手寫演算法-python代碼實作Ridge回歸
- Ridge簡介
- Ridge回歸分析與python代碼實作
- 方法一:梯度下降法求解Ridge回歸引數
- 方法二:標準方程法實作Ridge回歸
- 呼叫sklearn對比
Ridge簡介
前面2篇文章,我們介紹了過擬合與正則化,比較全面的講了L1、L2正則化的原理與特點;
鏈接: 原理決議-過擬合與正則化
以及python代碼實作Lasso回歸;
鏈接: 手寫演算法-python代碼實作Lasso回歸
今天,我們在這基礎上,講一講Ridge回歸,就比較簡單了,
本文主要實作python代碼的Ridge回歸(帶L2正則項),并用實體佐證原理,
Ridge回歸分析與python代碼實作
參考上篇文章的生成的資料集:
import numpy as np
from matplotlib import pyplot as plt
import sklearn.datasets
#生成100個一元回歸資料集
x,y = sklearn.datasets.make_regression(n_features=1,noise=5,random_state=2020)
plt.scatter(x,y)
plt.show()
#加5個例外資料,為什么這么加,大家自己看一下生成的x,y的樣子
a = np.linspace(1,2,5).reshape(-1,1)
b = np.array([350,380,410,430,480])
#生成加入例外資料后新的資料集
x_1 = np.r_[x,a]
y_1 = np.r_[y,b]
plt.scatter(x_1,y_1)
plt.show()
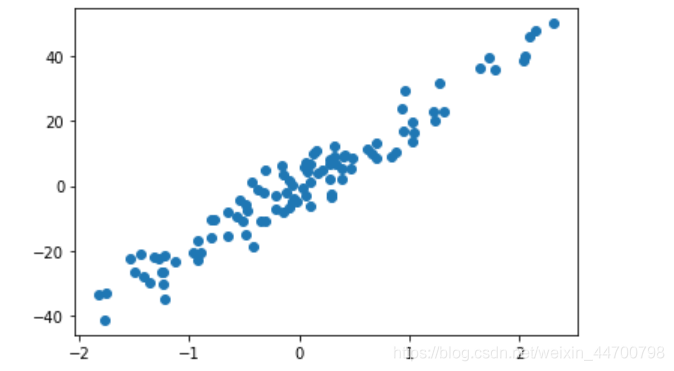
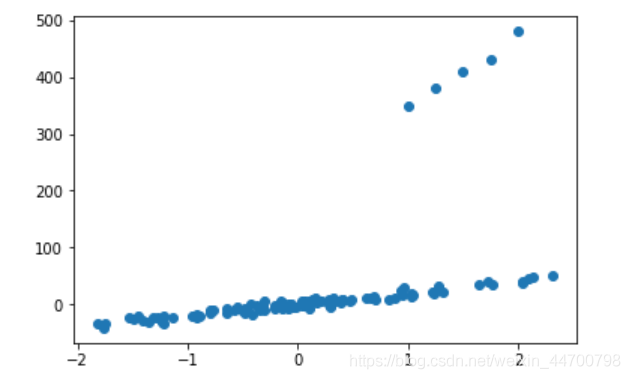
以上分別是正常資料集和加入了5個例外資料的影像,如果直接用線性回歸擬合:
class normal():
def __init__(self):
pass
def fit(self,x,y):
m=x.shape[0]
X = np.concatenate((np.ones((m,1)),x),axis=1)
xMat=np.mat(X)
yMat =np.mat(y.reshape(-1,1))
xTx=xMat.T*xMat
#xTx.I為xTx的逆矩陣
ws=xTx.I*xMat.T*yMat
#回傳引數
return ws
plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus']=False #用來正常顯示負號
clf1 =normal()
#擬合原始資料
w1 = clf1.fit(x,y)
#預測資料
y_pred = x * w1[1] + w1[0]
#擬合新資料
w2 = clf1.fit(x_1,y_1)
#預測資料
y_1_pred = x_1 * w2[1] + w2[0]
print('原始樣本擬合引數:\n',w1)
print('\n')
print('新樣本擬合引數:\n',w2)
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='樣本分布')
