尊重原創:轉自劉夢馨:一致性哈希看這篇就夠了
既然有一致性哈希,就肯定還有不一致哈希,為啥平時沒人說不一致哈希呢?因為常見的哈希都是不一致的,所以就不修飾了,到了一致性哈希才特殊加個描述詞修飾一下,
哈希一般都是將一個大數字取模然后分散到不同的桶里,假設我們只有兩個桶,有 2、3、4、5 四個數字,那么模 2 分桶的結果就是:

這時我們嫌桶太少要給哈希表擴容加了一個新桶,這時候所有的數字就需要模 3 來確定分在哪個桶里,結果就變成了:
可以看到新加了一個桶后所有數字的分布都變了,這就意味著哈希表的每次擴展和收縮都會導致所有條目分布的重新計算,這個特性在某些場景下是不可接受的,比如分布式的存盤系統,每個桶就相當于一個機器,檔案分布在哪臺機器由哈希演算法來決定,這個系統想要加一臺機器時就需要停下來等所有檔案重新分布一次才能對外提供服務,而當一臺機器掉線的時候盡管只掉了一部分資料,但所有資料訪問路由都會出問題,這樣整個服務就無法平滑的擴縮容,成為了有狀態的服務,
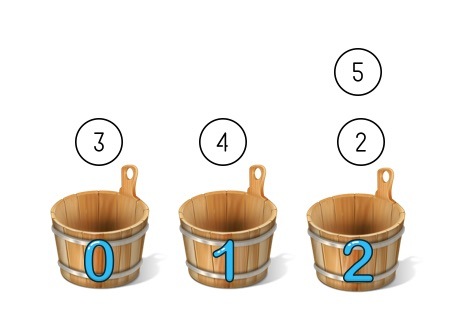
要想實作無狀態化,就要用到一致性哈希了,一致性哈希中假想我們有很多個桶,先定一個小目標比如 7 個,但一開始真實還是只有兩個桶,編號是 3 和 6,哈希演算法還是同樣的取模,只不過現在分桶分到的很可能是不存在的桶,那么就往下找找到第一個真實存在的桶放進去,這樣 2 和 3 都被分到了編號為 3 的桶, 4 和 5 被分到了編號為 6 的桶,
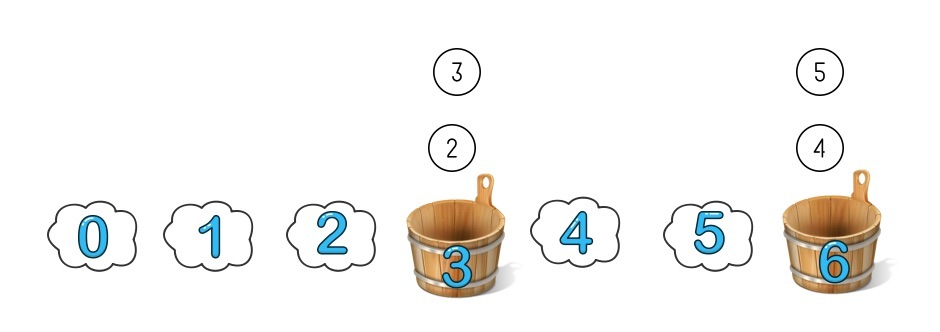
這時候再添加一個新的桶,編號是 4,取模方法不變還是模 7:
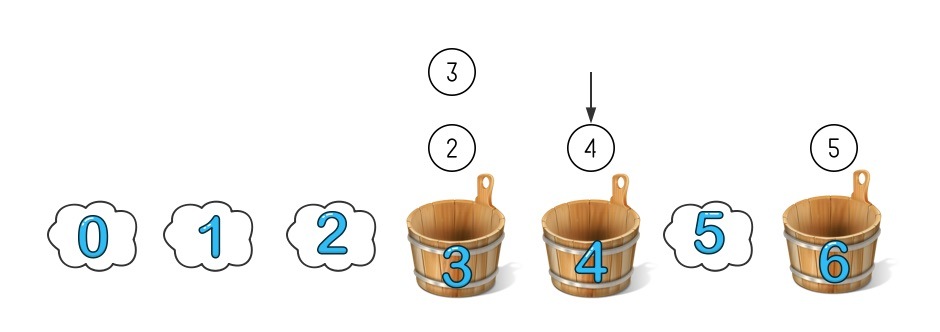
因為 3 號桶里都是取模小于等于 3 的,4 號桶只需要從 6 號桶里拿走屬于它的數字就可以了,這種情況下只需要調整一個桶的數字就可分成了重新分布,可以想象下即使有 1 億個桶,增加減少一個桶也只會影響一個桶的資料分布,
這樣增加一個機器只需要和他后面的機器同步一下資料就可以開始作業了,下線一個機器需要先把他的資料同步到后面一臺機器再下線,如果突然掉了一臺機器也只會影響這臺機器上的資料,實作中可以讓每臺機器同步一份自己前面機器的資料,這樣即使掉線也不會影響這一部分的資料服務,
