手寫演算法-Python代碼實作非線性回歸
- 生成非線性資料集
- 1、用線性回歸擬合
- 2、多項式擬合
- sklearn實作,校驗系數的結果
- 總結
生成非線性資料集
前面我們介紹了Python代碼實作線性回歸,今天,我們來聊一聊當資料呈現非線性時,這時我們繼續用線性運算式去擬合,顯然效果會很差,那我們該怎么處理?繼續上實體(我們的代碼里用到的資料集盡量直接由Python生成,因此,是可以全部跑通的,有需要的同學,建議大家粘貼復現一下,多思考,多動手,才可以學的更好,)
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號
#生成如下資料集
a= np.arange(1,11)
b=np.array([4500,5000,6000,8000,11000,15000,20000,30000,50000,100000])
data = np.c_[a,b]
#給x,y分別添加維度
x = data[:,0,np.newaxis]
y=data[:,1,np.newaxis]
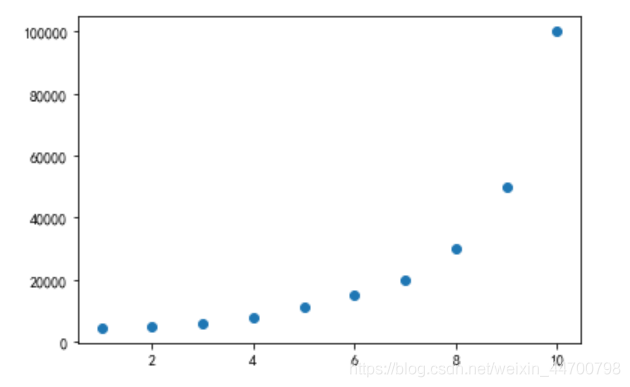
plt.scatter(x,y)
plt.show()
1、用線性回歸擬合
資料的分布如上圖所示,這時候如果繼續使用線性回歸去擬合,這里繼續使用上篇文章Python手寫的類,和sklearn里面實作是一樣的,
鏈接: 手寫演算法-Python代碼推廣多元線性回歸
class normal():
def __init__(self):
pass
def fit(self,x,y):
m=x.shape[0]
X = np.concatenate((np.ones((m,1)),x),axis=1)
xMat=np.mat(X)
yMat=yMat =np.mat(y.reshape(-1,1))
xTx=xMat.T*xMat
#xTx.I為xTx的逆矩陣
ws=xTx.I*xMat.T*yMat
return ws
model=normal()
w = model.fit(x,y)
#生成2個點畫圖
x_test=np.array([[1],[10]])
y_test = w[0] + x_test * w[1]
ax1= plt.subplot()
ax1.plot(x_test,y_test,c='r',label='線性回歸擬合線')
ax1.scatter(x,y,c='b',label='真實分布')
ax1.legend()
plt.show()
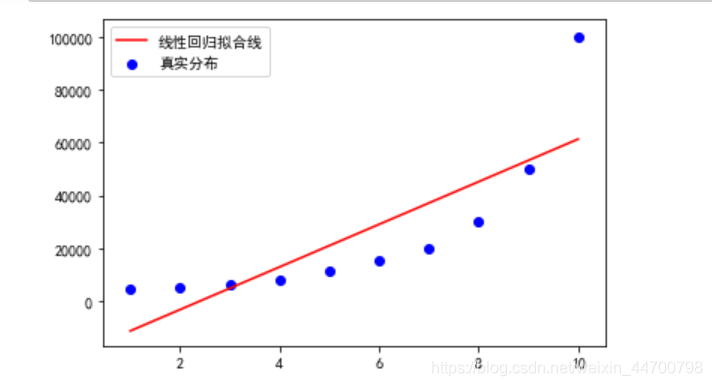
可以看出擬合的效果很差,這里如果用
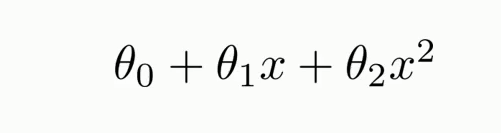
這種運算式去擬合應該會更好
2、多項式擬合
這里和大家介紹一個
#生成多項式
from sklearn.preprocessing import PolynomialFeatures
實作的功能是給X增加維度,具體的可以看官網或者看看我的這篇文章,里面有實作的原理決議,看一下明白了,
鏈接: 代碼系列-python實作PolynomialFeatures(多項式)
我們繼續用Python實作:
def multi_feature(x,n):
c = np.empty((x.shape[0],0)) #np.empty((3,1))并不會生成一個3行1列的空陣列,np.empty((3,0))才會生成3行1列空陣列
for i in range(n+1):
h=x**i
c=np.c_[c,h]
return c
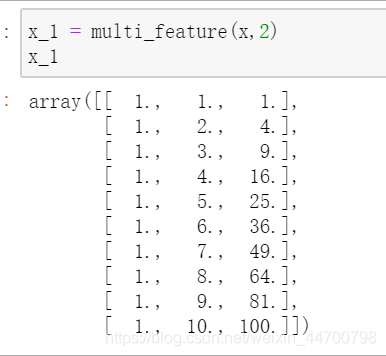
#先設定n=2
x_1 = multi_feature(x,2)
x_1 #輸出變化后的x
model=normal()
#用新生成的x作為輸入
w = model.fit(x_1,y)
報錯了!!!
