BeautifulSoup 根據輸入的公司名稱來爬取企查查網站中公司的詳細資訊(可避開手動驗證)
- 1、獲取headers
- 2、登錄成功后,可根據輸入的公司名稱進行查詢操作,得到所需要的內容,
- 3、將獲取到的文本進行文本特殊化處理,并將其匯總成一個dataframe,方便后面保存為csv
- 4、輸入公司名稱
- 5、最后執行此代碼,查詢companys串列中所有公司名稱的詳細資訊并保存為csv,
- ps:如果大家在 soup.find_all('a',{'class': 'title'})[0].get('href')這里遇到點錯誤,可能是天眼查那邊更新了網頁代碼,大家可以根據這個操作來更新代碼,
- 創作不易啊,如果大家覺得這個筆記對你們有用的,麻煩幫忙點個贊加關注哦,
- 上次因作業需要去天眼查網站爬取了一些公司的詳細資訊,但是那速度實在是太慢了,而且爬取到一定數量之后還會彈出驗證資訊導致爬取中斷,最近又需要爬取一次,而且資料量還比較大,用Selenium實在是太久都爬不完,所以被迫學習了下如何用BeautifulSoup來進行爬取,跟大家分享一下我對BeautifulSoup的用法,再次宣告,本筆記僅用于個人學習用途,并不可以進行大資料的爬取,
1、獲取headers
1、進入企查查官網進行注冊并登錄,
2、然后按F12彈出開發者工具,點擊Network,然后你會看到企查查這個網址,點擊一下
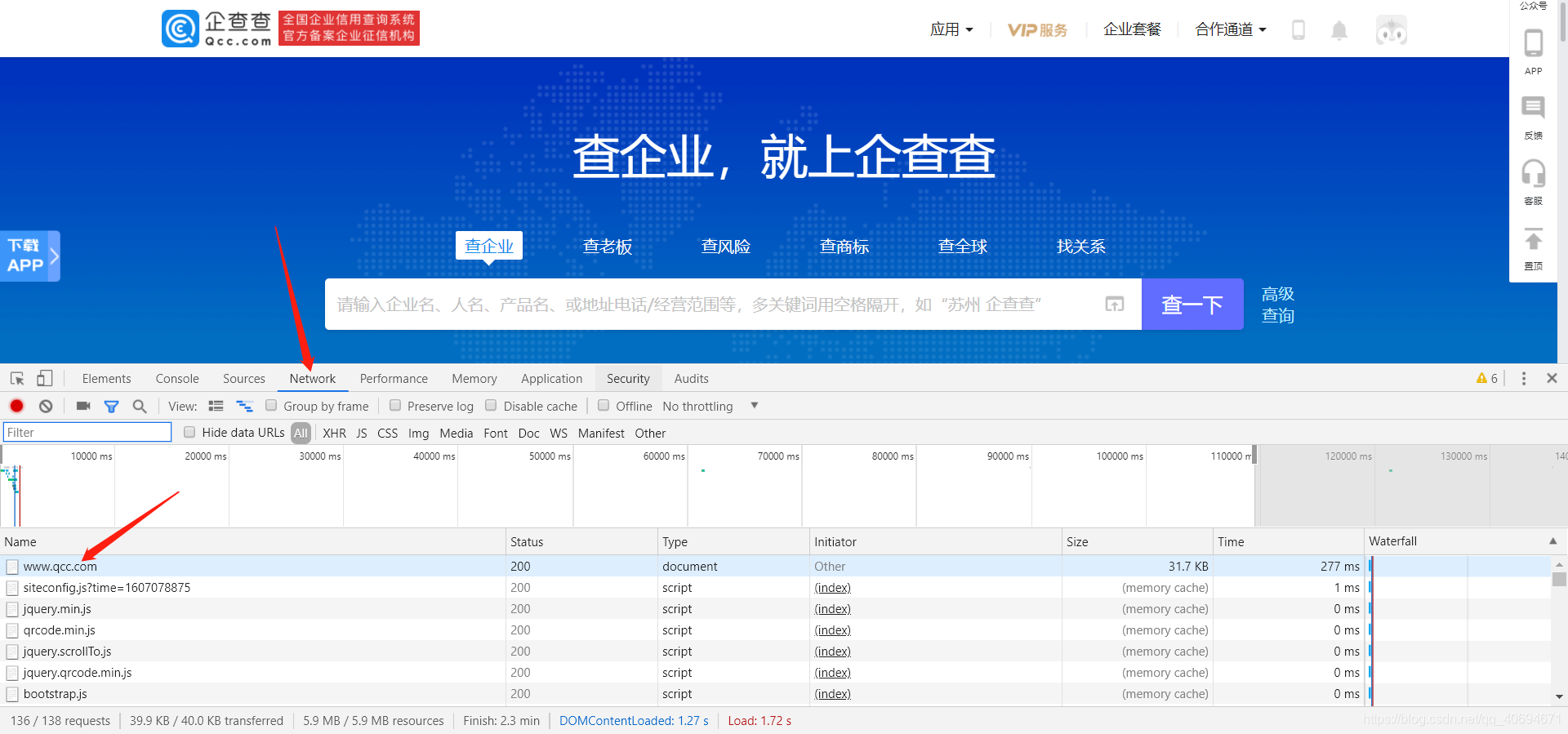
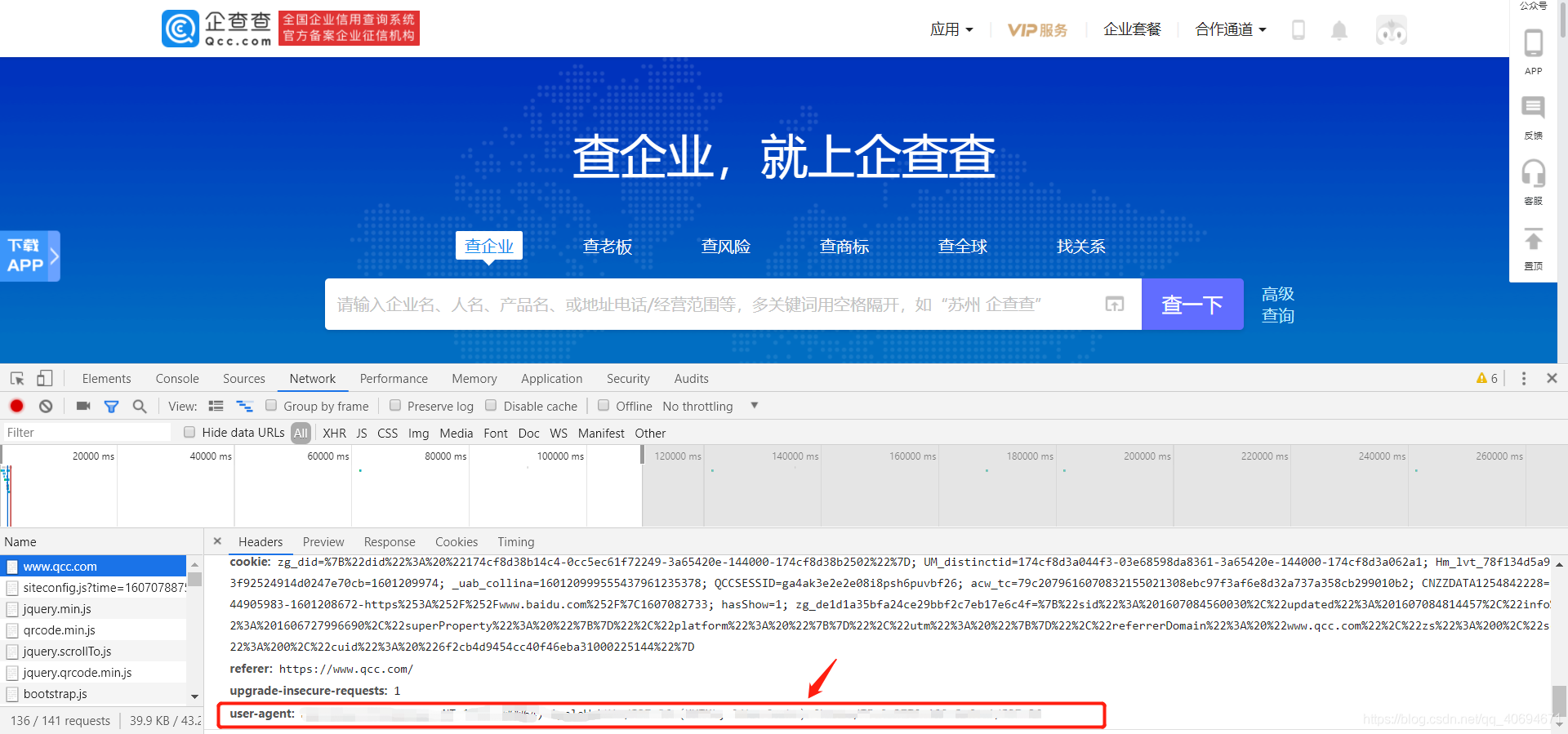
然后可以找到我們需要復制的header,這是非常關鍵的步驟,切記這個header是自己注冊之后登錄成功所獲取的header,這樣方便后面保存一次之后就可以在一定時間內無限訪問網址進行查詢的操作,
from bs4 import BeautifulSoup
import requests
import time
# 保持會話
# 新建一個session物件
sess = requests.session()
# 添加headers(header為自己登錄的企查查網址,輸入賬號密碼登錄之后所顯示的header,此代碼的上方介紹了獲取方法)
afterLogin_headers = {'User-Agent': '此代碼上方介紹了獲取的方法'}
# post請求(代表著登錄行為,登錄一次即可保存,方便后面執行查詢指令)
login = {'user':'自己注冊的賬號','password':'密碼'}
sess.post('https://www.qcc.com',data=login,headers=afterLogin_headers)
整段代碼的含義為:偽裝成用戶進行登錄行為(回傳200狀態碼代表著登錄成功),
2、登錄成功后,可根據輸入的公司名稱進行查詢操作,得到所需要的內容,
def get_company_message(company):
# 獲取查詢到的網頁內容(全部)
search = sess.get('https://www.qcc.com/search?key={}'.format(company),headers=afterLogin_headers,timeout=10)