ax1.plot(x,y_pred,c='y',label='原始樣本擬合')
ax1.plot(x_1,y_1_pred,c='r',label='新樣本擬合')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
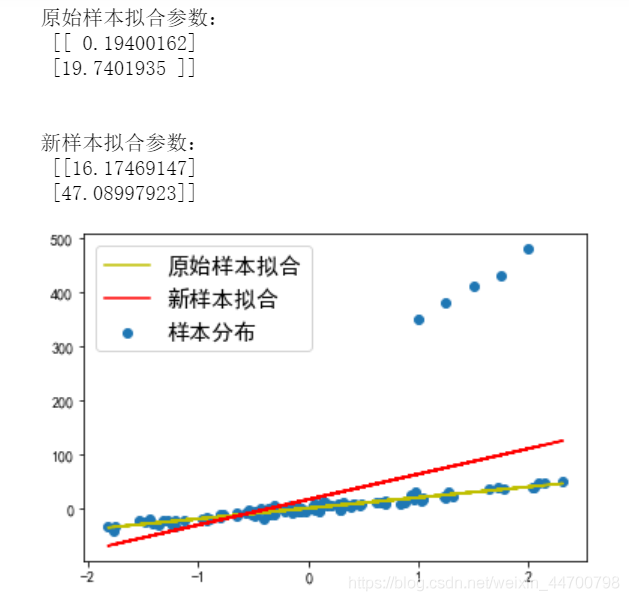
因為幾個例外點資料,新的擬合回歸線引數變大了很多,從19點多變成了47點多;脫離了實際資料的分布,模型性能下降,
我們加入L2正則項,來調優模型,下面是L2正則化的損失函式;
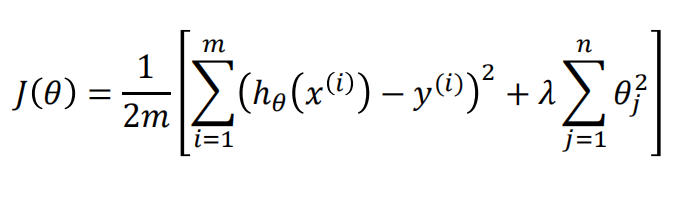
方法一:梯度下降法求解Ridge回歸引數
前面文章我們都推導過線性回歸的梯度和L2正則項的梯度,這個的梯度就是兩者相加,算了,還是寫一下:
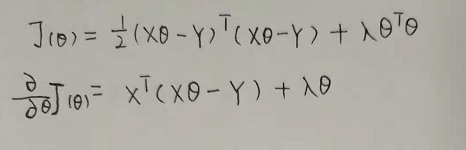
撰寫python代碼如下(就是在原來的線性回歸梯度上,加上L2的梯度):
class ridge():
def __init__(self):
pass
#梯度下降法迭代訓練模型引數,x為特征資料,y為標簽資料,a為學習率,epochs為迭代次數,Lambda為正則項引數
def fit(self,x,y,a,epochs,Lambda):
#計算總資料量
m=x.shape[0]
#給x添加偏置項
X = np.concatenate((np.ones((m,1)),x),axis=1)
#計算總特征數
n = X.shape[1]
#初始化W的值,要變成矩陣形式
W=np.mat(np.ones((n,1)))
#X轉為矩陣形式
xMat = np.mat(X)
#y轉為矩陣形式,這步非常重要,且要是m x 1的維度格式
yMat =np.mat(y.reshape(-1,1))
#回圈epochs次
for i in range(epochs):
gradient = xMat.T*(xMat*W-yMat)/m + Lambda * W
W=W-a * gradient
return W
def predict(self,x,w): #這里的x也要加偏置,訓練時x是什么維度的資料,預測也應該保持一樣
return np.dot(x,w)
ridge()函式來實作我們的Ridge回歸,示例(以下的引數都是我經過除錯,確認可以使模型收斂,繼續加大迭代次數或者改變學習率,最終的模型系數也不改變):
當Lambda引數為0時,也就是不加L2正則項時,就是普通的線性回歸,引數輸出都是一樣的,也是47點多
#Lambda=0時;
clf = ridge()
w = clf.fit(x_1,y_1,a = 0.001,epochs = 10000,Lambda=0)
print(w)
#計算新的擬合值
y_1_pred = x_1 * w[1] + w[0]
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='樣本分布')
ax1.plot(x,y_pred,c='y',label='原始樣本擬合')
ax1.plot(x_1,y_1_pred,c='r',label='新樣本擬合')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
