文章目錄
- 1. 概述
- 2. 資料
- 3. 模型
- 4. 訓練
- 5. 測驗
參考 基于深度學習的自然語言處理
本文使用attention機制的模型,將各種格式的日期轉化成標準格式的日期
1. 概述
- LSTM、GRU 減少了梯度消失的問題,但是對于復雜依賴結構的長句子,梯度消失仍然存在
- 注意力機制能同時看見句子中的每個位置,并賦予每個位置不同的權重(注意力),且可以并行計算
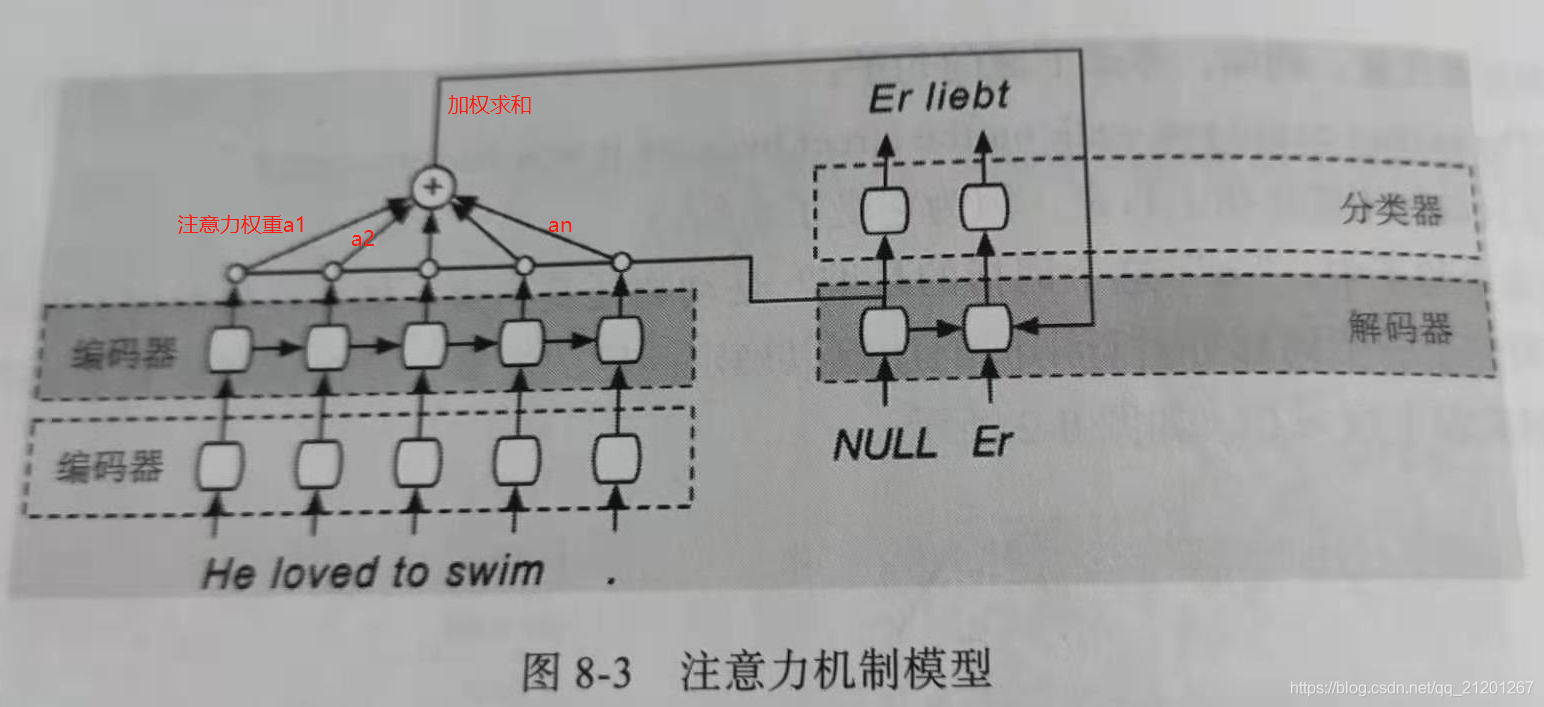
2. 資料
- 生成日期資料
from faker import Faker
from babel.dates import format_date
import random
fake = Faker()
fake.seed(123)
random.seed(321)
# 各種日期格式
FORMATS = ['short',
'medium',
'long',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'full',
'd MMM YYY',
'd MMMM YYY',
'dd MMM YYY',
'd MMM, YYY',
'd MMMM, YYY',
'dd, MMM YYY',
'd MM YY',
'd MMMM YYY',
'MMMM d YYY',
'MMMM d, YYY',
'dd.MM.YY']
- 生成日期資料:隨機格式(X),標準格式(Y)
def load_date():
# 加載一些日期資料
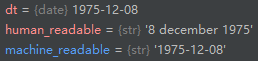
dt = fake.date_object() # 隨機一個日期
human_readable = format_date(dt, format=random.choice(FORMATS),
locale='en_US')
# 使用隨機選取的格式,生成日期
human_readable = human_readable.lower().replace(',','')
machine_readable = dt.isoformat() # 標準格式
return human_readable, machine_readable, dt
test_date = load_date()
輸出:
- 建立字典,以及映射關系(字符 :idx)
from tqdm import tqdm # 顯示進度條
def load_dateset(num_of_data):
human_vocab = set()
machine_vocab = set()
dataset = []
Tx = 30 # 日期最大長度
for i in tqdm(range(num_of_data)):
h, m, _ = load_date()
if h is not None:
dataset.append((h, m))
human_vocab.update(tuple(h))
machine_vocab.update(tuple(m))
human = dict(zip(sorted(human_vocab)+['<unk>', '<pad>'],
list(range(len(human_vocab)+2))))
# x 字符:idx 的映射
inv_machine = dict(enumerate(sorted(machine_vocab)))
# idx : y 字符
machine = {v : k for k, v in inv_machine.items()}
# y 字符 : idx
return dataset, human, machine, inv_machine
m = 10000 # 樣本個數
