前言

先看Pandas的百科介紹
pandas 是基于NumPy 的一種工具,該工具是為解決資料分析任務而創建的,Pandas
納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具,pandas提供了大量能使我們快速便捷地處理資料的函式和方法,你很快就會發現,它是使Python成為強大而高效的資料分析環境的重要因素之一,
所以學好Python原生和Numpy對于學習Pandas很重要,在這一章節我們主要介紹Python和Numpy的一些比較重要的知識,本章學習的思維導圖如下:
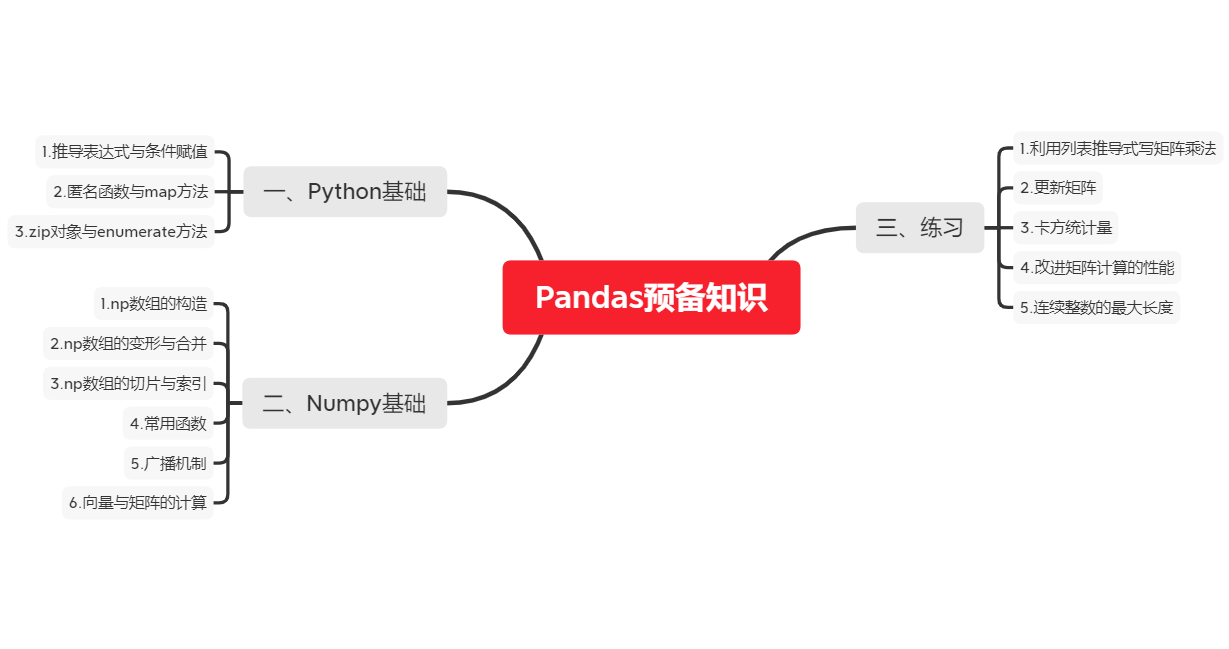
一、Python基礎
語法糖(Syntactic sugar),也譯為糖衣語法,是由英國計算機科學家彼得·約翰·蘭達(Peter J. Landin)發明的一個術語,指計算機語言中添加的某種語法,這種語法對語言的功能并沒有影響,但是更方便程式員使用,通常來說使用語法糖能夠增加程式的可讀性,從而減少程式代碼出錯的機會,
在Python原生中有很多好用的語法糖、物件和方法,在這里列舉幾個典型的并且常用的:
1.推導運算式與條件賦值
1)推導運算式
推導運算式是Python中常見的語法糖,在很多的資料處理場景中,我們可能會使用的到, 最常見的就是串列推導運算式,可以用來過濾、處理串列中的子項并輸出一個新的串列,除此之外還有幾個推導式也是非常好用的,
a.串列推導運算式
>>>a = [x for x in range(10)]
>>>print(a)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b.生成器推導運算式
>>> in_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 9, 8, 7]
>>> print('array before:', in_list)
>>> array = (i for i in in_list if i % 2 != 0) # 生成器推導運算式
>>> print('array after:', array)
c.集合推導運算式
>>> in_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 9, 8, 7]
>>> print('array before:', in_list)
>>> array = {i for i in in_list if i % 2 != 0} # 集合推導運算式
>>> print('array after:', array)
d.字典推導運算式
>>> in_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 9, 8, 7]
>>> print('array before:', in_list)
>>> array = {i: i * 2 for i in in_list if i % 2 != 0} # 字典推導運算式
>>> print('array after:', array)
其實,不止是節省代碼
耗時比較:

另外,推導運算式中也可以使用多層回圈(大于等于2):
>>> a = ["第{}行{}列".format(i+1,j+1) for i in range(3) for j in range(3)]
>>> print(a)
['第1行1列', '第1行2列', '第1行3列', '第2行1列', '第2行2列', '第2行3列', '第3行1列', '第3行2列', '第3行3列']
2)條件賦值
條件賦值類似于三目運算子,由if判斷和賦值陳述句組成:
>>> a = b if a==b else c
上面的語法糖等價于:
>>> if b > c:
>>> a = b
>>> else:
>>> a = c
2.匿名函式與map方法
匿名函式的好處是省去了利用def去定義函式的步驟,壞處是不能重復使用:
>>> x = [(lambda x: x+2)(i) for i in range(10)]
>>> print(x)
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
map() 會根據提供的函式對指定序列做映射:
>>> x = list(map(lambda x:x+2,range(10)))
>>> print(x)
[2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
其中,函式需要的引數要放入map的引數中,
3.zip物件與enumerate方法
zip() 函式用于將可迭代的物件作為引數,將物件中對應的元素打包成一個個元組,然后回傳由這些元組組成的串列:
>>> a = 'xiao'
>>> b = 'ming'
>>> c = 'yuan'
>>> print(list(zip(a,b,c)))
[('x', 'm', 'y'), ('i', 'i', 'u'), ('a', 'n', 'a'), ('o', 'g', 'n')]
我們也可以使用zip去生成tuple和dict:
>>> print(tuple(zip(a,b,c)))
(('x', 'm', 'y'), ('i', 'i', 'u'), ('a', 'n', 'a'), ('o', 'g', 'n'))
>>> print(dict(zip(b,c)))
{'m': 'y', 'i': 'u', 'n': 'a', 'g': 'n'}
zip配合串列推導運算式使用:
>>> print(["第{}行{}列".format(i+1,j+1) for i,j in zip(range(3),range(3))])
['第1行1列', '第2行2列', '第3行3列']
- 可理解為解壓:
>>> a = 'xiao'
>>> b = 'ming'
>>> c = 'yuan'
>>> zipped = list(zip(a,b,c))
>>> print(zipped)
[('x', 'm', 'y'), ('i', 'i', 'u'), ('a', 'n', 'a'), ('o', 'g', 'n')]
#復原方法一
>>> zipped_2 = list(zip(*zipped))
>>> print(zipped_2)
[('x', 'i', 'a', 'o'), ('m', 'i', 'n', 'g'), ('y', 'u', 'a', 'n')]
#復原方法二
>>> original_1 = list(zip(zipped))
>>> print(original_1)
[(('x', 'm', 'y'),), (('i', 'i', 'u'),), (('a', 'n', 'a'),), (('o', 'g', 'n'),)]
#復原方法三
>>> original_2 = list(zip(zipped[0],zipped[1],zipped[2],zipped[3]))
>>> print(original_2)
[('x', 'i', 'a', 'o'), ('m', 'i', 'n', 'g'), ('y', 'u', 'a', 'n')]
方法二失敗的原因是zipped實際上是作為一個引數輸入,
對于方法一和方法三,我們可以看到,*和將zipped所有元素展開成多個引數是等價的,
enumerate:同時可呼叫索引和值
name = 'xiao'
for i,x in enumerate(name):
print(str(i)+":"+x)
0:x
1:i
2:a
3:o
二、Numpy基礎
1.np陣列的構造
| np陣列的構造 | ||
| 構造型別 | 構造方法 | 構造說明 |
| 依據現有資料構造 | array() | 會產生原資料的copy |
| asarray() | 當dtype變化時會產生原資料的copy | |
