@
目錄- web scraper
- 簡介:
- 優點
- 缺點
- 下載地址:
- 操作
- 安裝
- 谷歌瀏覽器
- 火狐瀏覽器
- 使用說明
- 簡介:
文章首發:https://mp.weixin.qq.com/s/tJfZx1AcpZ-sJYby5yMo9g
web scraper
簡介:
Web Scraper分為chrome插件和云服務兩種,云服務是收費的,chrome插件是免費的,這里說的就是chrome插件這種,
Web Scraper插件,可以讓你以“所見即所得”的方式挑選要提取的網頁資料,形成模版,以后可以隨時執行該模版,并且執行結果可以匯出成Csv格式,
web scraper 比較類似selenium和火車頭瀏覽器,不過web scraper功能要少的多,不過更加小巧,學習成本更低
優點
- 抓取需要登錄的資料較方便,因為這個插件是運行在瀏覽器上的,
- 只要抓取頻率慢一點,被網站屏蔽的概率較小,也因為是瀏覽器的原因,這就像是真實的用戶訪問一樣,
- 學習成本低
缺點
- 好像并不能做驗證碼識別
- 抓取效率較低,相對于爬蟲程式來說,Web scraper沒法大并發,快速切換IP等,所以大量級的資料抓取用Web Scrpaer不適合,慢慢抓大幾千網頁還是可以,
- 插件本身是不支持配置定時任務的,云服務提供了這種功能,不過是收費的,到是可以嘗試使用Python驅動谷歌來進而來操作web scraper的定時
下載地址:
https://www.webscraper.io/
crx檔案:jnhgnonknehpejjnehehllkliplmbmhn_0_2_0_18.crx
操作
安裝
谷歌瀏覽器
- 打開google瀏覽器,進入應用
