摘要:性能優化指在不影響系統運行正確性的前提下,使之運行得更快,完成特定功能所需的時間更短,或擁有更強大的服務能力,
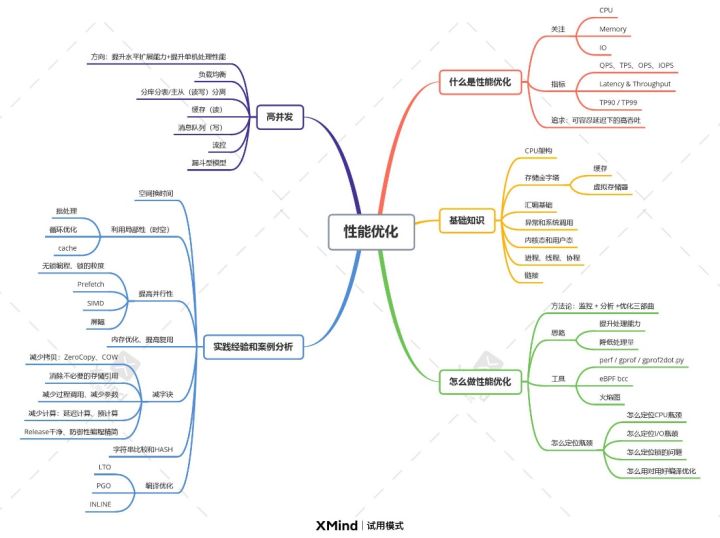
#一、思維導圖
#二、什么是性能優化?
性能優化指在不影響系統運行正確性的前提下,使之運行得更快,完成特定功能所需的時間更短,或擁有更強大的服務能力,
##關注
不同程式有不同的性能關注點,比如科學計算關注運算速度,游戲引擎注重渲染效率,而服務程式追求吞吐能力,
服務器一般都是可水平擴展的分布式系統,系統處理能力取決于單機負載能力和水平擴展能力,所以,提升單機性能和提升水平擴展能力是兩個主要方向,理論上系統水平方向可以無限擴展,但水平擴展后往往導致通信成本飆升(甚至瓶頸),同時面臨單機處理能力下降的問題,
##指標
衡量單機性能有很多指標,比如:QPS(Query Per Second)、TPS、OPS、IOPS、最大連接數、并發數等評估吞吐的指標,
CPU為了提高吞吐,會把指令執行分為多個階段,會搞指令Pipeline,同樣,軟體系統為了提升處理能力,往往會引入批處理(攢包),跟CPU流水線會引起指令執行Latency增加一樣,伴隨著系統負載增加也會導致延遲(Latency)增加,可見,系統吞吐和延遲是兩個沖突的目標,
顯然,過高的延遲是不能接受的,所以,服務器性能優化的目標往往變成:追求可容忍延遲(Latency)下的最大吞吐(Throughput),
延遲(也叫回應時間:RT)不是固定的,通常在一個范圍內波動,我們可以用平均時延去評估系統性能,但有時候,平均時延是不夠的,這很容易理解,比如80%的請求都在10毫秒以內得到回應,但20%的請求時延超過2秒,而這20%的高延遲可能會引發投訴,同樣不可接受,
一個改進措施是使用TP90、TP99之類的指標,它不是取平均,而是需確保排序后90%、99%請求滿足時延的要求,
通常,執行效率(CPU)是我們的重點關注,但有時候,我們也需要關注記憶體占用、網路帶寬、磁盤IO等,影響性能的因素很多,它是一個復雜而有趣的問題,
#三、基礎知識
能撰寫運行正確的程式不一定能做性能優化,性能優化有更高的要求,這樣講并不是想要嚇阻想做性能優化的工程師,而是實事求是講,性能優化既需要扎實的系統知識,又需要豐富的實踐經驗,只有這樣,你才能具備case by case分析問題解決問題的能力,
所以,相比直接給出結論,我更愿意多花些篇幅講一些基礎知識,我堅持認為底層基礎是理解并掌握性能優化技能的前提,值得花費一些時間研究并掌握這些根技術,
##CPU架構
你需要了解CPU架構,理解運算單元、記憶單元、控制單元是如何既各司其職又相互配合完成作業的,
- 你需要了解CPU如何讀取資料,CPU如何執行任務,
- 你需要了解資料總線,地址總線和控制總線的區別和作用,
- 你需要了解指令周期:取指、譯指、執行、寫回,
- 你需要了解CPU Pipeline,超標量流水線,亂序執行,
- 你需要了解多CPU、多核心、邏輯核、超執行緒、多執行緒、協程這些概念,
##存盤金字塔