| fromfunction() | 根據指定函式創建陣列 | |
| 依據填充方式 | zeros() | 構造零陣列 |
| empty() | 構造空陣列 | |
| eye() | 構造單位陣列 | |
| diag() | 構造對角陣列 | |
| full() | 構造常數陣列 | |
| 利用陣列范圍來創建 | arange() | 回傳給定間隔內的均勻間隔的值 |
| linspace() | 回傳指定間隔內的等間隔數字 | |
| logspace() | 回傳數以對數刻度均勻分布 | |
| 結構陣列的創建 | np.array()+np.dtype() | 利用包含多個元組的串列來定義結構 |
| np.array()+np.dtype() | 利用字典來定義結構 | |
| 隨機生成 | random() | 利用隨機抽樣的概念生成陣列 |
1)依據現有資料構造
Ⅰ.array()方法
numpy.array(p_object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
>>> datas = [x for x in range(10)]
>>> print(datas)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#通過array方法生成nd陣列
>>> nd_datas = np.array(datas)
>>> print(nd_datas,nd_datas.shape)
[0 1 2 3 4 5 6 7 8 9] (10,)
#改變原陣列
>>> datas[0] = 100
>>> #nd陣列并不會改變,說明產生的copy
>>> print(nd_datas,nd_datas.shape)
[0 1 2 3 4 5 6 7 8 9] (10,)
在這里我試圖用改變初始陣列的方式來判斷是否產生copy,此處也可以使用is進行比較,之后不再解釋,我們看到array默認產生一個copy,修改原陣列的資料并不會對生成的nd陣列產生影響,
Ⅱ.asarray()方法
numpy.asarray(a, dtype=None, order=None)
>>> datas = [x for x in range(10)]
>>> print(datas)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#通過asarray方法生成nd陣列
>>> nd_datas = np.asarray(datas)
>>> print(nd_datas,nd_datas.shape)
[0 1 2 3 4 5 6 7 8 9] (10,)
#改變原陣列
>>> datas[0] = 100
#nd陣列并不會改變,說明仍會產生的copy
>>> print(nd_datas,nd_datas.shape)
[0 1 2 3 4 5 6 7 8 9] (10,)
這樣看起來asarray()方法與array()方法并沒有太大區別,我們且看下面這個例子:
>>> datas = [x for x in range(10)]
>>> nd_datas = np.array(datas)
>>> x = np.array(nd_datas)
>>> y = np.asarray(nd_datas)
>>> nd_datas[0] = 100
#后者沒有copy,說明仍會產生的copy
>>> print(x,y)
[0 1 2 3 4 5 6 7 8 9] [100 1 2 3 4 5 6 7 8 9]
當傳入資料是nd型別時,asarray()方法不會產生copy,而array()方法依然產生copy,
這是因為asarray()方法默認在不改變dtype時不copy,如:
>>> datas = [x for x in range(10)]
>>> nd_datas = np.array(datas,dtype='int16')
>>> x = np.asarray(nd_datas,dtype='int8')
>>> y = np.asarray(nd_datas,dtype='int16')
>>> z = np.asarray(nd_datas,dtype='int32')
>>> nd_datas[0] = 100
>>> print(x,y,z)
[0 1 2 3 4 5 6 7 8 9] [100 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9]
Ⅲ.fromfunction()方法
numpy.fromfunction(function, shape, *, dtype=<class 'float'>, **kwargs)
fromfunction()方法通過在每個坐標上執行一個函式來構造陣列,舉例:
>>> def f(x,y):
>>> return 5*x+y
>>> data = np.fromfunction(f,(4,4))
>>> print(data)
[[ 0. 1. 2. 3.]
[ 5. 6. 7. 8.]
[10. 11. 12. 13.]
[15. 16. 17. 18.]]
等價于:
>>> print(np.fromfunction(lambda i, j: 5*i+j, (4, 4)))
[[ 0. 1. 2. 3.]
[ 5. 6. 7. 8.]
[10. 11. 12. 13.]
[15. 16. 17. 18.]]
2)依據填充方式構造
在機器學習任務中經常做的一件事就是初始化引數,需要用常數值或者隨機值來創建一個固定大小的矩陣,在這里介紹5中常用的矩陣填充方式:
Ⅰ.zeros()方法
numpy.zeros(shape, dtype=float, order='C')
zeros()方法用來回傳給定形狀和型別的零陣列:
#生成一個3*3的零陣列
>>> print(np.zeros([2,3]))
[[0. 0. 0.]
[0. 0. 0.]]
numpy.zeros_like(a, dtype=None, order='K', subok=True, shape=None)
類似地,numpy中還有zeros_like()方法回傳與給定陣列形狀和型別相同的零陣列,舉例:
#創建一個2*3的二維陣列
>>> data = np.array([[1,2,3],[4,5,6]])
>>> print(np.zeros_like(data))
[[0 0 0]
[0 0 0]]
Ⅱ.empty()方法
empty(shape, dtype=None, order='C')
empty()方法回傳一個空陣列,陣列元素為亂數:
>>> print(np.empty(5))
[2.12199584e-314 6.36598737e-314 1.06099790e-313 1.48539705e-313
1.90979621e-313]
empty_like(prototype, dtype=None, order='K', subok=True, shape=None)
同樣地,也有empty_like()方法回傳與給定陣列具有相同形狀和型別的空陣列:
>>> data = np.array([[1,2,3],[4,5,6]])
>>> print(np.empty_like(data))
[[2964 0 0]
[ 563 0 563]]
Ⅲ.eye()方法
numpy.eye(N, M=None, k=0, dtype=float, order='C')
eye()方法回傳一個對角線上為1,其它地方為零的單位陣列,可不是方陣:
#生成4*4的單位矩陣
>>> print(np.eye(4))
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
#形狀為3*2
>>> print(np.eye(3,2))
[[1. 0.]
