文章目錄
- 前言
- 一、A*演算法
- 二、N數碼問題
- 三、代碼實作
- 1.碼盤節點的類定義
- 2.源代碼
- 總結
前言
最近上課遇到了八數碼問題,正好為了練一練代碼,就自己動手開始寫,因為用的python,沒有傳統的樹和鏈表結構,所以寫起來遇到了一些麻煩,這里記錄一下,大佬輕拍
一、A*演算法
A*演算法是一種啟發式演算法,具體內容可參考一下這位大佬的筆記,記錄的很詳細,我的演算法也是基于這篇筆記復現的,這篇文章也解釋了A和A*演算法的重要區別,解答了我對于這兩個演算法的疑問,
https://blog.csdn.net/qwezhaohaihong/article/details/103353885
二、N數碼問題
八數碼問題是N數碼的特殊情況,對于python的N數碼實作參考了這篇文章,
https://blog.csdn.net/qq_35976351/article/details/82767029
這篇文章創建了一種節點狀態類,將演算法搜索程序中的節點狀態,父子節點、啟發函式值等元素加入類中,并覆寫了類的相等判斷,使得節點類能夠模擬出搜索樹的結構,這一點在我的代碼中有所借鑒,
原文章賦予OPEN表堆特性,并且覆寫比較函式,用啟發值進行比較,使得在OPEN表的維護在堆的壓入和彈出程序自動完成,為堆排序覆寫的比較函式也是啟發我的一點,
但是這篇文章中代碼有一些錯誤,比如在計算manhattan距離時目標碼盤對應元素的位置解算有錯誤,另外在求解程序中引入了hash值去重,但還是會有重復判斷的問題,對于OPEN表、CLOSE表、M表和G樹的維護也有所欠缺,
三、代碼實作
1.碼盤節點的類定義
代碼如下:
class Astar_node(object):
def __init__(self, gn, hn, state=None, par=None):
'''
初始化
:param state: 節點存盤的狀態
:param par: 父節點
'''
self.state = state # 節點狀態
self.par = par # 父節點
self.gn, self.hn = gn, hn # 啟發資訊
@property # 定義fn屬性
def fn(self):
return self.gn + self.hn
def __eq__(self, obj): # 相等的判斷
return self.state == obj.state
def __ne__(self, obj): # 不等的判斷
return not self.__eq__(obj)
def print_state(self):
for row in range(Lenth):
for col in range(Lenth):
print('%3d' % self.state[row][col], end='')
print('')
print('--------------------')
def print_node(self):
print("gn=%d,hn=%d,fn=%d" % (self.gn, self.hn, self.fn))
self.print_state()
對于碼盤節點的類定義,在實作程序中首先定義了基本啟發函式g(n)和h(n)以及節點狀態和父節點指向等基本屬性,對于啟發函式f(n)采用屬性定義方法,避免在OPEN表排序時忘記賦值的錯誤,
由于在排序程序中沒有使用堆特性,直接使用sort函式對實體的屬性進行排序,所以洗掉了原來的大小比較函式的覆寫,
個人認為在A*演算法中已經充分考了節點重復狀態下的問題,擴展節點加入M表時已經排除了當前節點的父節點,也就是不走回頭路,M中的資料在加入OPEN、CLOSE表的程序中也進行了重復性驗證,對重復節點遇到啟發函式值更小的情況已經進行了考慮,所以我取消了用hash值對碼盤的狀態進行去重判斷和相等判斷,而是采用原始碼盤狀態進行重復性驗證和相等判斷,
另外在十五數碼問題程序中我發現一個很有意思的現象,這也是為什么我想記錄下實作程序的原因,就是關于g(n)的設定問題,一般在A*演算法中,通常關注f(n)的選取,但很少討論g(n)的選取,一般認為每進行一部擴展,將g(n)加1,也就是我們認為每走一步則增加一個步數的代價,但是在我測驗的程序中發現,g(n)對演算法的搜索效率也有非常大的影響,下面是我測驗g(n)每擴展一步深度,所花費的時間,100秒為演算法求解超時
