從一個BUG說起
前段時間翻到了一個 JDK 有點意思的 BUG,帶大家一起瞅瞅,
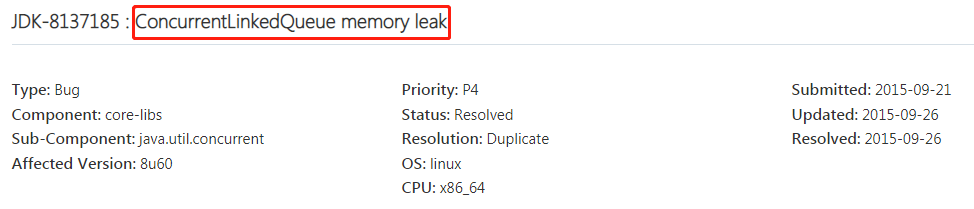
memory leak,記憶體泄漏,
是誰導致的記憶體泄漏呢?
ConcurrentLinkedQueue,這個佇列,
這個 BUG 里面說,在 jetty 專案里面也爆出了這個 BUG:

我看了一下,覺得 jetty 的這個寫的挺有意思的,
我按照 jetty 的這個講吧,反正都是同一個 JDK BUG 導致的,
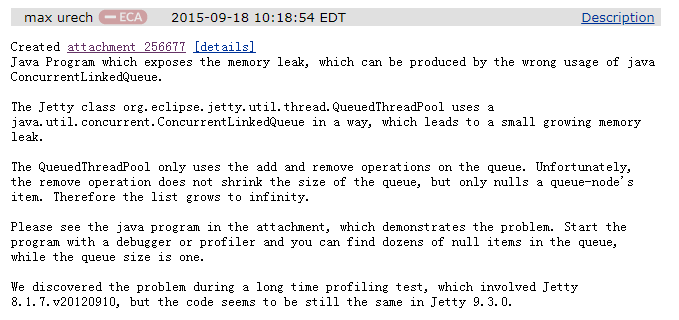
我用我八級半的蹩腳英語給大家翻譯一下這個叫做 max 的同學說了些什么,
他說:在 Java 專案里面,錯誤的使用 ConcurrentLinkedQueue(文章后面用縮寫 CLQ 代替)會導致記憶體泄漏的問題,
在 jetty 的 QueuedThreadPool 這個執行緒池里面,使用了 CLQ 這個佇列,它會導致記憶體緩慢增長,最終引發記憶體泄漏,
雖然 QueuedThreadPool 僅僅使用了這個佇列的 add 方法和 remove 方法,但不幸的是,remove 方法不會把佇列的大小變小,只會使佇列里面被洗掉的 node 為空,因此,該串列將增長到無窮大,
然后他給了一個附件,附件里面是一段程式,可以演示這個問題,
我們先不看他的程式,后面我們統一演示這個問題,
先給大家看一下 jetty 的 QueuedThreadPool 執行緒池,
看哪個版本的 jetty 呢?

可以看到這個 BUG 是在 2015 年 9 月 18 日被爆出來的,所以,我們找一個這個日期之前的版本就行,于是我找了一個 2015 年 9 月 3 日發布的 maven 版本:
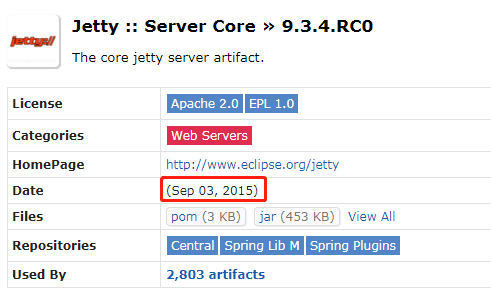
在這個版本里面的 QueuedThreadPool 是這樣的:
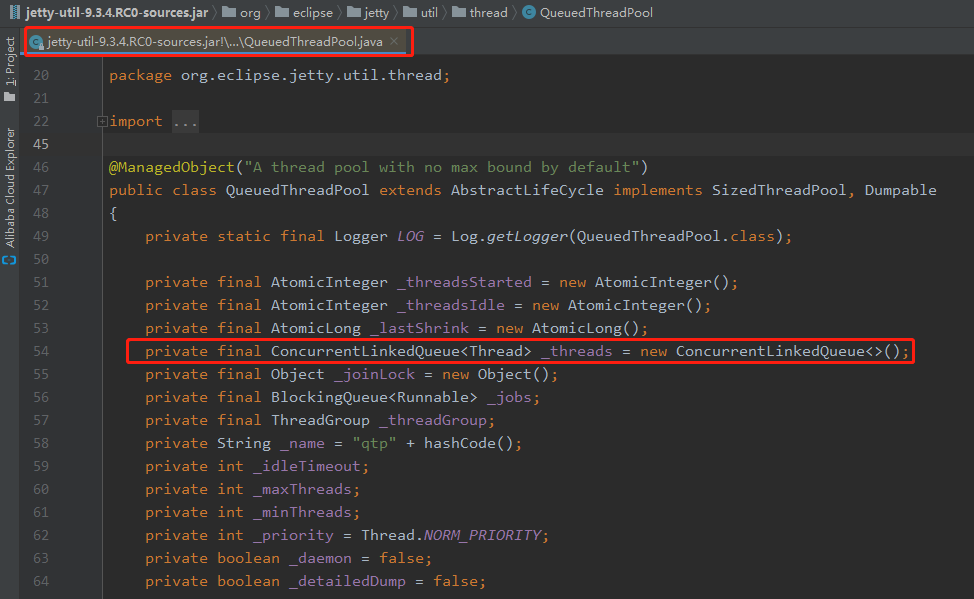
