本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來自于Python小二,作者:Python小二

本文以360手機助手為例,地址為:http://zhushou.360.cn/,相親軟體選擇 3 個比較流行的,分別為:世紀佳緣、百合婚戀、有緣網,我們使用 Python 爬取軟體評論區,看看用戶評價情況,
先來看一下這三款軟體的下載量和好中差評占比情況(下圖單位為萬次),




下面開始爬取評論區,以世紀佳緣為例,首先,在搜索框輸入世紀佳緣進行搜索,如圖所示:

接著,點擊搜索到的軟體進入其詳情頁,如圖所示:
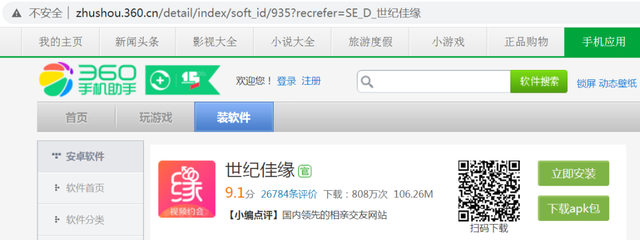
將頁面向下拉就可以看到評論區了,如圖所示:
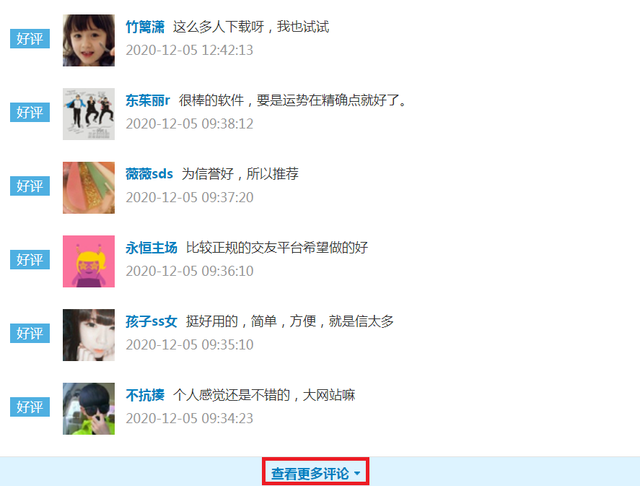
此時打開開發者工具并選擇Network項,點擊查看更多評論,然后可以看到getComments請求,如圖所示:

通過這個請求我們就可以動態獲取評論區資料了,其中引數star為開始的評論索引,引數count為每次加載的評論個數,可以通過引數callback、baike指定不同應用,爬取代碼實作如下:
headers = { "Accept": "*/*", "Accept-Encoding": "gzip, deflate, sdch", "Accept-Language": "zh-CN,zh;q=0.8", "Connection": "keep-alive", "Host": "comment.mobilem.360.cn", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER" } def comment_spider(param, file_name): base_url = "http://comment.mobilem.360.cn/comment/getComments?c=message&a=getmessage&&count=50" start = 0 for i in range(1, 50): print("第{}頁".format(i)) url = base_url + param + "&start=" + str(start) r = requests.get(url, headers=headers) data = re.findall("{\"errno\"(.*)\);}catch\(e\){}", r.text) # 轉為 Json 格式 jdata = https://www.cnblogs.com/hhh188764/p/json.loads("{\"errno\"" + data[0]) for message in jdata["data"]["messages"]: content = message["content"] print(content) with open(file_name + ".txt", "a", encoding="utf-8") as f: f.write(content) start = start + 50 time.sleep(2)
我們將爬取的評論資料存到了 txt 檔案中,
接著,我們將評論資料進行詞云展示,代碼實作如下:
with open("yy.txt", "r", encoding="utf-8") as f: content = f.read() stylecloud.gen_stylecloud(text=content, max_words=600, collocations=False, font_path="SIMLI.TTF", icon_name="fas fa-heart", size=800, output_name="yy.png") Image(filename="yy.png")
最后,通過詞云看一下用戶對上述軟體的評價情況,
世紀佳緣:

百合婚戀:

有緣網:

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/231311.html
標籤:Python
上一篇:安裝pyspider出現的問題