
1.1 MHA簡介
1.1.1 MHA軟體介紹
MHA(Master High Availability)目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司youshimaton(現就職于Facebook公司)開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟體,在MySQL故障切換程序中,MHA能做到在10~30秒之內自動完成資料庫的故障切換操作,并且在進行故障切換的程序中,MHA能在最大程度上保證資料的一致性,以達到真正意義上的高可用,
MHA能夠在較短的時間內實作自動故障檢測和故障轉移,通常在10-30秒以內;在復制 框架中,MHA能夠很好地解決復制程序中的資料一致性問題,由于不需要在現有的 replication中添加額外的服務器,僅需要一個manager節點,而一個Manager能管理多套復制,所以能大大地節約服務器的數量;另外,安裝簡單,無性能損耗,以及不需要修改現 有的復制部署也是它的優勢之處,
MHA還提供在線主庫切換的功能,能夠安全地切換當前運行的主庫到一個新的主庫中 (通過將從庫提升為主庫),大概0.5-2秒內即可完成,
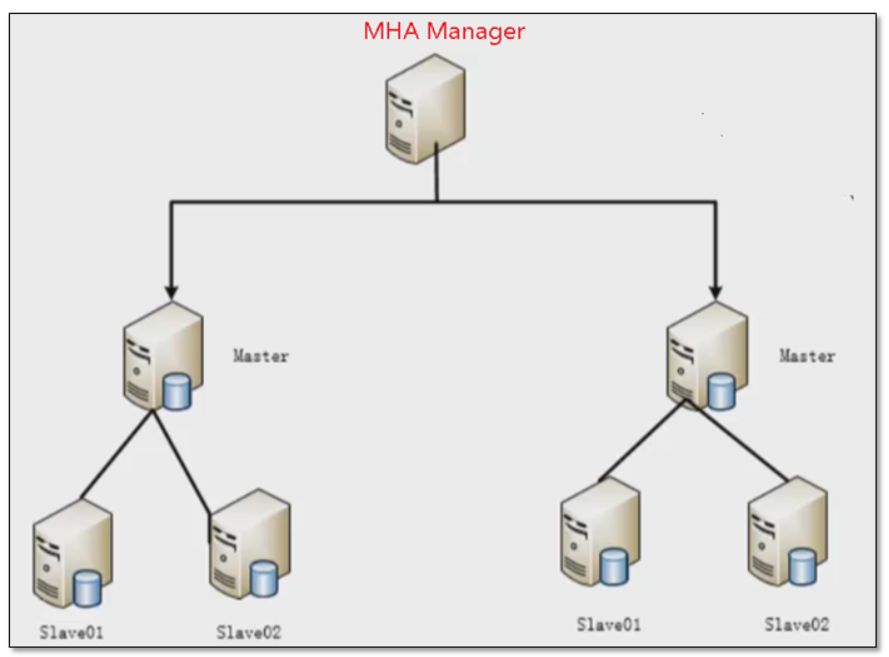
該軟體由兩部分組成:MHA Manager(管理節點)和MHA Node(資料節點),MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,也可以部署在一臺slave節點上,MHA Node運行在每臺MySQL服務器上,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新資料的slave提升為新的master,然后將所有其他的slave重新指向新的master,整個故障轉移程序對應用程式完全透明,
在MHA自動故障切換程序中,MHA試圖從宕機的主服務器上保存二進制日志,最大程度的保證資料的不丟失,但這并不總是可行的,例如,如果主服務器硬體故障或無法通過ssh訪問,MHA沒法保存二進制日志,只進行故障轉移而丟失了最新的資料,使用MySQL 5.5的半同步復制,可以大大降低資料丟失的風險,
MHA可以與半同步復制結合起來,如果只有一個slave已經收到了最新的二進制日志,MHA可以將最新的二進制日志應用于其他所有的slave服務器上,因此可以保證所有節點的資料一致性,
目前MHA主要支持一主多從的架構,要搭建MHA,要求一個復制集群中必須最少有三臺資料庫服務器,一主二從,即一臺充當master,一臺充當備用master,另外一臺充當從庫,因為至少需要三臺服務器,出于機器成本的考慮,淘寶也在該基礎上進行了改造,目前淘寶TMHA已經支持一主一從,
1.1.2 MHA作業原理
 |
作業原理說明: 1、保存master上的所有binlog事件 2、找到含有最新binlog位置點的slave 3、通過中繼日志將資料恢復到其他的slave 4、將包含最新binlog位置點的slave提升為master 5、將其他從庫slave指向新的master原slave01 并開啟主從復制 6、將保存下來的binlog恢復到新的master上 |
|---|---|
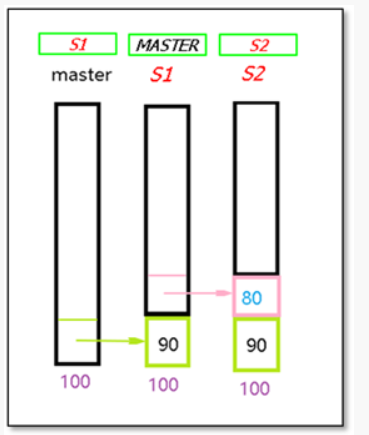
1、監控所有node節點MHA功能說明:
2、自動故障切換(failover)
前提是必須有三個節點存在,并且有兩個從庫
(1)選主前提,按照組態檔的順序進行,但是如果此節點后主庫100M以上relay-log 就不會選
(2)如果你設定了權重,總會切換帶此節點;一般在多地多中心的情況下,一般會把權重設定在本地節點,
(3)選擇s1為新主
(4)保存主庫binlog日志
3、重新構建主從
(1)將有問題的節點剔除MHA
進行第一階段資料補償,S2缺失部分補全90
(2)s1切換角色為新主,將s2指向新主S1
s2 change master to s1
(3) 第二階段資料補償
將保存過來的新主和原有主缺失部分的binlog,應用到新主,
(4)虛擬IP漂移到新主,對應用透明無感知
(5)通知管理員故障切換
1.1.3 MHA高可用架構圖
1.1.4 MHA工具介紹
MHA軟體由兩部分組成,Manager工具包和Node工具包,具體的說明如下:
Manager工具包主要包括以下幾個工具:
masterha_check_ssh #檢査 MHA 的 ssh-key^
masterha_check_repl #檢査主從復制情況
masterha_manger #啟動MHA
masterha_check_status #檢測MHA的運行狀態^
masterha_mast er_monitor #檢測master是否宕機一
masterha_mast er_switch #手動故障轉移—
masterha_conf_host #手動添加server倍息一
masterha_secondary_check #建立TCP連接從遠程服務器v
masterha_stop #停止MHA
Node工具包主要包括以下幾個工具:
save_binary_1ogs #保存宕機的master的binlog
apply_diff_relay_logs #識別relay log的差異
filter_mysqlbinlog #防止回滾事件一MHA已不再使用這個工具
purge_relay_logs #清除中繼曰志一不會阻塞SQL執行緒
1.1.5 MHA的優點
1、自動故障轉移
2、主庫崩潰不存在資料不一致的情況
3、不需要對當前的mysql環境做重大修改
4、不需要添加額外的服務器
5、性能優秀,可以作業再半同步和異步復制框架
6、只要replication支持的存盤引擎mha都支持
1.2 環境說明
在本次的實驗中,共需要用到三臺主機,系統、軟體說明如下,
1.2.1 系統環境說明
db01主機(master)
[root@db01 ~]# cat /etc/redhat-release
CentOS release 6.9 (Final)
[root@db01 ~]# uname -r
2.6.32-696.el6.x86_64