可以看到,它確實使用了 CLQ 佇列,而從這個物件所有被呼叫的地方來看,jetty 只使用了這個佇列的 size、add、remove(obj) 方法:

和前面 max 同學描述的一致,然后這個 max 同學給了幾張圖片,來佐證他的論點:
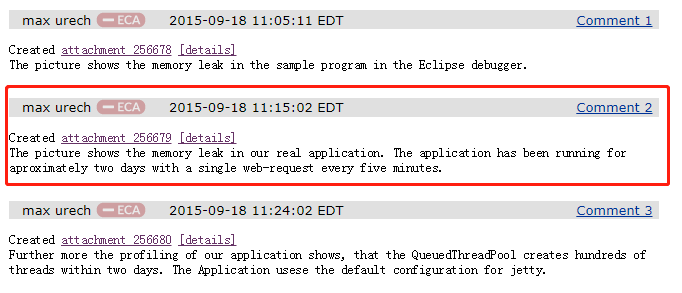
主要關注我框起來的地方,就是說他展示了一張圖片,可以從這圖片中看出記憶體泄漏的問題,而這個圖片的來源是他們真實的專案,這個專案已經運行了大約兩天,每五分鐘就會有一個 web 請求過來,
下面是他給出的圖片:
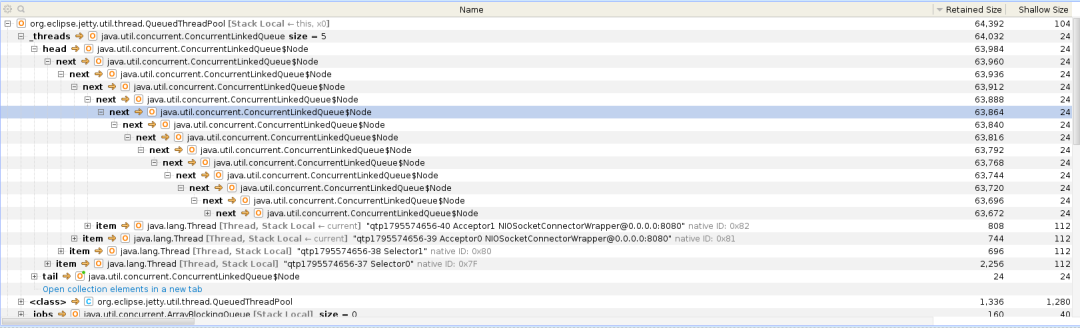
從他的這個圖片中,我就只看出了 CLQ 的 node 很多,但是他說了,他這個專案請求量并不大,用的 jetty 框架也不應該創建這么多的 node 出來,
好了,我們前面分析了 max 同學說的這個問題,接下來就是大佬出場,來解惑了:
好了,我們看一下這個 jetty 專案的領導者是怎么回答這個問題的:
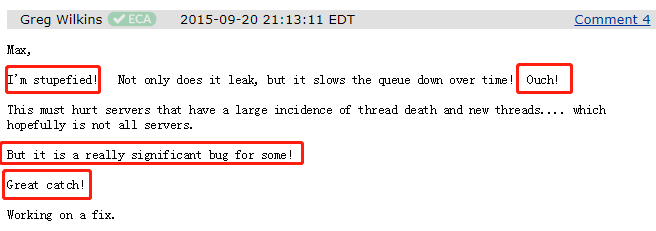
首先他用 stupefied 表示了非常的震驚!然后,用到了 Ouch 語氣詞,相當于我們常說的:他說:臥槽,我發現它不僅導致記憶體泄漏,而且會隨著時間的推移,導致佇列越來越慢,太TM震驚了,
這個問題一定會對使用大量執行緒的服務器產生影響…希望不是所有的服務器都會有影響,但不管是不是所有的服務器都有這個問題,只要出現了這個問題,對于某些服務器來說,它一定是一個非常嚴重的 BUG,
最后他說:我正在修復這個問題,
然后,在 7 分 37 秒之后, Greg 又回復了一次:
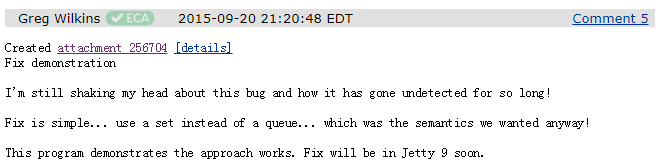
可以看出,過了快 8 分鐘,他還在持續震驚,我懷疑這 8 分鐘里面他一直在搖頭,他說:我還在為這個 BUG 搖頭,它怎么這么久都沒被發現呢!對于 jetty 來說修復起來非常的簡單,使用 set 結構代替 queue 佇列即可實作一樣的效果,
