Pandas基于時間應用
1 時間處理基礎
Pandas提供了四種型別的生成日期時間的物件:日期時間、時間增量、時間跨度、日期偏移量
(1)日期時間(Date Times):具有時區支持的特定日期和時間,與Python標準庫中的datetime.datetime類似,如2020年12月6日13點37分50秒;
(2)時間增量(Time Deltas):絕對持續時間,用于在指定時間點基礎上增加指定的增量,如在某年月日的基礎上增加2天、增加2個月、減少4小時等,最后產生一個新的時間點;
(3)時間跨度(Time Span):由時間點及其相關周期定義的時間跨度,如連續產生一年四個季度的時間序列;
(4)日期偏移(Date Offsets):以日歷計算的相對持續時間,表示時間間隔,兩個時間點之間的長度,如日、周、月、季度、年,

1.1 獲取當前時刻的時間
獲取當前時刻的時間就是獲取此時此刻與時間相關的資料,除了具體的年、月、日、時、分、秒,還會單獨看年、月、周、日等指標,
1.1.1 回傳當前時刻的日期和時間
回傳當前時刻的日期和時間在Python中借助函式 now() 實作,
from datetime import datetime
datetime.now()
datetime.datetime(2020, 12, 6, 14, 9, 55, 720085)
datetime.date(datetime.now()) # 獲取當前日期
datetime.date(2020, 12, 6)
datetime.time(datetime.now()) # 獲取當前時間
datetime.time(14, 11, 51, 776782)
1.1.2 分別回傳當前時刻的年、月、日
回傳當前時刻的年份在Python中借助函式 year 實作
datetime.now().year
2020
回傳當前時刻的月份在Python中借助函式 month 實作
datetime.now().month
11
回傳當前時刻的日在Excel和Python中都借助函式 day 實作
datetime.now().day
19
1.1.3 回傳當前時刻的周數
與當前時刻的周相關的資料有兩個,一個是當前時刻是一周中的周幾,另一個是回傳當前時刻所在的周在全年的周里面是第幾周,
回傳當前時刻是周幾在Python中借助 weekday() 函式實作,
datetime.now().weekday()+1
4
Attention :Python中周幾是從0開始數的,所以在后面加1
回傳當前時刻所在周的周數,在Python中使用的是 isocalendar() 函式,
datetime.now().isocalendar()
(2020, 47, 4)
2020年的第47周的第4天
datetime.now().isocalendar()[1]
47
1.2 pd.Timestamp創建日期時間物件
Pandas庫也提供了類似的日期時間物件 pd.Timestamp
import pandas as pd
pd.Timestamp("2020-12-06")
Timestamp('2020-12-06 00:00:00')
pd.Timestamp(2020,12,6,13,19,52)
Timestamp('2020-12-06 13:19:52')
pd.Timestamp(year=2020,month=12,day=6,hour=14,minute=19,second=52) # 鍵值對形式指定年月日時分秒
Timestamp('2020-12-06 14:19:52')
pd.Timestamp(2020,12,6,13,19,52).year # 通過year、month、day屬性獲取年月日
2020
1.4 指定日期和時間的格式
借助 date() 函式將日期和時間設定成只展示日期,
datetime.now().date()
datetime.date(2020, 11, 19)
借助 time() 函式將日期和時間設定成只展示時間,
datetime.now().time()
datetime.time(15, 1, 27, 19303)
借助 strftime() 函式可以自定義時間和日期的格式,strftime() 函式是將日期和時間的格式轉化為某些自定義的格式,具體的格式有以下幾種
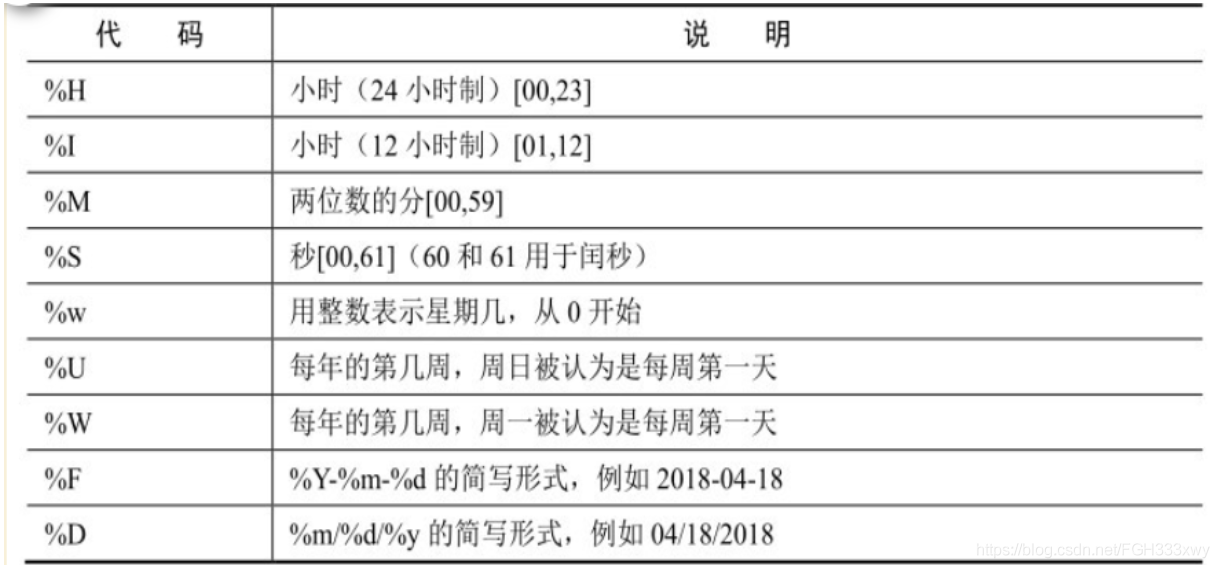
datetime.now().strftime("%F")
'2020-11-19'
datetime.now().strftime("%F %H:%M:%S")
'2020-11-19 15:04:31'
2 時間序列
基于時間序列的資料記錄,可以通過Series、DataFrame的索引值來記錄時間點,可以同步記錄對應時間點的資料元素,
2.1 指定時間點建立時間序列的Series物件
通過 pd.Timestamp 與 pd.DatetimeIndex 方法建立指定時間序列的Series物件
import pandas as pd
import numpy as np
T1 = pd.Series(np.arange(4),index=[pd.Timestamp("2020-12-6"),pd.Timestamp("2020-12-7"),pd.Timestamp("2020-12-8"),pd.Timestamp("2020-12-9")])