[root@db01 ~]# /etc/init.d/iptables status
iptables: Firewall is not running.
[root@db01 ~]# getenforce
Disabled
[root@db01 ~]# hostname -I
10.0.0.51 172.16.1.51
db02主機(slave1)
1 [root@db02 ~]# cat /etc/redhat-release
2 CentOS release 6.9 (Final)
3 [root@db02 ~]# uname -r
4 2.6.32-696.el6.x86_64
5 [root@db02 ~]# /etc/init.d/iptables status
6 iptables: Firewall is not running.
7 [root@db02 ~]# getenforce
8 Disabled
9 [root@db02 ~]# hostname -I
10 10.0.0.52 172.16.1.52
db03主機(slave1,MHA Manages、Atlas節點)
1 [root@db02 ~]# cat /etc/redhat-release
2 CentOS release 6.9 (Final)
3 [root@db02 ~]# uname -r
4 2.6.32-696.el6.x86_64
5 [root@db02 ~]# /etc/init.d/iptables status
6 iptables: Firewall is not running.
7 [root@db02 ~]# getenforce
8 Disabled
9 [root@db02 ~]# hostname -I
10 10.0.0.52 172.16.1.52
1.2.2 mysql軟體說明
? 三臺服務器上都全新安裝mysql 5.6.36 :
[root@db01 ~]# mysql --version
mysql Ver 14.14 Distrib 5.6.36, for Linux (x86_64) using EditLine wrapper
關于mysql資料庫具體的安裝方法參考:http://www.cnblogs.com/clsn/p/8038964.html#_label3
1.3 基于GTID的主從復制配置
1.3.1 先決條件
?? 主庫和從庫都要開啟binlog
?? 主庫和從庫server-id必須不同
?? 要有主從復制用戶
1.3.2 配置主從復制
db01 my.cnf****檔案
[root@db01 ~]# cat /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
socket=/tmp/mysql.sock
log-error=/var/log/mysql.log
log-bin=/data/mysql/mysql-bin
binlog_format=row
secure-file-priv=/tmp
server-id=51
skip-name-resolve # 跳過域名決議
gtid-mode=on # 啟用gtid型別,否則就是普通的復制架構
enforce-gtid-consistency=true #強制GTID的一致性
log-slave-updates=1 # slave更新是否記入日志(5.6必須的)
relay_log_purge = 0
[mysql]
socket=/tmp/mysql.sock
db02 my.cnf****檔案
1 [root@db02 ~]# cat /etc/my.cnf
2 [mysqld]
3 basedir=/application/mysql
4 datadir=/application/mysql/data
5 socket=/tmp/mysql.sock
6 log-error=/var/log/mysql.log
7 log-bin=/data/mysql/mysql-bin
8 binlog_format=row
9 secure-file-priv=/tmp
10 server-id=52
11 skip-name-resolve
12 gtid-mode=on
13 enforce-gtid-consistency=true
14 log-slave-updates=1
15 relay_log_purge = 0
16 [mysql]
17 socket=/tmp/mysql.sock
db03 my.cnf****檔案
1 [root@db03 ~]# cat /etc/my.cnf
2 [mysqld]
3 basedir=/application/mysql
4 datadir=/application/mysql/data
5 socket=/tmp/mysql.sock
6 log-error=/var/log/mysql.log
7 log-bin=/data/mysql/mysql-bin
8 binlog_format=row
9 secure-file-priv=/tmp
10 server-id=53
11 skip-name-resolve
12 gtid-mode=on
13 enforce-gtid-consistency=true
14 log-slave-updates=1
15 relay_log_purge = 0
16 skip-name-resolve
17 [mysql]
18 socket=/tmp/mysql.sock
創建復制用戶 (51作為主節點,52、53為從)
GRANT REPLICATION SLAVE ON *.* TO repl@'10.0.0.%' IDENTIFIED BY '123';
從庫開啟復制
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123',
MASTER_AUTO_POSITION=1;
啟動從庫復制
start slave;
1.3.3 GTID復制技術說明
MySQL GTID****簡介
GTID的全稱為 global transaction identifier ,可以翻譯為全域事務標示符,GTID在原始master上的事務提交時被創建,GTID需要在全域的主-備拓撲結構中保持唯一性,GTID由兩部分組成:
GTID = source_id:transaction_id
source_id用于標示源服務器,用server_uuid來表示,這個值在第一次啟動時生成,并寫入到組態檔data/auto.cnf中
transaction_id則是根據在源服務器上第幾個提交的事務來確定,
GTID**事件結構

GTID**在二進制日志中的結構
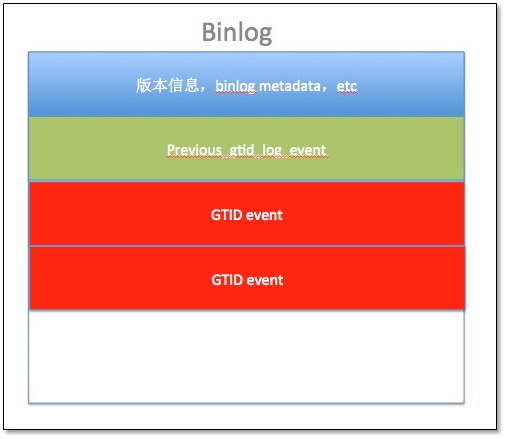
一個GTID*的生命周期包括:*
1.事務在主庫上執行并提交給事務分配一個gtid(由主庫的uuid和該服務器上未使用的最小事務序列號),該GTID被寫入到binlog中,
2.備庫讀取relaylog中的gtid,并設定session級別的gtid_next的值,以告訴備庫下一個事務必須使用這個值
3.備庫檢查該gtid是否已經被其使用并記錄到他自己的binlog中,slave需要擔保之前的事務沒有使用這個gtid,也要擔保此時已分讀取gtid,但未提交的事務也不恩呢過使用這個gtid.
4.由于gtid_next非空,slave不會去生成一個新的gtid,而是使用從主庫獲得的gtid,這可以保證在一個復制拓撲中的同一個事務gtid不變,由于GTID在全域的唯一性,通過GTID,我們可以在自動切換時對一些復雜的復制拓撲很方便的提升新主庫及新備庫,例如通過指向特定的GTID來確定新備庫復制坐標,
GTID是用來替代以前classic的復制方法;
MySQL5.6.2支持 MySQL5.6.10后完善;
GTID****相比傳統復制的優點:
1.一個事務對應一個唯一ID,一個GTID在一個服務器上只會執行一次
2.GTID是用來代替傳統復制的方法,GTID復制與普通復制模式的最大不同就是不需要指定二進制檔案名和位置
3.減少手工干預和降低服務故障時間,當主機掛了之后通過軟體從眾多的備機中提升一臺備機為主機
GTID****的限制:
1.不支持非事務引擎
2.不支持create table ... select 陳述句復制(主庫直接報錯)
原理:( 會生成兩個sql,一個是DDL創建表SQL,一個是insert into 插入資料的sql,
由于DDL會導致自動提交,所以這個sql至少需要兩個GTID,但是GTID模式下,只能給這個sql生成一個GTID )
3.不允許一個SQL同時更新一個事務引擎表和非事務引擎表
4.在一個復制組中,必須要求統一開啟GTID或者是關閉GTID
5.開啟GTID需要重啟(5.7除外)
6.開啟GTID后,就不再使用原來的傳統復制方式
7.對于create temporary table 和 drop temporary table陳述句不支持
8.不支持sql_slave_skip_counter
1.3.4 COM_BINLOG_DUMP_GTID
從機發送到主機執行的事務的識別符號的主范圍
Master send all other transactions to slave
同樣的GTID不能被執行兩次,如果有同樣的GTID,會自動被skip掉,
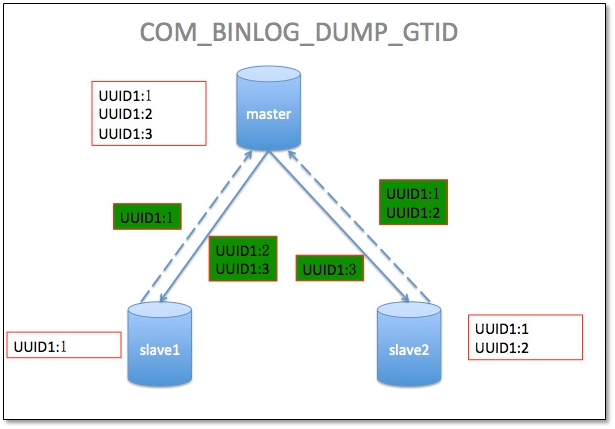
slave1:將自己的UUID1:1發送給master,然后接收到了UUID1:2,UUID1:3 event
slave2:將自己的UUID1:1,UUID1:2發送給master,然后接收到了UUID1:3事件
GTID****組成
GTID實際上是由UUID+TID組成的,其中UUID是一個MySQL實體的唯一標識,TID代表了該實體上已經提交的事務數量,并且隨著事務提交單調遞增
GTID = source_id :transaction_id
7E11FA47-31CA-19E1-9E56-C43AA21293967:29
1.3.5 【示例二】MySQL GTID復制配置
主節點my.cnf檔案
# vi /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/data/mysql
server-id=1
log-bin=mysql-bin
socket=/tmp/mysql.sock
binlog-format=ROW
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
從節點my.cnf檔案
# vi /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/data/mysql
server-id=2
binlog-format=ROW
gtid-mode=on
enforce-gtid-consistency=true
log-bin=mysql-bin
log_slave_updates = 1
socket=/tmp/mysql.sock
組態檔注解
server-id=x # 同一個復制拓撲中的所有服務器的id號必須惟一
binlog-format=RO # 二進制日志格式,強烈建議為ROW
gtid-mode=on # 啟用gtid型別,否則就是普通的復制架構
enforce-gtid-consistency=true # 強制GTID的一致性
log-slave-updates=1 # slave更新是否記入日志
復制用戶準備(Master主節點)
mysql>GRANT REPLICATION SLAVE ON *.* TO rep@'10.0.0.%' IDENTIFIED BY '123';
開啟復制(Slave從節點)
mysql>start slave;
mysql>show slave status\G
現在就可以進行主從復制測驗,
1.4 部署MHA
本次MHA的部署基于GTID復制成功構建,普通主從復制也可以構建MHA架構,
1.4.1 環境準備(所有節點操作)
安裝依賴包
yum install perl-DBD-MySQL -y
下載mha軟體,mha官網:https://code.google.com/archive/p/mysql-master-ha/
? github下載地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