那我們看一下修復之后的 jetty 中的 QueuedThreadPool 是怎樣的,這里我用的是 2015 年 10 月 6 日發布的一個包,也就是這個 BUG 爆出之后的最近的一個包:
里面對應的代碼是這樣的:
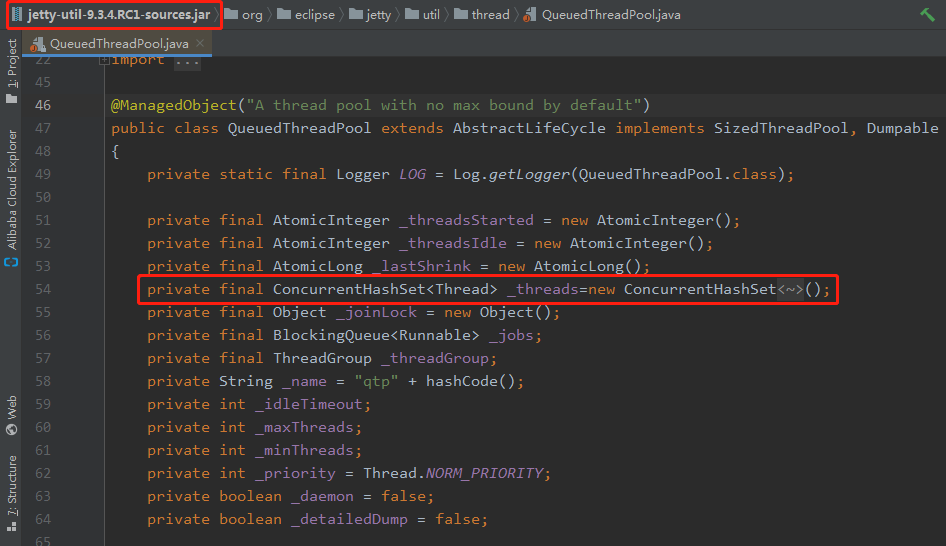
簡單粗暴的用 CurrentHashSet 代替了 CLQ,因為這個 BUG 在 JDK 中是已經修復了,出于好奇,我想看看 CLQ 還有沒有機會重新站出來,于是我看了一下今年發布的最新版本里面的代碼:
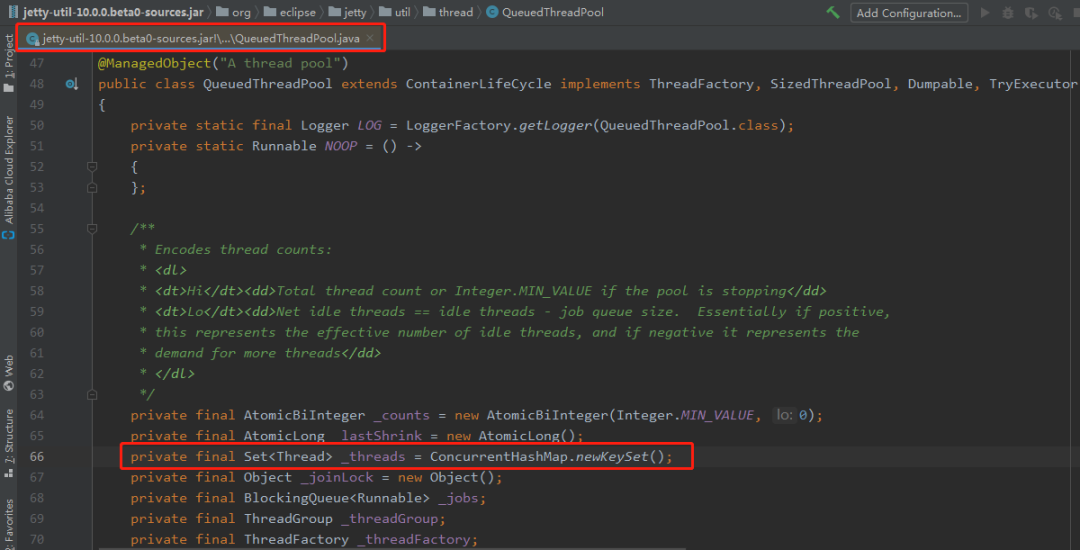
既不是用的 CurrentHashSet ,也沒有給 CLQ 機會,而是 JDK 8 的 ConcurrentHashMap 里面的 newKeySet 方法,C 位出道:
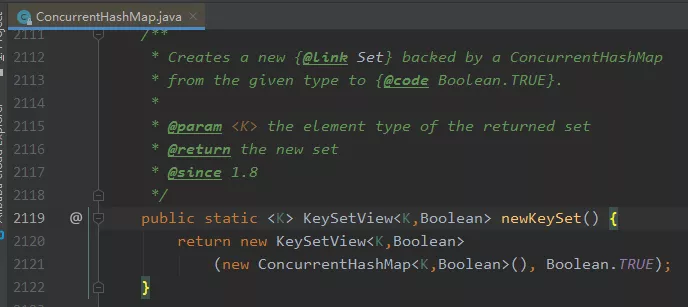
這是一個小小的 jetty 執行緒池的演變程序,恭喜你,又學到了一個基本上不會用到的知識點,回到 Greg 的回復中,這次的回復里面,他還給了一個修復的演示實體,下一小節我會針對這個實體進行解讀,在 23 分鐘之后,他就提交代碼修復完成了,

從第一次回復帖子,到定位問題,再到提交代碼,用了 30 分鐘的時間,然后在凌晨 2 點 57 分(這個時間點,大佬都是不用睡覺的嗎?還是說剛修完福報,下班了), max 回復到:

我不敢相信 CLQ 使用起來會有這樣的問題,他們至少應該在 API 檔案里面說明一下,這里的他們,應該指的是 JDK 團隊的成員,特指 Doug Lea,畢竟是他老爺子的作品,
為什么沒有在 API 檔案里面說明呢?因為他們自己也不知道有這個 BUG 啊,Greg 連著回復了兩條,并且直接指出了解決方案:
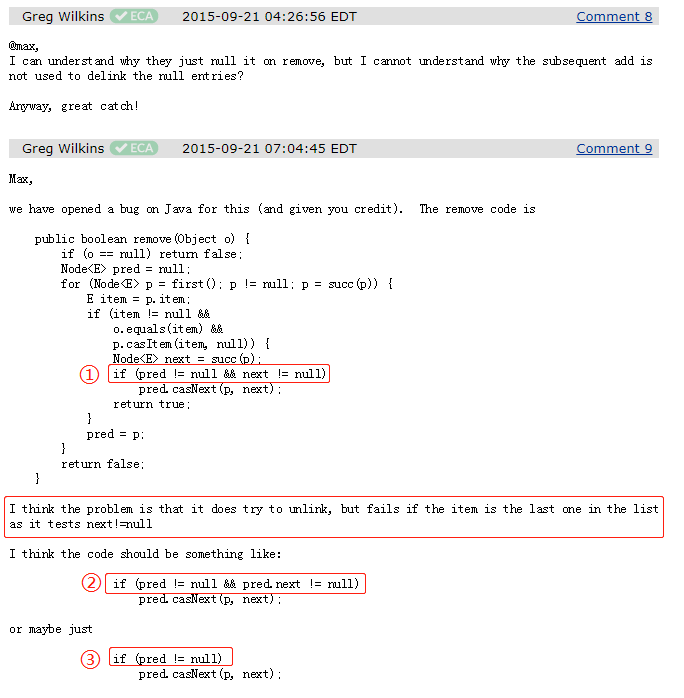
問題的原因是 remove 方法的原始碼里面,有上圖中標號為 ① 的這樣一行代碼,這行代碼會去取消被移除的這個 node (其值已經被替換為 null)和 list 之間的鏈接,然后可以讓 GC 回收這個 node,但是,當集合里面只有一個元素的時候, next != null 這個判斷是不成立的,所以就會出現這個需要移除的節點已經被置為 null 了,但卻沒有取消和佇列之間的連接,導致 GC 執行緒不會回收這個節點,他給出的解決方案也很簡單,就是標號為②、③的地方,總之,只需要讓代碼執行 pred.casNext 方法就行,