print(T1) # 指定4個時間點為索引值
print("="*30)
T1.index # pandas 自動把索引歸類為日期時間索引
2020-12-06 0
2020-12-07 1
2020-12-08 2
2020-12-09 3
dtype: int32
==============================
DatetimeIndex(['2020-12-06', '2020-12-07', '2020-12-08', '2020-12-09'], dtype='datetime64[ns]', freq=None)
T1 = pd.Series(np.arange(4),index=pd.DatetimeIndex(["2020-12-6","2020-12-7","2020-12-8","2020-12-9"]))
print(T1)
print("="*30)
T1.index
2020-12-06 0
2020-12-07 1
2020-12-08 2
2020-12-09 3
dtype: int32
==============================
DatetimeIndex(['2020-12-06', '2020-12-07', '2020-12-08', '2020-12-09'], dtype='datetime64[ns]', freq=None)
2.2 時間范圍函式建立時間序列
pd.date_range()函式用于產生連續的時間序列
pd.date_range(start=None,end=None,periods=None,freq=None,tz=None,normalize=False,name=None,close=None,**kwargs)
start :字串或者類似datetime型別的值,可選,設定開始日期,必須與end引數搭配使用
end :字串或者類似datetime型別的值,可選,設定結束日期
periods :整數,可選,設定要生成的日期周期數(也叫絕對增量),或者說在start指定開始日期的基礎上,按照指定頻率(freq)需要連續生成的日期數量,結合freq引數一起使用
freq :字串或者DateOffest型別值設定需要生成的日期間隔頻率,默認值為"D","D"代表以Day(天)為頻率,可以用數值加頻率擴展頻率范圍,如"2D"代表以2天為一個周期頻率 Attention:在以周為頻率的情況下,都是從周日開始,不一定是指定的開始時間開始
tz :字串或者tzinfor值,可選,用于指定本地時區的名稱
normalize :默認值為False,為True時則設定開始、結束日期的時間為午夜,即零點
name :字串,默認值為None,可以設定生成DatetimeIndex物件的名稱
closed :可選,可選項為{None,"left","right"}可以理解為時間范圍,左右邊界可以設定為開閉區間,"left"表示左閉區間,"right"表示右閉區間,None表示兩邊都為閉區間
pd.date_range(start="2020-12-6 15:02:30",end="2020-12-9 15:02:30") # 生成2020-12-06 15:02:30至2020-12-09 15:02:30按天為間隔的連續時間序列
DatetimeIndex(['2020-12-06 15:02:30', '2020-12-07 15:02:30',
'2020-12-08 15:02:30', '2020-12-09 15:02:30'],
dtype='datetime64[ns]', freq='D')
pd.date_range(start="2020-12-6 15:02:30",periods=4,freq="2D",name="時間索引") # 生成以2020-12-06 15:02:30為始的按2天為間隔的連續4個時間序列
DatetimeIndex(['2020-12-06 15:02:30', '2020-12-08 15:02:30',
'2020-12-10 15:02:30', '2020-12-12 15:02:30'],
dtype='datetime64[ns]', name='時間索引', freq='2D')
pd.date_range(start="2020-12-6 15:02:30",end="2020-12-9 15:02:30",closed="left") # 生成2020-12-06 15:02:30至2020-12-09 15:02:30按天為間隔左閉右開的連續時間序列
DatetimeIndex(['2020-12-06 15:02:30', '2020-12-07 15:02:30',
'2020-12-08 15:02:30'],
dtype='datetime64[ns]', freq='D')
2.3 時間轉換
在不同時間場合,時間使用的要求也不一樣,有需要字串形式的,有需要datetime形式的,有日期、時間的不同組合的,因此需要靈活轉換
2.3.1 pd.to_datetime方法將字串轉為datetime型
pd.to_datetime(arg,errors=“raise”,dayfirst=False,yearfirst=False,utc=None,box=True,format=None,exact=True,unit=None,infer_datetime_format=False,origin=“unix”,cache=False)