LinAlgError: Singular matrix
這個錯誤代表在對numpy的矩陣用np.linalg.inv方法時報錯,也就是無法求逆矩陣,難道要屈服用sklearn嗎?
不行!!
第一時間回傳去看我們寫的類,破案了!問題很簡單,python寫的類里面,我們給x添加了偏置,在這個生成的多項式x_1中,本身就有一列1,這樣的話就有2列1,變成了一個非滿秩矩陣,因此不需要再添加偏置,修改代碼如下:
class normal():
def __init__(self):
pass
def fit(self,x,y):
#x_1中已經生成了一列1,不需要再加偏置,因此注釋掉這2列,
#m=x.shape[0]
#X = np.concatenate((np.ones((m,1)),x),axis=1)
xMat=np.mat(x)
yMat=yMat =np.mat(y.reshape(-1,1))
xTx=xMat.T*xMat
#xTx.I為xTx的逆矩陣
ws=xTx.I*xMat.T*yMat
return ws
model=normal()
#用新生成的x作為輸入
w = model.fit(x_1,y)
w
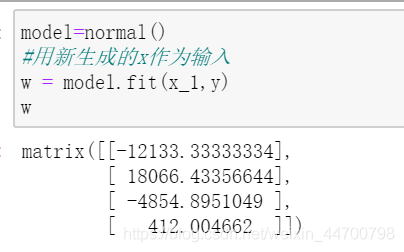
這次沒有問題了,(為了檢查引數是否正確,我又馬上呼叫了sklearn來跑了一遍,先透露結論:系數沒錯,后面上sklearn的結果)
畫圖看這次的擬合效果:
#計算x_1的擬合效果,下面是矩陣乘法
y_1 = np.dot(x_1,w)
ax1= plt.subplot()
ax1.plot(x,y_1,c='r',label='n=2時,擬合效果圖')
ax1.scatter(x,y,c='b',label='真實分布圖')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
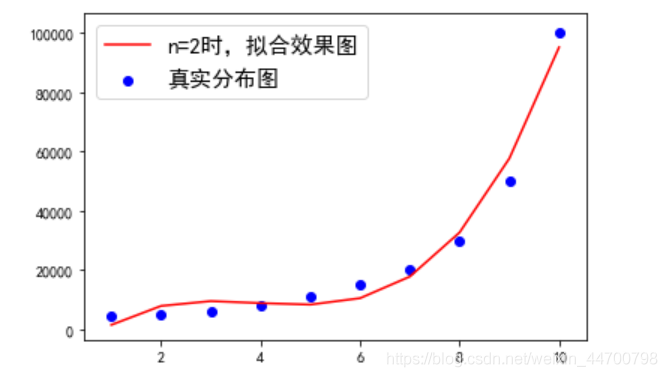
效果好很多了,設定n=5
#設定n=5
x_2 = multi_feature(x,5)
model=normal()
#用新生成的x_2作為輸入,重新擬合
w = model.fit(x_2,y)
#計算x_2的擬合效果,下面是矩陣乘法
y_2 = np.dot(x_2,w)
ax1= plt.subplot()
ax1.plot(x,y_2,c='r',label='n=5時,擬合效果圖')
