Dict在redis中是最為核心的一個資料結構,因為它承載了redis里的所有資料,你可以簡單粗暴的認為redis就是一個大的dict,里面存盤的所有的key-value,
redis中dict的本質其實就是一個hashtable,所以它也需要考慮所有hashtable所有的問題,如何組織K-V、如何處理hash沖突、擴容策略及擴容方式……,實際上Redis中hashtable的實作方式就是普通的hashtable,但Redis創新的引入了漸進式hash以減小hashtable擴容是對性能帶來的影響,接下來我們就來看看redis中hashtable的具體實作,
Redis中Dict的實作
dict的定義在dict.h中,其各個欄位及其含義如下:
typedef struct dict {
dictType *type; // dictType結構的指標,封裝了很多資料操作的函式指標,使得dict能處理任意資料型別(類似面向物件語言的interface,可以多載其方法)
void *privdata; // 一個私有資料指標(privdata),由呼叫者在創建dict的時候傳進來,
dictht ht[2]; // 兩個hashtable,ht[0]為主,ht[1]在漸進式hash的程序中才會用到,
long rehashidx; /* 增量hash程序程序中記錄rehash執行到第幾個bucket了,當rehashidx == -1表示沒有在做rehash */
unsigned long iterators; /* 正在運行的迭代器數量 */
} dict;
重點介紹下dictType *type欄位(個人感覺命名為type不太合適),其作用就是為了讓dict支持各種資料型別,因為不同的資料型別需要對應不同的操作函式,比如計算hashcode 字串和整數的計算方式就不一樣, 所以dictType通過函式指標的方式,將不同資料型別的操作都封裝起來,從面相物件的角度來看,可以把dictType當成dict中各種資料型別相關操作的interface,各個資料型別只需要實作其對應的資料操作就行, dictType中封裝了以下幾個函式指標,
typedef struct dictType {
uint64_t (*hashFunction)(const void *key); // 對key生成hash值
void *(*keyDup)(void *privdata, const void *key); // 對key進行拷貝
void *(*valDup)(void *privdata, const void *obj); // 對val進行拷貝
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 兩個key的對比函式
void (*keyDestructor)(void *privdata, void *key); // key的銷毀
void (*valDestructor)(void *privdata, void *obj); // val的銷毀
} dictType;
dict中還有另外一個重要的欄位dictht ht[2],dictht其實就是hashtable,但這里為什么是ht[2]? 這就不得不提到redis dict的漸進式hash,dict的hashtable的擴容不是一次性完成的,它是先建立一個大的新的hashtable存放在ht[1]中,然后逐漸把ht[0]的資料遷移到ht[1]中,rehashidx就是ht[0]中資料遷移的進度,漸進式hash的程序會在后文中詳解,
這里我們來看下dictht的定義:
typedef struct dictht {
dictEntry **table; // hashtable中的連續空間
unsigned long size; // table的大小
unsigned long sizemask; // hashcode的掩碼
unsigned long used; // 已存盤的資料個數
} dictht;
其中dictEntry就是對dict中每對key-value的封裝,除了具體的key-value,其還包含一些其他資訊,具體如下:
typedef struct dictEntry {
void *key;
union { // dictEntry在不同用途時存盤不同的資料
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // hash沖突時開鏈,單鏈表的next指標
} dictEntry;
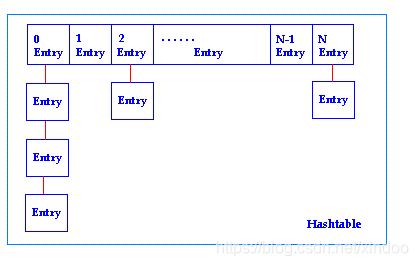
dict中的hashtable在出現hash沖突時采用的是開鏈方式,如果有多個entry落在同一個bucket中,那么他們就會串成一個單鏈表存盤,
如果我們將dict在記憶體中的存盤繪制出來,會是下圖這個樣子,
擴容
在看dict幾個核心API實作之前,我們先來看下dict的擴容,也就是redis的漸進式hash, 何為漸進式hash?redis為什么采用漸進式hash?漸進式hash又是如何實作的?
