目錄
- 1. 通過代理服務發送請求
- 2. 獲取免費的代理 IP
- 3. 檢測代理 IP 是否有效
1. 通過代理服務發送請求
在爬取網頁的程序中,經常會出現不久前可以爬取的網頁現在無法爬取的情況,這是因為您的 IP 被爬取網站的服務器屏蔽了,此時,代理服務可以為您解決這一麻煩,設定代理時,首先需要找到代理地址,例如,58.220.95.80,對應的埠號為 9401,完整的格式為 58.220.95.80:9401,代碼如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:7.代理的應用.py
@time:2020/11/13
"""
import requests # 匯入網路請求模塊
from lxml import etree
# 頭部資訊
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
proxies = {'http': 'http://58.220.95.80:9401',
'https': 'https://58.220.95.80:9401' # 設定代理IP與對應的埠號
}
try:
# 對需要爬取的網頁發送請求
response = requests.get(url="https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80",
headers=headers, proxies=proxies, timeout=3)
print(response.status_code) # 列印回應狀態碼
response.encoding = "utf8" # 進行編碼
html = etree.HTML(response.text) # 決議HTML
info = html.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td//text()')[1:]
info = " ".join(info).replace("\xa0", "").strip().replace("本機IP:", "本機IP: ")
print(info) # 輸出當前IP匿名資訊
except Exception as e:
print(f"錯誤例外資訊為: {e}") # 列印例外資訊
程式運行結果如下圖所示:
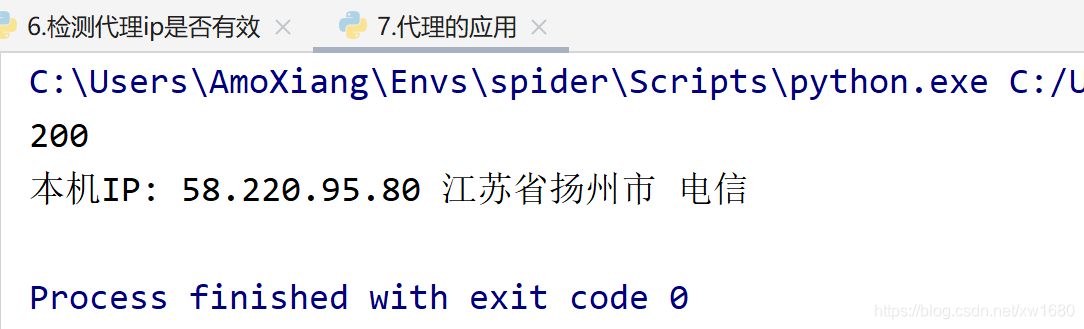
由于示例中代理 IP 是免費的,所以使用得時間不固定,超出使用的時間范圍該地址將失效,在地址失效或者地址錯誤時,控制臺將顯示以下所示的例外資訊,
錯誤例外資訊為: HTTPSConnectionPool(host='www.baidu.com', port=443): Max retries
exceeded with url: /s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80
(Caused by ProxyError('Cannot connect to proxy.', NewConnectionError
('<urllib3.connection.HTTPSConnection object at 0x00000299451C7F08>: Failed to
establish a new connection: [WinError 10060] 由于連接方在一段時間后沒有正確答復或
連接的主機沒有反應,連接嘗試失敗,')))
2. 獲取免費的代理 IP
