說明
本篇文章是轉載自周志明老師的文章,鏈接地址:https://www.infoq.cn/article/RQfWw2R2ZpYQiOlc1WBE
今天,25 歲的 Java 仍然是最具有統治力的編程語言,長期占據編程語言排行榜的首位,擁有一千二百萬的龐大開發者群體,全世界有四百五十億部物理設備使用著 Java 技術,同時,在云端資料中心的虛擬化環境里,還運行著超過兩百五十億個 Java 虛擬機的行程實體 (資料來自Oracle的WebCast),
以上這些資料是 Java 過去 25 年巨大成就的功勛佐證,更是 Java 技術體系維持自己“天下第一”編程語言的堅實壁壘,Java 與其他語言競爭,底氣從來不在于語法、類別庫有多么先進好用,而是來自它龐大的用戶群和極其成熟的軟體生態,這在朝夕之間難以撼動, 然而,這個現在看起來仍然堅不可摧的 Java 帝國,其統治地位的穩固程度不僅沒有高枕無憂,反而說是危機四伏也不為過,目前已經有了可預見的、足以威脅動搖其根基的潛在可能性正在醞釀,并隨云原生時代而降臨,
Java 的危機
Java 與云原生的矛盾,來源于 Java 誕生之初,植入到它基因之中的一些基本的前提假設已經逐漸開始被動搖,甚至已經不再成立,
我舉個例子,每一位 Java 的使用者都聽說過“一次撰寫,到處運行”(Write Once, Run Anywhere)這句口號,20 多年前,Java 成熟之前,開發者如果希望程式在 Linux、Solaris、Windows 等不同平臺,在 x86、AMD64、SPARC、MIPS、ARM 等不同指令集架構上都能正常運行,就必須針對每種組合,編譯出對應的二進制發行包,或者索性直接分發源代碼,由使用者在自己的平臺上編譯,
面對這個問題,Java 通過語言層虛擬化的方式,令每一個 Java 應用都自動取得平臺無關(Platform Independent)、架構中立(Architecture Neutral)的先天優勢,讓同一套程式格式得以在不同指令集架構、不同作業系統環境下都能運行且得到一致的結果,不僅方便了程式的分發,還避免了各種平臺下記憶體模型、執行緒模型、位元組序等底層細節差異對程式撰寫的干擾,在當年,Java 的這種設計帶有令人趨之若鶩的強大吸引力,直接開啟了托管語言(Managed Language,如 Java、.NET)的一段興盛期,
面對相同的問題,今天的云原生選擇以作業系統層虛擬化的方式,通過容器實作的不可變基礎設施去解決,不可變基礎設施這個概念出現得比云原生要早,原本是指該如何避免由于運維人員對服務器運行環境所做的持續的變更而導致的意想不到的副作用,但在云原生時代,它的內涵已不再局限于方便運維、程式升級和部署的手段,而是升華一種為向應用代碼隱藏環境復雜性的手段,是分布式服務得以成為一種可普遍推廣的普適架構風格的必要前提,