dataset, human_vocab, machine_vocab, inv_machine_vocab = load_dateset(m)
- 日期(char序列)轉 ids 序列,并且 pad / 截斷
import numpy as np
from keras.utils import to_categorical
def string_to_int(string, length, vocab):
string = string.lower().replace(',','')
if len(string) > length: # 長了,截斷
string = string[:length]
rep = list(map(lambda x : vocab.get(x, '<unk>'), string))
# 對string里每個char 使用 匿名函式 獲取映射的id,沒有的話,使用unk的id,map回傳迭代器,轉成list
if len(string) < length:
rep += [vocab['<pad>']]*(length-len(string))
# 長度不夠,加上 pad 的 id
return rep # 回傳 [ids,...]
- 根據 ids 序列生成 one_hot 矩陣
def process_data(dataset, human_vocab, machine_vocab, Tx, Ty):
X,Y = zip(*dataset)
print("處理前 X:{}".format(X))
print("處理前 Y:{}".format(Y))
X = np.array([string_to_int(date, Tx, human_vocab) for date in X])
Y = [string_to_int(date, Ty, machine_vocab) for date in Y]
print("處理后 X的shape:{}".format(X.shape))
print("處理后 Y: {}".format(Y))
Xoh = np.array(list(map(lambda x : to_categorical(x, num_classes=len(human_vocab)), X)))
Yoh = np.array(list(map(lambda x : to_categorical(x, num_classes=len(machine_vocab)), Y)))
return X, np.array(Y), Xoh, Yoh
Tx = 30 # 輸入長度
Ty = 10 # 輸出長度
X, Y, Xoh, Yoh = process_data(dataset, human_vocab, machine_vocab, Tx, Ty)

檢查生成的 one_hot 編碼矩陣維度
print(X.shape)
print(Y.shape)
print(Xoh.shape)
print(Yoh.shape)
輸出:
(10000, 30)
(10000, 10)
(10000, 30, 37)
(10000, 10, 11)
3. 模型
- softmax 激活函式,求注意力權重
from keras import backend as K
def softmax(x, axis=1):
ndim = K.ndim(x)
if ndim == 2:
return K.softmax(x)
elif ndim > 2:
e = K.exp(x - K.max(x, axis=axis, keepdims=True))
s = K.sum(e, axis=axis, keepdims=True)
return e/s
else:
raise ValueError('維度不對,不能是1維')