為了避免爬取目標網頁的后臺服務器,對我們實施封鎖 IP 的操作,我們可以每發送一次網路請求更換一個 IP,從而降低被發現的風險,其實在獲取免費的代理 IP 之前,需要先找到提供免費代理 IP 的網頁,然后通過爬蟲技術將大量的代理 IP 提取并保存至檔案當中,以某免費代理 IP 網頁為例,實作代碼如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:5.獲取免費的代理ip.py
@time:2020/11/12
"""
import requests # 匯入網路請求模塊
from lxml import etree # 匯入 HTML 決議模塊
import pandas as pd # 匯入pandas模塊
ip_list = [] # 創建保存IP地址的串列
# 頭部資訊
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
def get_ip(url, headers):
"""
用于獲取指定網站中的ip及埠
:param url: 抓取網站的鏈接
:param headers: 請求頭
:return: None
"""
response = requests.get(url=url, headers=headers)
response.encoding = "utf8" # 設定編碼方式
if response.status_code == 200: # 判斷請求是否成功
html = etree.HTML(response.text) # 決議HTML
# 獲取所有帶有IP的li標簽
li_list = html.xpath('//div[@class="container"]/div[2]/ul/li')[1:]
for li in li_list: # 遍歷每行內容
ip = li.xpath('./span[@class="f-address"]/text()')[0] # 獲取ip
port = li.xpath('./span[@class="f-port"]/text()')[0] # 獲取埠
ip_list.append(ip + ":" + port)
print(f"代理ip為: {ip}, 對應埠為: {port}")
if __name__ == '__main__':
ip_table = pd.DataFrame(columns=["ip"]) # 創建臨時表格
for i in range(1, 5):
# 構造免費代理IP的請求地址
url = "https://www.dieniao.com/FreeProxy/{}.html".format(i)
get_ip(url, headers)
ip_table["ip"] = ip_list # 將提取的ip保存至excel檔案中的ip列
# 生成xlsx檔案
ip_table.to_excel("ip.xlsx", sheet_name="data")
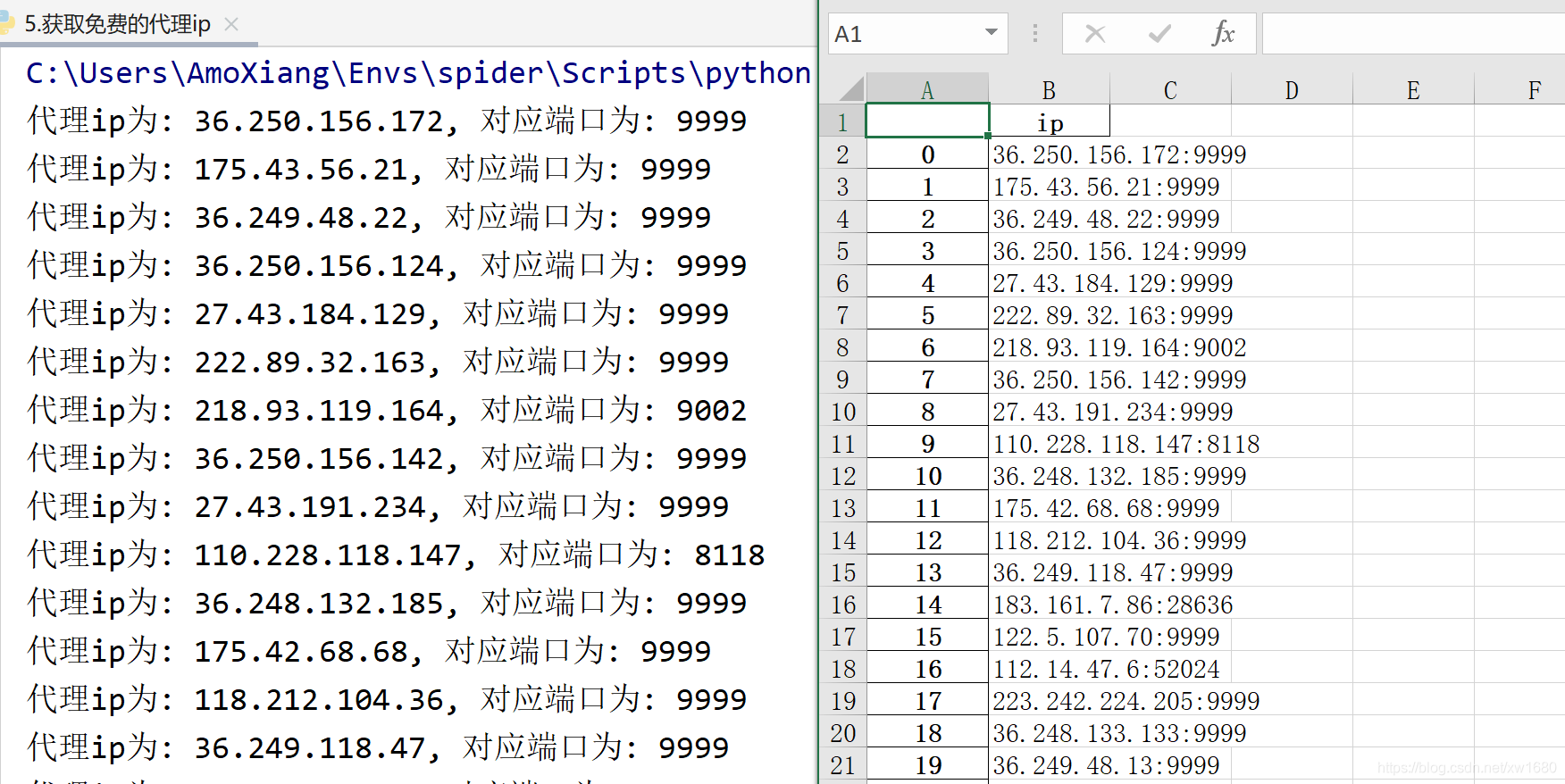
程式代碼運行后控制臺將顯示如下圖所示的代理 ip 與對應埠,專案檔案中將自動生成 ip.xlsx 檔案,檔案內容如下圖所示:
如果以上示例代碼運行出錯,讀者可以參考以上示例代碼的學習思路,然后爬取其他免費代理IP的網頁,博主這里提供幾個免費的代理 IP 網站:
- http://www.goubanjia.com/
- https://www.kuaidaili.com/free/
- http://www.ip3366.net/
- https://ip.jiangxianli.com/?page=1
- https://www.dieniao.com/FreeProxy/1.html