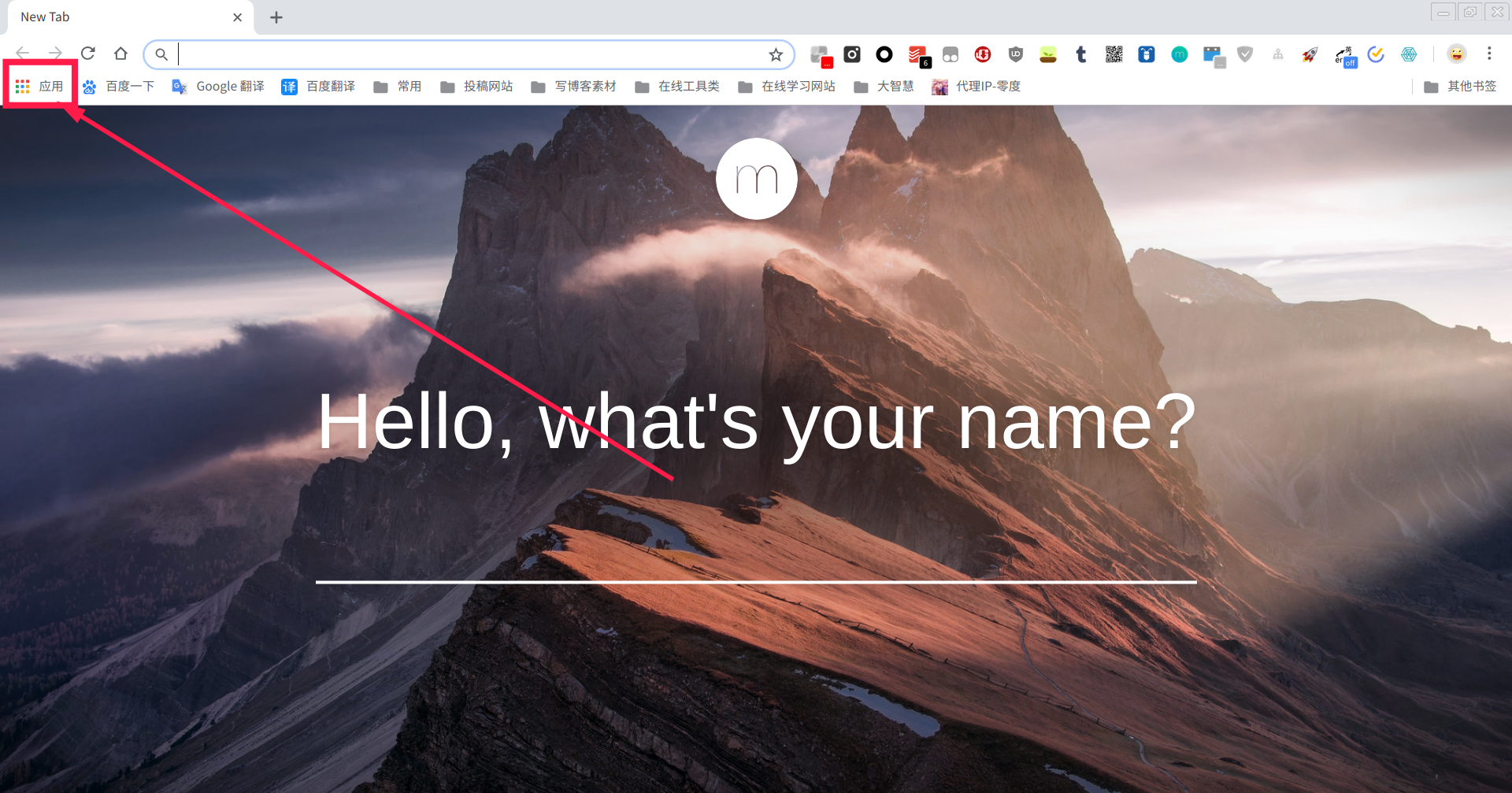
- 點擊網上應用商店
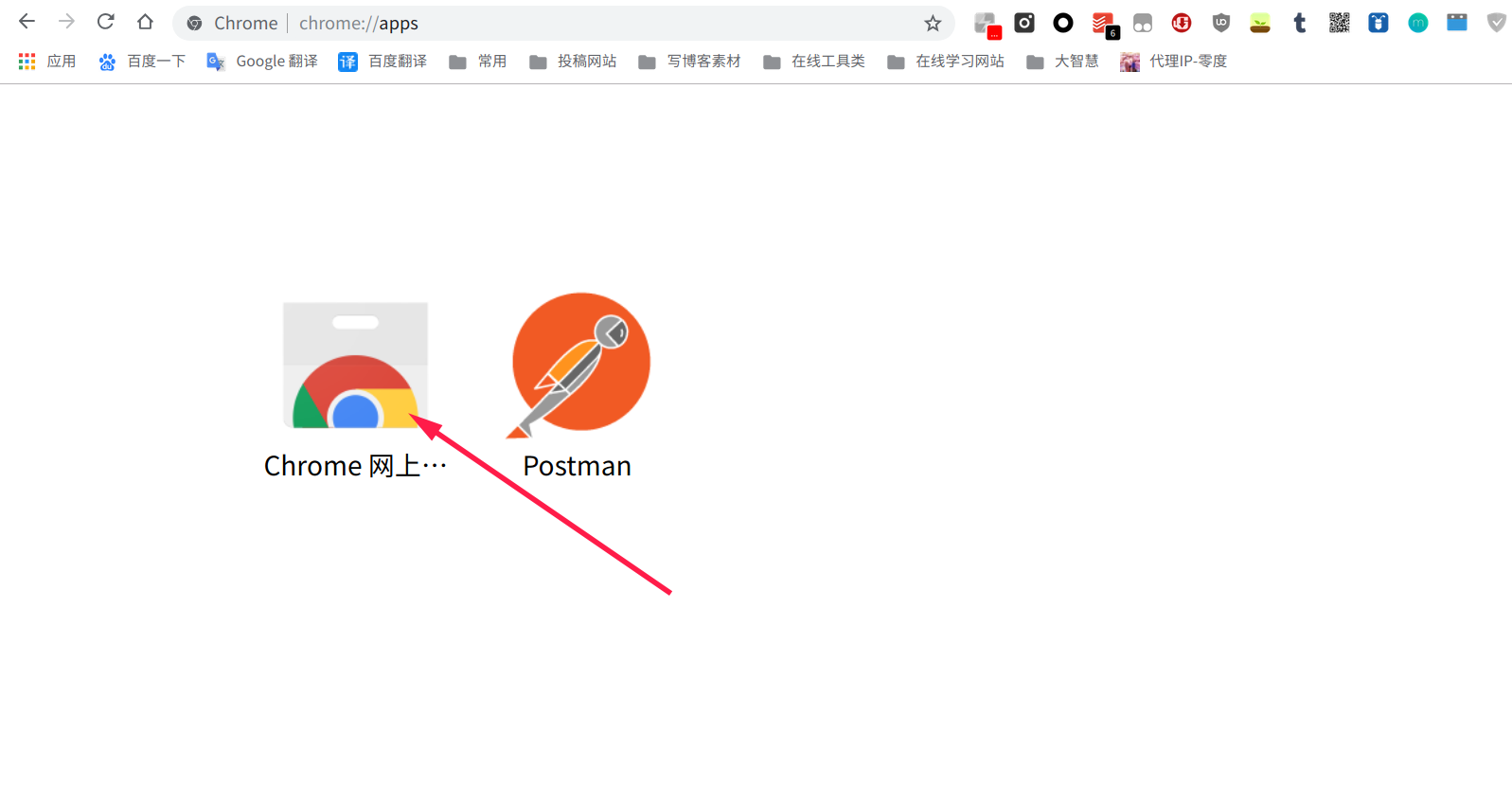
- 輸入框搜索
web scraper,點擊添加到chrome
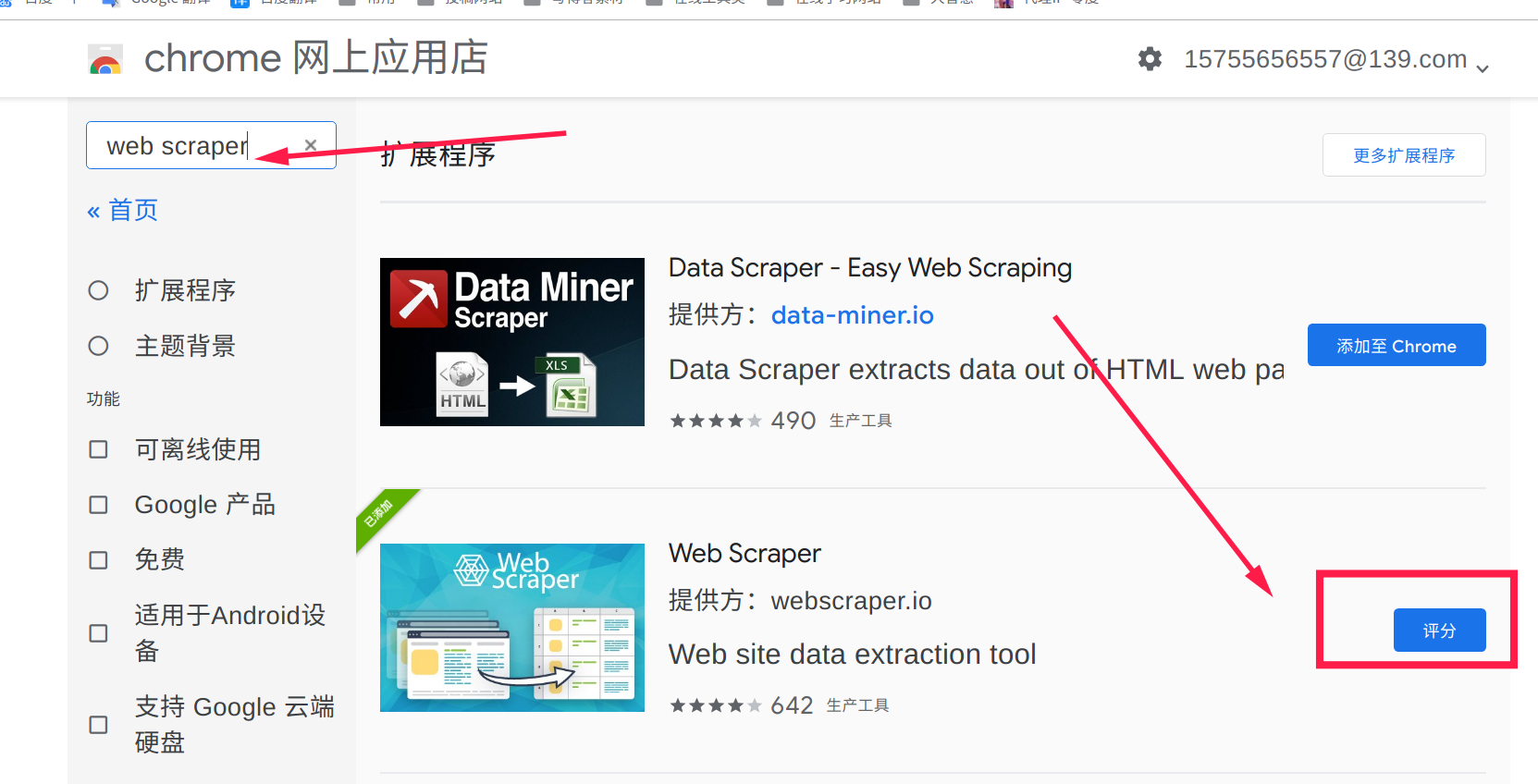
- 安裝完成
火狐瀏覽器
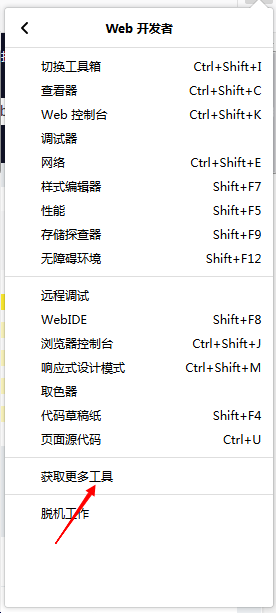
- 點擊右上角的選單按鈕,然后點擊進入web開發者
