宣告:本專案僅供學習使用,不會對網站造成影響,
最近閑來無事,發現有段時間沒有寫博客了,于是就找個一個動漫圖片網站來寫寫,
**難度低,適合新手練習========================**
網站網址:傳送門
我們要爬取的頁面是榜單,
第一步
打開F12,分析請求網址,
在XHR中可以很快找到網站用來存放圖片資訊的介面網址,

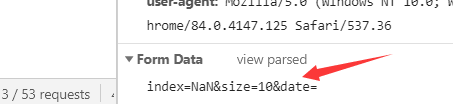
我們可以很直接的看出這個介面為post請求,并且有一段需要拼接的FormData內容,
這里博主還發現了這個網頁的Request header中有一段很長的Cookie,但是我們還是先用requests庫去請求一下再說,
import requests
start_url = 'https://rt.huashi6.com/front/works/rank_page?index=NaN&size=10&date='
data = requests.post(start_url)
print(data.text)
運行后發現能夠回傳正確的內容
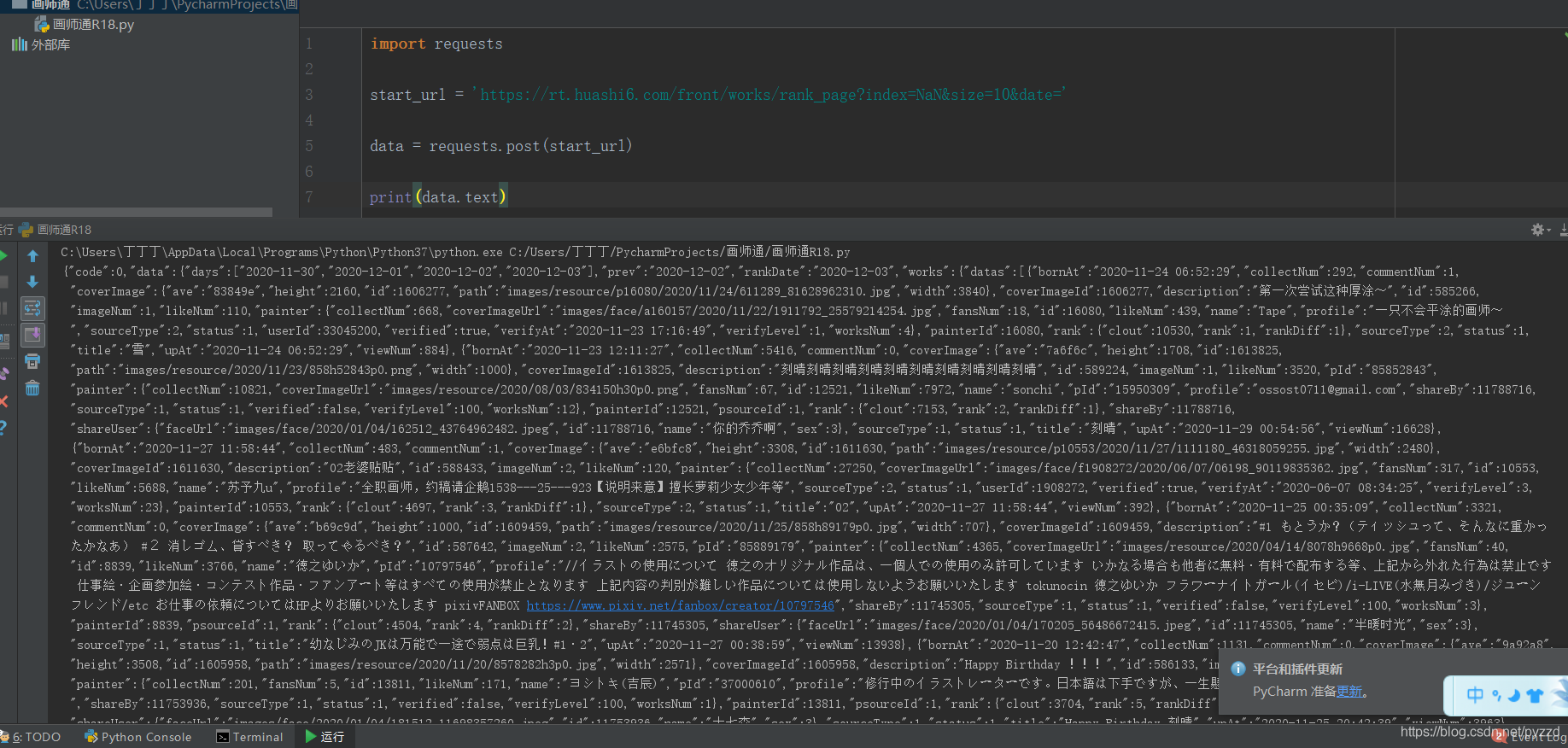
這就說明這個網站不需要添加請求頭,cookie并沒有反爬的作用,
第二步:決議
我們這次要獲取的資料為
1,圖片地址
2,圖片標題
3,作者(爬取圖片,視頻內容時建議要獲取作者)
雖然獲取到的資料格式為Json,但是這里我還是選擇使用正則,別問為什么,就是懶,
author_list = re.findall(r'"name":"(.*?)"',data.text)
url_list = re.findall(r'"path":"(.*?)"',data.text)
title_list = re.findall(r'"title":"(.*?)"',data.text)
這時候我們就獲取到了圖片的作者,鏈接,標題,
這里要注意,我們獲取到的圖片鏈接是不全的,我們要把它拼接成完整的,
for author,url,title in zip(author_list,url_list,title_list):
url = 'https://img2.huashi6.com/{}'.format(url)
