資料清洗是資料分析的必備環節,在進行分析程序中,會有很多不符合分析要求的資料,例如重復、錯誤、缺失、例外類資料,
一、 重復值處理
資料錄入程序、資料整合程序都可能會產生重復資料,直接洗掉是重復資料處理的主要方法,pandas提供查看、處理重復資料的方法duplicated和drop_duplicates,以如下資料為例:
>sample = pd.DataFrame({'id':[1,1,1,3,4,5],
'name':['Bob','Bob','Mark','Miki','Sully','Rose'],
'score':[99,99,87,77,77,np.nan],
'group':[1,1,1,2,1,2],})
>sample
group id name score
0 1 1 Bob 99.0
1 1 1 Bob 99.0
2 1 1 Mark 87.0
3 2 3 Miki 77.0
4 1 4 Sully 77.0
5 2 5 Rose NaN
發現重復資料通過duplicated方法完成,如下所示,可以通過該方法查看重復的資料,
>sample[sample.duplicated()]
group id name score
1 1 1 Bob 99.0
需要去重時,可drop_duplicates方法完成:
#Python學習交流群:778463939
>sample.drop_duplicates()
group id name score
0 1 1 Bob 99.0
2 1 1 Mark 87.0
3 2 3 Miki 77.0
4 1 4 Sully 77.0
5 2 5 Rose NaN
drop_duplicates方法還可以按照某列去重,例如去除id列重復的所有記錄:
>sample.drop_duplicates('id')
group id name score
0 1 1 Bob 99.0
3 2 3 Miki 77.0
4 1 4 Sully 77.0
5 2 5 Rose NaN
二、 缺失值處理
缺失值是資料清洗中比較常見的問題,缺失值一般由NA表示,在處理缺失值時要遵循一定的原則,
首先,需要根據業務理解處理缺失值,弄清楚缺失值產生的原因是故意缺失還是隨機缺失,再通過一些業務經驗進行填補,一般來說當缺失值少于20%時,連續變數可以使用均值或中位數填補;分類變數不需要填補,單算一類即可,或者也可以用眾數填補分類變數,
當缺失值處于20%-80%之間時,填補方法同上,另外每個有缺失值的變數可以生成一個指示啞變數,參與后續的建模,當缺失值多于80%時,每個有缺失值的變數生成一個指示啞變數,參與后續的建模,不使用原始變數,
在下圖中展示了中位數填補缺失值和缺失值指示變數的生成程序,
缺失值填補示例
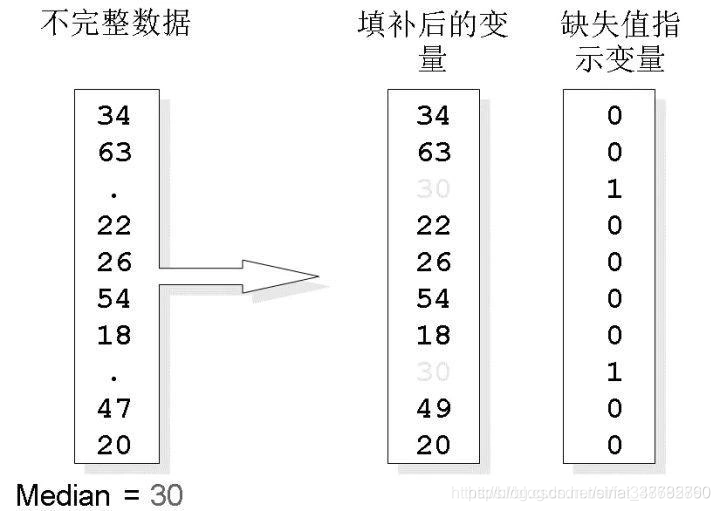
Pandas提供了fillna方法用于替換缺失值資料,其功能類似于之前的replace方法,例如對于如下資料:
> sample
group id name score
0 1.0 1.0 Bob 99.0
1 1.0 1.0 Bob NaN
2 NaN 1.0 Mark 87.0
3 2.0 3.0 Miki 77.0
4 1.0 4.0 Sully 77.0
5 NaN NaN NaN NaN
分步驟進行缺失值的查看和填補如下:
1. 查看缺失情況
在進行資料分析前,一般需要了解資料的缺失情況,在Python中可以構造一個lambda函式來查看缺失值,該lambda函式中,sum(col.isnull())表示當前列有多少缺失,col.size表示當前列總共多少行資料:
