標記-壓縮演算法首先還是“標記”,標記過后,將不用回收的記憶體物件壓縮到記憶體一端,此時即可直接清除邊界處的記憶體,這樣就能避免復制演算法帶來的效率問題,同時也能避免記憶體碎片化的問題,老年代的垃圾回收稱為“Major GC”,
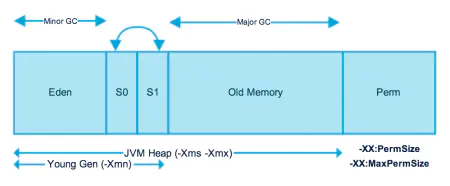
CMS的基本流程:
- 初始標記 :在這個階段,需要虛擬機停頓正在執行的任務,官方的叫法STW(Stop The Word),這個程序從垃圾回收的"根物件"開始,只掃描到能夠和"根物件"直接關聯的物件,并作標記,所以這個程序雖然暫停了整個JVM,但是很快就完成了,
- 并發標記 :這個階段緊隨初始標記階段,在初始標記的基礎上繼續向下追溯標記,并發標記階段,應用程式的執行緒和并發標記的執行緒并發執行,所以用戶不會感受到停頓,
- 并發預清理 :并發預清理階段仍然是并發的,在這個階段,虛擬機查找在執行并發標記階段新進入老年代的物件(可能會有一些物件從新生代晉升到老年代, 或者有一些物件被分配到老年代),通過重新掃描,減少下一個階段"重新標記"的作業,因為下一個階段會Stop The World,
- 重新標記 :這個階段會暫停虛擬機,收集器執行緒掃描在CMS堆中剩余的物件,掃描從"跟物件"開始向下追溯,并處理物件關聯,
- 并發清理 :清理垃圾物件,這個階段收集器執行緒和應用程式執行緒并發執行,
- 并發重置 :這個階段,重置CMS收集器的資料結構,等待下一次垃圾回收
延伸說明:
- CMS(Concurrent Mark-Sweep) 在啟動JVM引數加上-XX:+UseConcMarkSweepGC,這個引數表示對于老年代的回收采用CMS,CMS采用的基礎演算法是:標記—清除(Mark-Sweep),CMS不會整理、壓縮堆空間,這樣就會有一個問題:經過CMS收集的堆會產生空間碎片,CMS的另一個缺點是它需要更大的堆空間,
- 如果你的應用程式對停頓比較敏感,并且在應用程式運行的時候可以提供更大的記憶體和更多的CPU(也就是硬體牛逼),那么使用CMS來收集會給你帶來好處,還有,如果在JVM中,有相對較多存活時間較長的物件(老年代比較大)會更適合使用CMS,
3.Java程式是否會記憶體溢位,記憶體泄露情況發生?舉幾個例子,
- 靜態集合類引起記憶體泄漏:
Static Vector v = new Vector(10);
for (int i = 1; i<100; i++)
{
Object o = new Object();
v.add(o);
o = null;
}
//o的物件還在Vector中,因此需要從中移除,或者直接把vector=null
- 各種資源性連接沒有正確關閉.比如資料庫連接(dataSourse.getConnection()),網路連接(socket)和io連接,除非其顯式的呼叫了其close()方法將其連接關閉,否則是不會自動被GC 回收的,
- 不正確使用單例模式是引起記憶體泄漏的一個常見問題.
- 當集合里面的物件屬性被修改后,造成該物件的Hashcode改變了,再呼叫remove()方法時不起作用,
4.常用的GC策略,什么時候會觸發YGC,什么時候觸發FGC?