總之一句話,導致記憶體泄漏的原因是一個被置為 null 的 node,由于代碼問題,導致該 node 節點,既不會被使用,也不會被 GC 回收掉,
這個 BUG 在 jetty 里面的來龍去脈算是說清楚了,然后,我們再回到 JDK BUG 的這個鏈接中去:
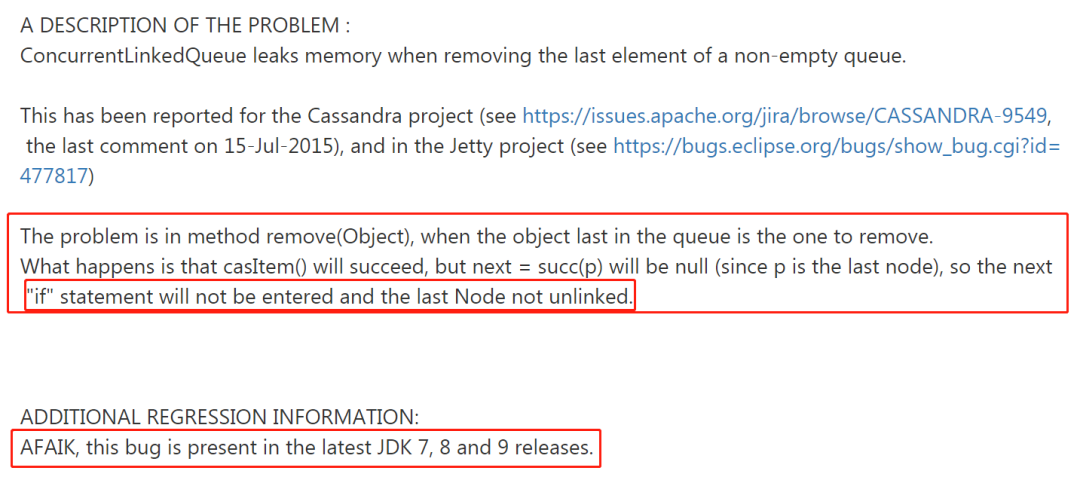
他這里寫的原因就是我前面說的原因,沒有 unlink,所以不能被回收,而且他說到:這個 BUG 在最新的JDK 7、8和9版本中都存在,他說的最新是指截止這個 BUG 被提出來之前:
Demo跑起來
這一小節里面,我們跑一下 Greg 給的那個修復 Demo,親手去摸一下這個 BUG 的樣子,你可以打開上面那個鏈接,直接復制粘貼到你的 IDEA 里面去:
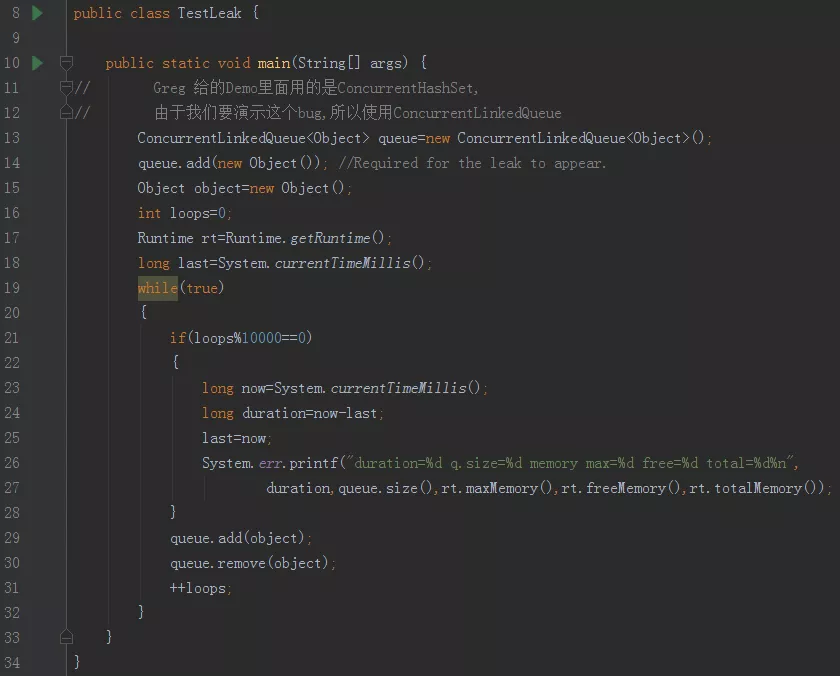
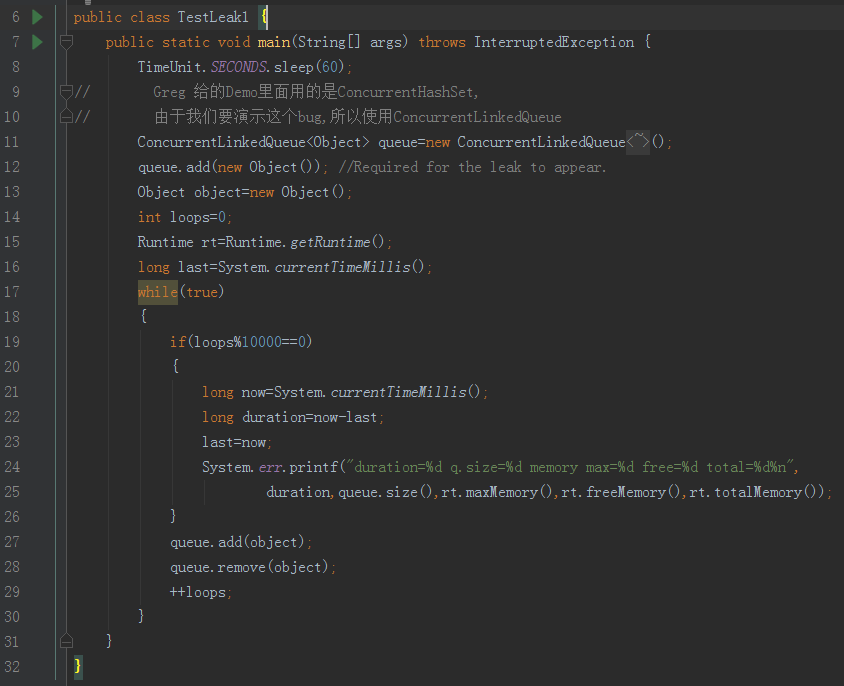
注意第 13 行,因為 Greg 給的是修復 Demo,所以用的是 ConcurrentHashSet,由于我們要演示這個bug,所以使用 CLQ,
這個 Demo 就是在死回圈里面呼叫 queue 的 add(obj) 和 remove(obj) 方法,每回圈 10000 次,就列印出時間間隔、佇列大小、最大記憶體、剩余記憶體、總記憶體的值,
最終運行起來的效果是這樣的(JDK 版本是 1.7.0_71):
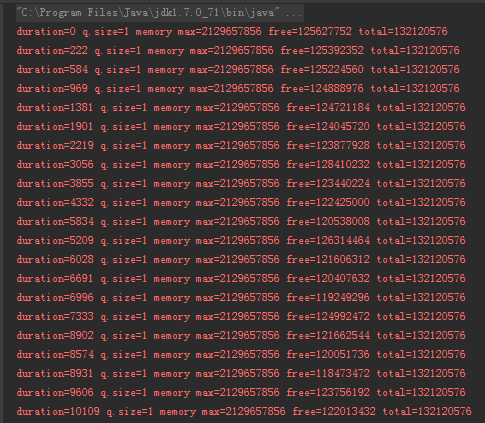
可以看到每次列印 duration 這個時間間隔是越來越大,佇列大小始終為 1,后面三個記憶體相關的引數可以先不關心,下一小節我們用圖形化工具來看,你知道上面這個程式,到我寫文章寫到這里的時候,我跑了多久了嗎?