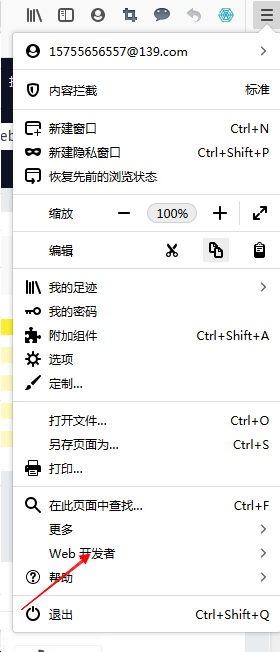
- 點擊獲取更多工具
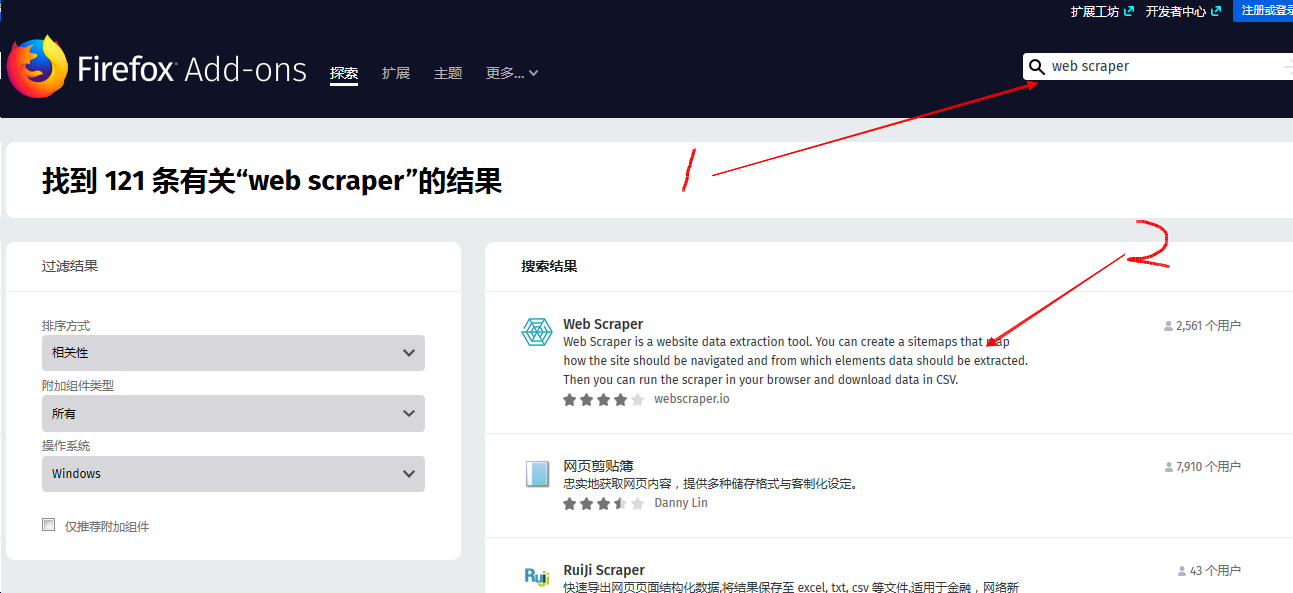
- 在搜索框里輸入
web scraper進行搜索
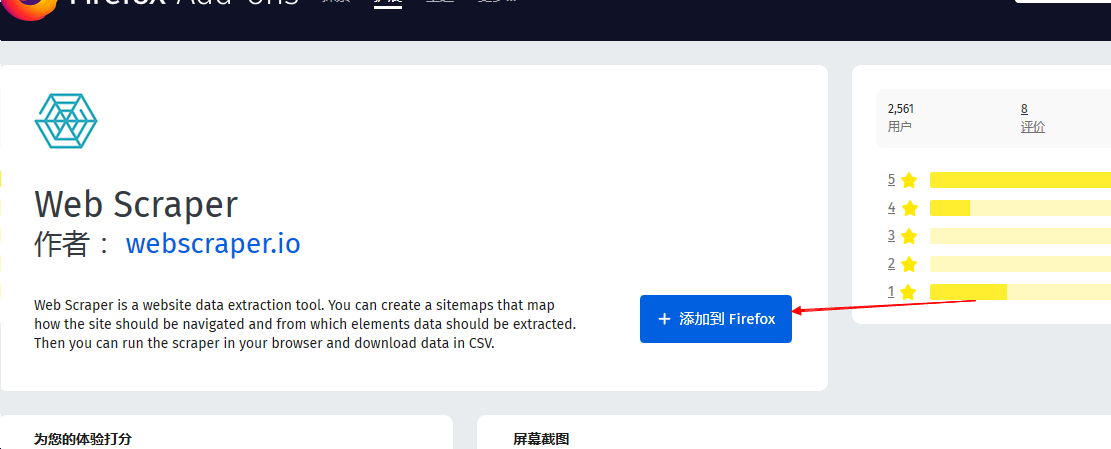
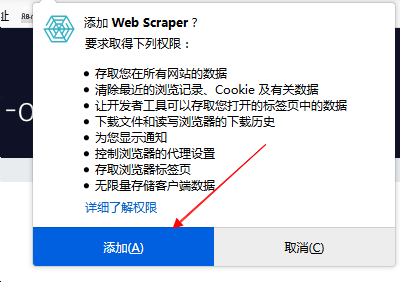
- 點擊添加到
Firefox
使用說明
- 進入谷歌瀏覽器,按F12進入開發者模式
- 安裝好