search.raise_for_status()
search.encoding = 'utf-8' #linux utf-8
soup = BeautifulSoup(search.text,features="html.parser")
href = soup.find_all('a',{'class': 'title'})[0].get('href')
time.sleep(4)
# 獲取查詢到的網頁內容(全部)
details = sess.get(href,headers=afterLogin_headers,timeout=10)
details.raise_for_status()
details.encoding = 'utf-8' #linux utf-8
details_soup = BeautifulSoup(details.text,features="html.parser")
message = details_soup.text
time.sleep(2)
return message
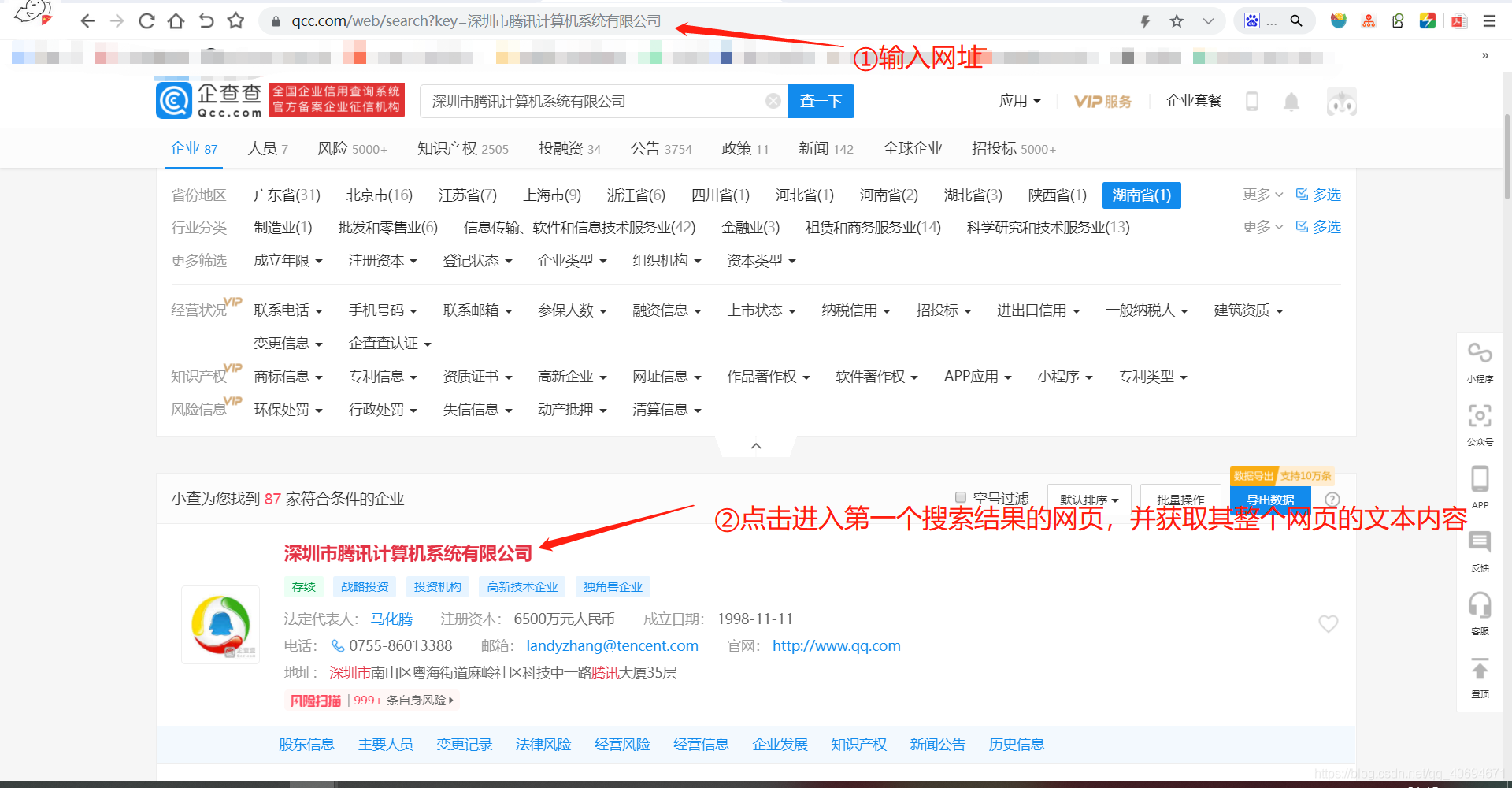
上面的代碼代表著執行了兩個步驟,
- ①查詢某公司
- ②點擊進入第一位搜索結果的新網站,并回傳該網址的文本內容,
3、將獲取到的文本進行文本特殊化處理,并將其匯總成一個dataframe,方便后面保存為csv
import pandas as pd
def message_to_df(message,company):
list_companys = []
Registration_status = []
Date_of_Establishment = []
registered_capital = []
contributed_capital = []
Approved_date = []
Unified_social_credit_code = []
Organization_Code = []
companyNo = []
Taxpayer_Identification_Number = []
sub_Industry = []
enterprise_type = []
Business_Term = []
Registration_Authority = []
staff_size = []
Number_of_participants = []
sub_area = []
company_adress = []
Business_Scope = []
list_companys.append(company)
Registration_status.append(message.split('登記狀態')[1].split('\n')[1].split('成立日期')[0].replace(' ',''))
Date_of_Establishment.append(message.split('成立日期')[1].split('\n')[1].replace(' ',''))