- 模型組件
from keras.layers import RepeatVector, LSTM, Concatenate, \
Dense, Activation, Dot, Input, Bidirectional
repeator = RepeatVector(Tx) # 重復 Tx 次
# 重復器
# Input shape:
# 2D tensor of shape `(num_samples, features)`.
#
# Output shape:
# 3D tensor of shape `(num_samples, n, features)`.
concator = Concatenate(axis=-1) # 拼接器
densor1 = Dense(10, activation='tanh') # FC
densor2 = Dense(1, activation='relu') # FC
activator = Activation(softmax, name='attention_weights') # 計算注意力權重
dotor = Dot(axes=1) # 加權
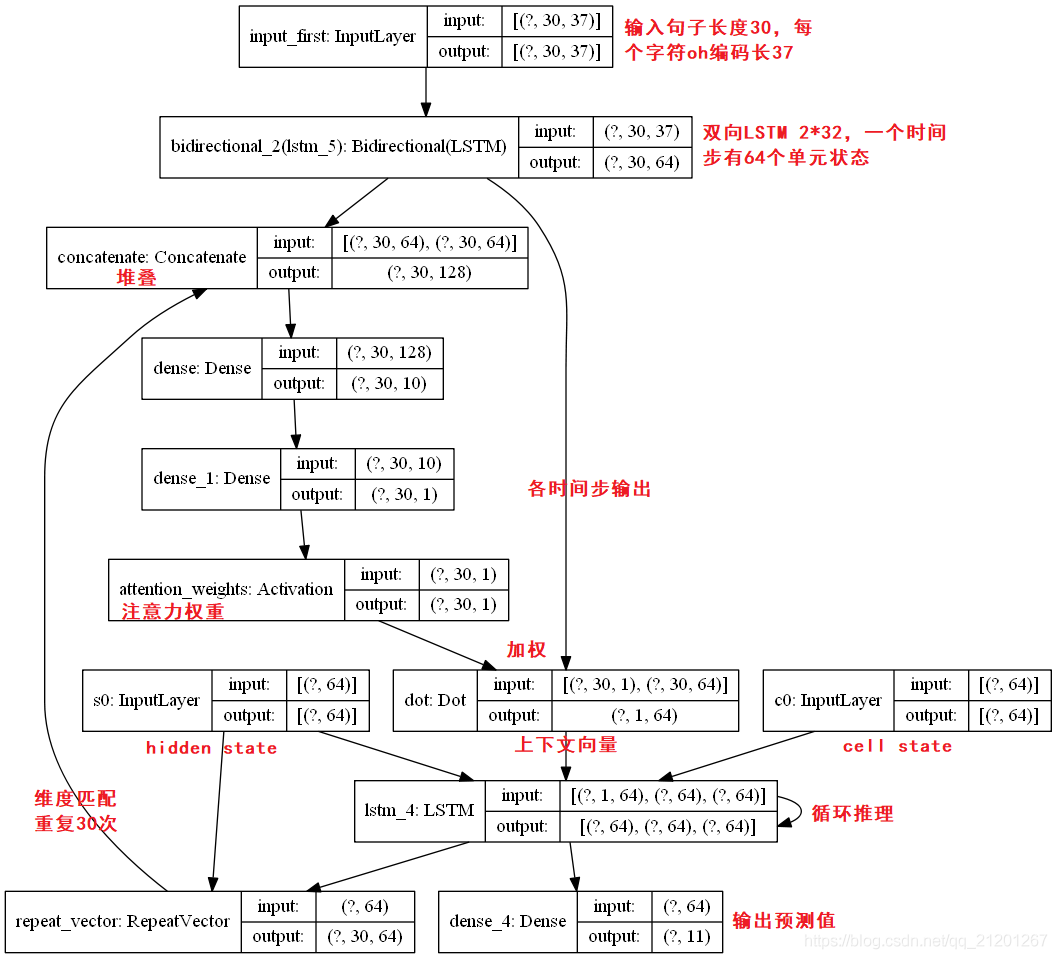
- 模型
def one_step_attention(h, s_prev):
s_prev = repeator(s_prev) # 將前一個輸出狀態重復 Tx 次
concat = concator([h, s_prev]) # 與 全部句子狀態 拼接
e = densor1(concat) # 經過 FC
energies = densor2(e) # 經過FC
alphas = activator(energies) # 得到注意力權重
context = dotor([alphas, h]) # 跟原句子狀態做attention
return context # 得到背景關系向量,后序輸入到解碼器
# 解碼器,是一個單向LSTM
n_h = 32
n_s = 64
post_activation_LSTM_cell = LSTM(n_s, return_state=True) # 單向LSTM
output_layer = Dense(len(machine_vocab), activation=softmax) # FC 輸出預測值
from keras.models import Model
def model(Tx, Ty, n_h, n_s, human_vocab_size, machine_vocab_size):
X = Input(shape=(Tx,human_vocab_size), name='input_first')
s0 = Input(shape=(n_s,),name='s0')
c0 = Input(shape=(n_s,),name='c0')
s = s0
c = c0
outputs = []
h = Bidirectional(LSTM(n_h, return_sequences=True))(X) # 編碼器得到整個序列的狀態
for t in range(Ty): # 解碼器 推理
context = one_step_attention(h, s) # attention 得到背景關系向量
s, _, c = post_activation_LSTM_cell(context, initial_state=[s,c])
out = output_layer(s) # FC 輸出預測
outputs.append(out)
model = Model(inputs=[X,s0,c0], outputs=outputs)
return model
model = model(Tx,Ty,n_h,n_s,len(human_vocab), len(machine_vocab))
model.summary()
from keras.utils import plot_model
plot_model(model, to_file='model.png',show_shapes=True,rankdir='TB')
輸出:
Model: "functional_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_first (InputLayer) [(None, 30, 37)] 0
__________________________________________________________________________________________________
s0 (InputLayer) [(None, 64)] 0