web scraper插件之后呢,會在最后出現web scraper標示
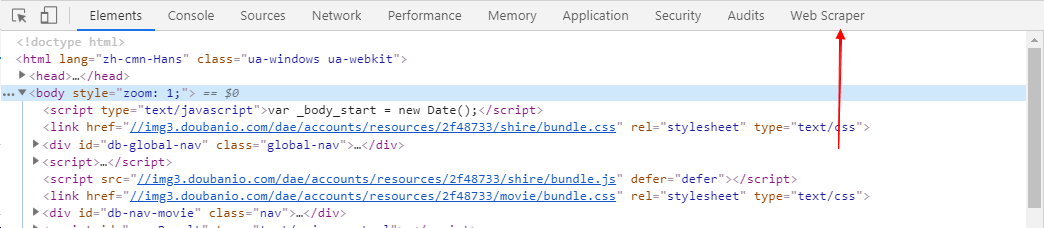
- 點擊進入
web scraper
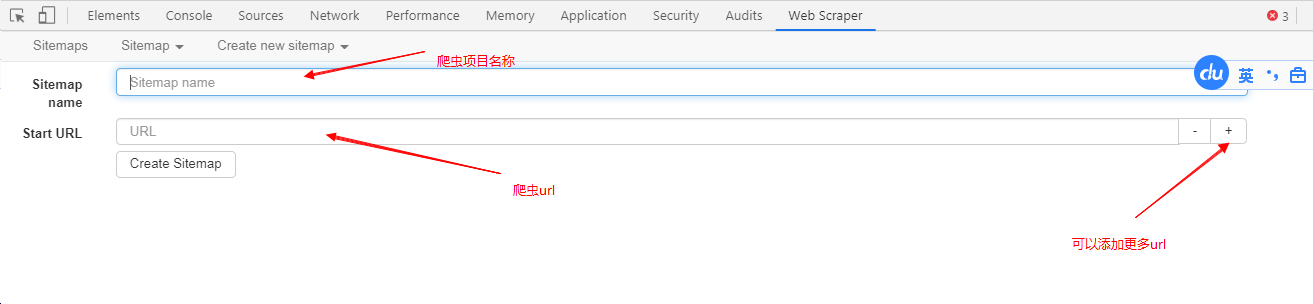
- 首先,我們點擊
create new sitemaps-->create sitemaps,來創建一個爬蟲專案 - 輸入爬蟲名稱和需要采集的url,點擊創建專案
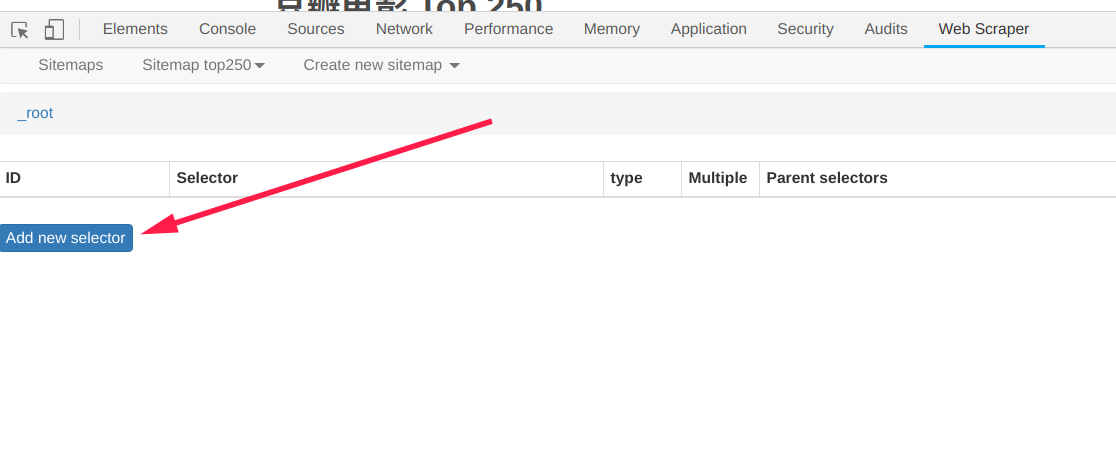