CPU的速度和訪存速度相差200倍,高速快取是跨越這個鴻溝的橋梁,你需要理解存盤金字塔,而這個層次結構思維基于著一個稱為區域性原理(principle of locality)的思想,它對軟硬體系統的設計和性能有著極大的影響,
區域性又分為時間區域性和空間區域性,
### 快取
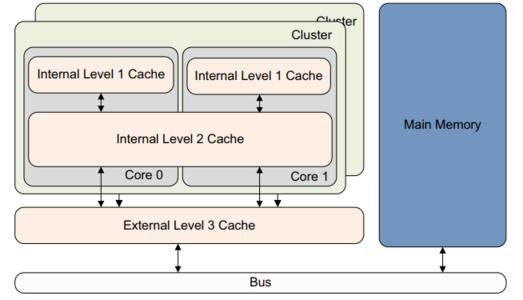
現代計算機系統一般有L1-L2-L3三級快取,
比如在我的系統,我通過進入 /sys/devices/system/cpu/cpu0/cache/index0 1 2 3目錄下查看,
size對應大小、type對應型別、coherency_line_size對應cache line大小,
每個CPU核心有獨立的L1、L2高速快取,所以L1和L2是on-chip快取;L3是多個CPU核心共享的,它是off-chip快取,
- L1快取又分為i-cache(指令快取)和d-cache(資料快取),L1快取通常只有32K/64KB,速度高達4 cycles,
- L2快取能到256KB,速度在8 cycles左右,
- L3則高達30MB,速度32 cycles左右,
- 而記憶體高達數G,訪存時延則在200 cycles左右,
所以CPU->暫存器->L1->L2->L3->記憶體->磁盤構成存盤層級結構:越靠近CPU,存盤容量越小、速度越快、單位成本越高,越遠離CPU,存盤容量越大、速度越慢、單位成本越低,
### 虛擬存盤器(VM)
行程和虛擬地址空間是作業系統的2個核心抽象,
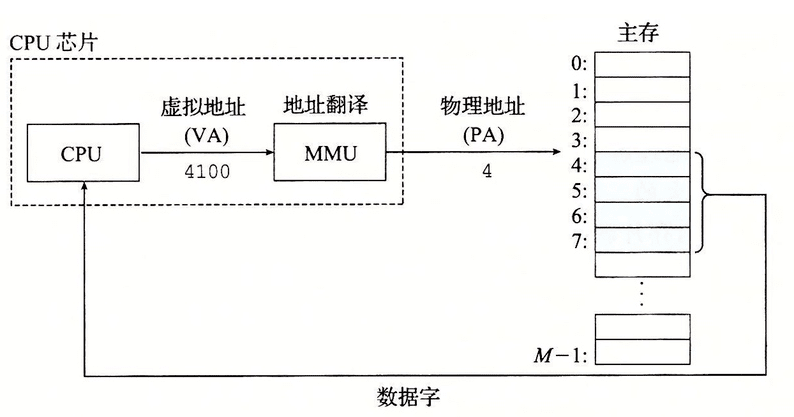
系統中的所有行程共享CPU和主存資源,虛擬存盤是對主存的抽象,它為每個行程提供一個大的、一致的、私有的地址空間,我們gdb除錯的時候,列印出來的變數地址是虛擬地址,
作業系統+CPU硬體(MMU)緊密合作完成虛擬地址到物理地址的翻譯(映射),這個程序總是沉默的自動的進行,不需要應用程式員的任何干預,
每個行程有一個單獨的頁表(Page Table),頁表是一個頁表條目(PTE)的陣列,該表的內容由作業系統管理,虛擬地址空間中的每個頁(4K或者8K)通過查找頁表找到物理地址,頁表往往是層級式的,多級頁表減少了頁表對存盤的需求,命失(Page Fault)將導致頁面調度(Swapping或者Paging),這個懲罰很重,所以,我們要改善程式的行為,讓它有更好的區域性,如果一段時間內訪存的地址過于發散,將導致顛簸(Thrashing),從而嚴重影響程式性能,
為了加速地址翻譯,MMU中增加了一個關于PTE的小的快取,叫翻譯后備緩沖器(TLB),地址翻譯單元做地址翻譯的時候,會先查詢TLB,只有TLB命失才會查詢高速快取(L1-2-3),
## 匯編基礎
雖然寫匯編的場景越來越少,但讀懂匯編依然很有必要,理解高級語言的程式是怎么轉化為匯編語言有助于我們撰寫高質量高性能的代碼,
對于匯編,至少需要了解幾種尋址模式,了解資料操作、分支、傳送、控制跳轉指令,
- 理解C語言的if else、while/do while/for、switch case、函式呼叫是怎么翻譯成匯編代碼,