arg :指定轉換的資料物件,可以是整型、浮點型、字串、串列、元組、一維陣列、Serise、DataFrame和字典
errors :設定出錯提示方式,可選{"ignore","raise","coercec"},默認值為"raise",如果轉換失敗,則給出出錯提示資訊;"ignore"則不出發出錯提示資訊;"coercec"在轉換程序存在無效時間值時,自動轉為NaT值
dayfirst :指定arg引數轉換時的順序,設定為True時,則先轉換日期,再轉換時間,默認值為False
yearfirst :值為True時則先轉換日期,默認值為False
utc :值為True回傳UTC DatetimeIndex,默認值為None
box :默認值為True回傳DatetimeIndex或相關索引物件;值為False則回傳多維陣列
format :字串,默認值為None,指定字串時間轉化為時間時的strftime的格式,類似strftime方法轉化為時間的使用方法
exact :默認值為True表示精確匹配格式,值為False則允許匹配目標字串中的任何位置
unit :字串,默認值為"ns",對轉換物件指定時間單位(D天、s秒、ma毫秒、ns納秒)
infer_datetime_format :默認值為False,如果為True,且沒有給出轉換固定格式(format引數),且字串日期時間格式確定,則可以提高轉換速度
origin :確定日期的開始點,默認值為"unix",則日期的開始點為1970-01-01,若提供值為Timestamp日期,則以Timestamp的起點日期作為開始點日期
cache :默認值為False,如果為True,則是用唯一的轉換日期快取來應用日期時間轉換,決議重復的日期字串時可以提高轉換速度
import pandas as pd
from datetime import datetime
filename = r"D:\data_test.xlsx"
df = pd.read_excel(filename)
print(df.head())
print("="*30)
print(df.info())
name gender birthday start_work income tel email \
0 趙一 男 1989/8/10 2012-09-08 15000 13611011234 zhaoyi@qq.com
1 王二 男 1990/10/2 2014-03-06 12500 13500012234 wanger@163.com
2 張三 女 1987/3/12 2009-01-08 18500 13515273330 zhangsan@qq.com
3 李四 女 1991/8/16 2014-06-04 13000 13923673388 lisi@gmail.com
4 劉五 女 1992/5/24 2014-08-10 8500 17823117890 liuwu@qq.com
other
0 {教育:本科,專業:電子商務,愛好:運動}
1 {教育:大專,專業:汽修,愛好:}
2 {教育:本科,專業:數學,愛好:打籃球}
3 {教育:碩士,專業:統計學,愛好:唱歌}
4 {教育:本科,專業:美術,愛好:}
==============================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 8 non-null object
1 gender 8 non-null object
2 birthday 8 non-null object
3 start_work 8 non-null datetime64[ns]
4 income 8 non-null int64
5 tel 8 non-null int64
6 email 8 non-null object
7 other 8 non-null object
dtypes: datetime64[ns](1), int64(2), object(5)
memory usage: 640.0+ bytes
None
df.birthday=pd.to_datetime(df.birthday,format="%Y-%m-%d")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 8 non-null object
1 gender 8 non-null object
2 birthday 8 non-null datetime64[ns]
3 start_work 8 non-null datetime64[ns]
4 income 8 non-null int64
5 tel 8 non-null int64
6 email 8 non-null object
7 other 8 non-null object
dtypes: datetime64[ns](2), int64(2), object(4)
memory usage: 640.0+ bytes
data = pd.DataFrame({"客戶":["李","張","劉","宋"],"工資":[3500,2500,1500,500],"日期":["2020-11-19","2020-11-20","2020-12-19","2020-12-20"]},index = ["A","B","C","D"])