要回答這些問題,我們先來考慮下hashtable擴容的程序,如果熟悉java的同學可能知道,java中hashmap的擴容是在資料元素達到某個閾值后,新建一個更大的空間,一次性把舊資料搬過去,搬完之后再繼續后續的操作,如果資料量過大的話,HashMap擴容是非常耗時的,所有有些編程規范推薦new HashMap時最好指定其容量,防止出現自動擴容,
但是redis在新建dict的時候,沒法知道資料量大小,如果直接采用java hashmap的擴容方式,因為redis是單執行緒的,勢必在擴容程序中啥都干不了,阻塞掉后面的請求,最終影響到整個redis的性能,如何解決? 其實也很簡單,就是化整為零,將一次大的擴容操作拆分成多次小的步驟,一步步來減少擴容對其他操作的影響,其具體實作如下:
上文中我們已經看到了在dict的定義中有個dictht ht[2],dict在擴容程序中會有兩個hashtable分別存盤在ht[0]和ht[1]中,其中ht[0]是舊的hashtable,ht[1]是新的更大的hashtable,
/* 檢查是否dict需要擴容 */
static int _dictExpandIfNeeded(dict *d)
{
/* 已經在漸進式hash的流程中了,直接回傳 */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* 當配置了可擴容時,容量負載達到100%就擴容,配置不可擴容時,負載達到5也會強制擴容*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); // 擴容一倍容量
}
return DICT_OK;
}
Redis在每次查找某個key的索引下標時都會檢查是否需要對ht[0]做擴容,如果配置的是可以擴容 那么當hashtable使用率超過100%(uesed/size)就觸發擴容,否則使用率操作500%時強制擴容,執行擴容的代碼如下:
/* dict的創建和擴容 */
int dictExpand(dict *d, unsigned long size)
{
/* 如果size比hashtable中的元素個數還小,那size就是無效的,直接回傳error */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* 新的hashtable */
// 擴容時新table容量是大于當前size的最小2的冪次方,但有上限
unsigned long realsize = _dictNextPower(size);
// 如果新容量和舊容量一致,沒有必要繼續執行了,回傳err
if (realsize == d->ht[0].size) return DICT_ERR;
/* 新建一個容量更大的hashtable */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// 如果是dict初始化的情況,直接把新建的hashtable賦值給ht[0]就行
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// 非初始化的情況,將新表賦值給ht[1], 然后標記rehashidx 0
d->ht[1] = n;
d->rehashidx = 0; // rehashidx表示當前rehash到ht[0]的下標位置
return DICT_OK;
}
這里dictExpand只是創建了新的空間,將rehashidx標記為0(rehashidx==-1表示不在rehash的程序中),并未對ht[0]中的資料遷移到ht[1]中,資料遷移的邏輯都在_dictRehashStep()中, _dictRehashStep()是只遷移一個bucket,它在dict的查找、插入、洗掉的程序中都會被調到,每次呼叫至少遷移一個bucket, 而dictRehash()是_dictRehashStep()的具體實作,代碼如下:
/* redis漸進式hash,采用分批的方式,逐漸將ht[0]依下標轉移到ht[2],避免了hashtable擴容時大量
* 資料遷移導致的性能問題
* 引數n是指這次rehash只做n個bucket */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* 最大空bucket數量,如果遇到empty_visits個空bucket,直接結束當前rehash的程序 */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1; // 如果遇到了empty_visits個空的bucket,直接結束
}
// 遍歷當前bucket中的鏈表,直接將其移動到新的hashtable中
de = d->ht[0].table[d->rehashidx];
/* 把所有的key從舊的hash桶移到新的hash桶中 */
while(de) {
uint64_t h;
nextde = de->next;
/* 獲取到key在新hashtable中的下標 */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* 檢測是否已對全表做完了rehash */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table); // 釋放舊ht所占用的記憶體空間
d->ht[0] = d->ht[1]; // ht[0]始終是在用ht,ht[1]始終是新ht,ht0全遷移到ht1后會交換下
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0; // 如果全表hash完,回傳0
}
/* 還需要繼續做hash回傳1 */
return 1;
}
可以看出,rehash就是分批次把ht[0]中的資料搬到ht[1]中,這樣將原有的一個大操作拆分為很多個小操作逐步進行,避免了redis發生dict擴容是瞬時不可用的情況,缺點是在redis擴容程序中會占用倆份存盤空間,而且占用時間會比較長,
核心API
插入
/* 向dict中添加元素 */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
//
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
/* 添加和查找的底層實作:
* 這個函式只會回傳key對應的entry,并不會設定key對應的value,而是把設值權交給呼叫者,
*
* 這個函式也作為一個API直接暴露給用戶呼叫,主要是為了在dict中存盤非指標類的資料,比如
* entry = dictAddRaw(dict,mykey,NULL);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* 回傳值:
* 如果key已經存在于dict中了,直接回傳null,并把已經存在的entry指標放到&existing里,否則
* 為key新建一個entry并回傳其指標,
*/
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 獲取到新元素的下標,如果回傳-1標識該元素已經存在于dict中了,直接回傳null */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* 否則就給新元素分配記憶體,并將其插入到鏈表的頭部(一般新插入的資料被訪問的頻次會更高)*/
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* 如果是新建的entry,需要把key填進去 */
dictSetKey(d, entry, key);
return entry;
}
插入程序也比較簡單,就是先定位bucket的下標,然后插入到單鏈表的頭節點,注意這里也需要考慮到rehash的情況,如果是在rehash程序中,新資料一定是插入到ht[1]中的,
查找
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (dictSize(d) == 0) return NULL; /* dict為空 */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
// 查找的程序中,可能正在rehash中,所以新老兩個hashtable都需要查
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果ht[0]中沒找到,且不再rehas中,就不需要繼續找了ht[1]了,
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
查找的程序比較簡單,就是用hashcode做定位,然后遍歷單鏈表,但這里需要考慮到如果是在rehash程序中,可能需要查找ht[2]中的兩個hashtable,
洗掉
/* 查找并洗掉一個元素,是dictDelete()和dictUnlink()的輔助函式,*/
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
// 這里也是需要考慮到rehash的情況,ht[0]和ht[1]中的資料都要洗掉掉
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* 從串列中unlink掉元素 */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
// 如果nofree是0,需要釋放k和v對應的記憶體空間
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return NULL; /* 沒找到key對應的資料 */
}
其它API
其他的API實作都比較簡單,我在dict.c原始碼中做了大量的注釋,有興趣可以自行閱讀下,我這里僅列舉并說明下其大致的功能,
dict *dictCreate(dictType *type, void *privDataPtr); // 創建dict
int dictExpand(dict *d, unsigned long size); // 擴縮容
int dictAdd(dict *d, void *key, void *val); // 添加k-v
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing); // 添加的key對應的dictEntry
dictEntry *dictAddOrFind(dict *d, void *key); // 添加或者查找
int dictReplace(dict *d, void *key, void *val); // 替換key對應的value,如果沒有就添加新的k-v
int dictDelete(dict *d, const void *key); // 洗掉某個key對應的資料
dictEntry *dictUnlink(dict *ht, const void *key); // 卸載某個key對應的entry
void dictFreeUnlinkedEntry(dict *d, dictEntry *he); // 卸載并清除key對應的entry
void dictRelease(dict *d); // 釋放整個dict
dictEntry * dictFind(dict *d, const void *key); // 資料查找
void *dictFetchValue(dict *d, const void *key); // 獲取key對應的value
int dictResize(dict *d); // 重設dict的大小,主要是縮容用的
/************ 迭代器相關 *********** */
dictIterator *dictGetIterator(dict *d);
dictIterator *dictGetSafeIterator(dict *d);
dictEntry *dictNext(dictIterator *iter);
void dictReleaseIterator(dictIterator *iter);
/************ 迭代器相關 *********** */
dictEntry *dictGetRandomKey(dict *d); // 隨機回傳一個entry
dictEntry *dictGetFairRandomKey(dict *d); // 隨機回傳一個entry,但回傳每個entry的概率會更均勻
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count); // 獲取dict中的部分資料
其他的API見代碼dict.c和dict.h.
本文是Redis原始碼剖析系列博文,同時也有與之對應的Redis中文注釋版,有想深入學習Redis的同學,歡迎star和關注,
Redis中文注解版倉庫:https://github.com/xindoo/Redis
Redis原始碼剖析專欄:https://zxs.io/s/1h
如果覺得本文對你有用,歡迎一鍵三連,
本文來自https://blog.csdn.net/xindoo
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/230877.html
標籤:Java
上一篇:自增運算子
下一篇:SpringCloud入門