- 理解ebp+esp暫存器在函式呼叫程序中是如何構建和撤銷堆疊幀的,
- 理解函式引數和回傳值是怎么傳遞的,
## 例外和系統呼叫
例外會導致控制流突變,例外控制流發生在計算機系統的各個層次,例外可以分為四類:
中斷(interrupt):中斷是異步發生的,來自處理器外部IO設備信號,中斷處理程式分上下部,
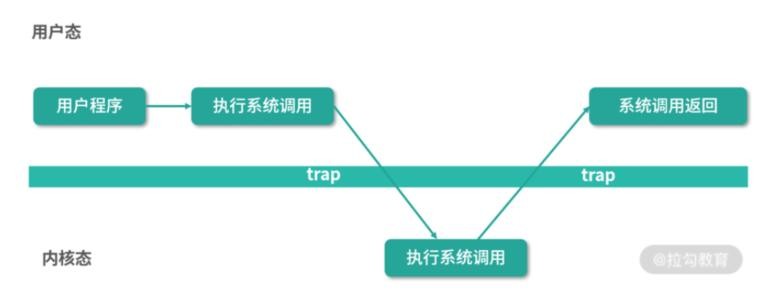
陷阱(trap):陷阱是有意的例外,是執行一條指令的結果,系統呼叫是通過陷阱實作的,陷阱在用戶程式和內核之間提供一個像程序呼叫一樣的介面:系統呼叫,
故障(fault):故障由錯誤情況引起,它有可能被故障處理程式修復,故障發生,處理器將控制轉移到故障處理程式,缺頁(Page Fault)是經典的故障實體,
終止(abort):終止是不可恢復的致命錯誤導致的結果,通常是硬體錯誤,會終止程式的執行,
系統呼叫:
## 內核態和用戶態
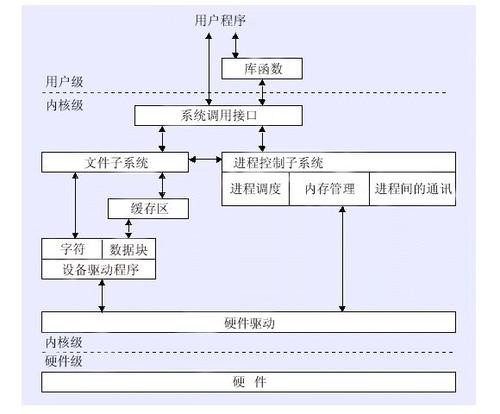
你需要了解作業系統的一些概念,比如內核態和用戶態,應用程式在用戶態運行我們撰寫的邏輯,一旦呼叫系統呼叫,便會通過一個特定的陷阱陷入內核,通過系統呼叫號標識功能,不同于普通函式呼叫,陷入內核態和從內核態回傳需要做背景關系切換,需要做環境變數的保存和恢復作業,它會帶來額外的消耗,我們撰寫的程式應避免頻繁做context swap,提升用戶態的CPU占比是性能優化的一個目標,
## 行程、執行緒、協程
在linux內核中,行程和執行緒是同樣的系統呼叫(clone),行程跟執行緒的區別:執行緒是共享存盤空間的,每個執行流有一個執行控制結構體,這里面會有一個指標,指向地址空間結構,一個行程內的多個執行緒,通過指向同一地址結構實作共享同一虛擬地址空間,
通過fork創建子行程的時候,不會馬上copy一份資料,而是推遲到子行程對地址空間進行改寫,這樣做是合理的,此即為COW(Copy On Write),在應用開發中,也有大量的類似借鑒,
協程是用戶態的多執行流,C語言提供makecontext/getcontext/swapcontext系列介面,很多協程庫也是基于這些介面實作的,微信的協程庫libco(已開源)通過hook慢速系統呼叫(比如write,read)做到靜默替換,非常巧妙,
## 鏈接
C/C++源代碼經編譯鏈接后產生可執行程式,其中資料和代碼分段存盤,我們寫的函式將進入text節,全域資料將進入資料段,未初始化的全域變數進入bss,堆和堆疊向著相反的方向生長,區域變數在堆疊里,引數通過堆疊傳遞,回傳值一般通過eax暫存器回傳,
想要程式運行的更快,最好把相互呼叫,關系緊密的函式放到代碼段相近的地方,這樣能提高icache命中性,減少代碼量、減少函式呼叫、減少函式指標同樣能提高i-cache命中性,
行內既避免了堆疊幀建立撤銷的開銷,又避免了控制跳轉對i-cache的沖刷,所以有利于性能,同樣,關鍵路徑的性能敏感函式也應該避免遞回函式,
減少函式呼叫(就地展開)跟封裝是相違背的,有時候,為了性能,我們不得不破壞封裝和損傷可讀性的代碼,這是一個權衡利弊的問題,