__________________________________________________________________________________________________
bidirectional (Bidirectional) (None, 30, 64) 17920 input_first[0][0]
__________________________________________________________________________________________________
repeat_vector (RepeatVector) (None, 30, 64) 0 s0[0][0]
lstm[0][0]
lstm[1][0]
lstm[2][0]
lstm[3][0]
lstm[4][0]
lstm[5][0]
lstm[6][0]
lstm[7][0]
lstm[8][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 30, 128) 0 bidirectional[0][0]
repeat_vector[0][0]
bidirectional[0][0]
repeat_vector[1][0]
bidirectional[0][0]
repeat_vector[2][0]
bidirectional[0][0]
repeat_vector[3][0]
bidirectional[0][0]
repeat_vector[4][0]
bidirectional[0][0]
repeat_vector[5][0]
bidirectional[0][0]
repeat_vector[6][0]
bidirectional[0][0]
repeat_vector[7][0]
bidirectional[0][0]
repeat_vector[8][0]
bidirectional[0][0]
repeat_vector[9][0]
__________________________________________________________________________________________________
dense (Dense) (None, 30, 10) 1290 concatenate[0][0]
concatenate[1][0]
concatenate[2][0]
concatenate[3][0]
concatenate[4][0]
concatenate[5][0]
concatenate[6][0]
concatenate[7][0]
concatenate[8][0]
concatenate[9][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 30, 1) 11 dense[0][0]
dense[1][0]
dense[2][0]
dense[3][0]
dense[4][0]
dense[5][0]
dense[6][0]
dense[7][0]
dense[8][0]
dense[9][0]
__________________________________________________________________________________________________
attention_weights (Activation) (None, 30, 1) 0 dense_1[0][0]
dense_1[1][0]
dense_1[2][0]
dense_1[3][0]
dense_1[4][0]
dense_1[5][0]
dense_1[6][0]
dense_1[7][0]
dense_1[8][0]
dense_1[9][0]
__________________________________________________________________________________________________
dot (Dot) (None, 1, 64) 0 attention_weights[0][0]
bidirectional[0][0]
attention_weights[1][0]
bidirectional[0][0]
attention_weights[2][0]
bidirectional[0][0]
attention_weights[3][0]
bidirectional[0][0]
attention_weights[4][0]
bidirectional[0][0]
attention_weights[5][0]
bidirectional[0][0]
attention_weights[6][0]
bidirectional[0][0]
attention_weights[7][0]
bidirectional[0][0]