[0. 1.]
[0. 0.]]
#形狀為2*3
>>> print(np.eye(2,3))
[[1. 0. 0.]
[0. 1. 0.]]
這里注意,如果給定一個兩個數并且不等,那么在生成的陣列中,會將從左上角第一個開始延展到邊界的路徑上設為1.
numpy.identity(n, dtype=None)
另外,numpy提供了只生成方的單位矩陣的identity()方法:
>>> print(np.identity(4))
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
Ⅳ.diag()方法
diag(v, k=0)
diag()方法用于提取對角線或構造對角陣列:
#提取對角線
>>> data = np.array([[1,2,3],[4,5,6],[7,8,9]])
>>> print(data)
[[1 2 3]
[4 5 6]
[7 8 9]]
#提取對角線
>>> print(np.diag(data))
[1 5 9]
#提取對角線 向右上偏移
>>> print(np.diag(data,k=1))
[2 6]
#提取對角線 向左下偏移
>>> print(np.diag(data,k=-1))
[4 8]
k代表偏移量,默認為0,右上方向為正,左下方向為負,
注:當引數是ndarray時,表示提取對角線;引數是list時,表示構建對角陣列:
>>> list = [x for x in range(1,6)]
>>> print(np.diag(list))
[[1 0 0 0 0]
[0 2 0 0 0]
[0 0 3 0 0]
[0 0 0 4 0]
[0 0 0 0 5]]
Ⅴ.full()方法
full()方法回傳一個由給定的值組成的常數陣列
numpy.full(shape, fill_value, dtype=None, order='C')
>>> print(np.full((3,2),7))
[[7 7]
[7 7]
[7 7]]
full_like(a, fill_value, dtype=None, order='K', subok=True, shape=None)
同樣地,我們也有full_like()方法,它的使用方式和之前的xx_like大致保持一致,回傳的是與給定陣列具有相同形狀和型別的常數陣列,并且由給定的值組成:
>>> data = np.array([[1,2,3],[4,5,6],[7,8,9]])
>>> print(np.full_like(data,7))
[[7 7 7]
[7 7 7]
[7 7 7]]
3)利用陣列范圍來創建
Ⅰ.arange()方法
numpy.arange([start,] stop[, step,], dtype=None)
arange()方法回傳給定間隔內的均勻間隔的值,舉例:
#指明終止位置(不包括),默認起點是0
>>> print(np.arange(5))
[0 1 2 3 4]
#無效
>>> print(np.arange(-5))
[]
#指明開始終止位置
>>> print(np.arange(1,5))
[1 2 3 4]
#指明開始終止位置和布長
>>> print(np.arange(1,5,2))
[1 3]
arange()方法的引數遵守左閉右開規則,并且默認start為0,
Ⅱ.linspace()方法
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
linspace()方法回傳指定間隔內的等間隔數字:
>>> print(np.linspace(1,5,9))
[1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. ]
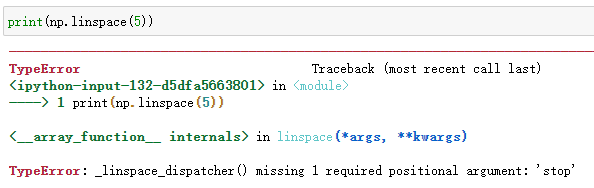
arange()方法的引數遵守左閉右閉規則,并且須設定start和end,num默認為50,
Ⅲ.logspace()方法
logspace(start, stop, num=50, endpoint=True, base=10.0,dtype=None, axis=0)
logspace()方法回傳的數以對數刻度均勻分布:
>>> x = np.logspace(0, 1, 5)
>>> print(x)
[ 1. 1.77827941 3.16227766 5.62341325 10. ]
>>> print(np.log10(x))
[0. 0.25 0.5 0.75 1. ]
>>> print(np.linspace(0, 1, 5))
[0. 0.25 0.5 0.75 1. ]
等價于先用linspace()方法,然后再對結果取以10為底的對數,
4)結構陣列的創建
Ⅰ.利用包含多個元組的串列來定義結構
結構陣列,首先需要定義結構,然后利用np.array()方法來創建陣列,其引數dtype為定義的結構,
>>> peopleType = np.dtype([('name', 'U20'), ('age', 'i1'), ('location', 'U20')])
>>> a = np.array([('xiaoA',20,'Beijing'),('xiaoB',20,'Shanghai'),('xiaoC',25,'Taiwan')],dtype=peopleType)
>>> print(a,type(a))
[('xiaoA', 20, 'Beijing') ('xiaoB', 20, 'Shanghai')
('xiaoC', 25, 'Taiwan')] <class 'numpy.ndarray'>
>>> print(a[0])
('xiaoA', 20, 'Beijing')
>>> print(a[0][0])
xiaoA
Ⅱ.利用字典來定義結構
現改為直接用字典方式訪問,只需對dtype進行處理,如:
>>> peopleType = np.dtype({ 'names': ['name', 'age', 'location'],'formats': ['U30', 'i8', 'U20']})
>>> a = np.array([('xiaoA',20,'Beijing'),('xiaoB',20,'Shanghai'),('xiaoC',25,'Taiwan')],dtype=peopleType)
>>> print(a,type(a))