registered_capital.append(message.split('注冊資本')[1].split('人民幣')[0].replace(' ',''))
contributed_capital.append(message.split('實繳資本')[1].split('人民幣')[0].replace(' ',''))
Approved_date.append(message.split('核準日期')[1].split('\n')[1].replace(' ',''))
try:
credit = message.split('統一社會信用代碼')[1].split('\n')[1].replace(' ','')
Unified_social_credit_code.append(credit)
except:
credit = message.split('統一社會信用代碼')[3].split('\n')[1].replace(' ','')
Unified_social_credit_code.append(credit)
Organization_Code.append(message.split('組織機構代碼')[1].split('\n')[1].replace(' ',''))
companyNo.append(message.split('工商注冊號')[1].split('\n')[1].replace(' ',''))
Taxpayer_Identification_Number.append(message.split('納稅人識別號')[1].split('\n')[1].replace(' ',''))
try:
sub = message.split('所屬行業')[1].split('\n')[1].replace(' ','')
sub_Industry.append(sub)
except:
sub = message.split('所屬行業')[1].split('為')[1].split(',')[0]
sub_Industry.append(sub)
enterprise_type.append(message.split('企業型別')[1].split('\n')[1].replace(' ',''))
Business_Term.append(message.split('營業期限')[1].split('登記機關')[0].split('\n')[-1].replace(' ',''))
Registration_Authority.append(message.split('登記機關')[1].split('\n')[1].replace(' ',''))
staff_size.append(message.split('人員規模')[1].split('人')[0].split('\n')[-1].replace(' ',''))
Number_of_participants.append(message.split('參保人數')[1].split('所屬地區')[0].replace(' ','').split('\n')[2])