拼接好鏈接,我們就可以去請求啦,
pic_data = requests.get(url).content
因為圖片為流媒體檔案,所以這里我們使用的是content,將它轉為二進制,
存盤
將獲取到的圖片資訊存到檔案夾里面,
我們使用的是with open來讀寫檔案,
我們可以直接在專案目錄下新建一個檔案夾來存放檔案,也可以在任何地方-如:D://data//xx, 只是如果不在專案檔案中我們就要使用絕對路徑,
with open('data/{}by{}.jpg'.format(title,author),'wb')as f:
f.write(pic_data)
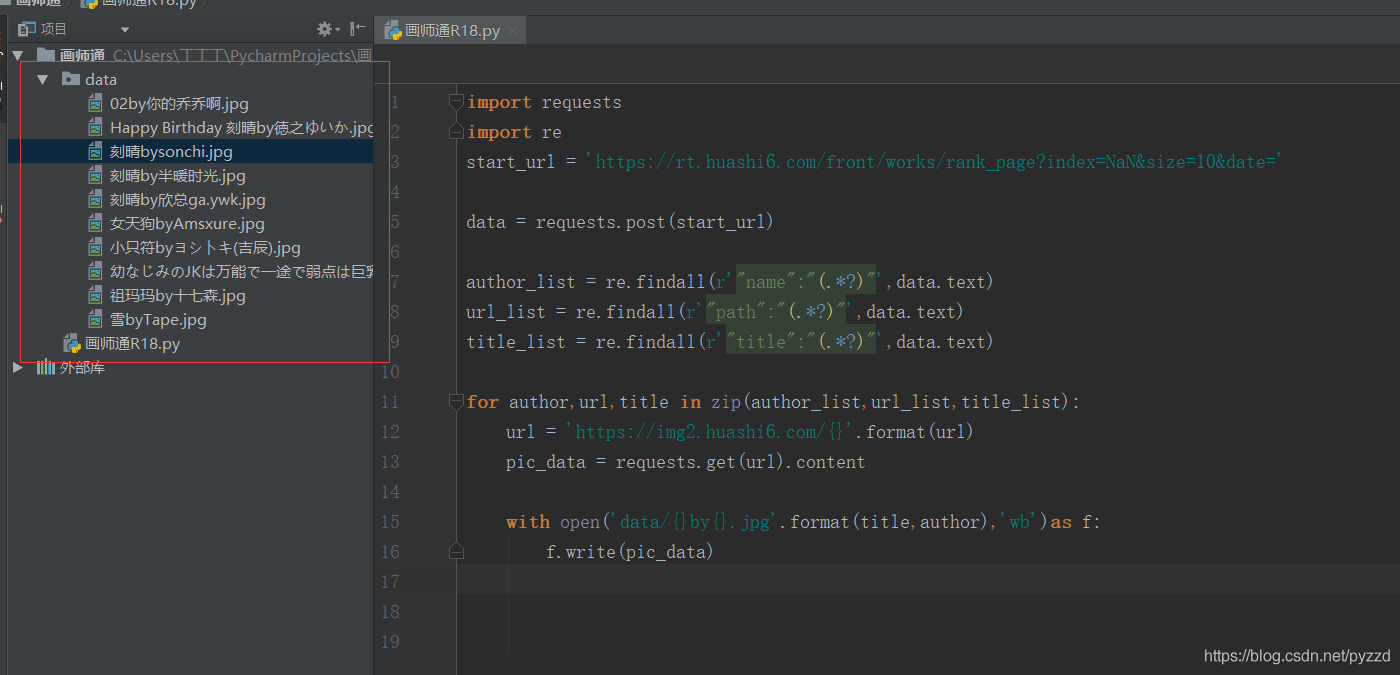
這里我將圖片標題與作者名拼接起來,作為圖片的名稱,
點開圖片查看,二次元老婆果然完好無損的被我們存入檔案夾里面了,
但是我們發現,我們獲取到的只有幾張圖片,
回到網站,發現網站是以下拉的形式加載圖片的,
簡單哦,還是打開F12-XHR,然后我們往下拉,
發現多出來了幾個網址,沒錯,這就是滑動后的網址,
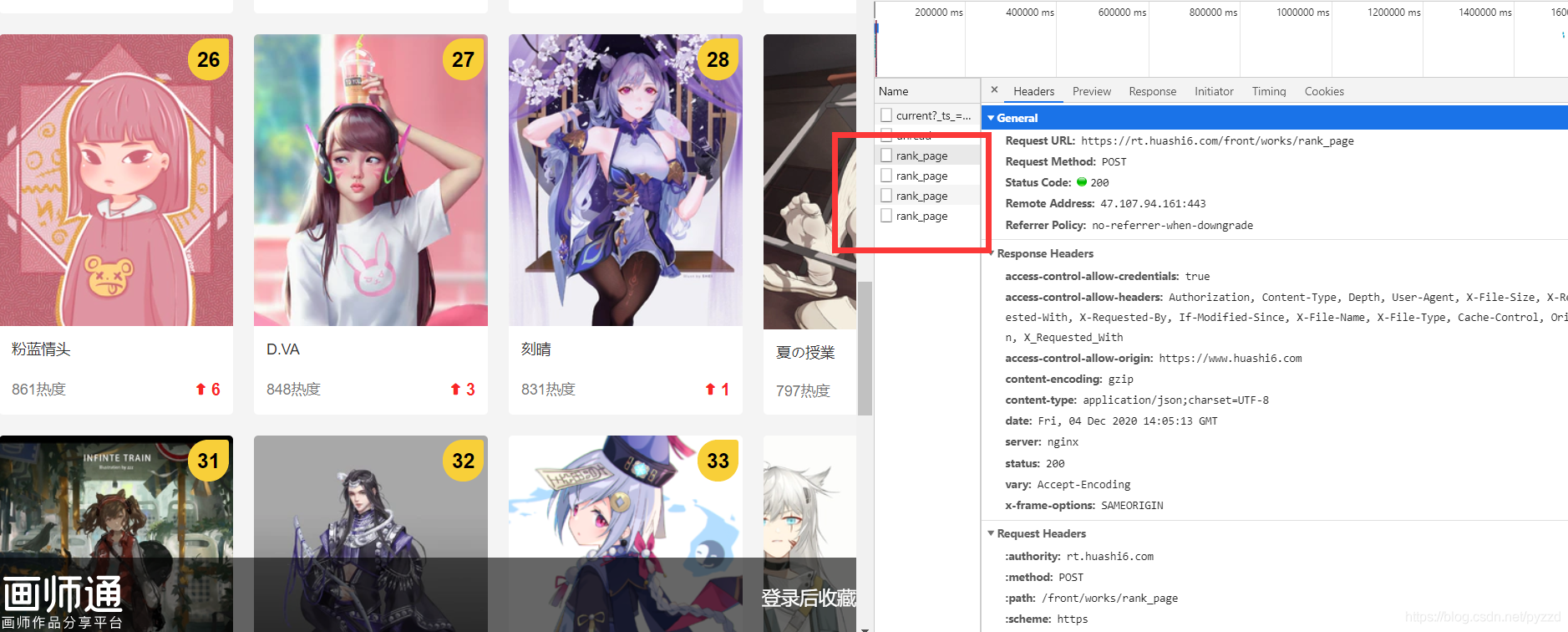
分析網址,明顯發現FormData里面的index引數發生了變化,我們每翻一頁它就會加一,起始為1,最大為5,
‘’‘https://rt.huashi6.com/front/works/rank_page?index=2&size=10&date=2020-12-02
https://rt.huashi6.com/front/works/rank_page?index=3&size=10&date=2020-12-02’‘’
滑動到底部,發現這個網站是由日期分頁,一樣的方法,
這個網站沒有當天的圖片,所以我們只獲取前三天的日期,
一個嵌套for回圈搞定
但是運行的時候我發現一個問題,作者名可能包含特殊符號,這會導致我們讀寫檔案時出錯,所以我就寫了一個例外處理,跳過這類資訊,
import datetime
import requests
import re
days = 4 #獲取最近幾天的日期
today = datetime.datetime.now()