[('xiaoA', 20, 'Beijing') ('xiaoB', 20, 'Shanghai')
('xiaoC', 25, 'Taiwan')] <class 'numpy.ndarray'>
#訪問所有名字
>>> print(a['name'])
['xiaoA' 'xiaoB' 'xiaoC']
>>> print(a[0])
('xiaoA', 20, 'Beijing')
#這兩種方式均可訪問屬性
>>> print(a[0][0])
xiaoA
>>> print(a[0]['name'])
xiaoA
5)隨機生成
簡單對numpy.random中隨機生成的方法做一個介紹:
| 方法名 | 介紹 |
|---|---|
| seed | 用于指定亂數生成時所用演算法開始的整數值 |
| rand | 生成范圍0-1的隨機浮點數 |
| randint | 生成指定范圍的整數 |
| shuffle | 打亂資料 |
| choice | 指定概率抽取元素 |
| binomial | 實作二項分布 |
| poisson | 實作泊松分布 |
| hypergeometric | 實作超幾何分布 |
| uniform | 實作均勻分布 |
| normal | 實作正態分布 |
| randn | 實作標準正態分布 |
| exponential | 實作指數分布 |
這里只給出前五個方法的案例,其他例子請移步【Numpy-隨機抽樣】章節,這里不再展開:
【Numpy學習16】隨機抽樣
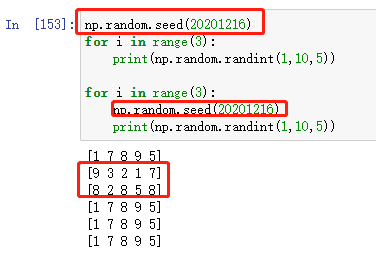
Ⅰ.seed()方法
numpy.random.seed(self, seed=None)
seed()方法用于指定亂數生成時所用演算法開始的整數值,規則:
- 如果使用相同的seed( )值,則每次生成的隨即數都相同
- 如果不設定這個值,則系統根據時間來自己選擇這個值,生成自己的種子,此時每次生成的亂數因時間差異而不同
- 設定的seed()值僅一次有效
>>> np.random.seed(20201216)
>>> print(np.random.randint(1,10,5))
[1 7 8 9 5]
>>> np.random.seed(20201216)
>>> print(np.random.randint(1,10,5))
[1 7 8 9 5]
注意,設定的seed()值僅一次有效,例如:
Ⅱ.rand()方法
numpy.random.rand(d0, d1, ..., dn)
random.rand()方法生成范圍0-1的隨機浮點數:
>>> print(np.random.rand(3,3))
[[0.30072091 0.01052971 0.06391355]
[0.55119221 0.09069377 0.83557964]
[0.85371122 0.91990132 0.27901161]]
Ⅲ.randint()方法
numpy.random.randint(low, high=None, size=None, dtype=int)
random.randint()方法生成指定范圍的整數:
>>> print(np.random.randint(1,10,(3,3)))
[[6 4 4]
[5 9 7]
[9 5 9]]
random.randint()方法遵循左閉右開原則,
Ⅳ.shuffle()方法
numpy.random.shuffle(x)
shuffle()方法用于打亂指定的陣列:
>>> x = np.arange(10)
>>> print(x)
>>> np.random.shuffle(x)
>>> print(x)
[0 1 2 3 4 5 6 7 8 9]
[4 0 8 7 6 9 2 5 1 3]
numpy.random.permutation(x)
同樣地,permutation()方法也可以打亂陣列,但它不會改變原來的陣列,只回傳打亂結果:
>>> x = np.arange(10)
>>> print(x)
[0 1 2 3 4 5 6 7 8 9]
>>> print(np.random.permutation(x))
[8 1 9 2 7 6 4 3 0 5]
>>> print(x)
[0 1 2 3 4 5 6 7 8 9]
我們可以看到,這種方式并沒有改變原始陣列,
另外,shuffle()方法只能對第一維度進行洗牌,如果想對第二維度洗牌,請使用:
numpy.random.Generator.shuffle(x, axis=0)
詳情參考中第三部分第2小節:
【Numpy學習16】隨機抽樣
Ⅴ.choice()方法
numpy.random.choice(a, size=None, replace=True, p=None)
choice()方法用于隨機從一維陣列從隨機抽取元素,默認概率相同:
>>> print(np.random.choice(10,10))
[1 4 8 9 9 3 7 7 3 0]
#不放回
>>> print(np.random.choice(10,10,replace=False))
[8 6 0 9 1 4 3 2 5 7]
#指定概率
>>> print(np.random.choice(10,10,p=[0.1,0,0,0,0,0,0,0,0,0.9]))
[9 9 9 9 9 9 9 0 9 0]
2.np陣列的變形與合并
1)翻轉陣列
| 函式 | 描述 |
|---|---|
| transpose | 對換陣列的維度 |
| T | 和 self.transpose() 相同 |
| rollaxis | 向后滾動指定的軸 |
| swapaxes | 對換陣列的兩個軸 |
Ⅰ.transpose()方法
numpy.transpose(a, axes=None)
transpose()方法用于對換陣列的維度:
>>> a = np.arange(9).reshape(3,3)
>>> print(a)
[[0 1 2]
[3 4 5]
[6 7 8]]
>>> print(np.transpose(a))
[[0 3 6]
[1 4 7]
[2 5 8]]
#三維情況
>>> a = np.random.randint(0,10,(3,2,1))
#交換后面兩個維度
>>> print(np.transpose(a,(0,2,1)).shape)
(3, 1, 2)