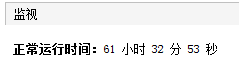
61 小時 32 分 53 秒,
最新一次回圈 10000 次所需要的時間間隔是 575615ms,快接近 10 分鐘:
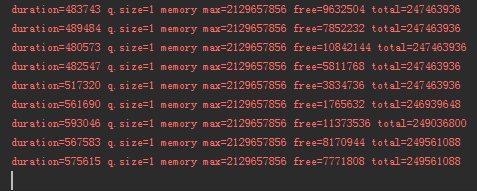
這就是 Greg 說的:不僅僅是記憶體泄漏,而且越來越慢,

但是,同樣的程式,我用 JDK 1.8.0_212 版本跑的時候情況卻是這樣的:
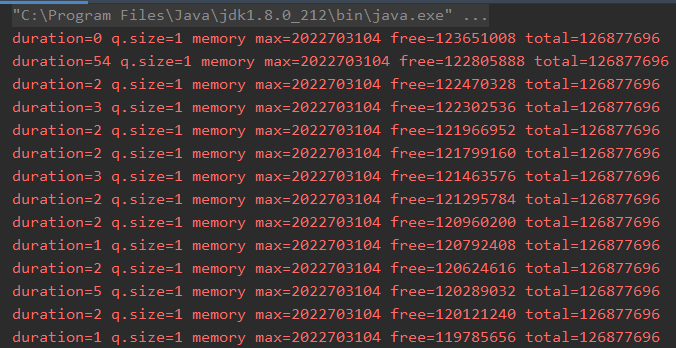
時間間隔很穩定,不會隨著時間的推移而增加,
說明這個版本是修復了這個 BUG 的,我帶大家看看原始碼:
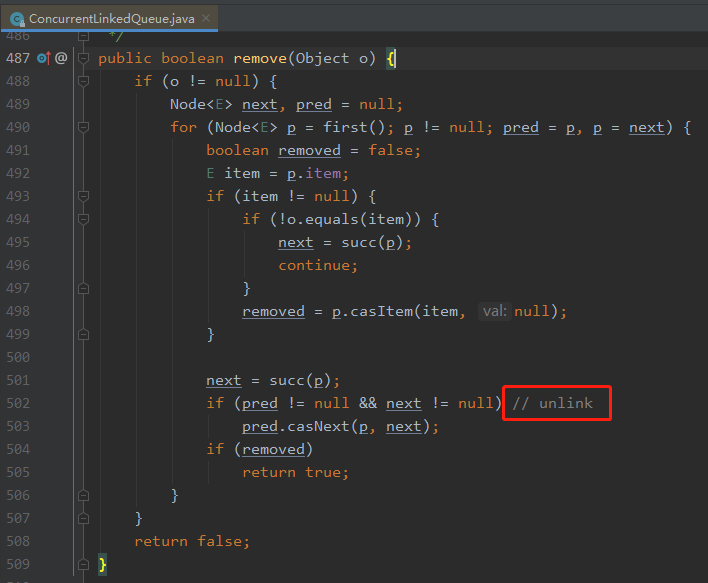
JDK 1.8.0_212 版本的原始碼里面,在 CLQ 的 remove(obj) 方法的 502 行末尾注釋了一個 unlink,
官方的修復方法可以看這里,改動比較多,但是原理還是和之前分析的一樣:
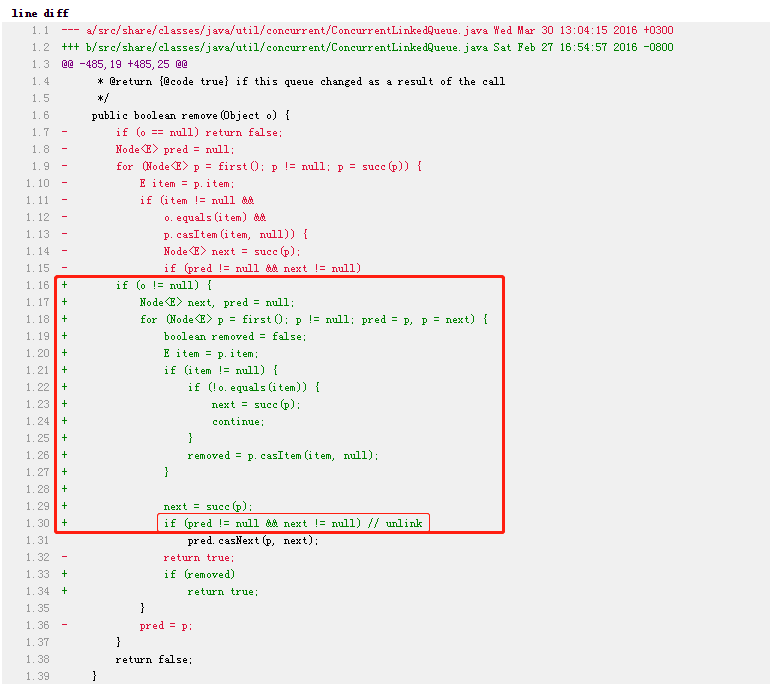
我僅僅在兩個 JDK 版本中跑過示例代碼,在 JDK 1.8.0_212 沒有發現記憶體泄漏的問題,我看了對應的 remove(obj) 方法的原始碼確實是修復了,
在 JDK 1.7.0_71 中可以看到記憶體泄漏的問題,unlink,一個簡簡單單的詞,背后原來藏了這么多故事,