- 點擊
Add new selector創建一個選擇器
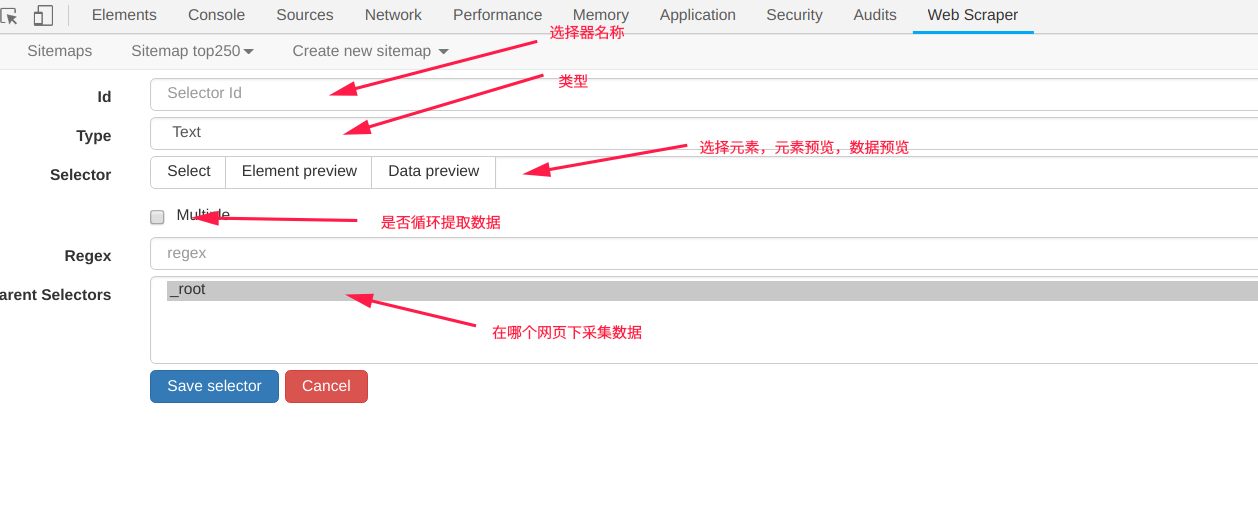
- 配置相關引數
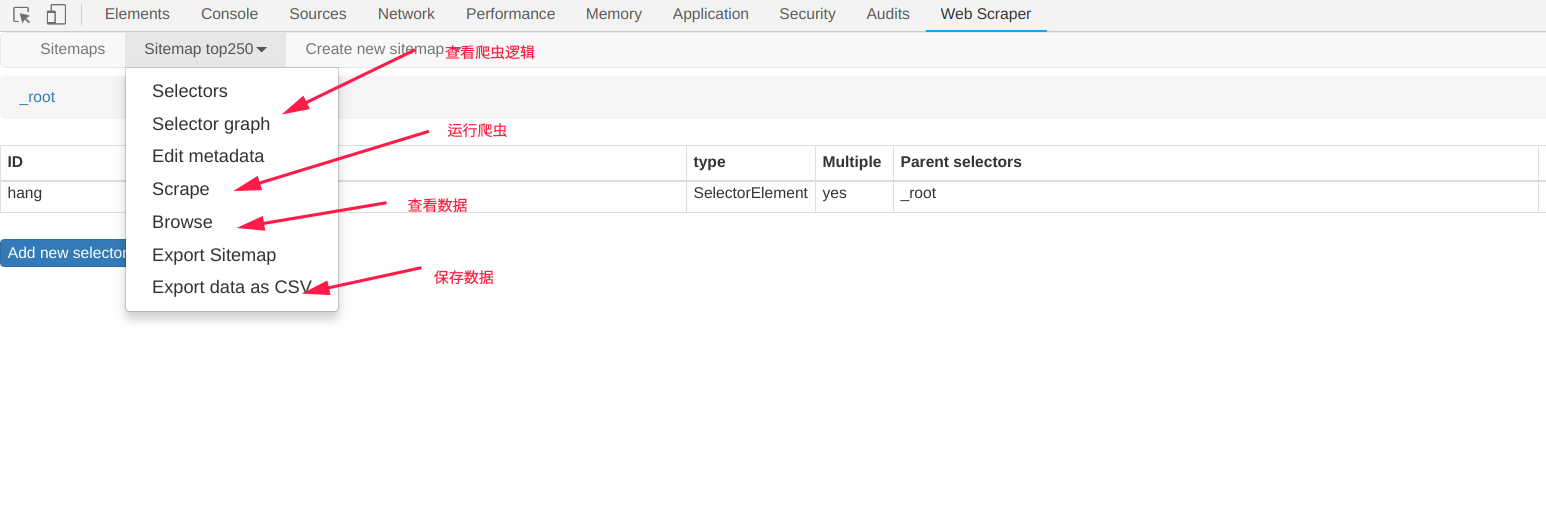
- 運行爬蟲,查看資料
關注我獲取更多內容
注:轉載還請注明出處,謝謝_
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/235894.html
標籤:其他
下一篇:時間格式里,sss與SSS的區別