Ⅱ.T方法
ndarray.T方法并沒有形參,只能用于轉置:
>>> a = np.arange(9).reshape(3,3)
>>> print(a.T)
[[0 3 6]
[1 4 7]
[2 5 8]]
2)陣列合并
陣列合并主要有下面幾種方法:
| 函式 | 描述 |
|---|---|
| concatenate | 連接沿現有軸的陣列序列 |
| stack | 沿著新的軸加入一系列陣列, |
| hstack | 水平堆疊序列中的陣列(列方向) |
| vstack | 豎直堆疊序列中的陣列(行方向) |
Ⅰ.concatenate()方法
numpy.concatenate((a1, a2, ...), axis=0, out=None)
concatenate()方法在不改變拼接原材料陣列的前提下,對指定的位置(axis)進行粘合:
>>> x = np.random.randint(0,10,(2,2))
>>> y = np.random.randint(0,10,(2,2))
#在第一維度進行拼接 下面三種方法是等價的
>>> print(np.concatenate([x,y]).shape)
(4, 2)
>>> print(np.r_[x,y].shape)
(4, 2)
>>> print(np.vstack([x,y]).shape)
(4, 2)
#在第二維度進行拼接 下面三種方法是等價的
>>> print(np.concatenate([x,y],axis=1).shape)
(2, 4)
>>> print(np.hstack([x,y]).shape)
(2, 4)
>>> print(np.c_[x,y].shape)
(2, 4)
concatenate()方法默認對第一維度進行粘合,且不會改變生成陣列的維度,
Ⅱ.stack()方法
numpy.stack(arrays, axis=0, out=None)
>>> x = np.random.randint(0,10,(3,4))
>>> y = np.random.randint(0,10,(3,4))
>>> print(np.stack([x,y]).shape)
(2, 3, 4)
>>> print(np.stack([x,y],axis=1).shape)
(3, 2, 4)
>>> print(np.stack([x,y],axis=2).shape)
(3, 4, 2)
與concatenate方法不同的是,stack方法生成的陣列比原始陣列維度多1,且多的維度的長度等于原始陣列的長度:
- 兩個shape為(3,3)的原始陣列,axis=0,結果陣列shape為(2,3,3)
- 兩個shape為(3,3)的原始陣列,axis=1,結果陣列shape為(3,2,3)
- 兩個shape為(3,3)的原始陣列,axis=2,結果陣列shape為(3,3,2)
且位置正是axis,
3)維度變換
在numpy中,修改陣列維度的方法有如下幾種:
| 函式 | 描述 |
|---|---|
| reshape | 不改變資料的條件下修改形狀 |
| flat | 陣列元素迭代器 |
| flatten | 回傳一份陣列拷貝,對拷貝所做的修改不會影響原始陣列 |
| ravel | 回傳展開陣列 |
Ⅰ.reshape()方法
numpy.reshape(a, newshape, order='C')
reshape()方法可以在不改變資料的條件下修改形狀:
>>> a = np.arange(12)
>>> print(a)
[ 0 1 2 3 4 5 6 7 8 9 10 11]
>>> print(a.reshape(3,4).shape)
(3, 4)
>>> print(a.reshape(2,6).shape)
(2, 6)
# -1表示自動填充,reshape引數最多只允許有一個-1存在
>>> print(a.reshape(2,-1).shape)
(2, 6)
我們可以看到,reshape(2,6)和reshape(2,-1)的輸出結果是一樣的,這是因為-1進行了自動補全,即用總數除其他維度的維數,
Ⅱ.flatten()方法
ndarray.flatten(order='C')
flatten()方法回傳原始陣列展開后的拷貝,對拷貝所做的修改不會影響原始陣列:
>>> a = np.arange(6).reshape(2,3)
>>> b = a.flatten()
>>> b[0] = 100
>>> print(b)
[100 1 2 3 4 5]
>>> print(a)
[[0 1 2]
[3 4 5]]
注:在這里只介紹陣列操作的部分方法,其他方法請參考:
【Numpy學習09】陣列操作
3.np陣列的切片與索引
1)整數索引
>>> a = np.random.randint(0,10,5)
>>> print(a,a[2])
[2 7 3 6 6] 3
>>> b = np.random.randint(0,10,(5,5))
>>> print(b,b[3][1],b[3,1])
[[3 7 0 7 9]
[1 6 9 3 1]
[2 7 5 0 7]
[6 2 6 1 0]
[5 5 6 8 1]] 2 2
>>> c = np.random.randint(0,10,(3,3,3))
>>> print(c,c[0][0][0],c[0,0,0])
[[[6 1 5]
[9 5 9]
[2 3 5]]
[[1 1 5]
[2 1 5]
[1 5 4]]
[[3 5 9]
[8 9 6]
[7 3 3]]] 6 6
2)切片索引
#二維陣列
>>> a = np.random.randint(0,10,(5,5))
>>> print(a)
[[7 7 9 8 0]
[7 9 9 9 9]
[2 1 4 7 7]
[4 9 7 3 8]
[2 1 8 2 8]]
#第2行與第3、4列交匯的資料
>>> print(a[1,2:4])
[9 9]
#第2列與第3、4行交匯的資料
>>> print(a[2:4,1])
[1 9]
#第3、4行與第3、4列交匯的資料
>>> print(a[2:4,2:4])
[[4 7]
[7 3]]
#從第一行開始以2為步長的行與從第一行開始以2為步長的列交匯的資料
>>> print(a[::2,::2])
[[7 9 0]
[2 4 7]
[2 8 8]]
#去掉最后一列
>>> print(a[...,:-1])