print(data.info)
<bound method DataFrame.info of 客戶 工資 日期
A 李 3500 2020-11-19
B 張 2500 2020-11-20
C 劉 1500 2020-12-19
D 宋 500 2020-12-20>
2.3.2 parse()函式將字串格式轉換為時間格式
使用 parse() 函式將字串格式轉換為時間格式
from dateutil.parser import parse
time ="2020-12-06"
print(type(time))
print("="*30)
print(parse(time))
print("="*30)
print(type(parse(time)))
<class 'str'>
==============================
2020-12-06 00:00:00
==============================
<class 'datetime.datetime'>
2.3.3 str方法將時間格式轉換為字串格式
使用 str() 函式將時間格式轉換為字串格式
now = str(datetime.now())
type(now)
str
2.4 時間索引
2.4.1 關鍵字檢索
import numpy as np
import pandas as pd
index = pd.DatetimeIndex(["2020-11-19","2020-11-20","2020-12-19","2020-12-20"])
data = pd.DataFrame(np.arange(1,5),columns= ["num"],index = index)
data
| num | |
|---|---|
| 2020-11-19 | 1 |
| 2020-11-20 | 2 |
| 2020-12-19 | 3 |
| 2020-12-20 | 4 |
data["2020"] # 年索引
| num | |
|---|---|
| 2020-11-19 | 1 |
| 2020-11-20 | 2 |
| 2020-12-19 | 3 |
| 2020-12-20 | 4 |
data["2020-11"] # 年月索引
| num | |
|---|---|
| 2020-11-19 | 1 |
| 2020-11-20 | 2 |
data["2020-11-19":"2020-12-20"] # 指定時間范圍索引
| num | |
|---|---|
| 2020-11-19 | 1 |
| 2020-11-20 | 2 |
| 2020-12-19 | 3 |
| 2020-12-20 | 4 |
上面的索引方法適用于索引是時間的情況下,但是并不是在所有情況下,時間都可以做索引,比如說時間只是一個普通列
from datetime import datetime
from dateutil.parser import parse
index =["A","B","C","D"]
data = pd.DataFrame({"客戶":["李","張","劉","宋"],"成交時間":[parse("2020-11-19"),parse("2020-11-20"),parse("2020-12-19"),parse("2020-12-20")]},index = index)
data
| 客戶 | 成交時間 | |
|---|---|---|
| A | 李 | 2020-11-19 |
| B | 張 | 2020-11-20 |
| C | 劉 | 2020-12-19 |
| D | 宋 | 2020-12-20 |
data[data["成交時間"] == datetime(2020,11,20)] # 選擇成交時間是2020-11-20的行
| 客戶 | 成交時間 | |
|---|---|---|
| B | 張 | 2020-11-20 |
data[(data["成交時間"] > datetime(2020,11,19)) & (data["成交時間"] < datetime(2020,12,21))] # 選擇成交時間大于2020-11-19和成交時間小于2020-11-21的所有行
| 客戶 | 成交時間 | |
|---|---|---|
| B | 張 | 2020-11-20 |
| C | 劉 | 2020-12-19 |
| D | 宋 | 2020-12-20 |
2.4.2 truncate方法截取時間
通過 truncate 方法實作對Series或DataFrame物件日期的截取
truncate(before=None,after=None,axis=None,copy=True)
before :指定行索引值或列索引值,用于截取前面的值
after :指定行索引值或列索引值,用于截取后面的值
axis :0為行索引,1為列索引
copy :復制資料
T = pd.date_range("2020-12-6",periods=5,freq="2D")
df1 = pd.DataFrame(("a","b","c","d","e"),index=T)
print(df1)
print("="*30)