sub_area.append(message.split('所屬地區')[1].split('\n')[1].replace(' ',''))
try:
adress = message.split('經營范圍')[0].split('企業地址')[1].split('查看地圖')[0].split('\n')[2].replace(' ','')
company_adress.append(adress)
except:
adress = message.split('經營范圍')[1].split('企業地址')[1].split()[0]
company_adress.append(adress)
Business_Scope.append(message.split('經營范圍')[1].split('\n')[1].replace(' ',''))
df = pd.DataFrame({'公司':company,\
'登記狀態':Registration_status,\
'成立日期':Date_of_Establishment,\
'注冊資本':registered_capital,\
'實繳資本':contributed_capital,\
'核準日期':Approved_date,\
'統一社會信用代碼':Unified_social_credit_code,\
'組織機構代碼':Organization_Code,\
'工商注冊號':companyNo,\
'納稅人識別號':Taxpayer_Identification_Number,\
'所屬行業':sub_Industry,\
'企業型別':enterprise_type,\
'營業期限':Business_Term,\
'登記機關':Registration_Authority,\
'人員規模':staff_size,\
'參保人數':Number_of_participants,\
'所屬地區':sub_area,\
'企業地址':company_adress,\
'經營范圍':Business_Scope})
return df
這段代碼是對獲取到的文本內容進行文本識別處理,只能處理大部分的內容,可能會有極個別的是空值,大家有興趣可以自己重寫,
4、輸入公司名稱
- 這里只是寫個案例,所以隨便寫了個串列,一般跑自己代碼的是讀取自己的csv檔案關于公司名稱的那一列,然后轉為串列)
# 測驗所用
companys = ['深圳市騰訊計算機系統有限公司','阿里巴巴(中國)有限公司']
# 實際所用
# df_companys = pd.read_csv('自己目錄的絕對路徑/某某.csv')
# companys = df_companys['公司名稱'].tolist()
5、最后執行此代碼,查詢companys串列中所有公司名稱的詳細資訊并保存為csv,
for company in companys:
try:
messages = get_company_message(company)
except:
pass
else:
df = message_to_df(messages,company)
if(company==companys[0]):