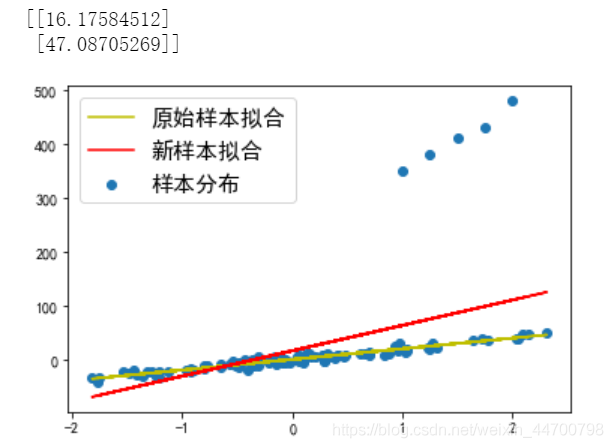
當Lambda =0.5時,引數變為31點多;
#Lambda=0.5時;
clf = ridge()
w = clf.fit(x_1,y_1,a = 0.001,epochs = 10000,Lambda=0.5)
print(w)
#計算新的擬合值
y_1_pred = x_1 * w[1] + w[0]
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='樣本分布')
ax1.plot(x,y_pred,c='y',label='原始樣本擬合')
ax1.plot(x_1,y_1_pred,c='r',label='新樣本擬合')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
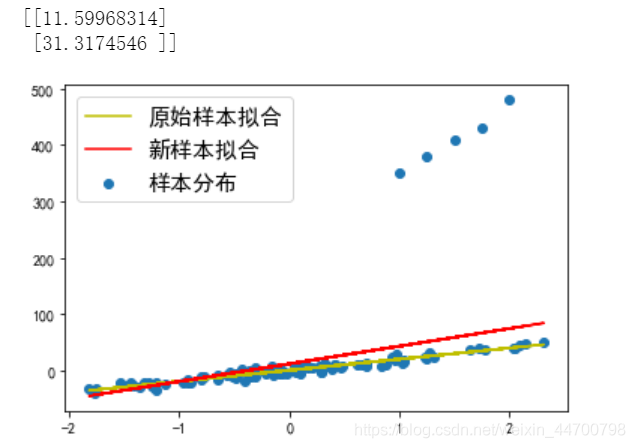
當Lambda =1.5時,引數變為18點多,基本上已經和沒添加例外值的引數是一樣的了;
#Lambda=1.5時;
clf = ridge()
w = clf.fit(x_1,y_1,a = 0.001,epochs = 10000,Lambda=1.5)
print(w)
#計算新的擬合值
y_1_pred = x_1 * w[1] + w[0]
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='樣本分布')
ax1.plot(x,y_pred,c='y',label='原始樣本擬合')
ax1.plot(x_1,y_1_pred,c='r',label='新樣本擬合')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
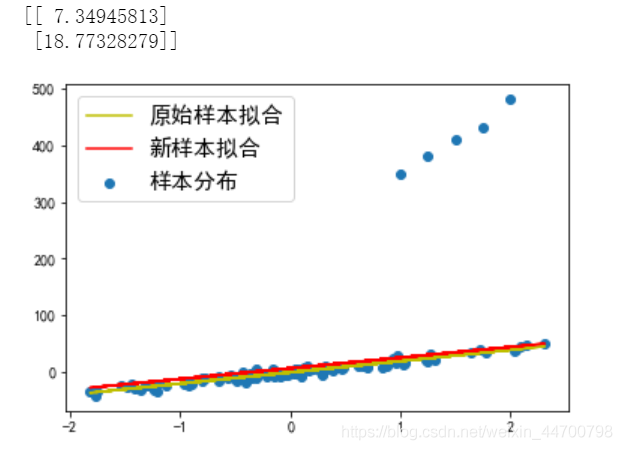
當Lambda =20時,引數是2點多,擬合線差不多就是一條水平線了,此時嚴重欠擬合,損失函式值很大,模型完全沒有收斂;
#Lambda=20時;
clf = ridge()
w = clf.fit(x_1,y_1,a = 0.001,epochs = 10000,Lambda=20)
print(w)
#計算新的擬合值
y_1_pred = x_1 * w[1] + w[0]
ax1= plt.subplot()
ax1.scatter(x_1,y_1,label='樣本分布')
ax1.plot(x,y_pred,c='y',label='原始樣本擬合')
ax1.plot(x_1,y_1_pred,c='r',label='新樣本擬合')
ax1.legend(prop = {'size':15}) #此引數改變標簽字號的大小
plt.show()
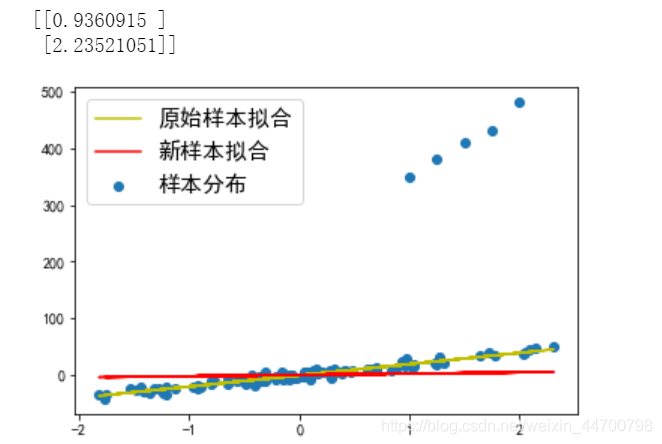
可以發現,合適的L2正則項引數,可以防止過擬合;
當Lambda引數一越來越大時,模型引數也越來越小,慢慢接近于0,
方法二:標準方程法實作Ridge回歸