df1.truncate(before = pd.Timestamp("2020-12-07"),after= pd.Timestamp("2020-12-13")) # 截取2020-12-07到2020-12-13這個時間段的資料
0
2020-12-06 a
2020-12-08 b
2020-12-10 c
2020-12-12 d
2020-12-14 e
==============================
| 0 | |
|---|---|
| 2020-12-08 | b |
| 2020-12-10 | c |
| 2020-12-12 | d |
2.5 時間增量處理
時間增量是相對時間點上的絕對時間差異,用不同的單位表示,如天、小時、分鐘、秒,可以是正數也可以是負數
2.5.1 Timedelta()增量函式
Timedelta 是 datetime 的一個子類,用于提供時間增量計算功能
pd.Timedelta(value,unit,days,seconds,microseconds,milliseconds,minutes,hours,weeks)
value :字串、整型、Timedelta、timedelta、np.timedelta64,指定時間增量
unit :字串,可選,時間增量單位,默認值為"ns",可選值為{"Y","M","W","D","days","day","hours","hour",.....}
days,seconds,microseconds,milliseconds,minutes,hours,weeks :用鍵值對形式顯示指定增量數值
(1)字串形式增減日期、小時
import pandas as pd
import datetime as dt
import numpy as np
today = dt.datetime.now()
print(today)
print("="*30)
today.date() + pd.Timedelta("2 day") # 提供增量為兩天的時間增量
2020-12-08 10:24:15.549743
==============================
datetime.date(2020, 12, 10)
today + pd.Timedelta("2 hours") # 提供增量為兩小時的時間增量
datetime.datetime(2020, 12, 8, 12, 24, 15, 549743)
today + pd.Timedelta("-2 hours") # 提供兩小時的時間減量
datetime.datetime(2020, 12, 8, 8, 24, 15, 549743)
(2)以整數和時間形式提供增減量
today + pd.Timedelta(2 ,unit="hours") # 提供增量為兩小時的時間增量
datetime.datetime(2020, 12, 8, 12, 24, 15, 549743)
today + pd.Timedelta(2 ,unit="W") # 提供增量為兩周的時間增量
datetime.datetime(2020, 12, 22, 10, 24, 15, 549743)
(3)以datetime.datetime、np.timedelta64形式提供增減量
today + pd.Timedelta(weeks=2) #提供增量為兩周的時間增量
datetime.datetime(2020, 12, 22, 10, 24, 15, 549743)
today + pd.Timedelta(np.timedelta64(2,"W"))
datetime.datetime(2020, 12, 22, 10, 24, 15, 549743)
2.5.2 to_timedelta()轉為增量函式
pd.to_timedelta(arg,unit=“ns”,box=True,errors=“raise”)
arg :字串、timedelta、類似串列、Series,指定需要轉換為增量的資料物件
unit :增量時間單位,同pd.Timedelta的unit
box :默認值為True回傳Timedelta\TimedeltaIndex結果,值為False則回傳timedelta64型別資料
pd.to_timedelta(np.arange(5),unit="s") # 回傳連續5個秒值的時間增量
TimedeltaIndex(['00:00:00', '00:00:01', '00:00:02', '00:00:03', '00:00:04'], dtype='timedelta64[ns]', freq=None)
2.5.3 timedelta_range()產生連續增量函式
timedelta_range(start=None,end=None,periods=None,freq=None,name==None,closed=None)
start :字串、類似timedelta物件,默認值為None,指定時間增量左邊邊界
end :字串、類似timedelta物件,默認值為None,指定時間增量右邊邊界
periods :整型,默認值為None,指定周期數,即增量個數
freq :字串、DateOffest,默認值為"D",指定增量頻率,可以使用倍數方式指定,如"5D"
name :字串,默認值為None,指定生成TimedeltaIndex的名稱
closed :字串,默認值為None,限制左右區間值得范圍,可選項為{"right","left",None}