將程式連同它的運行環境一起封裝到穩定的鏡像里,現已是一種主流的應用程式分發方式,Docker 同樣提出過“一次構建,到處運行”(Build Once, Run Anywhere)的口號,盡管它只能提供環境兼容性和有局限的平臺無關性(指系統內核功能以上的 ABI 兼容),且完全不可能支撐架構中立性,所以將“一次構建,到處運行”與“一次撰寫,到處運行”對立起來并不嚴謹恰當,但是無可否認,今天 Java 技術“一次編譯,到處運行”的優勢,已經被容器大幅度地削弱,不再是大多數服務端開發者技術選型的主要考慮因素了,
如果僅僅是優勢的削弱,并不足以成為 Java 的直接威脅,充其量只是一個潛在的不利因素,但更加迫在眉睫的風險來自于那些與技術潮流直接沖突的假設,譬如,Java 總體上是面向大規模、長時間的服務端應用而設計的,嚴(luō)謹(suō)的語法利于約束所有人寫出較一致的代碼;靜態型別動態鏈接的語言結構,利于多人協作開發,讓軟體觸及更大規模;即時編譯器、性能制導優化、垃圾收集子系統等 Java 最具代表性的技術特征,都是為了便于長時間運行的程式能享受到硬體規模發展的紅利,
另一方面,在微服務的背景下,提倡服務圍繞業務能力而非技術來構建應用,不再追求實作上的一致,一個系統由不同語言,不同技術框架所實作的服務來組成是完全合理的;服務化拆分后,很可能單個微服務不再需要再面對數十、數百 GB 乃至 TB 的記憶體;有了高可用的服務集群,也無須追求單個服務要 7×24 小時不可間斷地運行,它們隨時可以中斷和更新,
同時,微服務又對應用的容器化親和性,譬如鏡像體積、記憶體消耗、啟動速度,以及達到最高性能的時間等方面提出了新的要求,這兩年的網紅概念 Serverless 也進一步增加這些因素的考慮權重,而這些卻正好都是 Java 的弱項:哪怕再小的 Java 程式也要帶著完整的虛擬機和標準類別庫,使得鏡像拉取和容器創建效率降低,進而使整個容器生命周期拉長,基于 Java 虛擬機的執行機制,使得任何 Java 的程式都會有固定的基礎記憶體開銷,以及固定的啟動時間,而且 Java 生態中廣泛采用的依賴注入進一步將啟動時間拉長,使得容器的冷啟動時間很難縮短,
軟體工業中已經出現過不止一起因 Java 這些弱點而導致失敗的案例,如 JRuby 撰寫的Logstash,原本是同時承擔部署在節點上的收集端(Shipper)和專門轉換處理的服務端(Master)的職責,后來因為資源占用的原因,被Elstaic.co用 Golang 的Filebeat代替了 Shipper 部分的職能;又如 Scala 語言撰寫的邊車代理Linkerd,作為服務網格概念的提出者,卻最終被Envoy所取代,其主要弱點之一也是由于 Java 虛擬機的資源消耗所帶來的劣勢,
雖然在云原生時代依然有很多適合 Java 發揮的領域,但是具備彈性與韌性、隨時可以中斷重啟的微型服務的確已經形成了一股潮流,在逐步蠶食大型系統的領地,正是由于潮流趨勢的改變,新一代的語言與技術尤其重視輕量化和快速回應能力,大多又重新回歸到了原生語言(Native Language,如 Golang、Rust)之上,
Java 的變革