接下來,我們用標準方程法實作Ridge回歸,推導公式如下:
 python代碼實作如下:
python代碼實作如下:
class standard_ridge():
def __init__(self):
pass
def fit(self,x,y,Lambda):
m = x.shape[0]
X = np.concatenate((np.ones((m,1)),x),axis=1)
xMat= np.mat(X)
yMat = np.mat(y.reshape(-1,1))
xTx = xMat.T * xMat
#生成單位矩陣,2個矩陣行列相等才可以相加
#前面的梯度下降法代碼中,我們沒有省掉m,因此,我們化簡時,也不省掉m,最后形式就是在正則項梯度這里乘以m,其實不會造成本質影響
rxTx = xTx + np.eye(xMat.shape[1]) * Lambda * m
#rxTx.I為rxTx的逆矩陣
w = rxTx.I * xMat.T * yMat
return w
以下是運行結果:
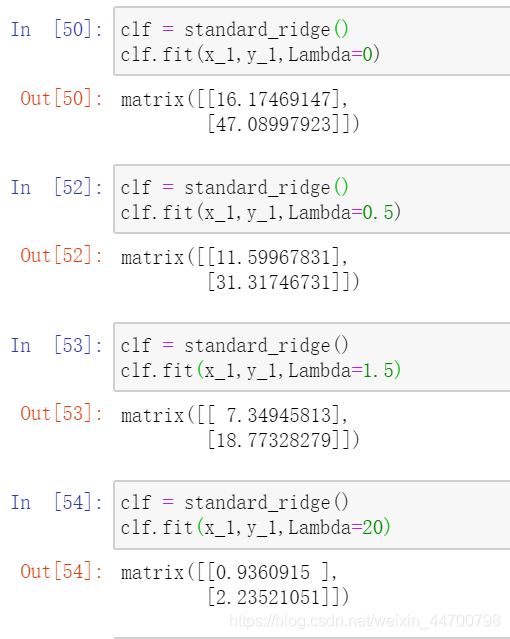
基本上結果一樣,但是這種形式,更簡潔方便一些,
呼叫sklearn對比
from sklearn.linear_model import Ridge
lr=Ridge(alpha=0)
lr.fit(x_1,y_1)
print('alpha=0時',lr.coef_,'\n')
lr=Ridge(alpha=40)
lr.fit(x_1,y_1)
print('alpha=40時',lr.coef_,'\n')
lr=Ridge(alpha=150)
lr.fit(x_1,y_1)
print('alpha=150時',lr.coef_,'\n')
lr=Ridge(alpha=2000)
lr.fit(x_1,y_1)
print('alpha=2000時',lr.coef_)

sklearn展示Ridge:
1、隨著alpha值的增大,也就是正則項系數增大,系數變得越來越接近于0,但是沒有等于0的,
#用波士頓房價回歸資料集展示
data = sklearn.datasets.load_boston()
x =data['data']
y= data['target']
lr=Ridge(alpha=0)
lr.fit(x,y)
print('alpha=0時',lr.coef_,'\n')
lr=Ridge(alpha=10)
lr.fit(x,y)
print('alpha=10時',lr.coef_,'\n')
lr=Ridge(alpha=100)
lr.fit(x,y)
print('alpha=100時',lr.coef_,'\n')
lr=Ridge(alpha=1000)
lr.fit(x,y)
print('alpha=1000時',lr.coef_)

總結:線性回歸系列我們就介紹到這里了,因為很多概念都是第一次講,所以寫的很細致,輔以資料實體展示,保證讀者可以看得懂,同時手動復現,這些基礎概念講清楚了,也方便后面講解復雜演算法,
接下來介紹邏輯回歸,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/231008.html
標籤:python