df.to_csv('自己目錄的絕對路徑/某某.csv',index=False,header=True)
else:
df.to_csv('自己目錄的絕對路徑/某某.csv',mode='a+',index=False,header=False)
time.sleep(1)
至此,就可以得到這兩家公司的一些詳細資訊,
ps:如果大家在 soup.find_all(‘a’,{‘class’: ‘title’})[0].get(‘href’)這里遇到點錯誤,可能是天眼查那邊更新了網頁代碼,大家可以根據這個操作來更新代碼,
①按F12進入開發者除錯頁面
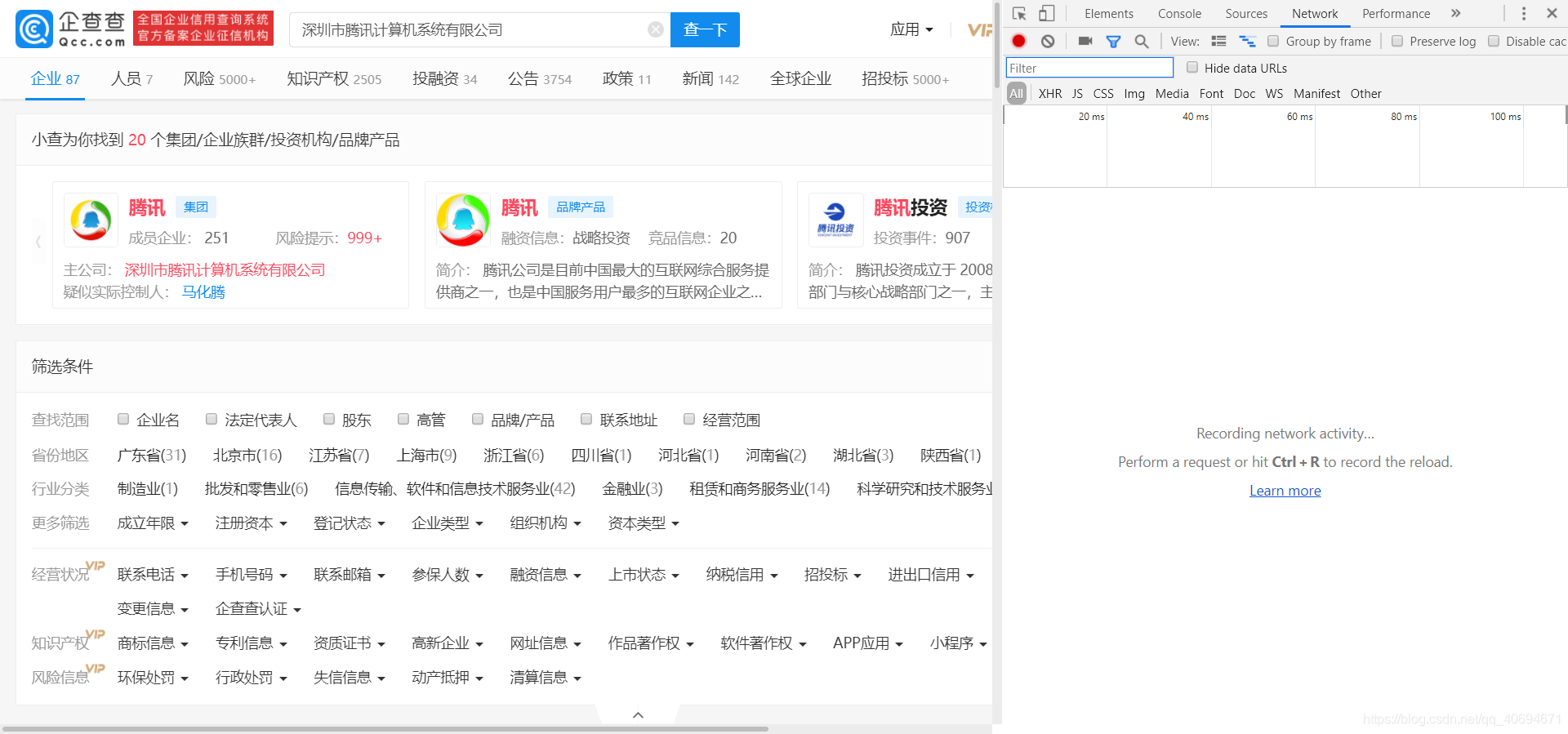
②就點擊“深圳市騰訊計算機系統有限公司”這個點擊操作而言,右擊,然后選擇“檢查”選項,然后就可以看到開發者除錯頁面那里也自動跳轉到了相關的位置,
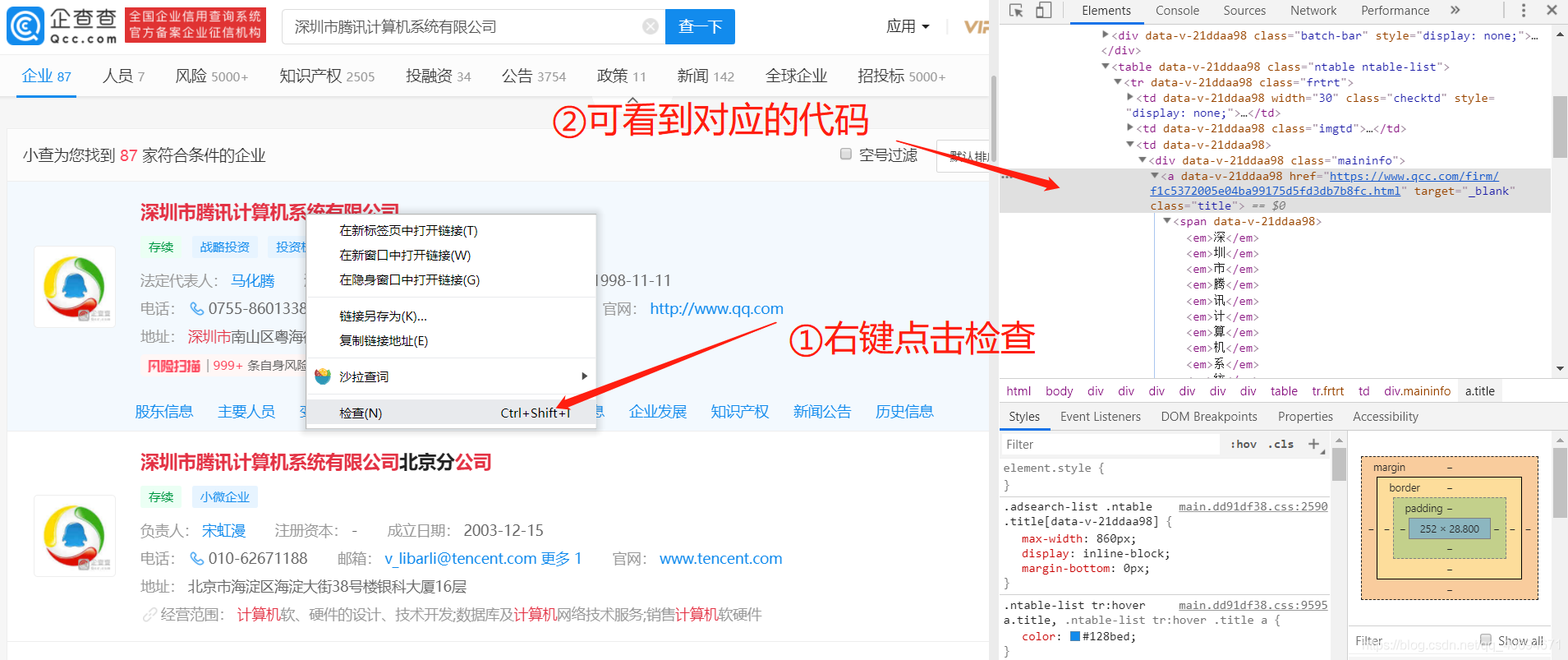
③我們可以看到,這是一個a標簽,class為title的html代碼,所以,如果報錯,可根據這個操作更換,比如,class改為了company_title,那代碼也可對應的改為:soup.find_all(‘a’,{‘class’: ‘company_title’})[0].get(‘href’)
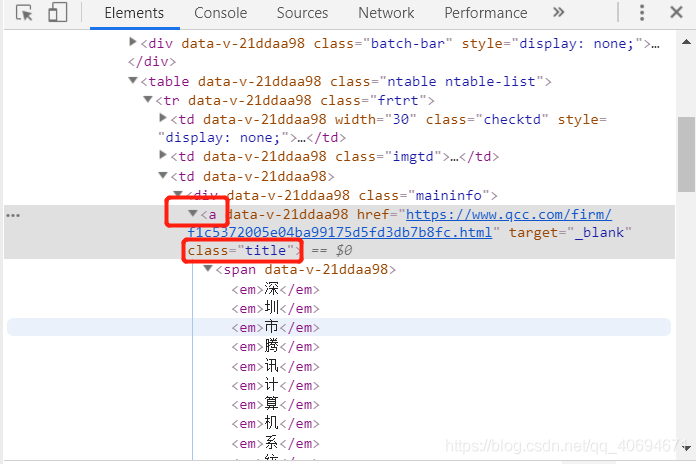
最后,大家需要注意的是,爬取的時候需要適當的設定一下睡眠時間,不然會被檢測到是爬蟲機器人在操作,可能會彈出彈窗讓你驗證,這樣會導致回圈被中斷,第二個就是某個時間段爬取量盡量不要太大,不然也是會被檢測到的,
此處貼上完整代碼,大家可參考著學習BeautifuSoup的妙用哦,
from bs4 import BeautifulSoup
import requests
import time
# 保持會話
# 新建一個session物件
sess = requests.session()
# 添加headers(header為自己登錄的企查查網址,輸入賬號密碼登錄之后所顯示的header,此代碼的上方介紹了獲取方法)
afterLogin_headers = {'User-Agent': '此代碼上方介紹了獲取的方法'}
# post請求(代表著登錄行為,登錄一次即可保存,方便后面執行查詢指令)
login = {'user':'自己注冊的賬號','password':'密碼'}
sess.post('https://www.qcc.com',data=login,headers=afterLogin_headers)
def get_company_message(company):
# 獲取查詢到的網頁內容(全部)
search = sess.get('https://www.qcc.com/search?key={}'.format(company),headers=afterLogin_headers,timeout=10)
search.raise_for_status()
search.encoding = 'utf-8' #linux utf-8