常見記憶體回收策略:
1. 串行&并行
串行:單執行緒執行記憶體回收作業,十分簡單,無需考慮同步等問題,但耗時較長,不適合多cpu,
并行:多執行緒并發進行回收作業,適合多CPU,效率高,
2.并發& stop the world
stop the world:jvm里的應用執行緒會掛起,只有垃圾回收執行緒在作業進行垃圾清理作業,簡單,無需考慮回收不干凈等問題,
并發:在垃圾回收的同時,應用也在跑,保證應用的回應時間,會存在回收不干凈需要二次回收的情況,
3.壓縮&非壓縮©
壓縮:在進行垃圾回收后,會通過滑動,把存活物件滑動到連續的空間里,清理碎片,保證剩余的空間是連續的,
非壓縮:保留碎片,不進行壓縮,
copy:將存活物件移到新空間,老空間全部釋放,(需要較大的記憶體,)
- YGC :對新生代堆進行GC: edn空間不足
- FGC的時機:old空間不足; 2.perm空間不足;3.顯示呼叫System.gc() ,包括RMI等的定時觸發; 4.YGC時的悲觀策略;dump live的記憶體資訊時(jmap –dump:live),
四、多執行緒/并發
1.如何創建執行緒?如何保證執行緒安全?
保證執行緒安全: 競爭與原子操作、同步與鎖、可重入、使用valatile防止CPU過度優化,
- 繼承Thread類,必須重寫run方法,在run方法中定義需要執行的任務,
- 實作Runnable介面,
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();
class MyRunnable implements Runnable{... }
Note: Java如何創建行程:
第一種方式是通過Runtime.exec()方法來創建一個行程,第二種方法是通過ProcessBuilder的start方法來創建行程,
2.什么是死鎖?如何避免死鎖
執行緒死鎖是指由于兩個或者多個執行緒互相持有對方所需要的資源,導致這些執行緒處于等待狀態,無法前往執行,.
- 按同樣的順序訪問(鎖定)資源
- 嘗試獲取鎖的時候加一個超時時間,這也就意味著在嘗試獲取鎖的程序中若超過了這個時限該執行緒則放棄對該鎖請求,
- 使用Atom原子操作(無鎖模式)
3.Volatile關鍵字的作用?
volatile特性一:記憶體可見性,即執行緒A對volatile變數的修改,其他執行緒獲取的volatile變數都是最新的,volatile特性二:可以禁止指令重排序,避免重排序指令后訪問資料錯亂.
Volatile可以看做一種輕量級的鎖,但又和鎖有些不同,
a) 它對于多執行緒,不是一種互斥(mutex)關系,
b) 用volatile修飾的變數,不能保證該變數狀態的改變對于其他執行緒來說是一種“原子化操作”,
4. HashMap在多執行緒環境下使用需要注意什么?為什么?
- 并發操作HashMap,是有可能帶來死回圈以及資料丟失的問題的,當我們呼叫get()這個鏈表中不存在的元素的時候,就會出現死回圈,
- HashMap在并發執行put操作時會引起死回圈,導致CPU利用率接近100%,因為多執行緒會導致HashMap的Node鏈表形成環形資料結構,一旦形成環形資料結構,Node的next節點永遠不為空,就會在獲取Node時產生死回圈,
- 一句話總結就是,并發環境下的rehash程序可能會帶來回圈鏈表,導致死回圈致使執行緒掛掉,
- HashTable,它并未使用分段鎖,而是鎖住整個陣列,高并發環境下效率非常的低,會導致大量執行緒等待,同樣的,Synchronized關鍵字、Lock性能都不如分段鎖實作的ConcurrentHashMap,
5.什么是守護執行緒?有什么用?
守護執行緒(即daemon thread)是服務執行緒,處理后臺事務,如垃圾回收等,JVM內部的實作是如果運行的程式只剩下守護執行緒的話,程式將終止運行,直接結束,所以守護執行緒是作為輔助執行緒存在的,應用程式里的執行緒,一般都是用戶自定義執行緒,用戶也可以在應用程式代碼自定義守護執行緒,只需要呼叫Thread類的t.setDaemon(true);設定一下即可,
6.Java里面的Threadlocal是怎樣實作的?
