背景:
最近使用MapReduce做離線資料清洗,在map段做簡單的資料過濾,有經緯度的發送到reduce端,沒經緯的過濾掉,reduce端將資料整理出來,按業務模型拼接成字串寫入HDFS,供hive作為外表進行后續資料處理分析,
問題:
該批資料總共2T大小,MapReduce執行第一次時,不出意料的崩潰了,每次都大概在map階段執行到61%左右,
排查:
查看日志發現果然記憶體溢位:java.lang.OutOfMemoryError: GC overhead limit exceeded,
Exception in thread thread_name: java.lang.OutOfMemoryError: GC Overhead limit exceededCause: The detail message “GC overhead limit exceeded” indicates that the garbage collector is running all the time and Java program is making very slow progress. After a garbage collection, if the Java process is spending more than approximately 98% of its time doing garbage collection and if it is recovering less than 2% of the heap and has been doing so far the last 5 (compile time constant) consecutive garbage collections, then a java.lang.OutOfMemoryError is thrown. This exception is typically thrown because the amount of live data barely fits into the Java heap having little free space for new allocations.Action: Increase the heap size. The java.lang.OutOfMemoryError exception for GC Overhead limit exceeded can be turned off with the command line flag -XX:-UseGCOverheadLimit.
大概意思就是說,JVM花費了98%的時間進行垃圾回收,而只得到2%可用的記憶體,頻繁的進行記憶體回收(最起碼已經進行了5次連續的垃圾回收),JVM就會曝出java.lang.OutOfMemoryError: GC overhead limit exceeded錯誤,本質上還是堆記憶體不足,
其實對于大資料執行來說記憶體溢位問題司空見慣,按照慣例一套標準流程,減小每個map的split位元組大小,增加map數,增加每個container的堆記憶體,增加每個map的堆記憶體,能想到的引數我試了個遍,其實縷了一下代碼,我認為我們的map不應該存在記憶體溢位的情況,因為并沒有進行復雜的關聯計算,并且不會存在資料傾斜問題,但是任務每次還是在60%左右卡死,同時,我觀察到一個現象,每次程式崩潰的時候,yarn 的任務追蹤頁面都會反應的例外慢,看來我之前想的方向有問題,看來不是map容器的堆記憶體溢位,
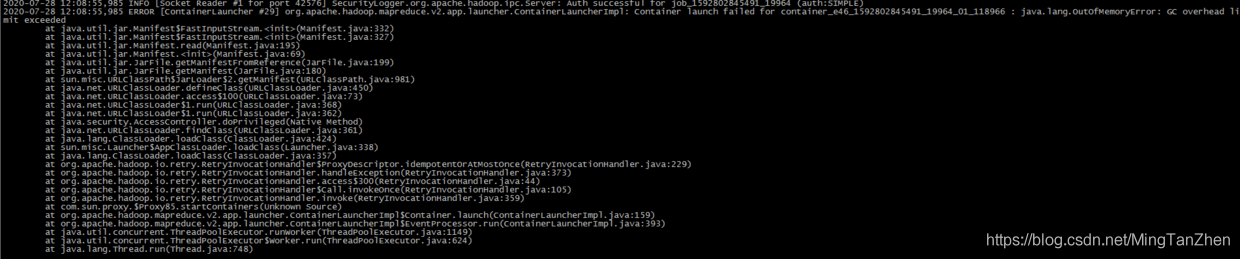
例外圖如上,仔細縷了一遍例外,發現是ContainerLauncherImpl 這個類的報錯,意思是容器啟動的時候發生的問題,
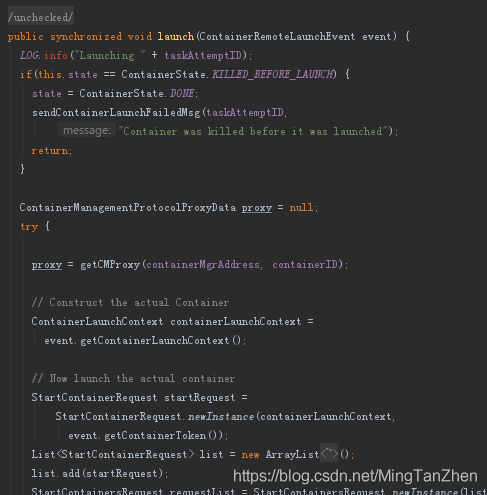
查了下hadoop 這塊的代碼,果然是申請容器的時候出了問題,MRAppMaster負責向yarn的resourcemanager去申請資源啟動容器,初步得出了應該是MRAppMaster的記憶體溢位,
ApplicationMaster向資源調度器申請執行任務的資源容器Container,運行用戶自己的程式任務job(我們可以用瀏覽器看yarn
里的job進展),監控整個任務的執行,跟蹤整個任務的狀態,處理任務失敗以例外情況,這也對應了我們看yarn上的任務監控會崩潰的情況,
解決:
通過調整引數,yarn.app.mapreduce.am.command-opts、yarn.app.mapreduce.am.resource.mb加大了MRAppMaster的記憶體,同時分析待處理的源資料,發現每個檔案10MB大小,總共有18萬,MapReduce處理檔案,默認使用FileInputFormat,但是這個處理小檔案是,會每一個小檔案生成一個map,所以以為著原來我們的任務有18萬個map,這應該突破了原來的MRAppMaster所能維護的map的極限,頻繁的申請創建、銷毀container也消耗了大量的計算資源,導致了記憶體溢位、任務崩潰,hadoop處理大量小檔案建議使用CombineFileInputFormat來合并輸入資料,減少map數量,修改完之后,map數量銳減到2800多個,程式不再報記憶體溢位,同時提升了執行速度,
至此,問題得到了解決,
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/235903.html
標籤:其他
上一篇:JAVA線上故障排查套路