①g(n)= 1

②g(n)= -1

③g(n)=0.2

④g(n)= 0.5
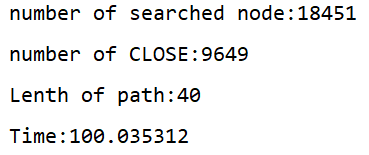
可以看到在g(n)=1的時候,搜索演算法搜索了大量的節點,但是實際求出的解路徑只有14個,最后超時未求解出來答案,
g(n)=0.5時得到了相似的結果,但是這次演算法搜索了相近的節點數,雖然同樣沒有求出答案,但是走出了更多的解路徑,
g(n)=-1時,演算法很快就求出了解路徑,但是解路徑十分長,顯然不是A*演算法所要求解的最優路徑,
g(n)= 0.2時,演算法在一個相對合理的時間內求出了一條相對合理的解,
至此可以得出對于A*解十五數碼問題的一個大致結論:
1.首先每一步的g(n)并不是取1最好,g(n)所代表的代價并不是實際所走的步數
2.g(n)有一個合適的取值區間能夠同時取得解的優選時間和優選路徑,
3.g(n)取值超過2中的區間后求解時間和路徑會隨取值增大成指數級增長,
4.g(n)取值小于2中的區間后,求解路徑會隨取值增加而減小,但時間會在一定范圍內縮減,
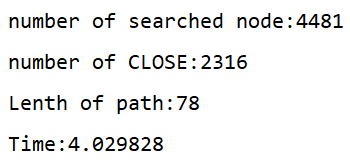
那么2中所說的區間是否存在呢,我嘗試驗證了之后得到一下資料:
⑤g(n) = 0.22
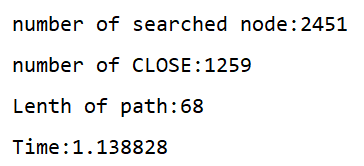
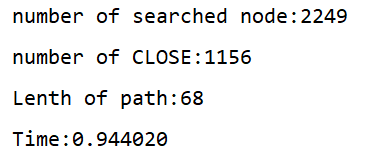
⑥g(n)= 0.25,0.27,0.29

⑦g(n) = 0.3
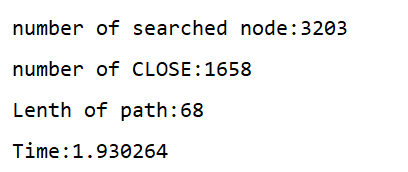
⑧g(n)=0.32

⑨g(n)=0.35

⑩g(n) = 0.46,0.44,0,42超時
另外有一個不符合規律的資料,在0.23~0.24之間,演算法執行時間都較長,并且0.24為幾秒,而0.238為十幾秒,這組資料較為反常,
g(n)=0.23
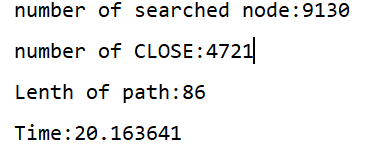
除去反常資料可以看到,g(n)對演算法求解影響大致是符合三條規律的,
在我完成了代碼之后,在初始使用g(n)=1求解演算法時,無法得出原本能幾秒求出的解,我在反復檢查了代碼之后發現依然不能求解,但是卻能求解簡單的碼盤,因此我嘗試不使用步數代價,發現能夠很快求出解,后面才有了這些資料,在此提出我的猜想:
如果有玩過華容道或拼圖游戲的朋友可能會知道,最短的求解路徑有時候反而需要多走一些步數,而在十五數碼這個問題中,一個空格轉一圈回到原點時,實際上碼盤是會發生改變的,而這個程序中可能會增加h(n)的值,但是在旋轉完成 后,整個f(n)的值卻可能是最小的,因此猜測這就是為什么g(n)的最優區間在0.25附近,當小于這個區間時,我們實際上是減小解路徑的行走代價,鼓勵多在解路徑上進行嘗試,因此會出現長路徑和少擴展以及合適的求解時間,當大于這個區間時,我們在增加演算法在解路徑的行走代價,造成演算法每走一步都需要謹慎小心,不斷擴展節點,期望求得較小的行走代價從而得到最短的路徑,最終造成擴展圖十分龐大,超時后最終能得到的解路徑很少,
因此g(n)的選取對演算法其實是有影響的,
PS:如果有興趣可以嘗試一下h(n)函式對演算法求解的影響,
2.源代碼
代碼如下(示例):
import copy
import re
import time
import os
# Lenth = 0 # 碼盤邊長
# 狀態節點
class Astar_node(object):
def __init__(self, gn, hn, state=None, par=None):
'''
初始化
:param state: 節點存盤的狀態
:param par: 父節點
'''
self.state = state # 節點狀態
self.par = par # 父節點
self.gn, self.hn = gn, hn # 啟發資訊
@property # 定義fn屬性
def fn(self):