*下載軟體包*
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
在所有節點安裝node
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
創建mha管理用戶
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
# 主庫上創建,從庫會自動復制(在從庫上查看)
創建命令軟連接(重要)
如果不創建命令軟連接,檢測mha復制情況的時候會報錯
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /application/mysql/bin/mysql /usr/bin/mysql
1.4.2 部署管理節點(mha-manager)
在mysql-db03上部署管理節點
# 安裝epel源,軟體需要
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
# 安裝manager 依賴包
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
# 安裝manager管理軟體
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
創建必須目錄
mkdir -p /etc/mha
mkdir -p /var/log/mha/app1 ----》可以管理多套主從復制
編輯mha-manager*組態檔*
[root@db03 ~]# cat /etc/mha/app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/mysql
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
【組態檔詳解】
[server default]
2 #設定manager的作業目錄
3 manager_workdir=/var/log/masterha/app1
4 #設定manager的日志
5 manager_log=/var/log/masterha/app1/manager.log
6 #設定master 保存binlog的位置,以便MHA可以找到master的日志,我這里的也就是mysql的資料目錄
7 master_binlog_dir=/data/mysql
8 #設定自動failover時候的切換腳本
9 master_ip_failover_script= /usr/local/bin/master_ip_failover
10 #設定手動切換時候的切換腳本
11 master_ip_online_change_script= /usr/local/bin/master_ip_online_change
12 #設定mysql中root用戶的密碼,這個密碼是前文中創建監控用戶的那個密碼
13 password=123456
14 #設定監控用戶root
15 user=root
16 #設定監控主庫,發送ping包的時間間隔,嘗試三次沒有回應的時候自動進行failover
17 ping_interval=1
18 #設定遠端mysql在發生切換時binlog的保存位置
19 remote_workdir=/tmp
20 #設定復制用戶的密碼
21 repl_password=123456
22 #設定復制環境中的復制用戶名
23 repl_user=rep
24 #設定發生切換后發送的報警的腳本
25 report_script=/usr/local/send_report
26 #一旦MHA到server02的監控之間出現問題,MHA Manager將會嘗試從server03登錄到server02
27 secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=10.0.0.51 --master_port=3306
28 #設定故障發生后關閉故障主機腳本(該腳本的主要作用是關閉主機放在發生腦裂,這里沒有使用)
29 shutdown_script=""
30 #設定ssh的登錄用戶名
31 ssh_user=root
32
33 [server1]
34 hostname=10.0.0.51
35 port=3306
36
37 [server2]
38 hostname=10.0.0.52
39 port=3306
40 #設定為候選master,如果設定該引數以后,發生主從切換以后將會將此從庫提升為主庫,即使這個主庫不是集群中事件最新的slave
41 candidate_master=1
42 #默認情況下如果一個slave落后master 100M的relay logs的話,MHA將不會選擇該slave作為一個新的master,因為對于這個slave的恢復需要花費很長時間,通過設定check_repl_delay=0,MHA觸發切換在選擇一個新的master的時候將會忽略復制延時,這個引數對于設定了candidate_master=1的主機非常有用,因為這個候選主在切換的程序中一定是新的master
43 check_repl_delay=0
配置ssh信任(密鑰分發,在所有節點上執行)
# 生成密鑰
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
# 分發公鑰,包括自己
for i in 1 2 3 ;do ssh-copy-id -i /root/.ssh/id_dsa.pub [email protected]$i ;done
? 分發完成后測驗分發是否成功
for i in 1 2 3 ;do ssh 10.0.0.5$i date ;done
或
[root@db03 ~]# masterha_check_ssh --conf=/etc/mha/app1.cnf
最后一行資訊為如下字樣即為分發成功:
Thu Dec 28 18:44:53 2017 - [info] All SSH connection tests passed successfully.
