背景
《利用Python進行資料分析》,第 6 章的資料加載操作 read_xxx,有 chunksize 引數可以進行逐塊加載,
經測驗,它的本質就是將文本分成若干塊,每次處理 chunksize 行的資料,最侄訓傳一個TextParser 物件,對該物件進行迭代遍歷,可以完成逐塊統計的合并處理,
示例代碼
文中的示例代碼分析如下:
from pandas import DataFrame,Series
import pandas as pd
path='D:/AStudy2018/pydata-book-2nd-edition/examples/ex6.csv'
# chunksize return TextParser
chunker=pd.read_csv(path,chunksize=1000)
# an array of Series
tot=Series([])
chunkercount=0
for piece in chunker:
print '------------piece[key] value_counts start-----------'
#piece is a DataFrame,lenth is chunksize=1000,and piece[key] is a Series ,key is int ,value is the key column
print piece['key'].value_counts()
print '------------piece[key] value_counts end-------------'
#piece[key] value_counts is a Series ,key is the key column, and value is the key count
tot=tot.add(piece['key'].value_counts(),fill_value=0)
chunkercount+=1
#last order the series
tot=tot.order(ascending=False)
print chunkercount
print '--------------'
流程分析
首先,例子資料 ex6.csv 檔案總共有 10000 行資料,使用 chunksize=1000 后,read_csv操作回傳一個 TextParser 物件,該物件總共有10個元素,遍歷程序中列印 chunkercount驗證得到,
其次,每個 piece 物件是一個 DataFrame 物件,piece['key'] 得到的是一個 Series 物件,默認是數值索引,值為 csv 檔案中的 key 列的值,即各個字串,
將每個 Series 的 value_counts 作為一個Series,與上一次統計的 tot 結果進行 add 操作,最終得到所有塊資料中各個 key 的累加值,
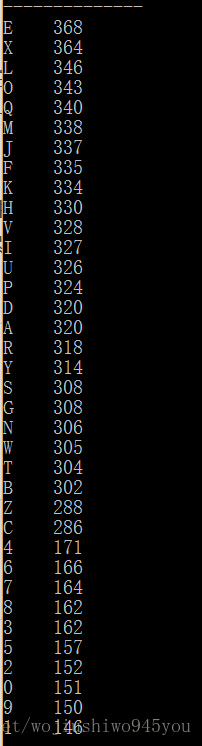
最后,對 tot 進行 order 排序,按降序得到各個 key 的值在 csv 檔案中出現的總次數,
這里很巧妙了使用 Series 物件的 add 操作,對兩個 Series 執行 add 操作,即合并相同key:key相同的記錄的值累加,key不存在的記錄設定填充值為0,
輸出結果為:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234267.html
標籤:python
下一篇:python實作插入排序