pd.timedelta_range(start="1 day",end="10 day",periods=5,name="索引")
TimedeltaIndex([ '1 days 00:00:00', '3 days 06:00:00', '5 days 12:00:00',
'7 days 18:00:00', '10 days 00:00:00'],
dtype='timedelta64[ns]', name='索引', freq=None)
pd.timedelta_range(start="1 day", periods=5,freq= "2D",name="索引")
TimedeltaIndex(['1 days', '3 days', '5 days', '7 days', '9 days'], dtype='timedelta64[ns]', name='索引', freq='2D')
2.5.4 時間增量屬性、增量索引
Timedelta、TimedeltaIndex物件提供了增量相關的屬性,用于增量不同單位的數值的獲取,當想單獨獲取增量的天(days)、秒(seconds)、毫秒(milliseconds)、微妙(microseconds)、納秒(nanoseconds)值時,可以通過上述兩物件所提供的屬性物件進行獲取,
1、Timedelta物件
import pandas as pd
d1 = pd.Timedelta("31 days 10 min 20 sec") # 建立一個Timedelta物件
d1
Timedelta('31 days 00:10:20')
(1) components屬性,以獲取增量的所有值
d1.components # 顯示增量的所有內容
Components(days=31, hours=0, minutes=10, seconds=20, milliseconds=0, microseconds=0, nanoseconds=0)
d1.components[2] # 通過下標值,獲取增量的分鐘值
10
(2) days屬性
d1.days # 從增量中獲取天的數值
31
(3) seconds屬性
d1.seconds # 從增量中獲取秒的數值(分鐘+秒)
620
(3) microseconds屬性
d1.microseconds # 從增量中獲取微秒的數值(分鐘+秒)
0
Attention:Timedelta并沒有提供hours、week等類似的其他屬性,而TimedeltaIndex提供的屬性也略有差異
2、TimedeltaIndex 時間增量索引物件
TimedeltaIndex(data,unit,freq,copy,start,periods,end,closed,name)
data :一維陣列、一維串列,可選,用于建立timedelta類似資料的索引值
unit :整數、浮點數,可選,指定增量時間單位(D、h、m、s、ms、ns)
freq :字串、偏移物件,可選,指定時間頻率,可以傳遞字串"infer",以便在創建時將索引的頻率設定為推斷頻率
copy :可選,默認值True為復制資料,值為False為資料視圖
start :可選, timedelta類似型別,指定增量開始值,如果data引數為None,則用該引數指定timedelta資料的起點
periods :整數,可選,指定值要求大于0,指定增量數,優先end引數設定
end : timedelta類似型別,指定結東時間,可選,如果 periods為None,則生效
closed :字串或默認值None,可選,指定生成值的開閉區間范圍,可選擇值{"left","right", None}
name :可選,指定時間增量索引的名稱
用 Timedeltalndex建立時間增量索引物件
import numpy as np
import datetime as dt
t = pd.TimedeltaIndex(["1 days","10 days","10:20:05",np.timedelta64(10,"D"),dt.timedelta(days=10,seconds=2)])
t
TimedeltaIndex([ '1 days 00:00:00', '10 days 00:00:00', '0 days 10:20:05',
'10 days 00:00:00', '10 days 00:00:02'],
dtype='timedelta64[ns]', freq=None)
t.days
Int64Index([1, 10, 0, 10, 10], dtype='int64')
生成連續時間增量還可以使用 pd.timedelta_range(),方法類似 pd.date_range()
2.6 時間周期處理
周期表示一段范圍的時間,如一天、一月、一季度、一年等,規則的時間周期用pandas中的pd Period物件表示,pd Period_range()產生連續的時間周期序列物件PeriodsIndex
2.6.1 時間周期建立
通過時間周期的建立,可以更加靈活地控制年、月等時間周期的變化,
pd Period(value, freq, year,month,quarter,day,hour,minute,second)
value : Period或 compat.string_types型別,默認值None表示時間段,如4Q2005代表2005年第四季度