1.4.3 啟動mha
經過上面的部署過后,mha架構已經搭建完成
# 啟動mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
? 啟動成功后,檢查主庫狀態
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:3298) is running(0:PING_OK), master:10.0.0.51
1.4.4 切換master測驗
查看現在的主庫是哪個
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:11669) is running(0:PING_OK), master:10.0.0.51
手動停止主庫
[root@db01 ~]# /etc/init.d/mysqld stop
Shutting down MySQL..... SUCCESS!
再停止資料的同時查看日志資訊的變化
[root@db03 ~]# tailf /var/log/mha/app1/manager
~~~
Fri Dec 29 15:51:14 2017 - [info] All other slaves should start replication from
here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';
修復主從
① 啟動原主庫,添加change master to 資訊
[root@db01 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
mysql> CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';
mysql> start slave;
② 查看主從復制狀態
mysql> show slave status\G
Master_Host: 10.0.0.52
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
修復mha
① 修改app1.cnf組態檔,添加回被剔除主機
[root@db03 ~]# cat /etc/mha/app1.cnf
[binlog1]
hostname=10.0.0.53
master_binlog_dir=/data/mysql/binlog/
no_master=1
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
user=mha
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
② mha檢查復制狀態
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK.
③ 啟動mha程式
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
到此主庫切換成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:11978) is running(0:PING_OK), master:10.0.0.52
實驗結束將主庫切換回db01.
① 停止mha
[root@db03 ~]# masterha_stop --conf=/etc/mha/app1.cnf
Stopped app1 successfully.
② 停止所有從庫slave(所有庫操作)
stop slave;
reset slave all;
③ 重做主從復制(db02、db03)
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='repl',
MASTER_PASSWORD='123';
④ 啟動slave
start slave;
? 啟動之后檢查從庫是否為兩個yes show slave status\G
⑤ mha檢查主從復制
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
MySQL Replication Health is OK.
⑥ 啟動mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
檢查切換是否成功
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:12127) is running(0:PING_OK), master:10.0.0.51
? 到此主主節點有切回到db01
1.4.5 設定權重
修改[server1]的權重
[server1]
hostname=10.0.0.51
port=3306
candidate_master=1
check_repl_delay=0
配置說明
candidate_master=1 ----》不管怎樣都切到優先級高的主機,一般在主機性能差異的時候用
check_repl_delay=0 ----》不管優先級高的備選庫,資料延時多久都要往那切
注:
1、多地多中心,設定本地節點為高權重
2、在有半同步復制的環境中,設定半同步復制節點為高權重
3、你覺著哪個機器適合做主節點,配置較高的 、性能較好的
1.5 配置VIP漂移
1.5.1 IP漂移的兩種方式
?? 通過keepalived的方式,管理虛擬IP的漂移
?? 通過MHA自帶腳本方式,管理虛擬IP的漂移
1.5.2 MHA腳本方式
修改mha****組態檔
[root@db03 ~]# grep "script" /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/usr/local/bin/master_ip_failover
? 再主配置中添加VIP腳本
腳本內容
[root@db03 ~]# cat /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '10.0.0.55/24';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
該腳本為軟體自帶,腳本獲取方法:再mha原始碼包中的samples目錄下有該腳本的模板,對該模板進行修改即可使用,路徑如: mha4mysql-manager-0.56/samples/scripts
腳本修改內容
my $vip = '10.0.0.55/24';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
腳本添加執行權限否則mha無法啟動