- 作用:在并發環境下避免競爭、簡化編程,高效.在并發環境下提供了一個邏輯上全域的訪問點訪問執行緒本地物件
- 原理: 每個執行緒內部都有一個hastable作為存盤存盤器保存執行緒本地物件集,ThreadLocal實體物件作為key可以被所有執行緒共享,這個實體物件就是我們所說得全域的訪問點,通過它可以訪問執行緒本地物件,所以我們可以這樣說:通過ThreadLocal提供了邏輯上全域的執行緒本地物件,
7.什么是條件鎖、讀寫鎖、自旋鎖、可重入鎖?
1.條件鎖
在lock中提供了與之關聯的條件,一個鎖可能關聯一個或多個條件,這些條件通過condition介面宣告,目的是運行執行緒獲取鎖并且查看等待某一個條件是否滿足,如果不滿足則掛起直到某個執行緒喚醒它們,condition介面提供了掛起執行緒和喚起執行緒的機制;
2.讀寫鎖
Java中讀寫鎖有個介面java.util.concurrent.locks.ReadWriteLock,也有具體的實作ReentrantReadWriteLock,它們不是繼承關系,但都是基于 AbstractQueuedSynchronizer來實作,ReentrantReadWriteLock的鎖策略有兩種,分為公平策略和非公平策略
注意: 在同一執行緒中,持有讀鎖后,不能直接呼叫寫鎖的lock方法 ,否則會造成死鎖,,
3.可重入(Reentrant)鎖
如果鎖具備可重入性,則稱作為可重入鎖,像synchronized和 ReentrantLock都是可重入鎖,假如某一時刻,執行緒A執行到了method1,此時執行緒 A獲取了這個物件的鎖,而由于method2也是synchronized方法,因為可重入,執行緒A不需要申請加鎖即可執行,(可以理解鎖的維度是執行緒,所以已擁有鎖不需要再次申請加鎖),不可重入鎖(自旋鎖):不可以再次進入方法A,也就是說獲得鎖進入方法A是此執行緒在釋放鎖錢唯一的一次進入方法A,
4.可中斷鎖
可中斷鎖:顧名思義,就是可以相應中斷的鎖,在Java中,synchronized就不是可中斷鎖,而Lock是可中斷鎖,
8.執行緒池ThreadPoolExecutor的幾個引數說明?
- corePoolSize 核心執行緒池大小
- maximumPoolSize 執行緒池最大容量大小
- keepAliveTime 執行緒池空閑時,執行緒存活的時間,
- TimeUnit 時間單位
- ThreadFactory 創建執行緒的工廠
- BlockingQueue任務佇列,用于保存等待執行的任務的阻塞佇列,比如基于陣列的有界ArrayBlockingQueue、,基于鏈表的無界LinkedBlockingQueue,最多只有一個元素的同步佇列SynchronousQueue,優先級佇列PriorityBlockingQueue
- RejectedExecutionHandler 執行緒拒絕策略
執行緒池在執行excute方法時,主要有以下四種情況:
- 如果當前運行的執行緒少于corePoolSize,則創建新執行緒來執行任務(需要獲得全域鎖)
- 如果運行的執行緒等于或多于corePoolSize ,則將任務加入BlockingQueue
- 如果無法將任務加入BlockingQueue(佇列已滿),則創建新的執行緒來處理任務(需要獲得全域鎖)
- 如果創建新執行緒將使當前運行的執行緒超出maxiumPoolSize,任務將被拒絕,并呼叫RejectedExecutionHandler.rejectedExecution()方法,
執行緒池采取上述的流程進行設計是為了減少獲取全域鎖的次數,在執行緒池完成預熱(當前運行的執行緒數大于或等于corePoolSize)之后,幾乎所有的excute方法呼叫都執行步驟2,
最后:
針對最近很多人都在復習等待金三銀四,我這邊也整理了相當多的面試專題資料,也有其他大廠的面經,希望可以幫助到大家,
下面的面試題答案都整理成檔案筆記,也還整理了一些面試資料&最新2020收集的一些大廠的面試真題(都整理成檔案,小部分截圖),有需要的可以點擊進入暗號CSDN
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230284.html
標籤:java