freq : 字串,默認值None,指定字串型的 Pandas時間周期,
year : 整數,默認值None,指定年數
month : 整數,默認值1,指定月數
quarter : 整數,默認值None,指定季度數
day : 整數,默認值1,指定天數,
hour : 整數,默認值0,指定小時數,
minute : 整數,默認值0,指定分鐘數
second:整數,默認值0,指定秒數,
M = pd.Period("2020-12",freq="M")
M
Period('2020-12', 'M')
M+2
Period('2021-02', 'M')
2.6.2 時間周期序列
在需要固定時間序列的地方,可以通過 pd.period_range() 函式產生
period_range(start=None,end= None, periods= None, freq=None,name=None)
start : 字串或 period物件,指定周期序列的開始時間點,默認值為None
end : 字串或 period物件,指定周期序列的結東時間點,默認值為None
periods : 整數,指定周期個數,默認值None
freq : 字串或 Dateoffset,指定周期名稱,如Y、MI、D、h、m、、ms、ns,默認值D(天)
name : 字串,默認值None,指定 Periodindex名稱
(1) 以月為周期產生連續的時間序列
M = pd.period_range("2020-12-12","2021-12-12",freq="M")
M
PeriodIndex(['2020-12', '2021-01', '2021-02', '2021-03', '2021-04', '2021-05',
'2021-06', '2021-07', '2021-08', '2021-09', '2021-10', '2021-11',
'2021-12'],
dtype='period[M]', freq='M')
(2) 以季度為周期產生連續的時間序列
Q = pd.period_range("12/12/2020","12/12/2021",freq="Q")
Q
PeriodIndex(['2020Q4', '2021Q1', '2021Q2', '2021Q3', '2021Q4'], dtype='period[Q-DEC]', freq='Q-DEC')
(3)以PeriodIndex物件為基礎建立二維表
a=pd.DataFrame({"韋德":[25,28,23,27,26]},index=Q)
a
| 韋德 | |
|---|---|
| 2020Q4 | 25 |
| 2021Q1 | 28 |
| 2021Q2 | 23 |
| 2021Q3 | 27 |
| 2021Q4 | 26 |
2.7 日期偏移處理
類似時間增量,只存在細微的區別
2.7.1 時間偏移量建立
日期偏移量更加遵循日歷持續時間規則,如 Dateoffset在增加日時總是增加到指定日的同時間,而忽略夏令時等所帶來的時間差異:而 Timedelta()在增加日時,每天增加24小時
pd.DateOffset(n,normalize,**kwds)
n : 整數,默認值為1,指定產生偏移量數
normalize : 默認值為 False,當值為True時將DateOffset添加的時間結果含入到半夜0點,
kwds : 以鍵值對形式指定偏移量周期
import pandas as pd
t1 = pd.Timestamp("2020-12-14")
print(t1)
t1 + pd.DateOffset(n=2,months=3) # 增加2*3=6個月
2020-12-14 00:00:00
Timestamp('2021-06-14 00:00:00')
2.7.2 用offsets物件附帶的方法調整日期
t2 = pd.Timestamp(2020,12,14,13,19,52)
print(t2)
t2 + pd.offsets.YearEnd() # 增加到年度結束日期
2020-12-14 13:19:52
Timestamp('2020-12-31 13:19:52')
t2 + pd.offsets.MonthBegin(n=2) # 增加到2個月后的月初
Timestamp('2021-02-01 13:19:52')
2.7.3 用pd.DateOffset()函式調整日期
t1 + pd.DateOffset(n=2,months=3)
Timestamp('2021-06-14 00:00:00')
2.8 時間運算
2.8.1 計算時間差
在Python中兩個時間做差會回傳一個timedelta物件,該物件中包含天數、秒、微秒三個等級,如果要獲取小時、分鐘,則需要進行換算,
time_cha = datetime(2020,11,19,18,5,50)-datetime(2020,11,18,17,5,50)
time_cha
datetime.timedelta(days=1, seconds=3600)
差值為1天3600秒
time_cha.days
1
time_cha.seconds
3600
import pandas as pd
from datetime import datetime
filename = r"D:\data_test.xlsx"