soup = BeautifulSoup(search.text,features="html.parser")
href = soup.find_all('a',{'class': 'title'})[0].get('href')
time.sleep(4)
# 獲取查詢到的網頁內容(全部)
details = sess.get(href,headers=afterLogin_headers,timeout=10)
details.raise_for_status()
details.encoding = 'utf-8' #linux utf-8
details_soup = BeautifulSoup(details.text,features="html.parser")
message = details_soup.text
time.sleep(2)
return message
import pandas as pd
def message_to_df(message,company):
list_companys = []
Registration_status = []
Date_of_Establishment = []
registered_capital = []
contributed_capital = []
Approved_date = []
Unified_social_credit_code = []
Organization_Code = []
companyNo = []
Taxpayer_Identification_Number = []
sub_Industry = []
enterprise_type = []
Business_Term = []
Registration_Authority = []
staff_size = []
Number_of_participants = []
sub_area = []
company_adress = []
Business_Scope = []
list_companys.append(company)
Registration_status.append(message.split('登記狀態')[1].split('\n')[1].split('成立日期')[0].replace(' ',''))
Date_of_Establishment.append(message.split('成立日期')[1].split('\n')[1].replace(' ',''))
registered_capital.append(message.split('注冊資本')[1].split('人民幣')[0].replace(' ',''))
contributed_capital.append(message.split('實繳資本')[1].split('人民幣')[0].replace(' ',''))
Approved_date.append(message.split('核準日期')[1].split('\n')[1].replace(' ',''))
try:
credit = message.split('統一社會信用代碼')[1].split('\n')[1].replace(' ','')
Unified_social_credit_code.append(credit)
except:
credit = message.split('統一社會信用代碼')[3].split('\n')[1].replace(' ','')
Unified_social_credit_code.append(credit)
Organization_Code.append(message.split('組織機構代碼')[1].split('\n')[1].replace(' ',''))
companyNo.append(message.split('工商注冊號')[1].split('\n')[1].replace(' ',''))
Taxpayer_Identification_Number.append(message.split('納稅人識別號')[1].split('\n')[1].replace(' ',''))
try:
sub = message.split('所屬行業')[1].split('\n')[1].replace(' ','')
sub_Industry.append(sub)
except:
sub = message.split('所屬行業')[1].split('為')[1].split(',')[0]
sub_Industry.append(sub)
enterprise_type.append(message.split('企業型別')[1].split('\n')[1].replace(' ',''))
Business_Term.append(message.split('營業期限')[1].split('登記機關')[0].split('\n')[-1].replace(' ',''))
Registration_Authority.append(message.split('登記機關')[1].split('\n')[1].replace(' ',''))
staff_size.append(message.split('人員規模')[1].split('人')[0].split('\n')[-1].replace(' ',''))
Number_of_participants.append(message.split('參保人數')[1].split('所屬地區')[0].replace(' ','').split('\n')[2])
sub_area.append(message.split('所屬地區')[1].split('\n')[1].replace(' ',''))
try:
adress = message.split('經營范圍')[0].split('企業地址')[1].split('查看地圖')[0].split('\n')[2].replace(' ','')
company_adress.append(adress)
except:
adress = message.split('經營范圍')[1].split('企業地址')[1].split()[0]