面對挑戰,Java 的開發者和社區都沒有退縮,它們在各自的領域給出了很多優秀的解決方案,涌現了如Quarkus、Micronaut、Helidon等一大批以提升 Java 在云原生環境下的適應性為賣點的框架,
不過,今天我們的主題將聚焦在由 Java 官方本身所推進的專案上,在圍繞 Java 25 周年的研討和布道活動中,官方的設定是以“面向未來的變革”(Innovating for the Future)為基調,你有可能在此之前已經聽說過其中某個(某些)專案的名字和改進點,但這里我們不僅關心這些專案改進的是什么,還更關心它們背后的動機與困難、帶來的收益,以及要付出的代價,

Project Leyden
對于原生語言的挑戰,最有力最徹底的反擊手段無疑是將位元組碼直接編譯成可以脫離 Java 虛擬機的原生代碼,如果真的能夠生成脫離 Java 虛擬機運行的原生程式,將意味著啟動時間長的問題能夠徹底解決,因為此時已經不存在初始化虛擬機和類加載的程序;也意味著程式馬上就能達到最佳的性能,因為此時已經不存在即時編譯器運行時編譯,所有代碼都是在編譯期編譯和優化好的(如下圖所示);沒有了 Java 虛擬機、即時編譯器這些額外的部件,也就意味著能夠省去它們原本消耗的那部分記憶體資源與鏡像體積,
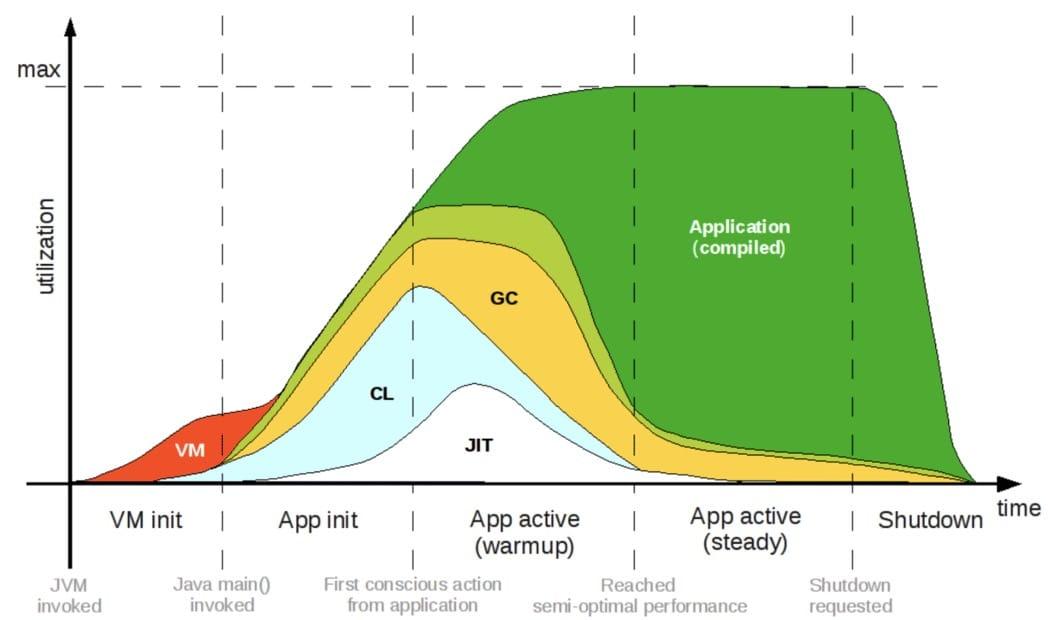
但同時,這也是風險系數最高、實作難度最大的方案,
Java 并非沒有嘗試走過這條路,從 Java 2 之前的GCJ(GNU Compiler for Java),到后來的Excelsior JET,再到 2018 年 Oracle Labs 啟動的GraalVM中的SubstrateVM模塊,最后到 2020 年中期剛建立的Leyden專案,都在朝著提前編譯(Ahead-of-Time Compilation,AOT)生成原生程式這個目標邁進,
Java 支持提前編譯最大的困難在于它是一門動態鏈接的語言,它假設程式的代碼空間是開放的(Open World),允許在程式的任何時候通過類加載器去加載新的類,作為程式的一部分運行,要進行提前編譯,就必須放棄這部分動態性,假設程式的代碼空間是封閉的(Closed World),所有要運行的代碼都必須在編譯期全部可知,這一點不僅僅影響到了類加載器的正常運作,除了無法再動態加載外,反射(通過反射可以呼叫在編譯期不可知的方法)、動態代理、位元組碼生成庫(如 CGLib)等一切會運行時產生新代碼的功能都不再可用,如果將這些基礎能力直接抽離掉,Helloworld 還是能跑起來,但 Spring 肯定跑不起來,Hibernate 也跑不起來,大部分的生產力工具都跑不起來,整個 Java 生態中絕大多數上層建筑都會轟然崩塌,
要獲得有實用價值的提前編譯能力,只有依靠提前編譯器、組件類別庫和開發者三方一起協同才可能辦到,由于 Leyden 剛剛開始,幾乎沒有公開的資料,所以下面我是以 SubstrateVM 為目標物件進行的介紹:
- 有一些功能,像反射這樣的基礎特性是不可能妥協的,折衷的解決辦法是由用戶在編譯期,以組態檔或者編譯器引數的形式,明確告知編譯器程式代碼中有哪些方法是只通過反射來訪問的,編譯器將方法的添加到靜態編譯的范疇之中,同理,所有使用到動態代理的地方,也必須在事先列明,在編譯期就將動態代理的位元組碼全部生成出來,其他所有無法通程序式指標分析(Points-To Analysis)得到的資訊,譬如程式中用到的資源、組態檔等等,也必須照此處理,
- 另一些功能,如動態生成位元組碼也十分常用,但用戶自己往往無法得知那些動態位元組碼的具體資訊,就只能由用到CGLib、javassist等庫的程式去妥協放棄,在Java世界中也許最典型的場景就是Spring用CGLib來進行類增強,默認情況下,每一個Spring管理的Bean都要用到CGLib,從Spring Framework 5.2開始增加了@proxyBeanMethods注解來排除對CGLib的依賴,僅使用標準的動態代理去增強類,
2019 年起,Pivotal 的 Spring 團隊與 Oracle Labs 的 GraalVM 團隊共同范訓了 Spring GraalVM Native 專案,這個目前仍處于 Experimental / Alpha 狀態的專案,能夠讓程序先以傳統方式運行(啟動)一次,自動化地找出程式中的反射、動態代理的代碼,代替用戶向編譯器提供絕大部分所需的資訊,并能將允許啟動時初始化的 Bean 在編譯期就完成初始化,直接繞過 Spring 程式啟動最慢的階段,這樣從啟動到程式可以提供服務,耗時竟能夠低于 0.1 秒,
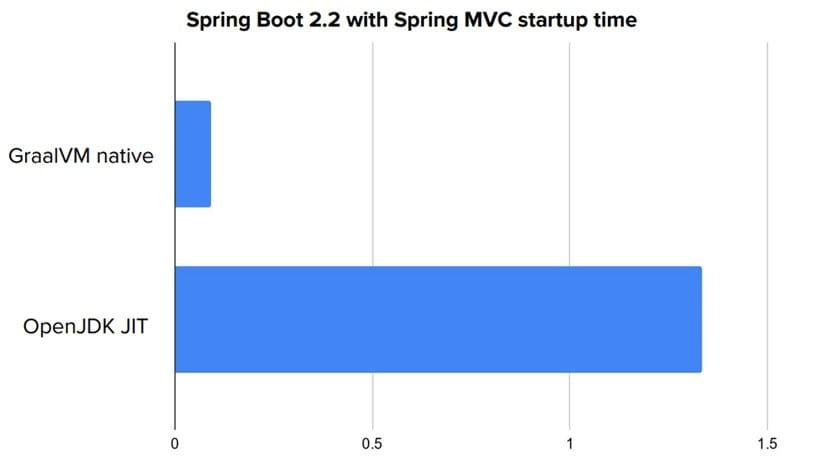
以原生方式運行后,縮短啟動時間的效果立竿見影,一般會有數十倍甚至更高的改善,程式容量和記憶體消耗也有一定程度的下降,不過至少目前而言,程式的運行效率還是要弱于傳統基于 Java 虛擬機的方式,雖然即時編譯器有編譯時間的壓力,但由于可以進行基于假設的激進優化和運行時性能度量的制導優化,使得即時編譯器的效果仍要優于提前編譯器,這方面需要 GraalVM 編譯器團隊的進一步努力,也需要從語言改進上入手,讓 Java 變得更適合被編譯器優化,
Project Valhalla
Java 語言上可感知的語法變化,多數來自于Amber專案,它的專案目標是持續優化語言生產力,近期(JDK 15、16)會有很多來自這個專案的特性,如 Records、Sealed Class、Pattern Matching、Raw String Literals 等實裝到生產環境,
然而語法不僅與編碼效率相關,與運行效率也有很大關系,“程式=代碼+資料”這個提法至少在衡量運行效率上是合適的,無論是托管語言還是原生語言,最終產物都是處理器執行的指令流和記憶體存盤的資料結構,Java、.NET、C、C++、Golang、Rust 等各種語言誰更快,取決于特定場景下,編譯器生成指令流的優化效果,以及資料在記憶體中的結構布局,