for day in range(1,days):
offset = datetime.timedelta(days=-day)
day_date = (today + offset).strftime('%Y-%m-%d') # 這段為獲取當前日期前三天的日期
for i in range(6): #向下滑動5頁
start_url = 'https://rt.huashi6.com/front/works/rank_page?index={}&size=10&date={}'.format(i,day_date)
data = requests.post(start_url)
author_list = re.findall(r'"name":"(.*?)"', data.text)
url_list = re.findall(r'"path":"(.*?)"', data.text)
title_list = re.findall(r'"title":"(.*?)"', data.text)
for author, url, title in zip(author_list, url_list, title_list):
url = 'https://img2.huashi6.com/{}'.format(url)
pic_data = requests.get(url).content
try:
with open('data/{}by{}.jpg'.format(title, author), 'wb')as f:
f.write(pic_data)
except:
pass
運行之后,代碼沒有問題,我們的二次元老婆多了起來,
這里就是完整代碼了,很簡單的一個小專案,沒有涉及到難點,但是也有很多坑需要避免的,非常適合新手,
喜歡爬蟲的朋友可以私聊我加個好友交流一下,新手有問題的話可以直接問我,有逆向高手的話也可以一起做做專案,
代碼有問題可以及時聯系我

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230728.html
標籤:python
上一篇:廣度優先bfs的python實作
下一篇:力扣7.整數反轉