company_adress.append(adress)
Business_Scope.append(message.split('經營范圍')[1].split('\n')[1].replace(' ',''))
df = pd.DataFrame({'公司':company,\
'登記狀態':Registration_status,\
'成立日期':Date_of_Establishment,\
'注冊資本':registered_capital,\
'實繳資本':contributed_capital,\
'核準日期':Approved_date,\
'統一社會信用代碼':Unified_social_credit_code,\
'組織機構代碼':Organization_Code,\
'工商注冊號':companyNo,\
'納稅人識別號':Taxpayer_Identification_Number,\
'所屬行業':sub_Industry,\
'企業型別':enterprise_type,\
'營業期限':Business_Term,\
'登記機關':Registration_Authority,\
'人員規模':staff_size,\
'參保人數':Number_of_participants,\
'所屬地區':sub_area,\
'企業地址':company_adress,\
'經營范圍':Business_Scope})
return df
# 測驗所用
companys = ['深圳市騰訊計算機系統有限公司','阿里巴巴(中國)有限公司']
# 實際所用
# df_companys = pd.read_csv('自己目錄的絕對路徑/某某.csv')
# companys = df_companys['公司名稱'].tolist()
for company in companys:
try:
messages = get_company_message(company)
except:
pass
else:
df = message_to_df(messages,company)
if(company==companys[0]):
df.to_csv('自己目錄的絕對路徑/某某.csv',index=False,header=True)
else:
df.to_csv('自己目錄的絕對路徑/某某.csv',mode='a+',index=False,header=False)
time.sleep(1)
注明:轉載需注明本原地址鏈接,利用代碼進行非法行為與本人無關,
(一經發現有人直接復制粘貼,請大家幫忙舉報一下,上次那篇Selenium的博客被人直接復制粘貼拿去發表了,居然閱讀量比我的還高,要不是有粉絲跟我說我還不知道,真的是)
創作不易啊,如果大家覺得這個筆記對你們有用的,麻煩幫忙點個贊加關注哦,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230304.html
標籤:python
上一篇:PAT (Basic Level) Practice 1035 插入與歸并 (25分) Python非遞回實作(測驗點2有坑)