Task02 sklearn邏輯回歸Demo
一、學習內容概括
通過一個小例子,掌握邏輯回歸的sklearn函式呼叫使用,
學習地址、參考資料:
1.阿里云天池-AI訓練營機器學習:https://tianchi.aliyun.com/specials/promotion/aicampml?invite_channel=1&accounttraceid=7df048c2ce194081b514fd2c8e9a3f00cqmm
2.Sklearn中文檔案:http://www.scikitlearn.com.cn/
3.Matplotlib.pyplot:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.html#module-matplotlib.pyplot
4.Numpy手冊:https://numpy.org/doc/stable/index.html
二、具體學習內容
1 庫函式匯入
## 基礎函式庫
import numpy as np
## 匯入畫圖庫
import matplotlib.pyplot as plt
import seaborn as sns
## 匯入邏輯回歸模型函式
from sklearn.linear_model import LogisticRegressionscikit-learn 是一個開源的機器學習庫,它支持監督學習和無監督學習,它還提供了用于模型擬合,資料預處理,模型選擇和評估以及許多其他實用程式的各種工具,
監督學習下有很多線性模型,邏輯回歸就是一種,該模型利用邏輯函式將單次試驗的可能結果輸出為概率,用來解決分類問題,scikit-learn 中邏輯回歸在LogisticRegression類中實作了二分類(binary)、一對多分類(one-vs-rest)及多項式 logistic 回歸,并帶有可選的 L1 和 L2 正則化,scikit-learn的邏輯回歸在默認情況下使用L2正則化,
2 模型訓練
## Demo演示LogisticRegression分類
## 構造資料集
x_features = np.array([[-1, -2], [-2, -1], [-3, -2], [1, 3], [2, 1], [3, 2]])#6x2
y_label = np.array([0, 0, 0, 1, 1, 1])
## 呼叫邏輯回歸模型
lr_clf = LogisticRegression()
## 用邏輯回歸模型擬合構造的資料集
lr_clf = lr_clf.fit(x_features, y_label) 因為本次訓練只是一個小練習,所以不需要加載一些標準資料集,自己構建一個簡單的資料集就行了,輸入變數x_features是6x2的矩陣,標記資訊y_label是兩個離散值0、1,意思是我們訓練這6個樣本,分成2類分別是0和1,擬合出一個估計器(在這里就是一個訓練好的邏輯回歸模型),再用這估計器去預測未知樣本所屬的類別,
在sklearn中,分類的估計器是一個python物件,因為都封裝好了,所以我們把估計器當成一個黑箱去操作就行了,我們先呼叫邏輯回歸模型把估計器實體化并命名為lr_clf ,lr_clf呼叫fit方法,輸入是訓練集,以此來擬合資料完成學習,把習得的估計器更新給lr_clf,
3 模型引數查看
## 其擬合方程為 y=w0+w1*x1+w2*x2
## 查看其對應模型的w
print('the weight of Logistic Regression:',lr_clf.coef_)
## 查看其對應模型的w0
print('the intercept(w0) of Logistic Regression:',lr_clf.intercept_)運行結果:
the weight of Logistic Regression: [[0.73455784 0.69539712]]
the intercept(w0) of Logistic Regression: [-0.13139986]sklearn線性模型中,目標值y是輸入變數x的線性組合,如果是預測值,那有:
,在整個模塊中定義向量
作為coef_,定義
作為intercept_,我們的輸入變數x_features是6x2的矩陣,表示我們有6個樣本,每個樣本都有2個屬性,所以我們的假設函式有2個未知項x1、x2,2個引數w1、w2:
4 資料和模型可視化
4.1 可視化構造的資料樣本點
## 可視化構造的資料樣本點
plt.figure()
plt.scatter(x_features[:,0],x_features[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
plt.show()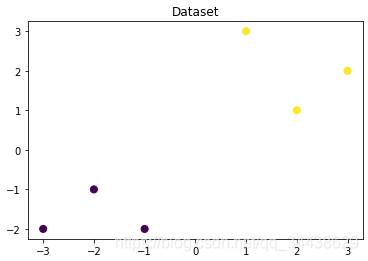
4.1.1 scatter()函式:繪制散點圖
matplotlib.pyplot.scatter:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.scatter.html#matplotlib.pyplot.scatter
相關代碼:plt.scatter(x_fearures[:,0],x_fearures[:,1], c=y_label, s=50, cmap='viridis')
語法:matplotlib.pyplot.scatter(x,y,c = None,s = None,cmap = None,...)
