手寫演算法-python代碼實作自定義的KNN
- 普通KNN存在的問題
- 自定義權重
- python代碼實作
- sklearn的KNN庫對比
普通KNN存在的問題
上篇文章,我們梳理了一下KNN,其中談到一個問題:
鏈接: 手寫演算法-python代碼實作KNN
做分類任務時,K個近鄰資料,到樣本的距離都不一樣,但是我們都一視同仁,統計最大樣本數對應的y標簽,作為預測標簽,這樣明顯不太合理,例如:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.metrics import classification_report
x0 = np.array([[1,2],
[2,3],
[3,4],
[3,3],
[2,4]])
y0 = np.array([0,0,0,0,0])
x1 = np.array([[10,14],
[10,12]])
y1 = np.array([1,1])
plt.scatter(x0[:,0],x0[:,1],c='r')
plt.scatter(x1[:,0],x1[:,1],c='b')
plt.scatter(9,13,marker='*',s =200,c='k')
plt.legend(labels=['label0','label1'],loc='best')
plt.show()
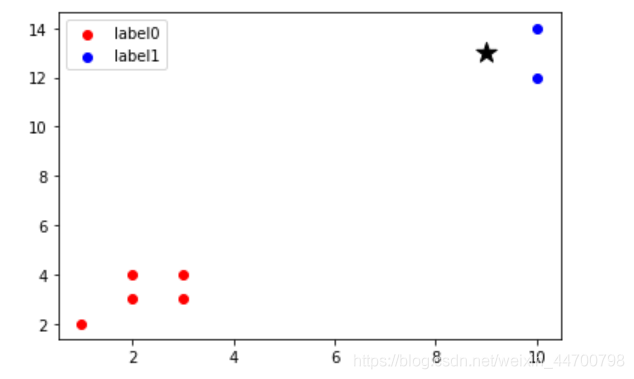
如圖所示的樣本集,五角星作為一個待預測的樣本點,當k=5時,該樣本點的預測標簽就是0,明顯的,此時把該樣本點預測為1更加合理,
自定義權重
造成上面的原因是:我們不加區別的對待這k個近鄰資料,只統計這些資料屬于哪個標簽,但是實際上,我們應該增加權重的概念,距離待預測樣本點更近的資料,應該獲得更大的權重,更遠的資料應該獲得更小的權重,這樣就合理一些,
方案一:weight = 1 / distance ,權重等于距離的倒數,符合我們自定義權重的要求,但是,這個方案存在的問題是,
權重的取值區間在(0,+∞),距離待預測樣本點最近的一個資料,權重過大,極端情況下,比如距離非常近的時候,該樣本點對應的標簽,就是預測標簽,這樣對噪聲資料很敏感,容易造成過擬合;
方案二:weight = 1 / (distance+const),把方案一的影像,往左平移const個單位,這樣的話,權重的取值區間在(0,1/const),較為平緩,既達到了增加權重的目的,也不會很容易過擬合,const的值可以根據實際業務來確定;

(還有其他方法,比如引入高斯函式,sigmoid函式,具體的還要看實際場景)
我們暫定使用方案二,
python代碼實作
根據上面所分析的,我們優化python代碼如下:
#自定義權重
class Knn_weight():
#默認k=5,設定和sklearn中的一樣,weight = False
def __init__(self,k=5,weight = False):
self.k = k
self.weight = weight
def fit(self,x,y):
self.x = x
self.y = y
def predict(self,x_test):
labels = []
#這里可以看出,KNN的計算復雜度很高,一個樣本就是O(m * n)
for i in range(len(x_test)):
#初始化一個y標簽的統計字典
dict_y = {}
#計算第i個測驗資料到所有訓練樣本的歐氏距離
diff = self.x - x_test[i]
distances = np.sqrt(np.square(diff).sum(axis=1))
#對距離排名,取最小的k個樣本對應的y標簽
rank = np.argsort(distances)
rank_k = rank[:self.k]
y_labels = self.y[rank_k]
#增加權重時
if self.weight:
distances_k = distances[rank_k]
#自定義權重運算式
weight = 1 / (distances_k + 0.5)
#累加權重,作為最終標簽的值
for j in y_labels:
if j not in dict_y:
dict_y.setdefault(j,weight[j])
else:
dict_y[j] += weight[j]