ax1.scatter(x,y,c='b',label='真實分布圖')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
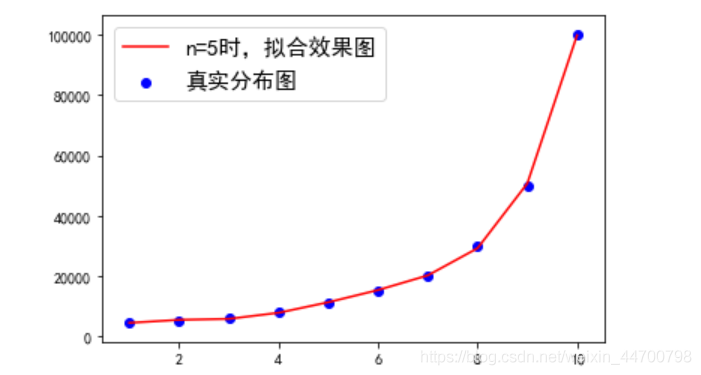
已經很完美了,由于點太少,顯得擬合曲線不是那么平滑,多傳入一些x值,
x_test = np.linspace(1,10,100)
x_3 = multi_feature(x_test,5)
#生成預測值y_3
y_3 = np.dot(x_3,w)
ax1= plt.subplot()
ax1.plot(x_test,y_3,c='r',label='n=5時,擬合效果圖')
ax1.scatter(x,y,c='b',label='真實分布圖')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
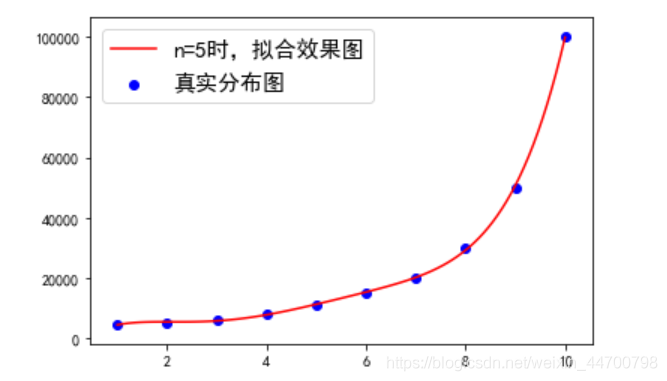
sklearn實作,校驗系數的結果
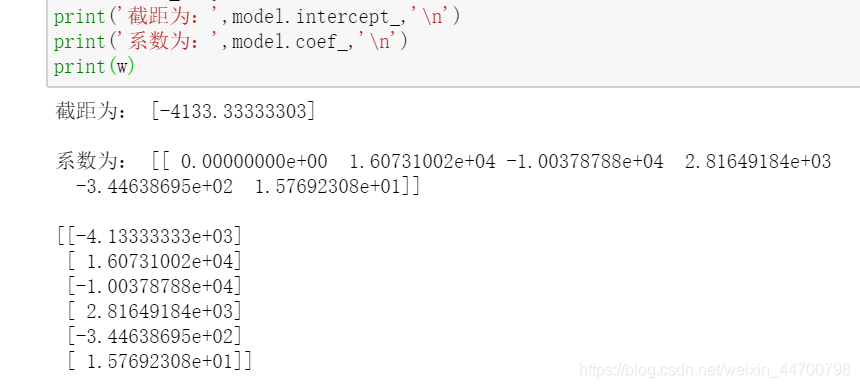
最后附上sklearn檢驗系數的結果,完全一樣的:
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_2, y)
print('截距為:',model.intercept_,'\n')
print('系數為:',model.coef_,'\n')
print(w)
總結
1、這篇文章主要告訴我們,做回歸模型時,要了解資料,不能上來就呼叫sklearn里面的線性回歸包,要根據資料的分布,選擇合適的演算法包,有時候還要對X特征進行一些預處理作業,
2、平時做機器學習還是調包,因為自己寫的有很多不足的地方,且很難做到推廣,但是,學習的程序中,還是建議多研究一下原理,這樣可以走得更遠,
3、大家有什么問題需要交流,我一定知無不言,期待一起進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230307.html
標籤:python
上一篇:構建決策樹時出現ValueError: Length of feature_names, 4 does not match number of features, 10的解決辦法