return self.gn + self.hn
def __eq__(self, obj): # 相等的判斷
return self.state == obj.state
def __ne__(self, obj): # 不等的判斷
return not self.__eq__(obj)
def print_state(self):
for row in range(Lenth):
for col in range(Lenth):
print('%3d' % self.state[row][col], end='')
print('')
print('--------------------')
def print_node(self):
print("gn=%d,hn=%d,fn=%d" % (self.gn, self.hn, self.fn))
self.print_state()
def manhattan_dis(cur):
'''
計算和目標碼盤的曼哈頓距離
:param cur: 當前節點
:return: 到目的狀態的曼哈頓距離
'''
cur_state = cur.state
end_state = end_node.state
dist = 0
for row in range(Lenth):
for col in range(Lenth):
if cur_state[row][col] == end_state[row][col]:
continue
num = cur_state[row][col]
# 求目標碼盤對應元素的橫縱坐標
num_row = num // Lenth if num % 4 != 0 else (num - 1) // Lenth
num_row = num_row if num_row != -1 else 3
num_col = num % Lenth - 1
num_col = num_col if num_col != -1 else 3
dist += (abs(row - num_row) + abs(col - num_col))
return dist
class A_start:
'''
A*演算法初始化
:param start: 起始節點
:param end: 終止節點
:param heuristic_fn: 啟發函式
return: G search_cnt
'''
def __init__(self, start, end, heuristic_fn,time_limite):
self.OPEN = [] # OPEN表
self.CLOSE = [] # CLOSE表
self.G = [] # 搜索樹
self.start = start
self.end = end
self.cur_node = None
self.heuristic_fn = heuristic_fn
self.start_t = 0 # 計時變數
self.end_t = 0
self.G.append(self.start) # 初始化搜索圖
self.OPEN.append(self.start) # 初始化OPEN表
def begin_search(self): # 演算法開始
self.start_t = time.time()
# 找空位坐標
blank_pos = None
while 1:
# OPEN表為空表示無解 直接退出
if self.OPEN == [] or (time.time()-self.start_t>time_limite):
print("There is no anser!")
self.print_result()
break
else:
self.cur_node = self.OPEN.pop(0) # 彈出OPEN表中第一個元素
self.CLOSE.append(self.cur_node) # 當前節點放入CLOSE表表示擴展完成
# self.cur_node.print_node()
# 搜索到目標節點
if self.cur_node == self.end:
# self.end.par=self.cur_node
print("Success!")