chmod +x /usr/local/bin/master_ip_failover
手動系結VIP(****主庫)
ifconfig eth0:0 10.0.0.55/24
檢查
[root@db01 ~]# ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:6c:7a:11 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0
inet6 fe80::20c:29ff:fe6c:7a11/64 scope link
valid_lft forever preferred_lft forever
? 至此vip****漂移配置完成
1.5.3 測驗虛擬IP漂移
查看db02的slave資訊
 View Code 現在主從狀態
View Code 現在主從狀態
停掉主庫
[root@db01 ~]# /etc/init.d/mysqld stop
在db03上查看從庫slave資訊
View Code 停掉主庫后的主從資訊
在db01上查看vip資訊
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:6c:7a:11 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.51/24 brd 10.0.0.255 scope global eth0
inet6 fe80::20c:29ff:fe6c:7a11/64 scope link
valid_lft forever preferred_lft forever
在db02上查看vip資訊
[root@db02 ~]# ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:d6:0a:b3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.52/24 brd 10.0.0.255 scope global eth0
inet 10.0.0.55/24 brd 10.0.0.255 scope global secondary eth0:0
inet6 fe80::20c:29ff:fed6:ab3/64 scope link
valid_lft forever preferred_lft forever
? 至此,VIP漂移就測驗成功
1.6 配置binlog-server
1.6.1 配置binlog-server
1)前期準備:
1、準備一臺新的mysql實體(db03),GTID必須開啟,
2、將來binlog接收目錄,不能和主庫binlog目錄一樣
2)停止mha
masterha_stop --conf=/etc/mha/app1.cnf
3)在app1.cnf開啟binlogserver功能
[binlog1]
no_master=1
hostname=10.0.0.53 ----> 主機DB03
master_binlog_dir=/data/mysql/binlog/ ----> binlog保存目錄
4)開啟binlog接收目錄,注意權限
mkdir -p /data/mysql/binlog/
chown -R mysql.mysql /data/mysql
# 進入目錄啟動程式
cd /data/mysql/binlog/ &&\
mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
引數說明:-R 遠程主機
5)啟動mha
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
1.6.2 測驗binlog備份
#查看binlog目錄中的binlog
[root@db03 binlog]# ll
total 44
-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001
#登錄主庫
[root@mysql-db01 ~]# mysql -uroot -p123
#重繪binlog
mysql> flush logs;
#再次查看binlog目錄
[root@db03 binlog]# ll
total 48
-rw-r--r-- 1 root root 285 Mar 8 03:11 mysql-bin.000001
-rw-r--r-- 1 root root 143 Mar 8 04:00 mysql-bin.000002
1.7 mysql中間件Atlas
1.7.1 atlas簡介
Atlas是由 Qihoo 360公司Web平臺部基礎架構團隊開發維護的一個基于MySQL協議的資料中間層專案,它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基礎上,修改了大量bug,添加了很多功能特性,目前該專案在360公司內部得到了廣泛應用,很多MySQL業務已經接入了Atlas平臺,每天承載的讀寫請求數達幾十億條,
同時,有超過50家公司在生產環境中部署了Atlas,超過800人已加入了我們的開發者交流群,并且這些數字還在不斷增加,而且安裝方便,配置的注釋寫的蠻詳細的,都是中文,
Atlas官方鏈接: https://github.com/Qihoo360/Atlas/blob/master/README_ZH.md
Atlas下載鏈接: https://github.com/Qihoo360/Atlas/releases
1.7.2 主要功能
讀寫分離、從庫負載均衡、自動分表、IP過濾
SQL陳述句黑白名單、DBA可平滑上下線DB、自動摘除宕機的DB
Atlas相對于官方MySQL-Proxy的優勢
1.將主流程中所有Lua代碼用C重寫,Lua僅用于管理介面
2.重寫網路模型、執行緒模型
3.實作了真正意義上的連接池
4.優化了鎖機制,性能提高數十倍
1.7.3 使用場景
Atlas是一個位于前端應用與后端MySQL資料庫之間的中間件,它使得應用程式員無需再關心讀寫分離、分表等與MySQL相關的細節,可以專注于撰寫業務邏輯,同時使得DBA的運維作業對前端應用透明,上下線DB前端應用無感知,
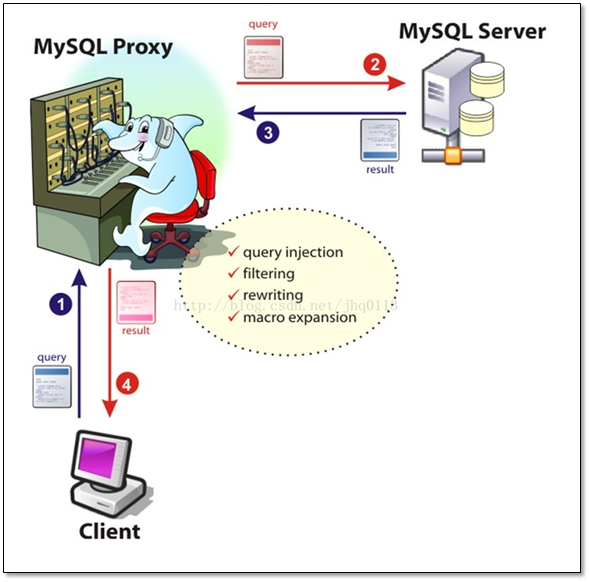
Atlas是一個位于應用程式與MySQL之間中間件,在后端DB看來,Atlas相當于連接它的客戶端,在前端應用看來,Atlas相當于一個DB,
Atlas作為服務端與應用程式通訊,它實作了MySQL的客戶端和服務端協議,同時作為客戶端與MySQL通訊,它對應用程式屏蔽了DB的細節,同時為了降低MySQL負擔,它還維護了連接池.