- http://http.zhiliandaili.cn/
3. 檢測代理 IP 是否有效
提供免費代理 IP 的網頁有很多,但是經過測驗會發現并不是所有的免費代理 IP 都是有效的,甚至更不是匿名IP(即獲取遠程訪問用戶的 IP 地址是代理服務器的 IP 地址,不是用戶本地真實的 IP 地址),所以要使用我們爬取下來的免費代理 IP,就需要對這個 IP 進行檢測,
實作檢測免費代理 IP 是否可用時,首先需要讀取保存免費代理 IP 的檔案,然后對代理 IP 進行遍歷并使用免費的代理 IP 發送網路請求,而請求地址可以使用查詢 IP 位置的網頁,如果網路請求成功說明免費的代理 IP 可以使用,并且還會回傳當前免費代理 IP 的匿名地址,代碼如下:
# -*- coding: UTF-8 -*-
"""
@author:AmoXiang
@file:6.檢測代理ip是否有效.py
@time:2020/11/12
"""
import requests # 匯入網路請求模塊
import pandas as pd # 匯入pandas模塊
from lxml import etree # 匯入HTML決議模塊
ip_table = pd.read_excel("ip.xlsx") # 讀取代理IP檔案內容
ip_list = ip_table["ip"] # 獲取代理IP資訊
# 頭部資訊
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
# 回圈遍歷代理IP并通過代理發送網路請求
for ip in ip_list:
# 這里添加了http和https兩個代理,這樣寫是因為有些網頁采用 http協議,有的則采用https協議,
# 為了在這兩類網頁上都能順利使用代理,所以一般都同時寫上,當然,如果確定了某網頁的請求型別,可以只寫一種
proxies = {'http': 'http://{ip}'.format(ip=ip),
'https': 'https://{ip}'.format(ip=ip)}
try:
response = requests.get("https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=ip%E5%9C%B0%E5%9D%80",
headers=headers, timeout=3, proxies=proxies)
if response.status_code == 200: # 判斷是否請求成功,請求成功說明代理IP可用
response.encoding = "utf8" # 進行編碼
html = etree.HTML(response.text) # 決議HTML
info = html.xpath('//*[@id="1"]/div[1]/div[1]/div[2]/table//tr/td//text()')[1:]
info = " ".join(info).replace("\xa0", "").strip().replace("本機IP:", "本機IP: ")
print(info) # 輸出當前IP匿名資訊
except Exception as e:
# print(e) # 列印例外資訊
pass
程式運行結果如下圖所示:

由于博主網路原因,故測驗出來的可用的 IP 地址較少,讀者可以根據自己查找的(IP查詢)請求地址進行更換測驗,免費的 IP 地址可用的較少,可以購買付費代理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236603.html
標籤:python
上一篇:連夜優化的一段代碼,請求指教