本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理
以下文章來源于騰訊云 作者:昱良

在本文中,我們將介紹一些用于資料科學方面的Python庫,它們并不像pandas、scikit-learn 和 matplotlib那么知名,但一樣非常實用的庫,歡迎大家評論區補充~
1、Wget
提取資料,尤其是從網路上提取資料,是資料科學家的主要任務之一,Wget是一個免費的實用程式,用于從Web上進行非互動式檔案下載,它支持HTTP,HTTPS和FTP協議,以及通過HTTP代理進行檢索,由于它是非互動式的,即使用戶沒有登錄也可以在后臺運行,因此,如果你需要下載一個網站或頁面中的所有圖片時,wget 就可以幫到你
安裝:
$ pip install wget
示例:
import wget url = http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3 filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename razorback.mp3
2、Pendulum
如果你還在苦惱Python中時間日期的處理,那么你需要Pendulum,它是一個Python包,用于簡化datetime操作,它是Python原生類的一個臨時替代,
安裝:
$ pip install pendulum
例子:
import pendulum dt_toronto = pendulum.datetime(2012, 1, 1, tz= America/Toronto ) dt_vancouver = pendulum.datetime(2012, 1, 1, tz= America/Vancouver ) print(dt_vancouver.diff(dt_toronto).in_hours()) 3
3、Imbalanced-learn
大多數分類演算法在每個類的樣本數量幾乎都是一樣的情況下是最有效的,但實際作業中大多數是不平衡的資料集,這些資料集對機器學習演算法的學習階段和后續預測都可能有影響,幸運的是,創imbalance -learn庫可以解決這個問題,它與scikit-learn兼容,是scikit- learning -contrib專案的一部分,下次遇到不平衡的資料集的情況,請別忘了它,
安裝:
pip install -U imbalanced-learn # or conda install -c conda-forge imbalanced-learn
4、FlashText
在自然語言處理(NLP)任務中清理文本資料通常需要替換關鍵字或從句子中提取關鍵字,通常,這樣的操作可以用正則運算式來完成,但是如果要搜索的詞匯量達到數千,那么這些操作就會變得很繁瑣,
Python的FlashText模塊基于FlashText演算法,為這種情況提供了合適的替代方案,FlashText最棒的地方是,它的運行與你的搜索量無關,
安裝:
$ pip install flashtext
例子:
1)提取關鍵詞
from flashtext import KeywordProcessor keyword_processor = KeywordProcessor() # keyword_processor.add_keyword(<unclean name>, <standardised name>) keyword_processor.add_keyword( Big Apple , New York ) keyword_processor.add_keyword( Bay Area ) keywords_found = keyword_processor.extract_keywords( I love Big Apple and Bay Area. ) keywords_found [ New York , Bay Area ]
2)替代關鍵詞