1.7.4 企業讀寫分離及分庫分表其他方案介紹
Mysql-proxy(oracle)
Mysql-router(oracle)
Atlas (Qihoo 360)
Atlas-sharding (Qihoo 360)
Cobar(是阿里巴巴(B2B)部門開發)
Mycat(基于阿里開源的Cobar產品而研發)
TDDL Smart Client的方式(淘寶)
Oceanus(58同城資料庫中間件)
OneProxy(原支付寶首席架構師樓方鑫開發 )
vitess(谷歌開發的資料庫中間件)
Heisenberg(百度)
TSharding(蘑菇街白輝)
Xx-dbproxy(金山的Kingshard、當當網的sharding-jdbc )
amoeba
1.7.5 安裝Atlas
軟體獲取地址:https://github.com/Qihoo360/Atlas/releases
注意:
1、Atlas只能安裝運行在64位的系統上
2、Centos 5.X安裝 Atlas-XX.el5.x86_64.rpm,Centos 6.X安裝Atlas-XX.el6.x86_64.rpm,
3、后端mysql版本應大于5.1,建議使用Mysql 5.6以上
Atlas (普通) : Atlas-2.2.1.el6.x86_64.rpm
Atlas (分表) : Atlas-sharding_1.0.1-el6.x86_64.rpm
下載安裝atlas
wget https://github.com/Qihoo360/Atlas/releases/download/2.2.1/Atlas-2.2.1.el6.x86_64.rpm
rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
? 至此安裝完成
1.7.6 配置Atlas組態檔
atlas組態檔中的密碼需要加密,可以使用,軟體自帶的加密工具進行加密
cd /usr/local/mysql-proxy/conf/
/usr/local/mysql-proxy/bin/encrypt 密碼 ---->制作加密密碼
生產密文密碼:
[root@db03 bin]# /usr/local/mysql-proxy/bin/encrypt 123
3yb5jEku5h4=
[root@db03 bin]# /usr/local/mysql-proxy/bin/encrypt mha
O2jBXONX098=
編輯組態檔
vim /usr/local/mysql-proxy/conf/test.cnf
[mysql-proxy]
admin-username = user
admin-password = pwd
proxy-backend-addresses = 10.0.0.55:3306
proxy-read-only-backend-addresses = 10.0.0.52:3306,10.0.0.53:3306
pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098=
daemon = true
keepalive = true
event-threads = 8
log-level = message
log-path = /usr/local/mysql-proxy/log
sql-log=ON
proxy-address = 0.0.0.0:33060
admin-address = 0.0.0.0:2345
charset=utf8
組態檔內為全中文注釋,這里有一份較為詳細的解釋:
View Code Atlas組態檔說明
1.7.7 啟動Atlas
撰寫一個atlas的管理腳本,當然也可以寫腳本,可以直接手動的管理:
/usr/local/mysql-proxy/bin/mysql-proxyd test start #啟動
/usr/local/mysql-proxy/bin/mysql-proxyd test stop #停止
/usr/local/mysql-proxy/bin/mysql-proxyd test restart #重啟
注意:test是組態檔的名稱
腳本內容:
View Code Atas管理腳本
檢查埠是否正常
[root@db03 ~]# netstat -lntup|grep mysql-proxy
tcp 0 0 0.0.0.0:33060 0.0.0.0:* LISTEN 2125/mysql-proxy
tcp 0 0 0.0.0.0:2345 0.0.0.0:* LISTEN 2125/mysql-proxy
1.7.8 Atlas管理操作
登入管理介面
[root@db03 ~]# mysql -uuser -ppwd -h127.0.0.1 -P2345
查看幫助資訊
mysql> SELECT * FROM help;
查看后端的代理庫
mysql> SELECT * FROM backends;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.55:3306 | up | rw |
| 2 | 10.0.0.52:3306 | up | ro |
| 3 | 10.0.0.53:3306 | up | ro |
+-------------+----------------+-------+------+
3 rows in set (0.00 sec)
平滑摘除mysql
mysql> REMOVE BACKEND 2;
Empty set (0.00 sec)
檢查是否摘除
mysql> SELECT * FROM backends;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.55:3306 | up | rw |
| 2 | 10.0.0.53:3306 | up | ro |
+-------------+----------------+-------+------+
2 rows in set (0.00 sec)
保存到組態檔中
mysql> SAVE CONFIG;
將節點再添加回來
mysql> add slave 10.0.0.52:3306;
Empty set (0.00 sec)
查看是否添加成功
mysql> SELECT * FROM backends;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.55:3306 | up | rw |
| 2 | 10.0.0.53:3306 | up | ro |
| 3 | 10.0.0.52:3306 | up | ro |
+-------------+----------------+-------+------+
3 rows in set (0.00 sec)
保存到組態檔中
mysql> SAVE CONFIG;
1.7.9 連接資料庫查看負載
通過atlas登陸資料,注意,使用的是資料庫上的用戶及密碼
shell> mysql -umha -pmha -h127.0.0.1 -P33060
第一次查詢server_id
mysql> show variables like "server_id";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 53 |
+---------------+-------+
1 row in set (0.00 sec)
第二次查詢server_id
mysql> show variables like "server_id";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 52 |
+---------------+-------+
1 row in set (0.00 sec)
? *通過上面可以看到負載成功*
1.7.10 讀寫分離的說明
Atlas會透明的將事務陳述句和寫陳述句發送至主庫執行,讀陳述句發送至從庫執行,具體以下陳述句會在主庫執行:
顯式事務中的陳述句
autocommit=0時的所有陳述句
含有select GET_LOCK()的陳述句
除SELECT、SET、USE、SHOW、DESC、EXPLAIN外的,
從庫負載均衡配置
proxy-read-only-backend-addresses=ip1:port1@權重,ip2:port2@權重
1.7.11 Atlas高級功能
自動分表
使用Atlas的分表功能時,首先需要在組態檔test.cnf設定tables引數,
tables引數設定格式:資料庫名.表名.分表欄位.子表數量,比如:
你的資料庫名叫school,表名叫stu,分表欄位叫id,總共分為2張表,那么就寫為school.stu.id.2,如果還有其他的分表,以逗號分隔即可,
用戶需要手動建立2張子表(stu_0,stu_1,注意子表序號是從0開始的),
所有的子表必須在DB的同一個database里,
當通過Atlas執行(SELECT、DELETE、UPDATE、INSERT、REPLACE)操作時,Atlas會根據分表結果(id%2=k),定位到相應的子表(stu_k),
例如,執行select * from stu where id=3;,Atlas會自動從stu_1這張子表回傳查詢結果,
但如果執行SQL陳述句(select * from stu;)時不帶上id,則會提示執行stu表不存在,
Atles功能的說明
Atlas暫不支持自動建表和跨庫分表的功能,
Atlas目前支持分表的陳述句有SELECT、DELETE、UPDATE、INSERT、REPLACE,
IP****過濾:client-ips
該引數用來實作IP過濾功能,
在傳統的開發模式中,應用程式直接連接DB,因此DB會對部署應用的機器(比如web服務器)的IP作訪問授權,
在引入中間層后,因為連接DB的是Atlas,所以DB改為對部署Atlas的機器的IP作訪問授權,如果任意一臺客戶端都可以連接Atlas,就會帶來潛在的風險,
client-ips引數用來控制連接Atlas的客戶端的IP,可以是精確IP,也可以是IP段,以逗號分隔寫在一行上即可,
如: client-ips=192.168.1.2, 192.168.2
這就代表192.168.1.2這個IP和192.168.2.*這個段的IP可以連接Atlas,其他IP均不能連接,如果該引數不設定,則任意IP均可連接Atlas,如果設定了client-ips引數,且Atlas前面掛有LVS,則必須設定lvs-ips引數,否則可以不設定lvs-ips,
SQL****陳述句黑白名單功能: Atlas會屏蔽不帶where條件的delete和update操作,以及sleep函式,
1.8 Atlas-Sharding版本
1.8.1 版本介紹
Sharding的基本思想就是把一個資料表中的資料切分成多個部分, 存放到不同的主機上去(切分的策略有多種), 從而緩解單臺機器的性能跟容量的問題.