[[7 7 9 8]
[7 9 9 9]
[2 1 4 7]
[4 9 7 3]
[2 1 8 2]]
>>> a = np.arange(9).reshape(3,3)
>>> print(a)
[[0 1 2]
[3 4 5]
[6 7 8]]
>>> print(a[np.ix_([0,2],[0,2])])
[[0 2]
[6 8]]
np.ix_()方法完美解決了任何幾行和幾列的交集問題,
3)整數陣列索引
>>> a = np.random.randint(0,10,(5,5))
>>> print(a)
[[6 2 9 7 2]
[8 5 4 5 9]
[1 4 3 3 9
[9 8 0 8 8]
[7 1 6 5 2]]
>>> s = [0,2,3]
>>> p = [1,2,4]
>>> print(a[s,p])
[2 3 8]
4)布爾索引
#控制型別,找到不是nan的資料
>>> c = np.array([np.nan,9,8,7,np.nan,6,5])
>>> d = np.logical_not(np.isnan(c))
>>> print(d)
[False True True True False True True]
>>> print(c[d])
[9. 8. 7. 6. 5.]
4.常用函式
1)where
numpy.where(condition[, x, y])
numpy.where() 方法回傳輸入陣列中滿足給定條件的元素的索引:
#一維情況
>>> a = np.random.randint(0,10,5)
>>> print(a)
[0 6 1 0 8]
>>> print(np.where(a>5))
(array([1, 4], dtype=int64),)
#二維情況
>>> a = np.random.randint(0,10,(3,3))
>>> print(a)
[[7 6 2]
[2 7 7]
[4 9 9]]
>>> print(np.where(a>5))
(array([0, 0, 1, 1, 2, 2], dtype=int64), array([0, 1, 1, 2, 1, 2], dtype=int64))
在二維情況下,回傳的陣列分別是x和y的坐標集合,如上面的例子,分別是(0,0)、(0,1)…(2,2),不要混淆,
numpy.where() 方法還有另外一種用法,回傳的是與原始數字相同shape的陣列并且改變其中的資料,但并不影響原始陣列:
>>> a = np.random.randint(0,10,5)
>>> print(a)
[6 6 4 5 9]
>>> print(np.where(a>5,0,a))
[0 0 4 5 0]
>>> print(a)
[6 6 4 5 9]
2)nonzero,argmax,argmin
Ⅰ.nonzero()方法
numpy.nonzero(a)
numpy.nonzero() 方法回傳輸入陣列中非零元素的索引:
#一維
>>> a = np.random.randint(-1,2,10)
>>> print(a)
[ 0 1 1 0 1 0 0 0 0 -1]
>>> print(np.nonzero(a))
(array([1, 2, 4, 9], dtype=int64),)
#二維
>>> a = np.random.randint(-1,2,(3,3))
>>> print(a)
[[ 0 0 1]
[ 1 -1 -1]
[ 0 0 1]]
>>> print(np.nonzero(a))
(array([0, 1, 1, 1, 2], dtype=int64), array([2, 0, 1, 2, 2], dtype=int64))
#回傳所有非0值
>>> print(a[np.nonzero(a)])
[ 1 1 -1 -1 1]
numpy.nonzero() 方法的一些規則:
- 只有
a中非零元素才會有索引值,那些零值元素沒有索引值 - 回傳一個長度為
a.ndim的元組(tuple),元組的每個元素都是一個整數陣列(array) - 每一個array均是從一個維度上來描述其索引值,比如,如果
a是一個二維陣列,則tuple包含兩個array,第一個array從行維度來描述索引值;第二個array從列維度來描述索引值,注意,一位陣列回傳的結果外層有一層元組包裹 - 通過
a[nonzero(a)]得到所有a中的非零值
Ⅱ.argmax()和argmin()方法
numpy.argmax(a, axis=None, out=None)
numpy.argmin(a, axis=None, out=None)
由于argmax()和argmin()方法用法相似,這里只介紹前者,argmax()方法回傳的是根據axis=n為參考,沿著第n維度的最大值的索引,如果不設定axis,那么原陣列會被平鋪:
>>> a = np.random.randint(0,10,5)
>>> print(a)
[4 2 1 5 0]
>>> print(np.argmax(a))
3
如果有超過1個最大值,會回傳第一個:

3)any,all
numpy.all(a, axis=None, out=None, keepdims=<no value>)
numpy.any(a, axis=None, out=None, keepdims=<no value>)
真值測驗包含np.all(),np.any()兩種方法:
np.all()判斷是否全為真:如果是就回傳True;否則回傳False,np.any()判斷是否至少有一個為真:如果有就回傳True;否則回傳False,
舉例:
>>> a = np.random.randint(0,5,5)
>>> print(a)
[0 0 0 4 0]
>>> print(np.all(a<5))
True
>>> print(np.any(a<0))
False
>>> print(np.all([2,np.nan]))
True
注意對np.nan的判斷,實際上它是一個numpy.float64物件,真值判斷時它為True,
4)cumprod,cumsum,diff
numpy.cumprod(a, axis=None, dtype=None, out=None)
numpy.cumsum(a, axis=None, dtype=None, out=None)