jconsole、VisualVM、jmc
既然都說到記憶體泄漏了,那必須得介紹幾個可視化的故障排除工具,
前面說了,這個程式跑了 61 個小時了,給大家看一下這個時間段里面堆記憶體的使用情況:
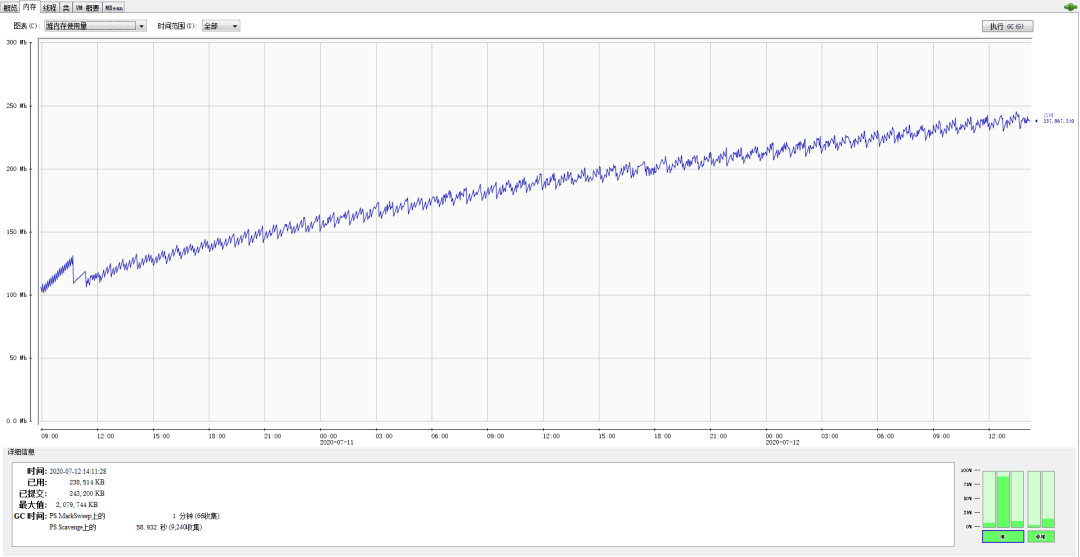
可以看到整個堆記憶體的使用量是一個明顯的、緩慢的上升趨勢,上面這個圖就是來自 jconsole,結合程式,通過圖片我們可以分析出,這種情況一定是記憶體泄漏了,這是一個非常經典的記憶體泄漏的走勢,
接下來,我們再看一下 jmc 的監控情況:
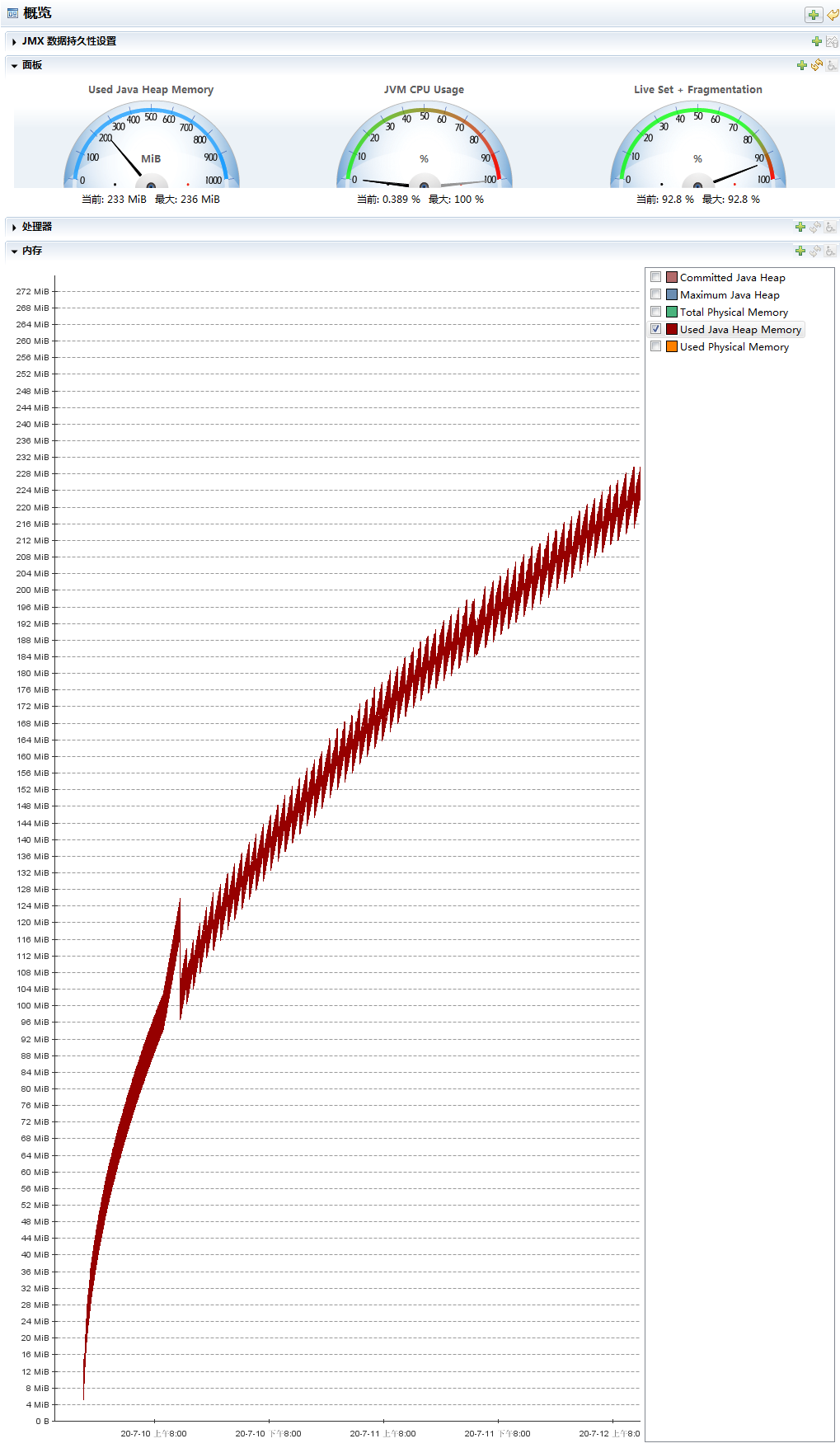
上面展示的是已經使用的堆記憶體的大小,走勢和 jconsole 的走勢一樣,
然后再看看 VisualVM 的圖:

VisualVM 的圖,我不知道怎么看整個運行了 60 多小時的走勢圖,但是從上面的圖也是能看出是有上升趨勢的,
在 VisualVM 里面,我們可以直接 Dump 堆,然后進行分析:
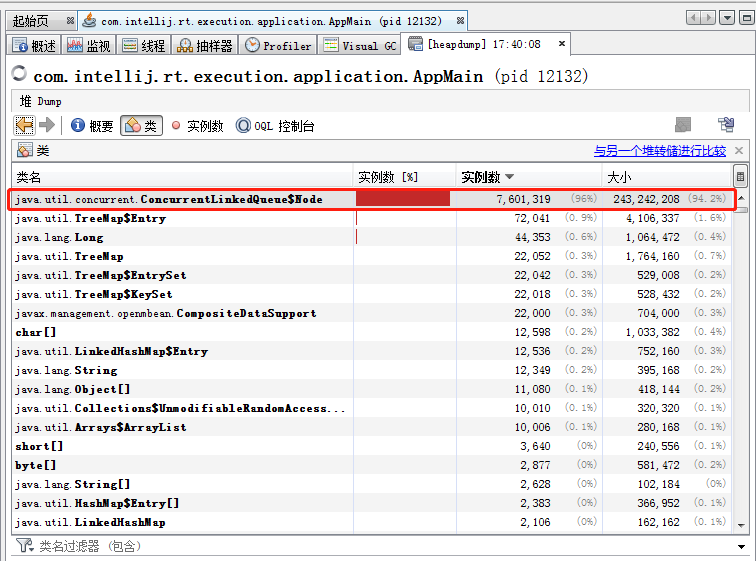
可以清楚的看到, CLQ 的 Node 的大小占據了 94.2%,
但是,從我們的程式來看,我們根本就沒有用到這么多 Node,我們只是用了一個而已,你說,這不是記憶體泄漏是什么,記憶體泄漏最侄訓導致 OOM,