df = pd.read_excel(filename)
print(df.head())
print("="*30)
df.birthday=pd.to_datetime(df.birthday,format="%Y-%m-%d")
df["年齡"]= datetime.now().year-df.birthday.dt.year
print(df.head())
name gender birthday start_work income tel email \
0 趙一 男 1989/8/10 2012-09-08 15000 13611011234 zhaoyi@qq.com
1 王二 男 1990/10/2 2014-03-06 12500 13500012234 wanger@163.com
2 張三 女 1987/3/12 2009-01-08 18500 13515273330 zhangsan@qq.com
3 李四 女 1991/8/16 2014-06-04 13000 13923673388 lisi@gmail.com
4 劉五 女 1992/5/24 2014-08-10 8500 17823117890 liuwu@qq.com
other
0 {教育:本科,專業:電子商務,愛好:運動}
1 {教育:大專,專業:汽修,愛好:}
2 {教育:本科,專業:數學,愛好:打籃球}
3 {教育:碩士,專業:統計學,愛好:唱歌}
4 {教育:本科,專業:美術,愛好:}
==============================
name gender birthday start_work income tel email \
0 趙一 男 1989-08-10 2012-09-08 15000 13611011234 zhaoyi@qq.com
1 王二 男 1990-10-02 2014-03-06 12500 13500012234 wanger@163.com
2 張三 女 1987-03-12 2009-01-08 18500 13515273330 zhangsan@qq.com
3 李四 女 1991-08-16 2014-06-04 13000 13923673388 lisi@gmail.com
4 劉五 女 1992-05-24 2014-08-10 8500 17823117890 liuwu@qq.com
other 年齡
0 {教育:本科,專業:電子商務,愛好:運動} 31
1 {教育:大專,專業:汽修,愛好:} 30
2 {教育:本科,專業:數學,愛好:打籃球} 33
3 {教育:碩士,專業:統計學,愛好:唱歌} 29
4 {教育:本科,專業:美術,愛好:} 28
2.8.2 時間偏移
時間偏移是指給時間往前推或往后推一段時間,即加或減一段時間
在Python中實作時間偏移的方式有兩種:第一種是借助timedelta,但是它只能偏移天、秒、微秒單位的時間;第二種是用Pandas中的日期偏移量(date offset),
● timedelta
由于timedelta只支持天、秒、微秒單位的時間運算,如果是其他單位的時間運算,則需要換算成以上三種單位中的一種方可進行偏移,
from datetime import timedelta
data = datetime(2020,11,19,18,5,50)
data + timedelta(days=1)
datetime.datetime(2020, 11, 20, 18, 5, 50)
data + timedelta(seconds=1)
datetime.datetime(2020, 11, 19, 18, 5, 51)
data - timedelta(days=1)
datetime.datetime(2020, 11, 18, 18, 5, 50)
data - timedelta(seconds=1)
datetime.datetime(2020, 11, 19, 18, 5, 49)
● date offset
date offset 可以直接實作天、小時、分鐘單位的時間偏移,不需要換算,相比timedelta要方便一些,
from pandas.tseries.offsets import Day,Hour,Minute
data = datetime.now()
data
datetime.datetime(2020, 11, 19, 18, 21, 20, 937641)
data + Day(1)
Timestamp('2020-11-20 18:21:20.937641')
data + Hour(1)
Timestamp('2020-11-19 19:21:20.937641')
data + Minute(10)
Timestamp('2020-11-19 18:31:20.937641')
data - Day(1)
Timestamp('2020-11-18 18:21:20.937641')
data - Hour(1)
Timestamp('2020-11-19 17:21:20.937641')
data - Minute(10)
Timestamp('2020-11-19 18:11:20.937641')
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/234904.html
標籤:python