Java 即時編譯器的優化效果拔群,但是由于 Java“一切皆為物件”的前提假設,導致在處理一系列不同型別的小物件時,記憶體訪問性能非常拉垮,這點是 Java 在游戲、圖形處理等領域一直難有建樹的重要制約因素,也是 Java 建立Valhalla專案的目標初衷,
這里舉個例子來說明此問題,如果我想描述空間里面若干條線段的集合,在 Java 中定義的代碼會是這樣的:
public record Point(float x, float y, float z) {}
public record Line(Point start, Point end) {}
Line[] lines;
面向物件的記憶體布局中,物件識別符號(Object Identity)存在的目的是為了允許在不暴露物件結構的前提下,依然可以參考其屬性與行為,這是面向物件編程中多型性的基礎,在 Java 中堆記憶體分配和回收、空值判斷、參考比較、同步鎖等一系列功能都會涉及到物件識別符號,記憶體訪問也是依靠物件識別符號來進行鏈式處理的,譬如上面代碼中的“若干條線段的集合”,在堆記憶體中將構成如下圖的參考關系:
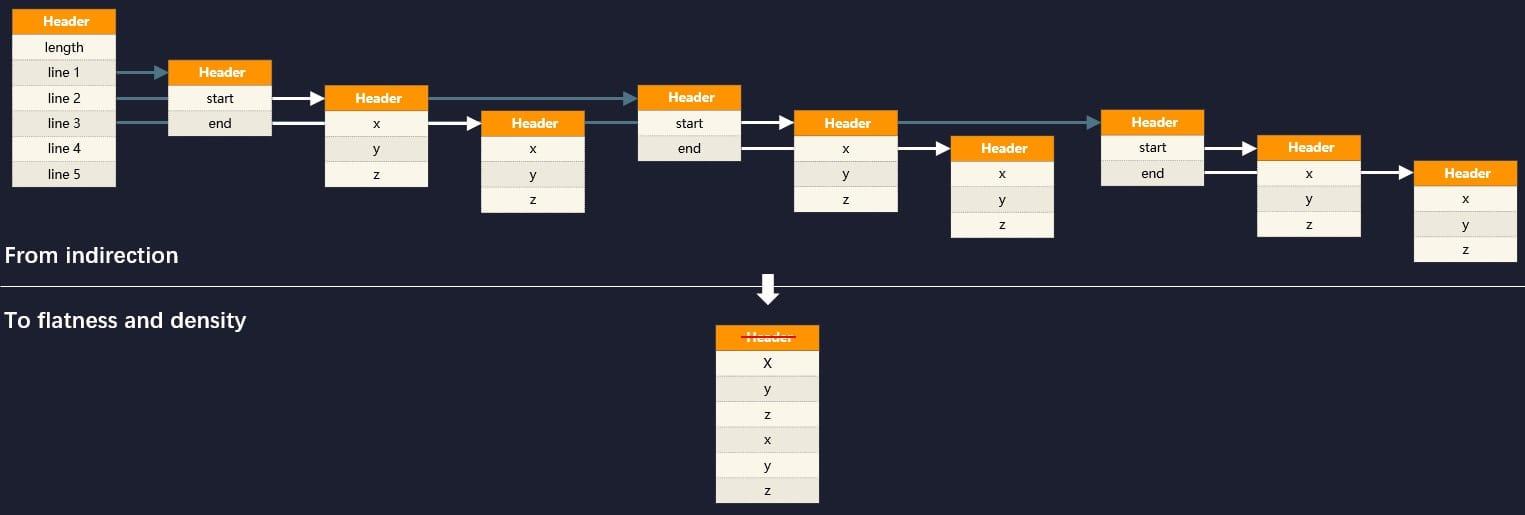
計算機硬體經過 25 年的發展,記憶體與處理器雖然都在進步,但是記憶體延遲與處理器執行性能之間的馮諾依曼瓶頸(Von Neumann Bottleneck)不僅沒有縮減,反而還在持續加大,“RAM Is the New Disk”已經從嘲諷梗逐漸成為了現實,
一次記憶體訪問(將主記憶體資料調入處理器 Cache)大約需要耗費數百個時鐘周期,而大部分簡單指令的執行只需要一個時鐘周期而已,因此,在程式執行性能這個問題上,如果編譯器能減少一次記憶體訪問,可能比優化掉幾十、幾百條其他指令都來得更有效果,
額外知識:馮諾依曼瓶頸
不同處理器(現代處理器都集成了記憶體管理器,以前是在北橋芯片中)的記憶體延遲大概是40-80納秒(ns,十億分之一秒),而根據不同的時鐘頻率,一個時鐘周期大概在0.2-0.4納秒之間,如此短暫的時間內,即使真空中傳播的光,也僅僅能夠行進10厘米左右,
資料存盤與處理器執行的速度矛盾是馮諾依曼架構的主要局限性之一,1977年的圖靈獎得主John Backus提出了“馮諾依曼瓶頸”這個概念,專門用來描述這種局限性,
編譯器的確在努力減少記憶體訪問,從 JDK 6 起,HotSpot 的即時編譯器就嘗試通過逃逸分析來做標量替換(Scalar Replacement)和堆疊上分配(Stack Allocations)優化,基本原理是如果能通過分析,得知一個物件不會傳遞到方法之外,那就不需要真實地在對中創建完整的物件布局,完全可以繞過物件識別符號,將它拆散為基本的原生資料型別來創建,甚至是直接在堆疊記憶體中分配空間(HotSpot 并沒有這樣做),方法執行完畢后隨著堆疊幀一起銷毀掉,