numpy.diff(a, n=1, axis=-1, prepend=<no value>, append=<no value>)
這三個方法分別代表累積、累加、和相鄰差:
>>> a = np.arange(1,10).reshape(3,3)
>>> print(a)
[[1 2 3]
[4 5 6]
[7 8 9]]
>>> print(np.cumprod(a))
[ 1 2 6 24 120 720 5040 40320 362880]
>>> print(np.cumsum(a))
[ 1 3 6 10 15 21 28 36 45]
>>> print(np.diff(a))
[[1 1]
[1 1]
[1 1]]
注意,這里diff()方法的axis默認為-1,對于上面的例子,即求相鄰列的差,
5)統計函式
Nump中的統計函式如下:
這里只舉幾個常用的例子:
>>> nums = np.array([[10, 7, 4],[3, 2, 1]])
#中位數
>>> print(np.median(nums))
3.5
#70分位數
>>> print(np.percentile(nums,70))
5.5
#均值
>>> print(np.mean(nums))
4.5
#極差
>>> print(np.ptp(nums))
9
#方差
>>> print(np.var(nums))
9.583333333333334
#標準差
>>> print(np.std(nums))
3.095695936834452
5.廣播機制
當運算中的 2 個陣列的形狀不同時,numpy 將自動觸發廣播機制,
廣播的規則:
- 讓所有輸入陣列都向其中形狀最長的陣列看齊,形狀中不足的部分都通過在前面加 1 補齊,
- 輸出陣列的形狀是輸入陣列形狀的各個維度上的最大值,
- 如果輸入陣列的某個維度和輸出陣列的對應維度的長度相同或者其長度為 1 時,這個陣列能夠用來計算,否則出錯,
- 當輸入陣列的某個維度的長度為 1 時,沿著此維度運算時都用此維度上的第一組值,
簡單概括就是,如果shape不匹配,必須滿足情況1或情況2才能滿足廣播,超過二維時可以是截面圖:
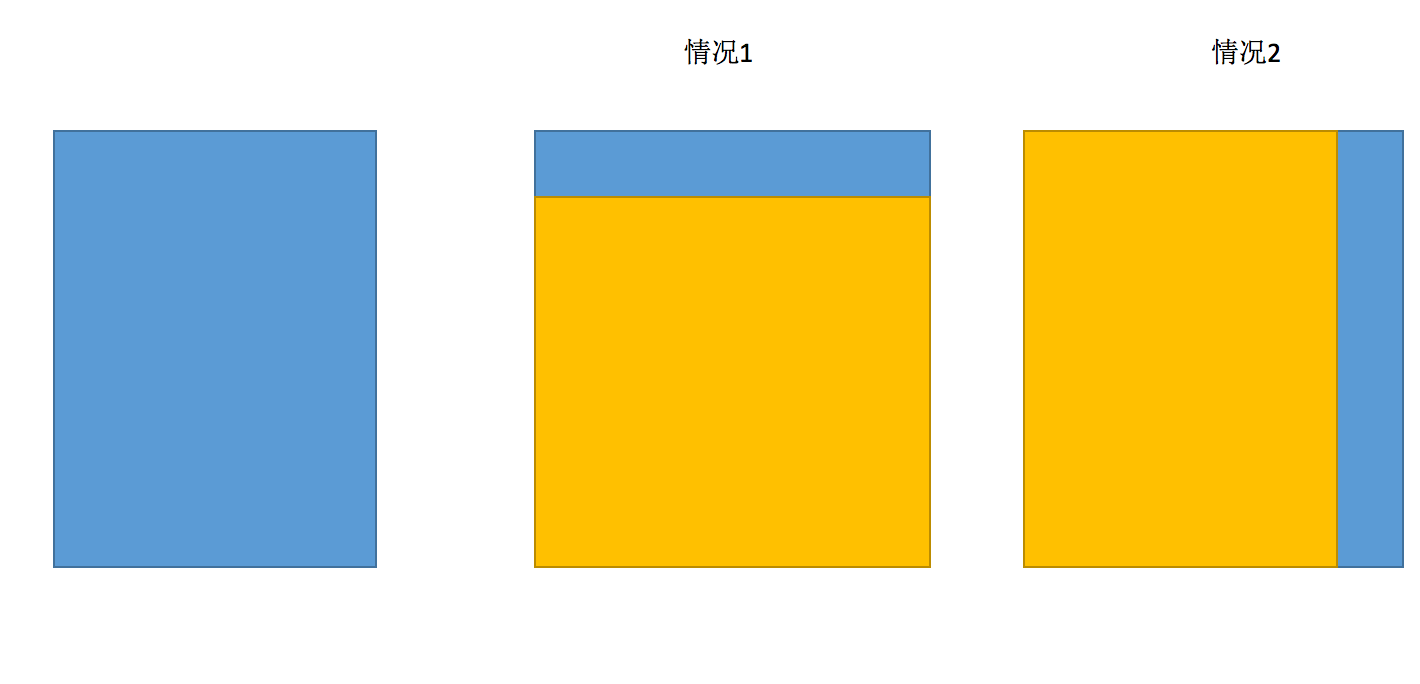
舉例:
>>> a = np.random.randint(0,10,(2,1))
>>> b = np.random.randint(0,10,(1,3))
>>> print((a+b).shape)
(2, 3)
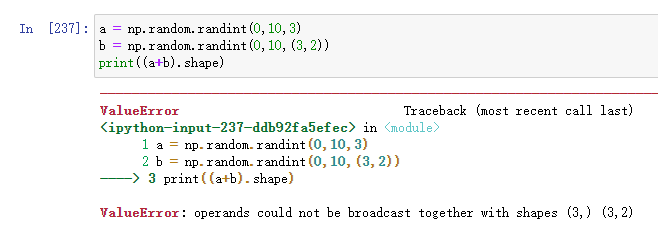
兩個一維陣列必須保證長度相同,否則:

其中一個為一維時,另一個陣列最后一個維度的維數須為1或者等于一維陣列的長度,否則:
6.向量與矩陣的計算
1)向量內積 dot
numpy.dot(a, b, out=None)
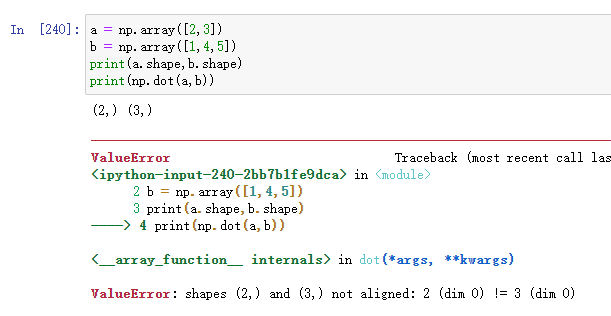
Ⅰ.一維向量的積

當a和b均為一維時,dot()方法即為求2個陣列對應的乘積:1*3+2*4 = 11
,注意此時a和b的長度需要保持一致,否則會報錯:
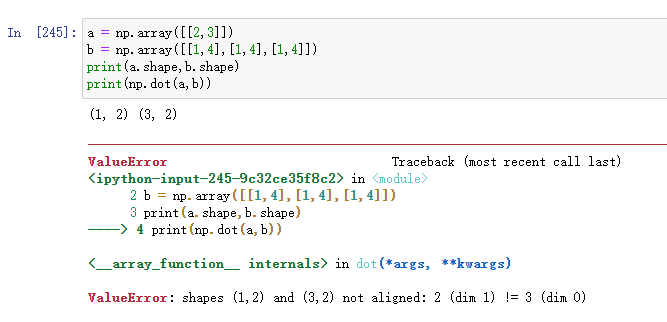
Ⅱ.shape分別為(a,m)和(m,b)的矩陣之積

上面的例子就是正常的矩陣乘法,我們也可以用np.matmul()方法實作
但需要保證a最后維度的維數和b第一維度的維數保持一致,否則會報錯:
Ⅲ.矩陣與標量之積
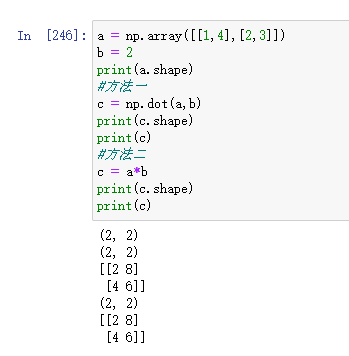
此時,可以直接用‘*’代替np.dot()方法
Ⅳ.第二個引數是一維向量的情況

我們可以看到,此時ndarray在一維時的表達解答了我在前面學習程序中的思考,為什么一維ndarray變數的shape是(n,)而不是(,n),最后的結果依然保持一維,
此時需要滿足矩陣最后維度的維數等于向量的長度,否則依然會報錯:
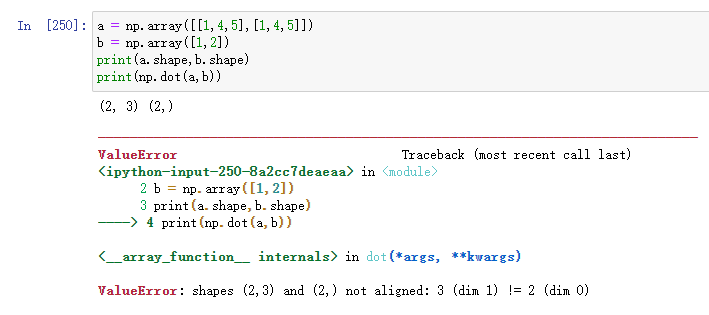
注:對于線性代數中的n維行向量,numpy表示為形如(n,)的一位陣列;對于線性代數中的n維列向量,numpy表示為行如(n,1)的二維陣列,
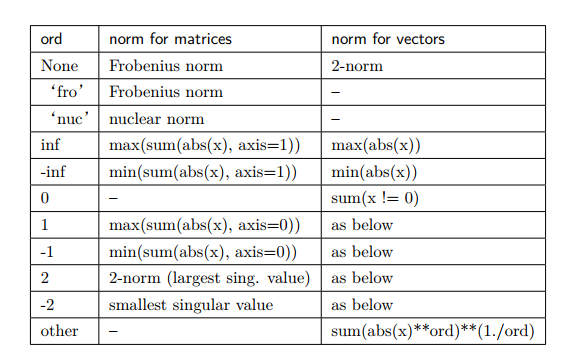
2)向量范數和矩陣范數

3)矩陣乘法

此種情況下,與np.dot()方法保持一致,
三、練習
Ex1:利用串列推導式寫矩陣乘法
>>> a = np.array([sum(M1[i,k]*M2[k,j] for k in range(p)) for i in range(m) for j in range(n)]).reshape(m,n)
>>> print(a)
[[1.21998497 1.22514323 0.96636003 0.7386822 ]
[1.01499004 1.08397318 0.77515486 0.53678796]]
>>> b = M1@M2
>>> print(b)
[[1.21998497 1.22514323 0.96636003 0.7386822 ]
[1.01499004 1.08397318 0.77515486 0.53678796]]
>>> print(np.allclose(a,b))
True
思路:

先求出m,p,n這兩個矩陣長寬指標,然后最外層的兩層回圈分別是m和n,最內層的回圈是計算單個元素結果,后面要加一個reshape()方法去固定生成矩陣的維數,
Ex2:更新矩陣
>>> A = np.arange(1,10).reshape(3,-1)
>>> B = A*(1/A).sum(1).reshape(-1,1)
>>> print(B)
[[1.83333333 3.66666667 5.5 ]
[2.46666667 3.08333333 3.7 ]
[2.65277778 3.03174603 3.41071429]]
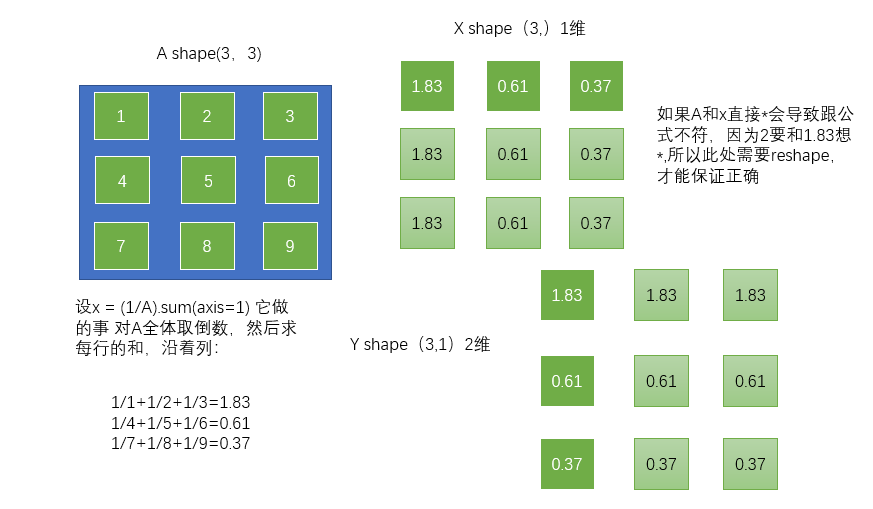
Ex3:卡方統計量
>>> np.random.seed(20201216)
>>> def getB(A):
>>> #shape:5,
>>> a = A.sum(axis=0)
>>> #shape:8,
>>> b = A.sum(axis=1)
>>> total = A.sum()
>>> #生成shape滿足(8,5) 所以要把b提升維度 再利用廣播特性