>sample.apply(lambda col:sum(col.isnull())/col.size)
group 0.333333
id 0.166667
name 0.166667
score 0.333333
dtype: float64
2. 以指定值填補
pandas資料框提供了fillna方法完成對缺失值的填補,例如對sample表的列score填補缺失值,填補方法為均值:
>sample.score.fillna(sample.score.mean())
0 99.0
1 85.0
2 87.0
3 77.0
4 77.0
5 85.0
Name: score, dtype: float64
當然還可以以分位數等方法進行填補:
>sample.score.fillna(sample.score.median())
0 99.0
1 82.0
2 87.0
3 77.0
4 77.0
5 82.0
Name: score, dtype: float64
3. 缺失值指示變數
pandas資料框物件可以直接呼叫方法isnull產生缺失值指示變數,例如產生score變數的缺失值指示變數:
>sample.score.isnull()
0 False
1 True
2 False
3 False
4 False
5 True
Name: score, dtype: bool
若想轉換為數值0,1型指示變數,可以使用apply方法,int表示將該列替換為int型別,
>sample.score.isnull().apply(int)
0 0
1 1
2 0
3 0
4 0
5 1
Name: score, dtype: int64
三、噪聲值處理
噪聲值指資料中有一個或幾個數值與其他數值相比差異較大,又稱為例外值、離群值(outlier),
對于大部分的模型而言,噪聲值會嚴重干擾模型的結果,并且使結論不真實或偏頗,需要在資料預處理的時候清除所以噪聲值,噪聲值的處理方法很多,對于單變數,常見的方法有蓋帽法、分箱法;多變數的處理方法為聚類法,下面進行詳細介紹:
1. 蓋帽法
蓋帽法將某連續變數均值上下三倍標準差范圍外的記錄替換為均值上下三倍標準差值,即蓋帽處理
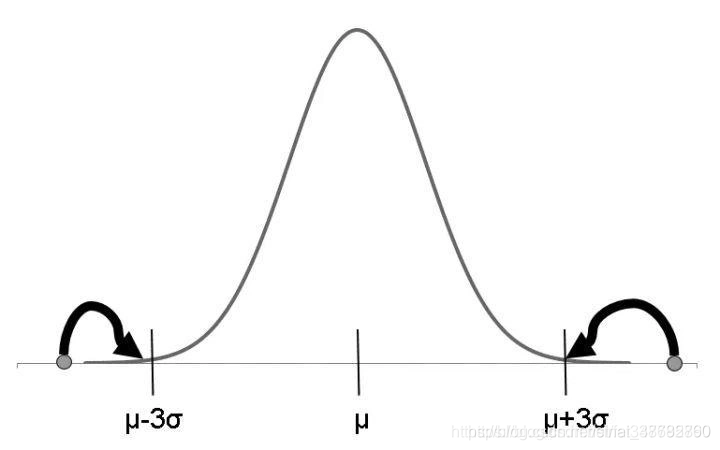
Python中可自定義函式完成蓋帽法,如下所示,引數x表示一個pd.Series列,quantile指蓋帽的范圍區間,默認凡小于百分之1分位數和大于百分之99分位數的值將會被百分之1分位數和百分之99分位數替代:
#Python學習交流群:778463939
>def cap(x,quantile=[0.01,0.99]):
"""蓋帽法處理例外值
Args:
x:pd.Series列,連續變數
quantile:指定蓋帽法的上下分位數范圍
"""
# 生成分位數
Q01,Q99=x.quantile(quantile).values.tolist()
# 替換例外值為指定的分位數
if Q01 > x.min():
x = x.copy()
x.loc[x<Q01] = Q01
if Q99 < x.max():
x = x.copy()
x.loc[x>Q99] = Q99
return(x)
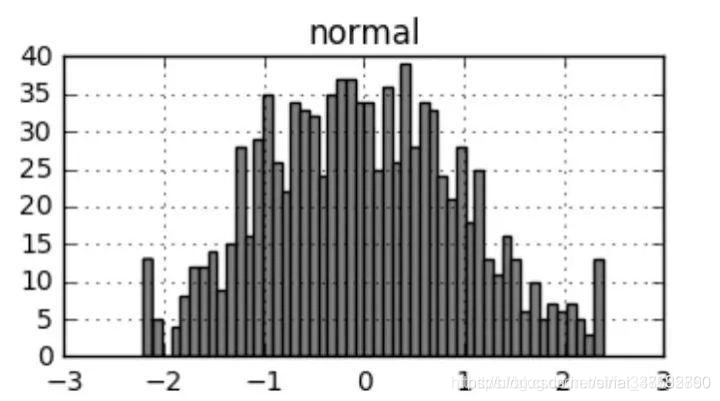
現生成一組服從正態分布的亂數,sample.hist表示產生直方圖,更多繪圖方法會在下一章節進行講解:
>sample = pd.DataFrame({'normal':np.random.randn(1000)})
>sample.hist(bins=50)
對pandas資料框所有列進行蓋帽法轉換,可以以如下寫法,從直方圖對比可以看出蓋帽后極端值頻數的變化,
>new = sample.apply(cap,quantile=[0.01,0.99])
>new.hist(bins=50)
2. 分箱法
分箱法通過考察資料的“近鄰”來光滑有序資料的值,有序值分布到一些桶或箱中,
分箱法包括等深分箱:每個分箱中的樣本量一致;等寬分箱:每個分箱中的取值范圍一致,直方圖其實首先對資料進行了等寬分箱,再計算頻數畫圖,
比如價格排序后資料為:4、8、15、21、21、24、25、28、34
將其劃分為(等深)箱:
-
箱1:4、8、15
-
箱2:21、21、24
-
箱3:25、28、34
將其劃分為(等寬)箱:
-
箱1:4、8
-
箱2:15、21、21、24
-
箱3:25、28、34
分箱法將例外資料包含在了箱子中,在進行建模的時候,不直接進行到模型中,因而可以達到處理例外值的目的,
pandas的qcut函式提供了分箱的實作方法,下面介紹如何具體實作,
等寬分箱:qcut函式可以直接進行等寬分箱,此時需要的待分箱的列和分箱個數兩個引數,如下所示,sample資料的int列為從10個服從標準正態分布的亂數:
>sample =pd.DataFrame({'normal':np.random.randn(10)})
>sample
normal
0 0.065108
1 -0.597031
2 0.635432
3 -0.491930
4 -1.894007
5 1.623684
6 1.723711
7 -0.225949
8 -0.213685
9 -0.309789
現分為5箱,可以看到,結果是按照寬度分為5份,下限中,cut函式自動選擇小于列最小值一個數值作為下限,最大值為上限,等分為五分,結果產生一個Categories類的列,類似于R中的factor,表示分類變數列,
此外弱資料存在缺失,缺失值將在分箱后將繼續保持缺失,如下所示:
#Python學習交流群:778463939
>pd.cut(sample.normal,5)
0 (-0.447, 0.277]
1 (-1.17, -0.447]
2 (0.277, 1.0]
3 (-1.17, -0.447]
4 (-1.898, -1.17]
5 (1.0, 1.724]
6 (1.0, 1.724]
7 (-0.447, 0.277]
8 (-0.447, 0.277]
9 (-0.447, 0.277]
Name: normal, dtype: category
Categories (5, interval[float64]): [(-1.898, -1.17] < (-1.17, -0.447] < (-0.447, 0.277] < (0.277, 1.0] < (1.0, 1.724]]
這里也可以使用labels引數指定分箱后各個水平的標簽,如下所示,此時相應區間值被標簽值替代:
> pd.cut(sample.normal,bins=5,labels=[1,2,3,4,5])
0 1
1 1
2 2
3 2
4 3
5 3
6 4
7 4
8 5
9 5
Name: normal, dtype: category
Categories (5, int64): [1 < 2 < 3 < 4 < 5]