所以當發生 OOM 的時候,我們需要分析是不是有記憶體泄漏,也就是看記憶體里面的物件到底應不應該存活,如果都應該存活那就不是記憶體泄漏,是記憶體不足了,需要檢查一下 JVM 的引數配置(-Xmx/-Xms),根據機器記憶體情況,判斷是否還能再調大一點,
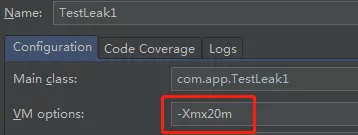
同時,也需要檢查一下代碼,是否存在生命周期程序的物件,是否有資料結構使用不合理的地方,盡量減少程式運行期的記憶體消耗,我們可以通過把堆記憶體設定的小一點,來模擬一下記憶體泄漏導致的 OOM,還是用之前的測驗案例,但是我們指定 -Xmx 為 20m,即最大可用的堆大小為 20m,
然后把代碼跑起來,同時通過 VisualVM 、jconsole、jmc 這三個工具監控起來,為了我們有足夠的時候準備好檢測工具,我在第 8 行加入休眠代碼,其他的代碼和之前的一樣:
加入 -Xmx20m 引數:
運行起來之后,我們同時通過工具來查看記憶體變化,下面三個圖從上到下的工具分別是 VisualVM、jconsole、jmc:

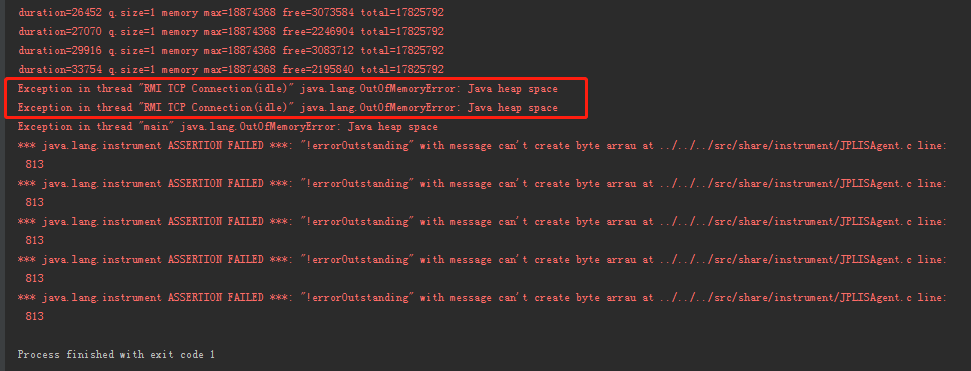
從圖片的走勢來看,和我們之前分析的是一樣的,記憶體一直在增長,
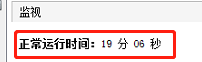
程式運行 19 分 06 秒后,發生 OOM 例外:
那正常的走勢圖應該是怎么樣的呢?