這里還有個小問題要是編號為 6 的機桶下線了,它沒有后一個桶了,資料該咋辦?為了解決這個問題,實作上通常把哈希空間做成環狀,這樣 3 就成了 6 的下一桶,資料給 3 就好了:

用一致性哈希還能實作部分的分布式系統無鎖化,每個任務有自己的編號,由于哈希演算法的確定性,分到哪個桶也是確定的就不存在爭搶,也就不需要分布式鎖了,
既然一致性哈希有這么多好的特性,那為啥主流的哈希都是非一致的呢?主要一個原因在于查找效率上,普通的哈希查詢一次哈希計算就可以找到對應的桶了,演算法時間復雜度是 O(1),而一致性哈希需要將排好序的桶組成一個鏈表,然后一路找下去,k 個桶查詢時間復雜度是 O(k),所以通常情況下的哈希還是用不一致的實作,
當然 O(k) 的時間復雜度對于哈希來說還是不能忍的,想一下都是O(k) 這個量級了用哈希的意義在哪里?既然是在排好序的桶里查詢,很自然的想法就是二分了,能把時間復雜度降到 O(logk),然而桶的組合需要不斷的增減,所以是個鏈表的實作,二分肯定就不行了,還好可以用跳轉表進行一個快速的跳轉也能實作 O(logk) 的時間復雜度,
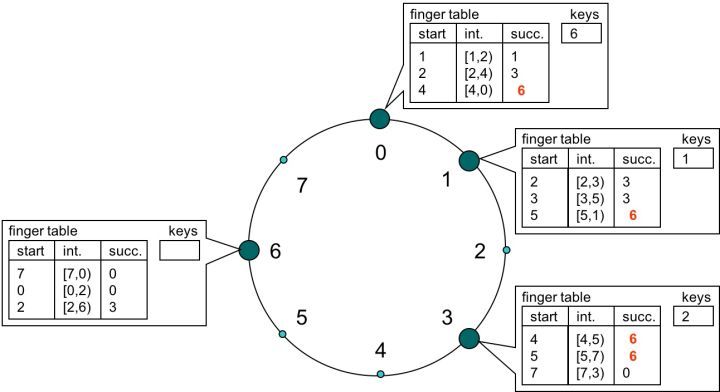
在這個跳轉表中,每個桶記錄距離自己 1,2,4 距離的數字所存的桶,這樣不管查詢落在哪個節點上,對整個哈希環上任意的查詢一次都可以至少跳過一半的查詢空間,這樣遞回下去很快就可以定位到資料是存在哪個桶上,
當然這寫都只是一致性哈希實作方式中的一種,還有很多實作上的變體,比如選擇數字放在哪個桶,上面的介紹里是選擇順著數字下去出現的第一個桶,其實也可以選擇距離這個數字最近的桶,這樣實作和后面的跳轉表規則也會有變化,同樣跳轉表也有多種不同的演算法實作,感興趣的可以去看一下 CAN,Chord,Tapestry,Pastry 這四種 DHT 的實作,有意思的是它們都是 2001 年發出來的 paper,所以 2001 年大概是 P2P 下載的元年吧,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234136.html
標籤:其他