不過,逃逸分析是一種程序間優化(Interprocedural Optimization),非常耗時,也很難處理那些理論有可能但實際不存在的情況,相同的問題在 C、C++中卻并不存在,上面場景中,程式員只要將 Point 和 Line 都定義為 struct 即可,C#中也有 struct,是依靠.NET 的值型別(Value Type)來實作的,Valhalla 專案的核心改進就是提供類似的值型別支持,提供一個新的關鍵字(inline),讓用戶可以在不需要向方法外部暴露物件、不需要多型性支持、不需要將物件用作同步鎖的場合中,將類標識為值型別,此時編譯器就能夠繞過物件識別符號,以平坦的、緊湊的方式去為物件分配記憶體,
有了值型別的支持后,現在 Java 泛型中令人詬病的不支持原資料型別(Primitive Type)、頻繁裝箱問題也就隨之迎刃而解,現在 Java 的包裝類,理所當然地會以代表原生型別的值型別來重新定義,這樣 Java 泛型的性能會得到明顯的提升,因為此時 Integer 與 int 的訪問,在機器層面看完全可以達到一致的效率,
Project Loom
Java 語言抽象出來隱藏了各種作業系統執行緒差異性的統一執行緒介面,這曾經是它區別于其他編程語言(C/C++表示有被冒犯到)的一大優勢,不過,統一的執行緒模型不見得永遠都是正確的,
Java 目前主流的執行緒模型是直接映射到作業系統內核上的1:1模型,這對于計算密集型任務這很合適,既不用自己去做調度,也利于一條執行緒跑滿整個處理器核心,但對于 I/O 密集型任務,譬如訪問磁盤、訪問資料庫占主要時間的任務,這種模型就顯得成本高昂,主要在于記憶體消耗和背景關系切換上:64 位 Linux 上 HotSpot 的執行緒堆疊容量默認是 1MB,執行緒的內核元資料(Kernel Metadata)還要額外消耗 2-16KB 記憶體,所以單個虛擬機的最大執行緒數量一般只會設定到 200 至 400 條,當程式員把數以百萬計的請求往執行緒池里面灌時,系統即便能處理得過來,其中的切換損耗也相當可觀,
Loom 專案的目標是讓 Java 支持額外的N:M執行緒模型,請注意是“額外支持”,而不是像當年從綠色執行緒過渡到內核執行緒那樣的直接替換,也不是像 Solaris 平臺的 HotSpot 虛擬機那樣通過引數讓用戶二選其一,
Loom 專案新增加一種“虛擬執行緒”(Virtual Thread,以前以 Fiber 為名進行宣傳過,但因為要頻繁解釋啥是 Fiber 所以現在放棄了),本質上它是一種有堆疊協程(Stackful Coroutine),多條虛擬執行緒可以映射到同一條物理執行緒之中,在用戶空間中自行調度,每條虛擬執行緒的堆疊容量也可由用戶自行決定,
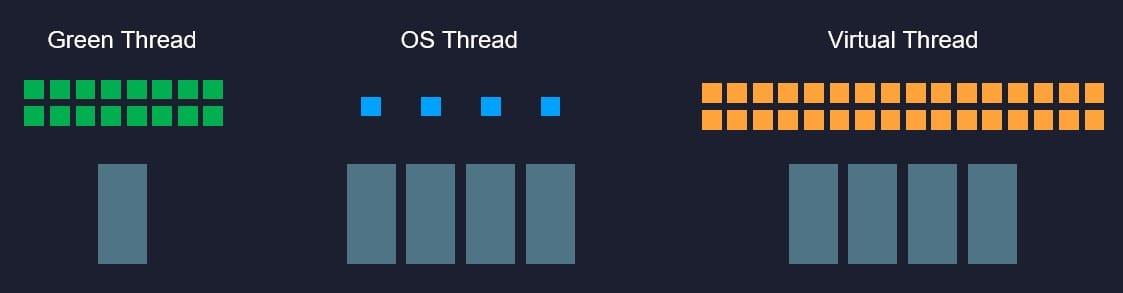
同時,Loom 專案的另一個目標是要盡最大可能保持原有統一執行緒模型的互動方式,通俗地說就是原有的 Thread、J.U.C、NIO、Executor、Future、ForkJoinPool 等這些多執行緒工具都應該能以同樣的方式支持新的虛擬執行緒,原來多執行緒中你理解的概念、編碼習慣大多數都能夠繼續沿用,