## 常識和資料
CPU拷貝資料一般一秒鐘能做到幾百兆,當然每次拷貝的資料長度不同,吞吐不同,
一次函式執行如果耗費超過1000 cycles就比較大了(刨除呼叫子函式的開銷),
pthread_mutex_t是futex實作,不用每次都進入內核,首次加解鎖大概耗時4000-5000 cycles左右,之后,每次加解鎖大概120 cycles,O2優化的時候100 cycles,spinlock耗時略少,
lock記憶體總線+xchg需要50 cycles,一次記憶體屏障要50 cycles,
有一些無鎖的技術,比如CAS,比如linux kernel里的kfifo,主要利用了整型回繞+記憶體屏障,
#四、怎么做性能優化(TODO)
兩個?向:提?運?速度 + 減少計算量,
性能優化監控先?,要基于資料??基于猜測,要搭建能盡量模擬真實運?狀態的壓?測驗環境,在此基于上獲取的profiling資料才是有?的,
方法論:監控 -> 分析 -> 優化 三部曲,
##工具:
perf是linux內核自帶的profiling工具,除之之外還有gprof,但gprof是侵入式的(插樁),編譯的時候需要加-pg引數,會導致運行變慢(慢很多),
perf采集的資料,可以用來生成火焰圖,也可以用gprof2dot.py這個工具來產生比火焰圖更直觀的呼叫圖,這些工具就是我經常用的,
gprof2dot.py鏈接:https://github.com/jrfonseca/gprof2dot/blob/master/gprof2dot.py
性能優化一個重要原則就是用資料說話,而不能憑空猜測,
瓶頸點可能有多個,如果不解決最狹窄的瓶頸點,性能優化就不能達到預期效果,所以性能優化之前一定要先進行性能測驗,摸清家底,建立測驗基線,
例子:之前做SIP協議堆疊,公司的產品需要提高SIP性能,美國的一個團隊經過理論分析,單憑理論分析認為主要是動態記憶體分配是主要瓶頸,把記憶體申請成一大塊記憶體,指標都變成的一大塊記憶體的偏移量,非常難于除錯,最后效果也不好,我們又通過測驗分析的方式重構了程式,性能是它們的五倍,
另外,性能優化要一個點一個點的做,做完一點,馬上做性能驗證,這樣可以避免無用的修改,
#五、幾個具體問題(TODO)
##1. 如何定位CPU瓶頸?
CPU是通常大家最先關注的性能指標,宏觀維度有核的CPU使用率,微觀有函式的CPU cycle數,根據性能的模型,性能規格與CPU使用率是互相關聯的,規格越高,CPU使用率越高,但是處理器的性能往往又受到記憶體帶寬、Cache、發熱等因素的影響,所以CPU使用率和規格引數之間并不是簡單的線性關系,所以性能規格翻倍并不能簡單地翻譯成我們的CPU使用率要優化一倍,
至于CPU瓶頸的定位工具,最有名也是最有用的工具就是perf,它是性能分析的第一步,可以幫我們找到系統的熱點函式,就像人看病一樣,只知道癥狀是不夠的,需要通過醫療機器進一步分析病因,才能對癥下藥,
所以我們通過性能分析工具PMU或者其他工具去進一步分析CPU熱點的原因比如是指令數本身就比較多,還是Cache miss導致的等,這樣在做性能優化的時候不會走偏,
##2. 如何定位IO瓶頸?