x,y表示平面點的位置,可以用陣列形式表示,x表示點的橫坐標,y表示對應點的縱坐標,x_features[:,0] 是array([-1, -2, -3, 1, 2, 3]),x_features[:,1] 是array([-2, -1, -2, 3, 1, 2]),
c表示每一個點的顏色的標記值,可以用陣列形式表示,這里c并不是設定點的顏色,只是會給這個點分配一個標記值,可搭配其他項一起使用,比如cmap項可以把顏色的指示值映射到具體顏色上去,這里c=y_label=array([0, 0, 0, 1, 1, 1]),表示對應的前三個點是一種顏色,后三個點是一種顏色,如果不設定c值,默認所有點是一個顏色,
s表示點大小,
cmap設定點的顏色,可以用注冊的顏色表名表示,注意僅當c是浮點數陣列時才使用cmap,默認值就是viridis(matplotlib.pyplot.viridis)所以本條代碼去掉cmap也會得到一樣的顏色,可以改成其他值如summer、winter、hot、cool試試效果,更多的顏色:https://matplotlib.org/examples/color/colormaps_reference.html,
4.2 可視化決策邊界
# 可視化決策邊界
plt.figure()
plt.scatter(x_features[:,0],x_features[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
nx, ny = 200, 100
#獲取當前軸的極限,如x軸:left, right = plt.xlim()
#x_min = -3,3, x_max = 3.3;y_min = -2.25, y_max = 3.25
x_min, x_max = plt.xlim()
y_min, y_max = plt.ylim()
#linspace(x_min, x_max, nx)回傳一個numpy陣列,包含了從x_min到x_max等間隔的nx個值
#meshgrid()從坐標向量回傳網格點坐標矩陣,
x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
#ravel()呼叫它的陣列展平變為一維陣列
#c_()生成一個新矩陣,把x_grid.ravel()變為新矩陣的第一列,y_grid.ravel()變為新矩陣的第二列,最終shape為(nx*ny,0)
#如此,生成了一個20000行,2列的測驗集
#predict_proba()函式進行資料預測
z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
z_proba = z_proba[:, 1].reshape(x_grid.shape)
#繪制邊界線
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()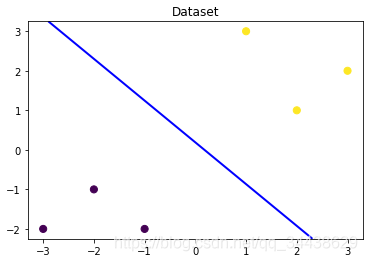
4.2.1 meshgrid()函式:從坐標向量到坐標網格矩陣
numpy.meshgrid()函式:https://numpy.org/doc/stable/reference/generated/numpy.meshgrid.html
詳解meshgrid()函式參考資料:https://blog.csdn.net/lllxxq141592654/article/details/81532855
相關代碼:x_grid, y_grid = np.meshgrid(np.linspace(x_min, x_max, nx),np.linspace(y_min, y_max, ny))
語法:X,Y=np.meshgrid(x,y),輸入:x,y是兩組一維陣列,輸出:X,Y是坐標矩陣
概念比較抽象,直接代入例子,上文的代碼中,x表示橫軸上[-3.3,3.3]等間隔的nx個點,y表示縱軸上[-2.25,3.25]等間隔的ny個點,我們可以動手畫出x軸、y軸上的間隔點,然后我們把x軸上的間隔點沿豎直方向發射直線,y軸上的間隔點橫向發射直線,這些直線一交叉就形成一張網格,豎向直線有nx條,橫向直線有ny條,處在這些直線交叉的點就叫做網格點,共有nx乘ny個,注意不包括坐標軸上的點,坐標軸上的點并不是交叉點!所有這些網格點的橫坐標從上到下,從左到右排列,形成一個坐標矩陣記為X,X就有ny行nx列,X形狀為(ny,nx),同理,所有網格點的縱坐標也形成一個坐標矩陣記為Y,Y形狀也是(ny,nx),網格大概的樣子如參考資料里的這張圖,綠色的點就是所有網格點,但注意它并不是按軸的左右極限均勻劃分的,所以我們只需要從這張圖里知道網格坐標矩陣的點是什么樣子的就行:
4.2.2 predict_proba()函式
詳解predict_proba()和predict()參考資料:http://sofasofa.io/forum_main_post.php?postid=1000600
相關代碼:z_proba = lr_clf.predict_proba(np.c_[x_grid.ravel(), y_grid.ravel()])
函式的輸入np.c_[x_grid.ravel(), y_grid.ravel()]是nx*ny行2列的矩陣,作為測驗集,輸出z_proba也是nx*ny行2列,每一行代表預測該行樣本的標簽為0或為1的概率,2列是因為我們的標簽總共分兩類,第一列代表預測本行樣本的標簽是0的概率,第二列代表預測本行樣本的標簽是1的概率,每行的兩列概率值相加必須為1,
z_proba[:, 1]意思是預測所有的測驗集樣本的標簽為1的概率組成的一維陣列,共有nx*ny個值,所以形狀是1行nx*ny列,
z_proba = z_proba[:, 1].reshape(x_grid.shape),根據4.2.1的分析,坐標矩陣的形狀是(ny,nx),即x_grid.shape是(ny,nx),z_proba是由1行nx*ny列的一維陣列重塑為ny行nx列的二維陣列,
4.2.3 contour()函式
matplotlib.pyplot.contour:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.contour.html#matplotlib.pyplot.contour
相關代碼:plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
語法:contour([X, Y,] Z, [levels], ...)