為此,虛擬執行緒將會與物理執行緒一樣使用java.lang.Thread來進行抽象,只是在創建執行緒時用到的引數或者方法稍有不同(譬如給 Thread 增加一個Thread.VIRTUAL_THREAD引數,或者增加一個startVirtualThread()方法),這樣現有的多執行緒代碼遷移到虛擬執行緒中的成本就會變得很低,而代價就是 Loom 的團隊必須做更多的作業以保證虛擬執行緒在大部分涉及到多執行緒的標準 API 中都能夠兼容,甚至在除錯器上虛擬執行緒與物理執行緒看起來都會有一致的外觀,但很難全部都支持,譬如呼叫 JNI 的本地堆疊幀就很難放到虛擬執行緒上,所以一旦遇到本地方法,虛擬執行緒就會被系結(Pinned)到一條物理執行緒上,
Loom 的另一個重點改進是支持結構化并發(Structured Concurrency),這是 2016 年才提出的新的并發編程概念,但很快就被諸多編程語言所吸納,它是指程式的并發行為會與代碼的結構對齊,譬如以下代碼所示,按照傳統的編程觀念,如果沒有額外的處理(譬如無中生有地弄一個 await 關鍵字),那在task1和task2提交之后,程式應該繼續向下執行:
ThreadFactory factory = Thread.builder().virtual().factory();
try (var executor = Executors.newThreadExecutor(factory)) {
executor.submit(task1);
executor.submit(task2);
} // blocks and waits
但是在結構化并發的支持下,只有兩個并行啟動的任務執行緒都結束之后,程式才會繼續向下執行,很好地以同步的編碼風格,來解決異步的執行問題,事實上,“Code like sync,Work like async”正是 Loom 簡化并發編程的核心理念,
Project Portola
Portola 專案的目標是將 OpenJDK 向 Alpine Linux 移植,Alpine Linux 是許多 Docker 容器首選的基礎鏡像,因為它只有 5 MB 大小,比起其他 Cent OS、Debain 等動輒一百多 MB 的發行版來說,更適合用于容器環境,不過 Alpine Linux 為了盡量瘦身,默認是用musl作為 C 標準庫的,而非傳統的glibc(GNU C library),因此要以 Alpine Linux 為基礎制作 OpenJDK 鏡像,必須先安裝 glibc,此時基礎鏡像大約有 12 MB,Portola 計劃將 OpenJDK 的上游代碼移植到 musl,并通過兼容性測驗,使用 Portola 制作的標準 Java SE 13 鏡像僅有 41 MB,不僅遠低于 Cent OS 的 OpenJDK(大約 396 MB),也要比官方的 slim 版(約 200 MB)要小得多,
$ sudo docker build .