系統IO的瓶頸可以通過CPU和負載的非線性關系體現出來,當負載增大時,系統吞吐量不能有效增大,CPU不能線性增長,其中一種可能是IO出現阻塞,
系統的佇列長度特別是發送、寫磁盤執行緒的佇列長度也是IO瓶頸的一個間接指標,
對于網路系統來講,我建議先從外部觀察系統,所謂外部觀察是指通過觀察外部的網路報文交換,可以用tcpdump, wireshark等工具,抓包看一下,
比如我們優化一個RPC專案,它的吞吐量是10TPS,客戶希望是100TPS,我們使用wireshark抓取TCP報文流,可以分析報文之間的時間戳,回應延遲等指標來判斷是否是由網路引起來的,
然后可以通過netstat -i/-s選項查看網路錯誤、重傳等統計資訊,
還可以通過iostat查看cpu等待IO的比例,
IO的概念也可以擴展到行程間通信,
對于磁盤類的應用程式,我們最希望看到寫磁盤有沒有時延、頻率如何,其中一個方法就是通過內核ftrace、perf-event事件來動態觀測系統,比如記錄寫塊設備的起始和回傳時間,這樣我們就可以知道磁盤寫是否有延時,也可以統計寫磁盤時間耗費分布,有一個開源的工具包perf-tools里面包含著iolatency, iosnoop等工具,
##3. 如何定位IO瓶頸?
應用程式常用的IO有兩種:Disk IO和網路IO,判斷系統是否存在IO瓶頸可以通過觀測系統或行程的CPU的IO等待比例來進行,比如使用mpstat、top命令,
系統的佇列長度特別是發送、寫磁盤執行緒的佇列長度也是IO瓶頸的一個重要指標,
對于網路 IO來講,我們可以先使用netstat -i/-s查看網路錯誤、重傳等統計資訊,然后使用sar -n DEV 1和sar -n TCP,ETCP 1查看網路實時的統計資訊,ss (Socket Statistics)工具可以提供每個socket相關的佇列、快取等詳細資訊,
更直接的方法可以用tcpdump, wireshark等工具,抓包看一下,
對于Disk IO,我們可以通過iostat -x -p xxx來查看具體設備使用率和讀寫平均等待時間,如果使用率接近100%,或者等待時間過長,都說明Disk IO出現飽和,
一個更細致的觀察方法就是通過內核ftrace、perf-event來動態觀測Linux內核,比如記錄寫塊設備的起始和回傳時間,這樣我們就可以知道磁盤寫是否有延時,也可以統計寫磁盤時間耗費分布,有一個開源的工具包perf-tools里面包含著iolatency, iosnoop等工具,
##4.如何定位鎖的問題?
大家都知道鎖會引入額外開銷,但鎖的開銷到底有多大,估計很多人沒有實測過,我可以給一個資料,一般單次加解鎖100 cycles,spinlock或者cas更快一點,
使用鎖的時候,要注意鎖的粒度,但鎖的粒度也不是越小越好,太大會增加撞鎖的概率,太小會導致代碼更難寫,
多執行緒場景下,如果cpu利用率上不去,而系統吞吐也上不去,那就有可能是鎖導致的性能下降,這個時候,可以觀察程式的sys cpu和usr cpu,這個時候通過perf如果發現lock的開銷大,那就沒錯了,
如果程式卡住了,可以用pstack把堆疊打出來,定位死鎖的問題,
##5. 如何提?Cache利用率?
記憶體/Cache問題是我們常見的負載瓶頸問題,通常可利用perf等一些通用工具來輔助分析,優化cache的思想可以從兩方面來著手,一個是增加區域資料/代碼的連續性,提升cacheline的利用率,減少cache miss,另一個是通過prefetch,降低miss帶來的開銷,
通過對資料/代碼根據冷熱進行重排磁區,可提升cacheline的有效利用率,當然觸發false-sharing另當別論,這個需要根據運行trace進行深入調整了;
說到prefetch,用過的人往往都有一種體會,現實效果比預期差的比較遠,確實無論是資料prefetch還是代碼prefetch,不確定性太大,我們和無線做過一些實踐,最終以無線輸出預取pattern,編譯器自動插入prefetch的方案,效果還算可以,
剩下的,下次我們接著說!
本文分享自華為云社區《性能之巔:定位和優化程式CPU、記憶體、IO瓶頸》,原文作者:左X偉,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234883.html
標籤:java