keyword_processor.add_keyword( New Delhi , NCR region ) new_sentence = keyword_processor.replace_keywords( I love Big Apple and new delhi. ) new_sentence I love New York and NCR region.
5、FuzzyWuzzy
這個名稱聽起來很奇怪,但是在字串匹配方面,FuzzyWuzzy是一個非常有用的庫,它可以方便地實作字串匹配率等操作,它還可以方便地匹配保存在不同資料庫中的記錄,
安裝:
$ pip install fuzzywuzzy
例子:
from fuzzywuzzy import fuzz from fuzzywuzzy import process # Simple Ratio fuzz.ratio("this is a test", "this is a test!") 97 # Partial Ratio fuzz.partial_ratio("this is a test", "this is a test!") 100
6、PyFlux
時間序列分析是機器學習中最常見的問題之一,PyFlux是Python中的一個開源庫,它是為處理時間序列問題而構建的,該庫擁有一系列很優秀的現代時間序列模型,諸如ARIMA、GARCH和VAR模型等,簡而言之,PyFlux提供了一種時間序列建模的概率方法,
安裝:
pip install pyflux
7、IPyvolume
資料科學很重要的一部分就是交流結果,可視化結果顯示可以給你提供一個巨大的優勢,IPyvolume是一個Python庫,用于可視化Jupyter筆記本中的3D容量和符號(例如3D散點圖),只需少量的配置,
安裝 :
Using pip $ pip install ipyvolume Conda/Anaconda $ conda install -c conda-forge ipyvolume
例子: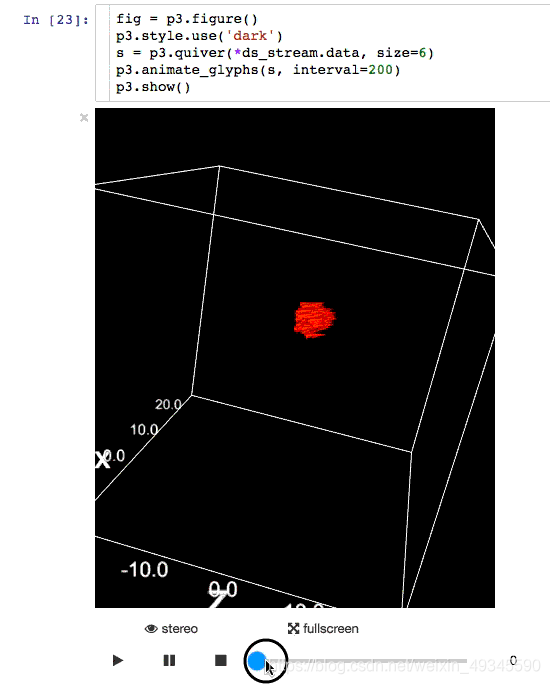
繪制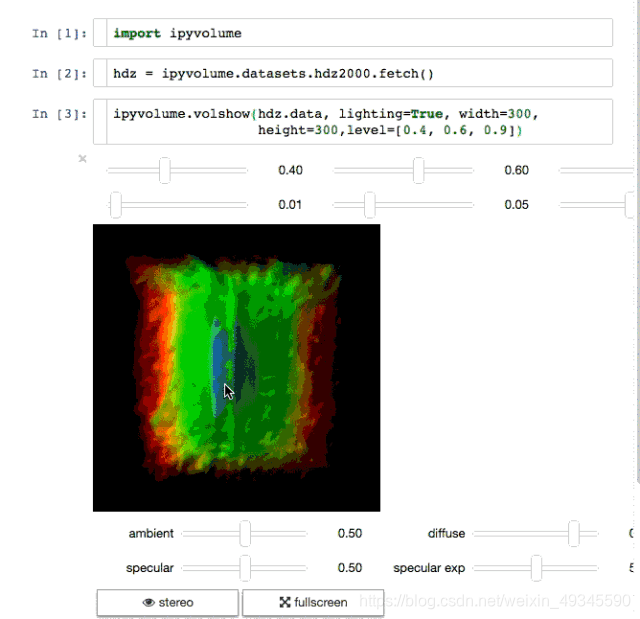
8、Dash
Dash是一個用于構建web應用程式的高效Python框架,它基于FlaskPlotty.js 和 Response.js 之上,將下拉選單和圖形等UI元素與Python分析代碼捆綁在一起,而不需要使用JavaScript,Dash非常適合構建可以在web瀏覽器中呈現的資料可視化應用程式,
安裝:
pip install dash==0.29.0 # The core dash backend pip install dash-html-components==0.13.2 # HTML components pip install dash-core-components==0.36.0 # Supercharged components pip install dash-table==3.1.3 # Interactive DataTable component (new!)
例子:
下面的示例顯示了具有下拉功能的高度互動式圖,當用戶在下拉選單中選擇一個值時,應用程式代碼將動態地將資料從Google Finance 匯出到panda DataFrame,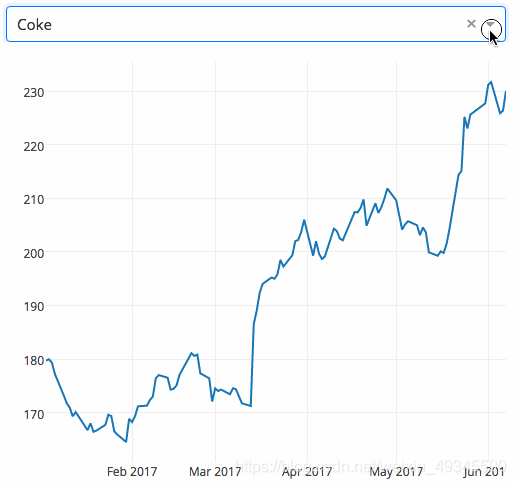
9、Gym
Gym是開發和對比強化學習演算法的工具,它兼容任何資料科學庫,如TensorFlow或Theano,是一個測驗問題的集合,也叫環境,你可以用它來計算強化學習演算法,這些環境有一個共享介面,允許用戶撰寫通用演算法,
安裝:
pip install gym
例子:
以下示例將在 CartPole-v0環境中,運行 1000 次,在每一步渲染環境,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/235658.html
標籤:其他
上一篇:【C++學習筆記】一分鐘帶你了解C++中new和delete的使用方法!
下一篇:05全球IP歸屬地查詢工具