attention_weights[8][0]
bidirectional[0][0]
attention_weights[9][0]
bidirectional[0][0]
__________________________________________________________________________________________________
c0 (InputLayer) [(None, 64)] 0
__________________________________________________________________________________________________
lstm (LSTM) [(None, 64), (None, 33024 dot[0][0]
s0[0][0]
c0[0][0]
dot[1][0]
lstm[0][0]
lstm[0][2]
dot[2][0]
lstm[1][0]
lstm[1][2]
dot[3][0]
lstm[2][0]
lstm[2][2]
dot[4][0]
lstm[3][0]
lstm[3][2]
dot[5][0]
lstm[4][0]
lstm[4][2]
dot[6][0]
lstm[5][0]
lstm[5][2]
dot[7][0]
lstm[6][0]
lstm[6][2]
dot[8][0]
lstm[7][0]
lstm[7][2]
dot[9][0]
lstm[8][0]
lstm[8][2]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 11) 715 lstm[0][0]
lstm[1][0]
lstm[2][0]
lstm[3][0]
lstm[4][0]
lstm[5][0]
lstm[6][0]
lstm[7][0]
lstm[8][0]
lstm[9][0]
==================================================================================================
Total params: 52,960
Trainable params: 52,960
Non-trainable params: 0
________________________________________________________________________________________________
4. 訓練
from keras.optimizers import Adam
# 優化器
opt = Adam(learning_rate=0.005, decay=0.01)
# 配置模型
model.compile(optimizer=opt, loss='categorical_crossentropy',
metrics=['accuracy'])
# 初始化 解碼器狀態
s0 = np.zeros((m, n_s))
c0 = np.zeros((m, n_s))
outputs = list(Yoh.swapaxes(0, 1))
# Yoh shape 10000*10*11,調換0,1軸,為10*10000*11
# outputs list,長度 10, 每個里面是array 10000*11
history = model.fit([Xoh, s0, c0], outputs,
epochs=10, batch_size=128,
validation_split=0.1)
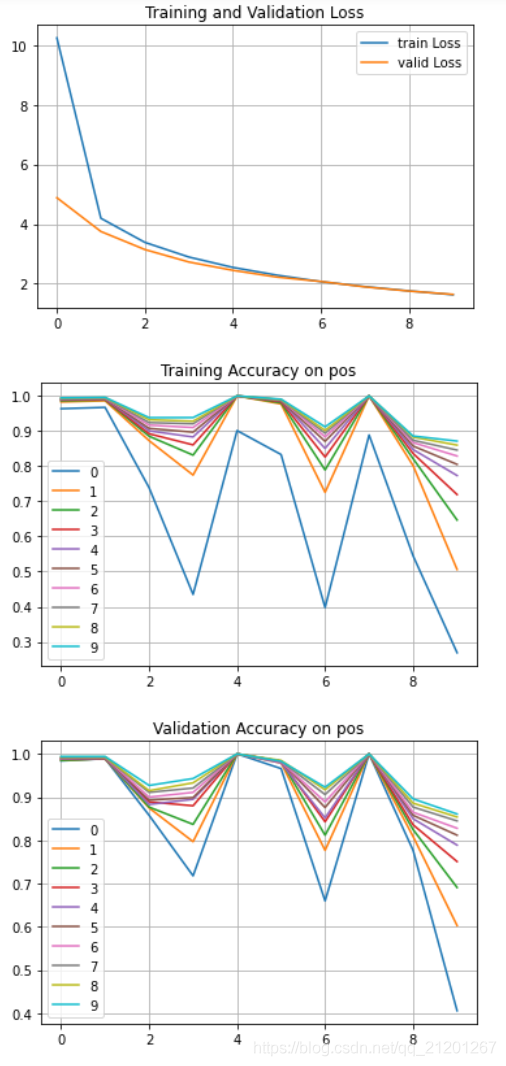
- 繪制 loss 和 各位置的準確率
from matplotlib import pyplot as plt
import pandas as pd
his = pd.DataFrame(history.history)
print(his.columns)
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='train Loss')
plt.plot(val_loss, label='valid Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid()
plt.show()
# 列 具體的名字根據運行次數,會有變化
col_train_acc = (
'dense_7_accuracy', 'dense_7_1_accuracy', 'dense_7_2_accuracy',
'dense_7_3_accuracy', 'dense_7_4_accuracy', 'dense_7_5_accuracy',