Sending build context to Docker daemon 2.56kB
Step 1/8 : FROM alpine:latest as build
latest: Pulling from library/alpine
bdf0201b3a05: Pull complete
Digest: sha256:28ef97b8686a0b5399129e9b763d5b7e5ff03576aa5580d6f4182a49c5fe1913
Status: Downloaded newer image for alpine:latest
---> cdf98d1859c1
Step 2/8 : ADD https://download.java.net/java/early_access/alpine/16/binaries/openjdk-13-ea+16_linux-x64-musl_bin.tar.gz /opt/jdk/
Downloading [==================================================>] 195.2MB/195.2MB
---> Using cache
---> b1a444e9dde9
Step 3/7 : RUN tar -xzvf /opt/jdk/openjdk-13-ea+16_linux-x64-musl_bin.tar.gz -C /opt/jdk/
---> Using cache
---> ce2721c75ea0
Step 4/7 : RUN ["/opt/jdk/jdk-13/bin/jlink", "--compress=2", "--module-path", "/opt/jdk/jdk-13/jmods/", "--add-modules", "java.base", "--output", "/jlinked"]
---> Using cache
---> d7b2793ed509
Step 5/7 : FROM alpine:latest
---> cdf98d1859c1
Step 6/7 : COPY --from=build /jlinked /opt/jdk/
---> Using cache
---> 993fb106f2c2
Step 7/7 : CMD ["/opt/jdk/bin/java", "--version"] - to check JDK version
---> Running in 8e1658f5f84d
Removing intermediate container 8e1658f5f84d
---> 350dd3a72a7d
Successfully built 350dd3a72a7d
$ sudo docker tag 350dd3a72a7d jdk-13-musl/jdk-version:v1
$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
jdk-13-musl/jdk-version v1 350dd3a72a7d About a minute ago 41.7MB
alpine latest cdf98d1859c1 2 weeks ago 5.53M
Java 的未來
云原生時代,Java 技術體系的許多前提假設都受到了挑戰,“一次編譯,到處運行”、“面向長時間大規模程式而設計”、“從開放的代碼空間中動態加載”、“一切皆為物件”、“統一執行緒模型”,等等,技術發展迭代不會停歇,沒有必要堅持什么“永恒的真理”,舊的原則被打破,只要合理,便是創新,
Java 語言意識到了挑戰,也意識到了要面向未來而變革,文中提到的這些專案,Amber 和 Portola 已經明確會在 2021 年 3 月的 Java 16 中發布,至少也會達到 Feature Preview 的程度:
- JEP 394:Pattern Matching for instanceof
- JEP 395:Records
- JEP 397:Sealed Classes
- JEP 386:Alpine Linux Port
至于更受關注,同時也是難度更高的 Valhalla 和 Loom 專案,目前仍然沒有明確的版本計劃資訊,盡管它們已經開發了數年時間,非常希望能夠趕在 Java 17 這個 LTS 版本中面世,但前路還是困難重重,
至于難度最高、創建時間最晚的 Leyden 專案,目前還完全處于特性討論階段,連個胚胎都算不上,對于 Java 的原生編譯,我們中短期內只可能寄希望于 Oracle 的 GraalVM,
未來一段時間,是 Java 重要的轉型視窗期,如果作為下一個 LTS 版的 Java 17,能夠成功集 Amber、Portola、Valhalla、Loom 和 Panama(用于外部函式介面訪問,本文沒有提到)的新能力、新特性于一身,GraalVM 也能給予足夠強力支持的話,那 Java 17 LTS 大概率會是一個里程碑式的版本,帶領著整個 Java 生態從大規模服務端應用,向新的云原生時代軟體系統轉型,可能成為比肩當年從面向嵌入式設備與瀏覽器 Web Applets 的 Java 1,到確立現代 Java 語言方向(Java SE/EE/ME 和 JavaCard)雛形的 Java 2 轉型那樣的里程碑,
但是,如果 Java 不能加速自己的發展步伐,那由強大生態所構建的護城河終究會消耗殆盡,被 Golang、Rust 這樣的新生語言,以及 C、C++、C#、Python 等老對手蠶食掉很大一部分市場份額,以至被迫從“天下第一”編程語言的寶座中退位,
Java 的未來是繼續向前,再攀高峰,還是由盛轉衰,鋒芒挫縮,你我拭目以待,
公眾號
coding 筆記、點滴記錄,以后的文章也會同步到公眾號(Coding Insight)中,希望大家關注_
代碼和思維導圖在 GitHub 專案中,歡迎大家 star!

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236904.html
標籤:Java