我們在 JDK 1.8.0_121 版本中(已經修復了 remove 方法),用相同的 JVM 引數(-Xmx20m)再跑一下:
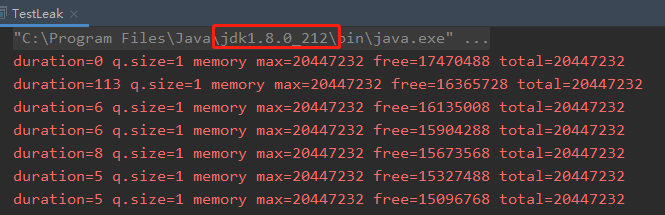
首先從上面的日志中可以看出,時間間隔并沒有遞增,程式運行的非常的快,
然后用 VisualVM 檢測記憶體,同樣跑 19 分鐘后截圖如下:
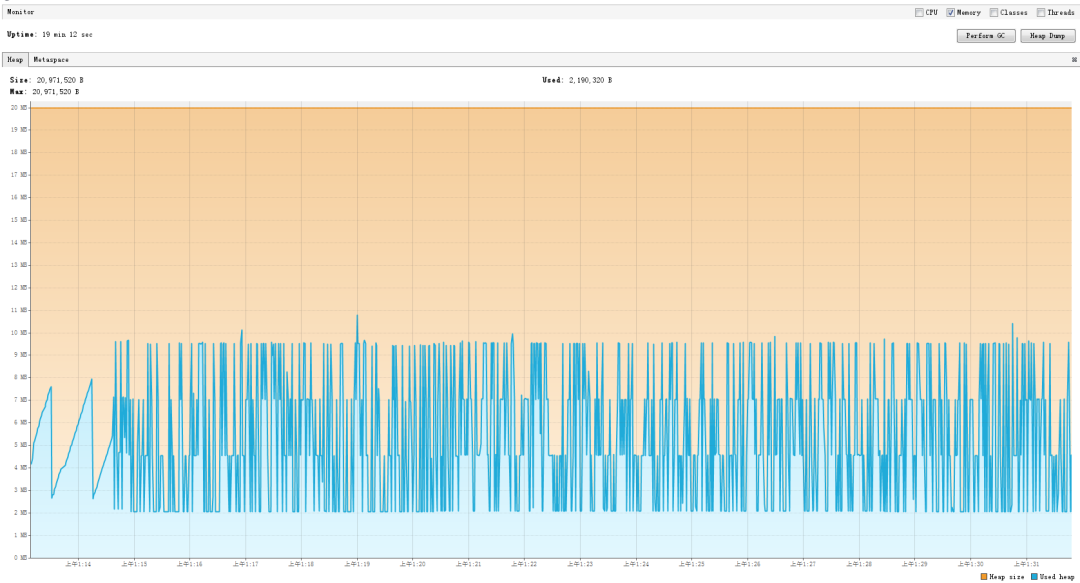
可以看到堆記憶體的使用量并沒有隨著時間的推移而越來越高,但是還是有非常頻繁的 GC 操作,
這個不難理解,因為 CLQ 的資料結構用的是鏈表,而鏈表又是由不同的 node 節點組成,由于呼叫 remove 方法后,node 節點具備被回收的條件,所以頻繁的呼叫 remove 方法對節點進行洗掉,會觸發 JVM 的 min GC,
這種 JDK BUG 導致的記憶體泄漏其實挺讓人崩潰的,首先你第一次感知到它是因為程式發生了 OOM,也許你會先無腦的加大堆記憶體空間,恰好你的程式運行了一周之后又要上線了,所以涉及到重啟應用,
然后很長一段時間內沒有發生 OOM 了,你就想這個問題可能解決了,
但是它還是在繼續發生著,很可能由于節假日前后不能上線,比如國慶七天,加上前后幾天,大概有半個月的樣子應用沒有上線,所以沒有重啟,程式越來越慢,最終導致第二次 OOM 的出現,這個時候,你覺得可能不是記憶體溢位這么簡單了,
會不會是記憶體泄漏了?
然后你再次重啟,這次重啟之后,你開始時不時的 Dump 一下記憶體,拿出來分析分析,突然發現,這個 node 怎么這么多呢?
最終,找到這個問題的原因,
原來是 JDK 的 BUG,
你就會發出和 Greg 一樣的感嘆:臥槽,震驚,這么牛皮!?

我這個運行了 60 多小時的程式到現在堆記憶體使用了 233m,但是我整個堆的大小是接近 2G,通過 jmc 同時展示堆的整體大小和已經使用的堆大小你可以發現,距離記憶體泄漏可以說是道阻且長了:
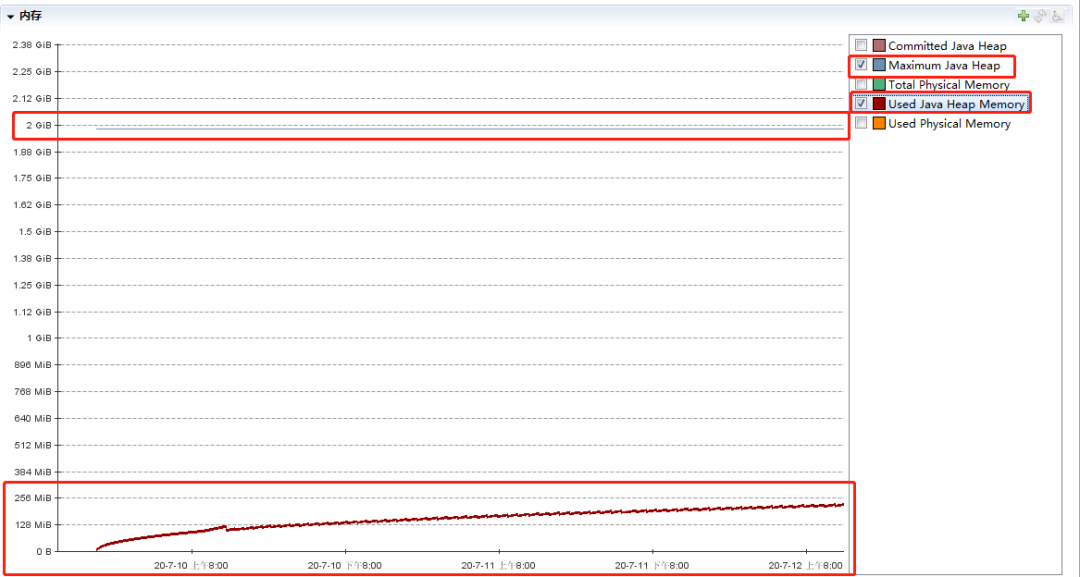
我粗略的算了一下,這個程式大概還得運行 475 個小時左右,也就是 19 天之后才會出現由于記憶體泄漏,導致的 OOM,我會盡量跑下去,但是聽到我電腦嗡嗡嗡的風扇聲,我不知道它還能不能頂得住,
如果它頂住了,我在后面的文章里面通知大家,
好了,圖形化工具這一小節就到這里了,
我們只是展示了它們非常小的一個功能,合理的使用它們常常能達到事半功倍的作用,
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/235900.html
標籤:其他