標簽除了可以設定為數值,也可以設定為字符,如下所示,將資料等寬分為兩箱,標簽為‘bad’,‘good’:
>pd.cut(sample.normal,bins=2,labels=['bad','good'])
0 bad
1 bad
2 bad
3 bad
4 bad
5 good
6 good
7 good
8 good
9 good
Name: normal, dtype: category
Categories (2, object): [bad < good]
等深分箱:等深分箱中,各個箱的寬度可能不一,但頻數是幾乎相等的,所以可以采用資料的分位數來進行分箱,依舊以之前的sample資料為例,現進行等深度分2箱,首先找到2箱的分位數:
>sample.normal.quantile([0,0.5,1])
0.0 0.0
0.5 4.5
1.0 9.0
Name: normal, dtype: float64
在bins引數中設定分位數區間,如下所示完成分箱,include_lowest=True引數表示包含邊界最小值包含資料的最小值:
>pd.cut(sample.normal,bins=sample.normal.quantile([0,0.5,1]),
include_lowest=True)
0 [0, 4.5]
1 [0, 4.5]
2 [0, 4.5]
3 [0, 4.5]
4 [0, 4.5]
5 (4.5, 9]
6 (4.5, 9]
7 (4.5, 9]
8 (4.5, 9]
9 (4.5, 9]
Name: normal, dtype: category
Categories (2, object): [[0, 4.5] < (4.5, 9)]
此外也可以加入label引數指定標簽,如下所示:
>pd.cut(sample.normal,bins=sample.normal.quantile([0,0.5,1]),
include_lowest=True)
0 bad
1 bad
2 bad
3 bad
4 bad
5 good
6 good
7 good
8 good
9 good
Name: normal, dtype: category
Categories (2, object): [bad < good]
3. 多變數例外值處理-聚類法
通過快速聚類法將資料物件分組成為多個簇,在同一個簇中的物件具有較高的相似度,而不同的簇之間的物件差別較大,聚類分析可以挖掘孤立點以發現噪聲資料,因為噪聲本身就是孤立點,
本案例考慮兩個變數income和age,散點圖所示,其中A、B表示例外值:
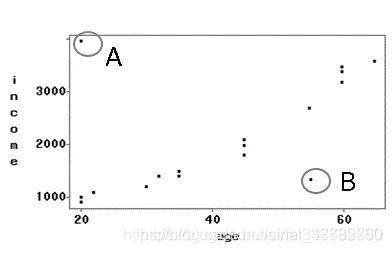
對于聚類方法處理例外值,其步驟如下所示:
-
輸入:資料集S(包括N條記錄,屬性集D:{年齡、收入}),一條記錄為一個資料點,一條記錄上的每個屬性上的值為一個資料單元格,資料集S有N×D個資料單元格,其中某些資料單元格是噪聲資料,
-
輸出:孤立資料點如圖所示,孤立點A是我們認為它是噪聲資料,很明顯它的噪聲屬性是收入,通過對收入變數使用蓋帽法可以剔除A,
另外,資料點B也是一個噪聲資料,但是很難判定它在哪個屬性上的資料出現錯誤,這種情況下只可以使用多變數方法進行處理,
常用檢查例外值聚類演算法為K-means聚類,會在后續章節中詳細介紹,本節不贅述,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/235885.html
標籤:Python
下一篇:python中取整數的幾種方法