sharding是一種水平切分, 適用于單表資料龐大的情景. 目前atlas支持靜態的
sharding方案, 暫時不支持資料的自動遷移以及資料組的動態加入.
Atlas以表為單位sharding, 同一個資料庫內可以同時共有sharding的表和不sharding的表, 不sharding的表資料存在未sharding的資料庫組中.
目前Atlas sharding支持insert, delete, select, update陳述句, 只支持不跨shard的事務. 所有的寫操作如insert, delete, update只能一次命中一個組, 否則會報"ERROR 1105 (HY000):write operation is only allow to one dbgroup!"錯誤.
由于sharding取替了Atlas的分表功能, 所以在Sharding分支里面, Atlas單機分表的功能已經移除, 配置tables將不會再有效.
1.8.2 Atlas-Sharding架構
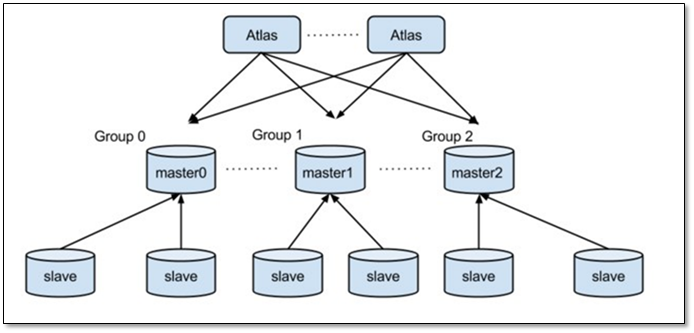
1.8.3 Sharding配置示例
Atlas支持非sharding跟sharding的表共存在同一個Atlas中, 2.2.1之前的配置可以直接運行. 之前的配置如
proxy-backend-addresses = 192.168.0.12:3306
proxy-read-only-backend-addresses = 192.168.0.13:3306,192.168.0.14:3306 ...
這配置了一個master和兩個slave,這屬于非sharding的組, 所有非sharding的表跟陳述句都會發往這個組內.
所以之前沒有Sharding的Atlas的表可以無縫的在新版上使用,
? 注意: 非Sharding的組只能配置一個, 而sharding的組可以配置多個. 下面的配置, 配置了Sharding的組, 注意與上面的配置區分
[shardrule-0]
table = test.sharding_test
分表名,有資料庫+表名組成 t
ype = range
sharding型別:range 或 hash
shard-key = id
sharding 欄位
groups = 0:0-999,1:1000-1999
分片的group,如果是range型別的sharding,則groups的格式是:group_id:id范圍,如果是hash型別的sharding,則groups的格式是:group_id,例如groups = 0, 1
[group-0]
proxy-backend-addresses=192.168.0.15:3306
proxy-read-only-backend-addresses=192.168.0.16:3306
[group-1]
proxy-backend-addresses=192.168.0.17:3306
proxy-read-only-backend-addresses=192.168.0.18:3306
1.8.4 Sharding限制
關于支持的陳述句
Atlas sharding只對sql陳述句提供有限的支持, 目前支持基本的Select, insert/replace, delete,update陳述句,支持全部的Where語法(SQL-92標準), 不支持DDL(create drop alter)以及一些管理陳述句,DDL請直連MYSQL執行, 請只在Atlas上執行Select, insert, delete, update(CRUD)陳述句.
對于以下陳述句, 如果陳述句命中了多臺dbgroup, Atlas均未做支持(如果陳述句只命中了一個dbgroup, 如 select count(*) from test where id < 1000, 其中dbgroup0范圍是0 - 1000, 那么這些特性都是支持的)Limit Offset(支持Limit)
Order by
Group by Join
ON
Count, Max, Min等函式
增加節點
注意: 暫時只支持range方式的節點擴展, hash方式由于需要資料遷移, 暫時未做支持.
擴展節點在保證原來節點的范圍不改變的情況下, 如已有dbgroup0為范圍0 - 999, dbgroup1為范圍 1000-1999, 這個時候可以增加范圍>2000的節點. 如增加一個節點為2000 - 2999, 修改組態檔, 重啟Atlas即可.
來源:博客園 http://dwz.date/d8qV
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】【面試】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234614.html
標籤:Java