self.print_result()
break
# 找節點空位
for row in range(Lenth):
for col in range(Lenth):
if self.cur_node.state[row][col] == 0:
blank_pos = [row, col]
break
# 擴展節點
M = [] # 擴展出的新節點集合(不包括當前節點的父節點)
for dict in dicts:
b_x, b_y = blank_pos[0], blank_pos[1]
n_x, n_y = b_x + dict[0], b_y + dict[1]
if n_x in range(Lenth) and n_y in range(Lenth): # 越界判定
new_node = Astar_node(0, 0, copy.deepcopy(self.cur_node.state))
new_node.state[b_x][b_y], new_node.state[n_x][n_y] = \
new_node.state[n_x][n_y], new_node.state[b_x][b_y] # 移動空位
if new_node != self.cur_node.par: # 擴展結點不是當前節點的父節點
new_node.gn = self.cur_node.gn + 0.25
new_node.hn = self.heuristic_fn(new_node) # 計算節點hn
M.append(new_node) # 新節點加入集合
# 處理新擴展的節點
for node in M:
# 去重擴展搜索樹
if node not in self.G:
self.G.append(node)
# 未出現在OPEN和CLOSE表中 將擴展節點父節點設為當前節點并加入OPEN表
if node not in self.OPEN and node not in self.CLOSE:
node.par = self.cur_node
self.OPEN.append(node)
# 出現在OPEN表中 比較OPEN表和M表中的fn值 若M<OPEN 在OPEN表中將該節點父節點設為當前節點
elif node in self.OPEN:
for node_open in self.OPEN:
if node == node_open and node.fn < node_open.fn:
# node_open.par = self.cur_node
node.par=self.cur_node
self.OPEN.remove(node_open)
self.OPEN.append(node)
# 出現在CLOSE表中 比較CLOSE表和M表中的fn值 若M<CLOSE 在CLOSE表中將擴展節點子節點指向當前節點(將當前節點父節點設為CLOSE表中擴展節點)彈出CLOSE表中的該節點加入OPEN表
elif node in self.CLOSE:
for node_close in self.CLOSE:
if node == node_close and node.fn < node_close.fn:
self.cur_node.par = node_close
self.CLOSE.remove(node_close)
self.OPEN.append(node_close)
# 依照啟發資訊重排OPEN表
self.OPEN.sort(key=lambda x: x.fn)
def print_result(self):
self.end_t = time.time()
#列印路徑
path_cnt = 1
self.cur_node.print_state()
while True:
self.cur_node = self.cur_node.par
self.cur_node.print_state()
path_cnt += 1
if self.cur_node.par == root_node:
break
print("number of searched node:%d" % len(self.G))
print("number of CLOSE:%d" % len(self.CLOSE))
print("Lenth of path:%d" % (path_cnt - 1))
print("Time:%f" % (self.end_t - self.start_t))
if __name__ == '__main__':
dicts = [[0, 1], [0, -1], [-1, 0], [1, 0]] # 空格移動方向
with open("./infile.txt", "r") as f: # 讀取碼盤邊長和初始碼盤
Lenth = int(f.readline().strip().split()[-1])
List = list(map(int, f.readline().strip().split()))
# 創建初始碼盤和目標碼盤
Start = [List[i:i + Lenth] for i in range(0, len(List), Lenth)]
GOAL_list = [i for i in range(1, Lenth * Lenth)]
GOAL_list.append(0)
GOAL = [GOAL_list[i:i + Lenth] for i in range(0, len(GOAL_list), Lenth)]
root_node = Astar_node(0, 0, [[0] * 4] * 4, None) # 創建樹根
end_node = Astar_node(0, 0, GOAL, None) # 創建目標節點
start_node = Astar_node(0, 0, Start, root_node) # 創建初始節點
start_node.hn = manhattan_dis(start_node)
time_limite=100
Astar = A_start(start_node, end_node, manhattan_dis,time_limite)
Astar.begin_search()
os.system("pause")
總結
A*演算法確實是一個優秀的演算法,在親自撰寫的程序中才體會到這個演算法的嚴謹和精妙之處,演算法有很強的擴展性和靈活性,對于很多問題的求解都適用,比如:路徑搜索,圖搜索等等,如果有機會希望能嘗試它的改進演算法的研究和實作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234257.html
標籤:python
上一篇:報數,報數啦!(講義)
下一篇:路徑規劃演算法學習Day3