else:
#生成類別字典,key為類別,value為樣本個數
for j in y_labels:
if j not in dict_y:
dict_y.setdefault(j,1)
else:
dict_y[j] += 1
#取得y_labels里面,value值最大對應的類別標簽即為測驗樣本的預測標簽
#label = sorted(dict_y.items(),key = lambda x:x[1],reverse=True)[0][0]
#下面這種實作方式更加優雅
label = max(dict_y,key = dict_y.get)
labels.append(label)
return labels
針對上一篇文章的資料集,我們來對比一下,增加權重之后的分類效果如何,
print('距離沒有權重時,分類報告和分類效果圖如下:\n')
#預測
knn = Knn_weight(weight=False)
knn.fit(x,y)
labels = knn.predict(x)
#查看分類報告
print(classification_report(y,labels))
#畫等高線圖
x_min,x_max = x[:,0].min() - 1,x[:,0].max() + 1
y_min,y_max = x[:,1].min() - 1,x[:,1].max() + 1
xx = np.arange(x_min,x_max,0.02)
yy = np.arange(y_min,y_max,0.02)
xx,yy = np.meshgrid(xx,yy)
x_1 = np.c_[xx.ravel(),yy.ravel()]
y_1 = knn.predict(x_1)
#list沒有reshape方法,轉為np.array的格式
plt.contourf(xx,yy,np.array(y_1).reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
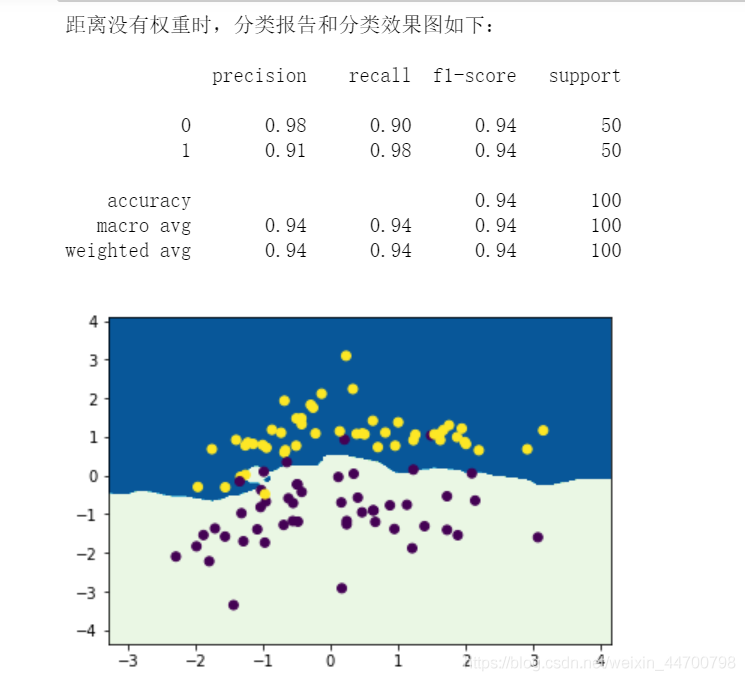
給距離增加權重時:
print('給距離增加權重時,分類報告和分類效果圖如下:\n')
#預測
knn = Knn_weight(weight=True)
knn.fit(x,y)
labels = knn.predict(x)
#查看分類報告
print(classification_report(y,labels))
y_1_weight = knn.predict(x_1)
#list沒有reshape方法,轉為np.array的格式
plt.contourf(xx,yy,np.array(y_1_weight).reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
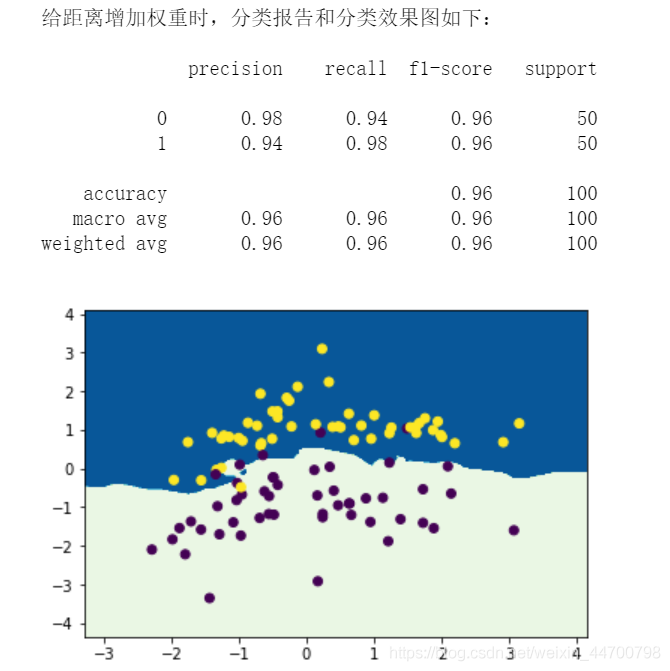
精準率、召回率、F1的值均有提升,從影像里面看,有2個點,之前預測錯了,但是現在預測對了,還是有一定的效果,
sklearn的KNN庫對比
from sklearn.neighbors import KNeighborsClassifier
#默認是weights='uniform',weights='distance'表示增加權重
clf = KNeighborsClassifier(weights='distance')
clf.fit(x,y)
y_pred = clf.predict(x)
#查看分類報告
print(classification_report(y,y_pred))
y_1_sklearn = clf.predict(x_1)
plt.contourf(xx,yy,y_1_sklearn.reshape(xx.shape),cmap='GnBu')
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
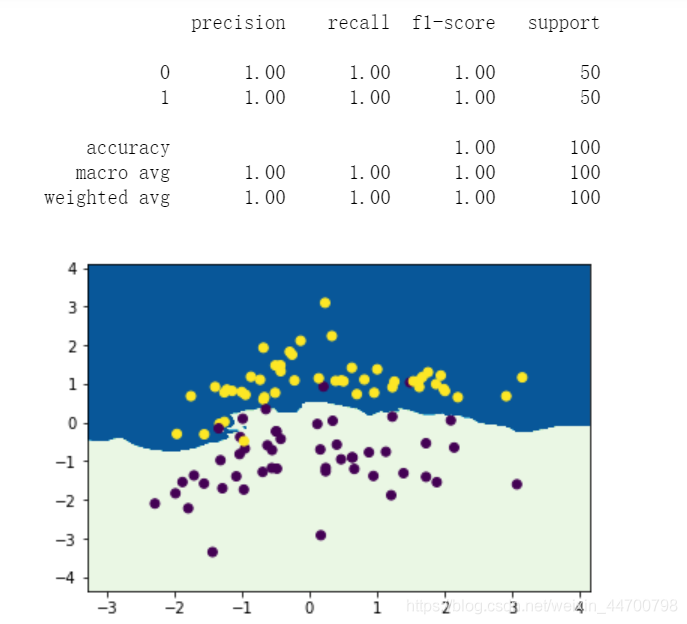
百分之百的準確率!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234255.html
標籤:python
上一篇:python socket通信(檔案、資料傳輸、例外處理)
下一篇:報數,報數啦!(講義)