>>> B = a*b.reshape(-1,1)/total
>>> return B
>>> A = np.random.randint(10, 20, (8, 5))
>>> B = getB(A)
>>> result = np.power(A-B,2)/B
>>> print(result.sum())
17.490048845986898
Ex4:改進矩陣計算的性能
>>> np.random.seed(20201216)
>>> m, n, p = 100, 80, 50
>>> B = np.random.randint(0, 2, (m, p))
>>> U = np.random.randint(0, 2, (p, n))
>>> Z = np.random.randint(0, 2, (m, n))
>>> res = [(np.power(B[i]-U[...,j],2).sum())*Z[i,j] for i in range(m) for j in range(n)]
print(sum(res))
102517
方法一:利用串列推導運算式改進性能:

方法二:利用Numpy特性—向量化與廣播:
R的左側結果是一個m * n的矩陣,暫定為A,右側Z也是一個m * n的矩陣,重點是將左側矩陣用代碼表示出來,我嘗試用一種簡單清晰的方式解釋如何用代碼表示:
第一步,求A的第一個元素:
由公式可知在固定i和j時,就是求一個常量,以i=0,j=0為例:
#i鎖定為0 j鎖定為0 生成1個item
>>> b = B[0]
>>> print(b.shape)
(50,)
>>> u = U[...,0]
>>> print(u.shape)
(50,)
#這里利用Numpy向量化進行展開,實際上是陣列中相對應位置的每一個元素的平方,而不要理解成矩陣乘法
>>> result = b**2+u**2-2*b*u
>>> print(result.shape)
(50,)
>>> print(result.sum())
24
這里的b和u都是一維陣列,長度都為50(也就是p),而b**2的shape依然與b保持一致,這里利用了Numpy中的向量化特性,意思是對b的每一個元素求平方,
第二步,求A的第一行元素:
由公式可知在固定i時,就是在第一步的基礎上重復n次,以i=0為例:
>>> b = B[0]
>>> print(b.shape)
(50,)
>>> b = b.reshape(-1,1)
>>> result = (b**2+U**2-2*b*U).sum(axis=0)
>>> print(result.shape)
(80,)
這里解釋一下為什么要對b進行reshape操作,在第一步中b和u都是一維陣列且長度相同,所以可以直接進行數學運算,但在此處U的shape為(p,n),根據廣播的法則b * U會出錯,此時需要對b進行升維,即變為(p,1),這樣b * N的結果即為(p,n),
在這一步,我們最終得到的結果是一個長度為n的一位陣列,它代表了A矩陣的第一行,
第三步,求整個A:
由公式可知,這一步就是在第二步的基礎上重復m次:
>>> print(((B**2).sum(axis=1,keepdims=True) + (U**2).sum(axis=0) - 2*B@U).shape)
(100, 80)
讓我們來依次解釋,從結果反推我們不難得知最后的結果需要滿足shape為(m,n),B@U結果的shape為(m,n),而B ** 2的shape為(m,p),所以要對最后一個維度進行求和并且保留當前維度,同理U**2的shape為(p,n),所以要對第一個維度進行求和,這樣就可以保證可以成功生成m*n的矩陣,
從另一個角度,對于B來說,單獨一行的資訊屬于一個整體,所以需要將它們進行按列求和匯總;同理,對于U來說,單獨一列的資訊屬于一個整體,所以需要將它們按行求和匯總,并且對于B來說,需要滿足廣播條件,所以B要保持自己的維度屬性,
時耗查看:

對比方法一幾乎節省了99%的時間,原因是充分利用了Numpy的向量化和廣播特性,
Ex5:連續整數的最大長度
>>> def func(data):
>>> #在頭尾插入一個標志變數
>>> data.insert(0,data[0]-2)
>>> data.insert(len(data),data[-1]+2)
>>> return np.diff(np.nonzero(np.diff(data)!=1)).max()
>>> print(func([1,2,5,6,7]))
3
>>> print(func([3,2,1,2,3,4,6]))
4
思路:先在頭尾插入標志變數,防止出現0,1,2,3,5或者0,2,3,4,5這樣左或右存在連續邊界值,第一次diff計算的是原陣列相鄰差值,然后求不連續的坐標,之后再使用第二次diff求得相鄰兩個不連續坐標的差值,然后求最大值即為所求,
自己的做法:
>>> def func(x):
>>> a = np.diff(x)
>>> result = 0
>>> temp = 0
>>> for item in a:
>>> if item == 1:
>>> temp += 1
>>> else:
>>> result = temp if temp > result else result
>>> temp = 0
>>> result = temp if temp > result else result
>>> return result+1
>>> print(func([1,2,5,6,7]))
3
>>> print(func([3,2,1,2,3,4,6]))
4
用一次diff方法生成a,遍歷一次a,得到結果,時間復雜度O(n),空間復雜度O(1),
參考文獻
#Python語法糖系列
1、https://blog.csdn.net/five3/article/details/83474633
#Python菜鳥教程
2、https://www.runoob.com/python/python-tutorial.html
#Numpy系列學習手冊
3、Numpy入門系列學習手冊
陣列的創建
陣列操作
索引與切片
向量化和廣播
數學函式
邏輯函式
排序,搜索和計數
隨機抽樣
統計相關
線性代數
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236593.html
標籤:python