X,Y為等長的一維陣列,表示坐標點的位置
Z為二維陣列,表示平面點(Xi,Yi)映射的函式值,在我們代碼里,這個函式值z_proba代表的是每一個預測樣本點的標簽為1的概率值,
[levels]為int或其他,確定輪廓線/區域的數量和位置,這里設定0.5是因為我們邏輯回歸把大于等于0.5的和小于0.5的分成不同類,
4.3 可視化預測新樣本
### 可視化預測新樣本
plt.figure()
## new point 1
x_features_new1 = np.array([[0, -1]])
plt.scatter(x_features_new1[:,0],x_features_new1[:,1], s=50, cmap='viridis')
plt.annotate(s='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
## new point 2
x_features_new2 = np.array([[1, 2]])
plt.scatter(x_features_new2[:,0],x_features_new2[:,1], s=50, cmap='viridis')
plt.annotate(s='New point 2',xy=(1,2),xytext=(-1.5,2.5),color='red',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
## 訓練樣本
plt.scatter(x_features[:,0],x_features[:,1], c=y_label, s=50, cmap='viridis')
plt.title('Dataset')
# 可視化決策邊界
plt.contour(x_grid, y_grid, z_proba, [0.5], linewidths=2., colors='blue')
plt.show()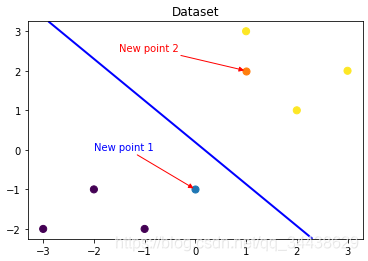
4.3.1 annotate()函式:用文本text注釋點xy
matplotlib.pyplot.annotate:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.annotate.html#matplotlib.pyplot.annotate
相關代碼:plt.annotate(text='New point 1',xy=(0,-1),xytext=(-2,0),color='blue',arrowprops=dict(arrowstyle='-|>',connectionstyle='arc3',color='red'))
語法:matplotlib.pyplot.annotate(text,xy,xytext,color,arrowprops,...)
text表示注釋文本,
xy表示要注釋的點坐標(x,y),
xytext表示放置文本的位置,
color表示注釋點顏色,
arrowprops表示在位置xy和xytext之間繪制箭頭,dict字典形式,鍵arrowstyle='-|>'表示箭頭樣式head_length = 0.4,head_width = 0.2,鍵connectionstyle='arc3'表示連接方式,連線的弧度= 0.0,鍵color='red'表示箭頭顏色是紅色,
5 模型預測
## 在訓練集和測驗集上分布利用訓練好的模型進行預測
y_label_new1_predict = lr_clf.predict(x_features_new1)
y_label_new2_predict = lr_clf.predict(x_features_new2)
print('The New point 1 predict class:\n',y_label_new1_predict)
print('The New point 2 predict class:\n',y_label_new2_predict)
## 由于邏輯回歸模型是概率預測模型(前文介紹的 p = p(y=1|x,\theta)),所有我們可以利用 predict_proba 函式預測其概率
y_label_new1_predict_proba = lr_clf.predict_proba(x_features_new1)
y_label_new2_predict_proba = lr_clf.predict_proba(x_features_new2)
print('The New point 1 predict Probability of each class:\n',y_label_new1_predict_proba)
print('The New point 2 predict Probability of each class:\n',y_label_new2_predict_proba)運行結果:
The New point 1 predict class:
[0]
The New point 2 predict class:
[1]
The New point 1 predict Probability of each class:
[[0.69567724 0.30432276]]
The New point 2 predict Probability of each class:
[[0.11983936 0.88016064]]
訓練好的回歸模型將x_features_new1預測為了類別0(判別面左下側),x_features_new2預測為了類別1(判別面右上側),其訓練得到的邏輯回歸模型的概率為0.5的判別面為上圖中藍色的線,
三、學習問題和解決方法記錄
Q:通過跟敲代碼,發現自己對python、numpy的語法很多都不熟,基礎不扎實,像是x_features[:,0]這樣的形式都不知道該如何解釋,
A:經過查詢,這屬于numpy陣列切片知識,在敲代碼的時候遇到不理解的矩陣、向量其實可以多列印看看生成的到底是什么,這樣更容易消化語法知識,
四、學習總結
雖然這次只是寫一個很小的例子,但是也從中看到自己基礎面不好的問題,以后要多敲代碼夯實基礎,另外,我發現“遇到問題、查詢、理解”的程序其實不慢,但當想整理下來整個思考程序,想自己給自己說明白并不容易,而且在整理程序中還會不經意發現一些隱藏的細節問題,總之,我認為學習不能止步于“感覺自己懂了”,而是應該更進一步“自己給自己講明白”,如果能達到“給別人講明白”就更好了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236597.html
標籤:python
上一篇:ORM正向和反向查詢