'dense_7_6_accuracy', 'dense_7_7_accuracy', 'dense_7_8_accuracy',
'dense_7_9_accuracy')
col_test_acc = (
'val_dense_7_accuracy', 'val_dense_7_1_accuracy',
'val_dense_7_2_accuracy', 'val_dense_7_3_accuracy',
'val_dense_7_4_accuracy', 'val_dense_7_5_accuracy',
'val_dense_7_6_accuracy', 'val_dense_7_7_accuracy',
'val_dense_7_8_accuracy', 'val_dense_7_9_accuracy')
train_acc = pd.DataFrame(history.history[c] for c in col_train_acc)
test_acc = pd.DataFrame(history.history[c] for c in col_test_acc)
train_acc.plot()
plt.title('Training Accuracy on pos')
plt.legend()
plt.grid()
plt.show()
test_acc.plot()
plt.title('Validation Accuracy on pos')
plt.legend()
plt.grid()
plt.show()
5. 測驗
s0 = np.zeros((1, n_s))
c0 = np.zeros((1, n_s))
test_data,_,_,_ = load_dateset(10)
for x,y in test_data:
print(x + " ==> " +y)
for x,_ in test_data:
source = string_to_int(x, Tx, human_vocab)
source = np.array(list(map(lambda a : to_categorical(a, num_classes=len(human_vocab)), source)))
source = source[np.newaxis, :]
pred = model.predict([source, s0, c0])
pred = np.argmax(pred, axis=-1)
output = [inv_machine_vocab[int(i)] for i in pred]
print('source:',x)
print('output:',''.join(output))
輸出:
18 april 2014 ==> 2014-04-18
saturday august 22 1998 ==> 1998-08-22
october 22 1995 ==> 1995-10-22
thursday february 29 1996 ==> 1996-02-29
wednesday october 17 1979 ==> 1979-10-17
7 12 73 ==> 1973-12-07
9/30/01 ==> 2001-09-30
22 may 2001 ==> 2001-05-22
7 march 1979 ==> 1979-03-07
19 feb 2013 ==> 2013-02-19
預測10個,錯誤了4個,日期字符不完全正確
source: 18 april 2014
output: 2014-04-18
source: saturday august 22 1998
output: 1998-08-22
source: october 22 1995
output: 1995-12-22 # 錯誤 10 月
source: thursday february 29 1996
output: 1996-02-29
source: wednesday october 17 1979
output: 1979-10-17
source: 7 12 73
output: 1973-02-07 # 錯誤 12月
source: 9/30/01
output: 2001-05-00 # 錯誤 09-30
source: 22 may 2001
output: 2011-05-22 # 錯誤 2001
source: 7 march 1979
output: 1979-03-07
source: 19 feb 2013
output: 2013-02-19
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236688.html
標籤:python
上一篇:使用VUE+SpringBoot+EasyExcel 整合匯入匯出demo
下一篇:萌新求解